 基于人工智能技術的OCR應用
基于人工智能技術的OCR應用
光學字符識別(Optical Character Recognition,OCR)是將圖像中的文字信息轉化為可供計算機處理的字符信息的技術,發揮著計算機“眼睛”的功能,是機器與現實世界進行視覺交互的重要技術基礎。
早期的OCR技術可追溯到1870年,電報技術和為盲人設計的閱讀設備的出現標志著OCR的誕生。近年來,隨著人工智能技術在OCR中的實際應用,OCR的性能和效率都得到了很大的提升。
如今,基于人工智能的OCR已經廣泛應用于金融、交通、政務、司法、醫療等多個領域,進入到人們生產生活的方方面面。
檔案OCR是利用OCR技術對紙質檔案數字化副本等圖像文件中的字符形狀進行識別、文字轉換和文本輸出、呈現的過程。
利用人工智能技術開展檔案OCR工作,對于提高工作效率和準確性,加快自動著錄、全文檢索、數據分析等系統功能更好實現,推動檔案信息資源建設從數字化向數據化轉型具有重要意義。
檔案OCR工作現狀
2013年以來,在國家檔案局大力實施“存量數字化、增量電子化”的戰略背景下,紙質檔案數字化副本大量產生。全國各級檔案館(室)存量檔案數字化工作成效顯著,數字化比例大幅提高,很多檔案部門已完成全部館藏檔案的數字化工作。
截至2019年年底,全國各級綜合檔案館館藏檔案數字化副本容量已達1407.8萬GB(吉字節)。當前,檔案OCR工作已全面啟動,相關標準規范已適時出臺。部分地區檔案部門在完成紙質檔案數字化工作的基礎上,紛紛開展了檔案OCR工作。
也有一些檔案部門在開展檔案數字化工作的同時,同步開展了檔案OCR工作。為規范相關工作的開展,國家檔案局因勢利導,于2019年12月發布《紙質檔案數字復制件光學字符識別(OCR)工作規范》,規定了紙質檔案數字復制件OCR工作的組織、實施和管理要求,確定了開展檔案OCR工作的總體原則、工作流程、質量規定等。基于此,檔案部門相關工作取得了大量成果,未來檔案OCR將融入更廣泛、更深層次的檔案工作中。
傳統OCR的不足
在人工智能技術廣泛應用之前,文字的自動化識別是一項十分艱巨、亟需解決的問題。傳統OCR識別是以文字基本外形為基礎,對文字字符之間的差別進行統計分析,再找到一組最優的、可以代表文字之間差異的統計學參數,從而實現對文字的篩選和識別。
傳統OCR工作流程包括圖像導入、圖像預處理、版面分析、文字切割、文字識別等過程。多年來,人們對傳統OCR工作流程進行過大量優化研究,但是受限于流程的復雜性和人工設計特征的表達能力等,傳統的文字檢測與識別方法對于較為復雜的圖像,例如帶有畸變以及模糊的圖像,最終的文字識別結果往往不盡如人意。
傳統OCR對中文字符識別的不足,主要表現在以下4個方面。
一是傳統OCR處理流程的工序太多,且多串行,導致錯誤不斷被傳遞放大。如,在OCR處理流程中,假如每一步都是90%的正確率,看似很高,但是經過5步的錯誤疊加之后,結果就已經不合格了。
二是傳統OCR處理流程涉及較多人工設計,并不一定能夠抓住問題的本質。例如,在文字的二值化這一預處理過程中,二值化的閾值在一些情況下很難調整好。由于這個模型的復雜度較低且無法充分擬合全部數據,在實際處理過程中不得不過濾掉很多有用的信息。
三是在一些背景稍微復雜或者存在變體文字的情況下,傳統OCR基本會失效,處理模型的適應性較弱。版面分析以及行切分的方式只能處理相對簡單的場景,一旦面臨復雜排版等情況,就很難實現準確處理。
四是對單字的識別,傳統OCR無法考慮到上下文的語義關聯。為了解決這個問題,傳統OCR進行了很多組合,如,對識別的結果進行動態路徑搜索。在路徑尋優過程中,經常需要結合文字的外觀特征以及語言模型進行處理,存在較多的耦合,導致在識別系統中堆砌了較多的算法。
即便如此,傳統OCR也存在很多無法處理的問題,如,手寫字體等存在較多的筆畫粘連,傳統OCR很難進行切分。以上這些不足,造成傳統OCR的識別率相對較低,識別時間相對較長。
基于人工智能技術的OCR
近年來,隨著計算機視覺、自然語言理解、知識圖譜等人工智能技術在OCR中的實際使用,OCR的性能和效率都得到了很大提升。通過深度學習的自適應學習驅動方式,能夠更好地應對傳統OCR產生的一些問題,簡化參數預處理的流程,實現端到端的處理,提高OCR識別率。
目前,基于人工智能技術的OCR在簡體印刷文字方面的識別率已達98%以上。人工智能OCR技術還能應用于具有多樣性和復雜性的識別場景。如,不同大小、字體、顏色、亮度、對比度的文字,排列和對齊方式不相同的文字,圖像的非文字區域與文字區域存在相似的紋理,低對比度、模糊斷裂、殘缺文字等。因此,人工智能OCR不僅能應用于文檔的識別,還可應用于自然場景文字圖像的識別。
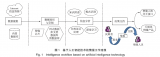
此外,人工智能OCR還能提高工作效率、節省大量成本。基于此,將人工智能OCR應用在檔案工作中,具有重要的作用和意義,必將成為支撐檔案行業數字轉型、智能升級、融合創新的重要基礎。人工智能OCR工作流程主要包括圖像輸入、文本檢測、文本識別、人工確認、人工干預等。首先,將需要識別的紙質檔案數字化副本圖像單個或批量導入OCR系統中。
其次,進行文本檢測。文本檢測主要是定位文字在數字圖像中的位置,并進行位置標注。文本檢測的方法主要有基于候選框的文本檢測、基于語義分割的文本檢測,以及基于兩種方法的混合方法等。基于候選框的文本檢測是先預生成若干候選框,之后再回歸坐標和分類,最后經過NMS(非極大抑制)算法得到最終的檢測結果;基于語義分割的文本檢測是通過FPN(特征金字塔網絡)直接進行像素級別的語義分割,并處理得到相關的坐標。再次,進行文本識別。
文本識別主要是針對定位好的文字區域,識別文本的具體內容,并將圖像中的一串文字轉換為對應的字符。文本識別的算法可分為基于CTC(連接時序分類)技術的方法和基于注意力機制的網絡模型兩大類。其中,基于CTC技術的方法可以有效地捕獲輸入序列的下文依賴關系,同時能夠很好地解決圖像和文本字符對不齊的問題,但在自由度較大的手寫場景下會出現識別錯誤。
基于注意力機制的網絡模型主要應用于卷積神經網絡特征權重的分配上,并提高強特征的權重、降低弱特征的權重,在由圖像到文字的解碼過程中有天然的語義捕獲能力。然后,進行人工確認。對OCR識別后的結果進行確認,判斷是否出錯。
在人工確認過程中,可以采用后期批量處理等靈活性較強的方式。最后,進行人工干預,修正OCR識別結果中可能存在的錯誤。人工智能OCR可采用獨立式或嵌入式等方式應用在檔案數字化系統中。獨立式是作為獨立軟件使用,或者通過應用程序接口(API)進行數據交互,不依賴于檔案數字化系統。
嵌入式是將OCR模塊嵌入檔案數字化系統,作為其功能的一部分,需要在設計開發檔案管理系統時進行統一規劃,或對已有的系統進行改造。目前,人工智能OCR已被引入多個行業領域,但在檔案行業應用中仍存在難點和不足,主要體現在兩個方面。
一是檔案文字存在多樣性。檔案類型多種多樣,文字內容包羅萬象,存在不同語言、字體、大小、顏色、亮度、排列和對齊方式,以及圖像內容對比度低、模糊斷裂、殘缺等問題,甚至存在出現識別難度更大的不同時期手寫體、繁簡體等各種情況。這些問題或情況給檔案OCR工作帶來了各種挑戰,人工智能OCR也無法解決所有的問題,這就需要工作人員結合實際情況,尋找基于特定技術條件的最優工作解決方案。
二是技術瓶頸。近年來,雖然人工智能OCR使機器識別文字的性能和效率得到了顯著提升,但是,機器識別文字的能力和水平與工作人員理解圖像中文字的能力和水平相比,依然存在較大差距。總體來看,仍需繼續不斷提升OCR的魯棒性、效率性和智能化水平,才能更好地將其應用在難度更大、情況更復雜的檔案工作中。
編輯:lyn
-
人工智能
+關注
關注
1791文章
47233瀏覽量
238351 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
45986 -
OCR
+關注
關注
0文章
144瀏覽量
16355
原文標題:圖像識別技術在檔案OCR工作中的應用
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
嵌入式和人工智能究竟是什么關系?
對話華為大咖,探討油氣行業數字化轉型和人工智能技術的應用與實踐

未來智慧建筑:人工智能技術的無限可能
《AI for Science:人工智能驅動科學創新》第6章人AI與能源科學讀后感
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
risc-v在人工智能圖像處理應用前景分析
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅動科學創新
FPGA在人工智能中的應用有哪些?
人工智能技術在集成電路中的應用
Google開發專為視頻生成配樂的人工智能技術
嵌入式人工智能的就業方向有哪些?
aigc是什么意思和人工智能有什么區別
人工智能技術在軍事情報領域的應用背景





 工商網監
工商網監
評論