 圖神經網絡的解釋性綜述
圖神經網絡的解釋性綜述
圖神經網絡的可解釋性是目前比較值得探索的方向,今天解讀的2021最新綜述,其針對近期提出的 GNN 解釋技術進行了系統的總結和分析,歸納對比了該問題的解決思路。作者還為GNN解釋性問題提供了標準的圖數據集和評估指標,將是這一方向非常值得參考的一篇文章。
論文標題:Explainability in Graph Neural Networks: A Taxonomic Survey
論文地址:https://arxiv.org/pdf/2012.15445.pdf
參考文獻
0.Abstract近年來,深度學習模型的可解釋性研究在圖像和文本領域取得了顯著進展。然而,在圖數據領域,既沒有針對GNN可解釋性的統一處理方法,也不存在標準的 benchmark 數據集和評估準則。在這篇論文中,作者對目前的GNN解釋技術從統一和分類的角度進行了總結,闡明了現有方法的共性和差異,并為進一步的方法發展奠定了基礎。此外,作者專門為GNN解釋技術生成了 benchmark 圖數據集,并總結了當前用于評估GNN解釋技術的數據集和評估方法。
1. Introduction解釋黑箱模型是十分必要的:如果沒有對預測背后的底層機制進行推理,深層模型就無法得到完全信任,這就阻礙了深度模型在與公平性、隱私性和安全性有關的關鍵應用程序中使用。為了安全、可信地部署深度模型,需要同時提供準確的預測和人類能領會的解釋,特別是對于跨學科領域的用戶。
深層模型的解釋技術通常從研究其預測背后的潛在關系著手,解釋技術大致可分為兩類:
1)input-dependent explanations(依賴輸入的解釋方法)
該類方法從特征的角度出發,提供與輸入相關的解釋,例如研究輸入特征的重要性得分,或對深層模型的一般行為有高水平的理解。論文 [10],[11],[18]通過研究梯度或權重,分析預測結果相對于輸入特征的敏感程度。論文 [12],[13],[19] 通過將隱藏特征映射到輸入空間,從而突出重要的輸入特征。[14] 通過遮蔽不同的輸入特征,觀察預測的變化,以識別重要的特征。
2)input-independent explanations(獨立于輸入的解釋方法)
與依賴特征的解釋方法不同,該類方法從模型角度出發,提供獨立于輸入的解釋,例如研究輸入 patterns,使某類的預測得分最大化。論文[17],[22]通過探究隱藏神經元的含義,進而理解的整個預測過程。論文[23],[24],[25],[26] 對近期的方法進行了較為系統的評價和分類。然而,這些研究只關注圖像和文本領域的解釋方法,忽略了深度圖模型的可解釋性。
GNN 的可解釋性
與圖像和文本領域相比,對圖模型解釋性的研究較少,然而這是理解深度圖神經網絡的關鍵。近年來,人們提出了幾種解釋 GNN 預測的方法,如XGNN[41]、gnexplainer[42]、PGExplainer[43]等。這些方法是從不同的角度提供了不同層次的解釋。但至今仍然**缺乏標準的數據集和度量來評估解釋結果。**因此,需要對GNN解釋技術和其評估方法進行系統的研究。
本文
本研究提供了對不同GNN解釋技術的系統研究,目的對不同方法進行直觀和高水平的解釋,論文貢獻如下:
對現有的深度圖模型的解釋技術進行了系統和全面的回顧。
提出了現有GNN解釋技術的新型分類框架,總結了每個類別的關鍵思想,并進行了深刻的分析。
詳細介紹了每種GNN解釋方法,包括其方法論、優勢、缺點,與其他方法的區別。
總結了GNN解釋任務中常用的數據集和評價指標,討論了它們的局限性,并提出了幾點建議。
通過將句子轉換為圖,針對文本領域構建了三個人類可理解的數據集。這些數據集即將公開,可以直接用于GNN解釋任務。
名詞解釋:Explainability versus Interpretability
在一些研究中,“explainability” 和 “interpretability”被交替使用。本文作者認為這兩個術語應該被區分開來,遵循論文[44]來區分這兩個術語。如果一個模型本身能夠對其預測提供人類可理解的解釋,則認為這個模型是 “interpretable”。注意,這樣的模型在某種程度上不再是一個黑盒子。例如,一個決策樹模型就是一個 “interpretable“的模型。同時,”explainable “模型意味著該模型仍然是一個黑盒子,其預測有可能被一些事后解釋技術所理解。
2. 總體框架目前存在一系列針對深度圖模型解釋性問題的工作,這些方法關注圖模型的不同方面,并提供不同的觀點來理解這些模型。它們一般都會從幾個問題出發實現對圖模型的解釋:哪些輸入邊更重要?哪些輸入節點更重要? 哪些節點特征更重要?什么樣的圖模式會最大限度地預測某個類?為了更好地理解這些方法,本文為GNNs的不同解釋技術提供了分類框架,結構如圖1所示。根據提供什么類型的解釋,解釋性技術被分為兩大類:實例級方法和模型級方法。本文接下來的部分將針對圖1的各個分支展開講解,并作出對比。
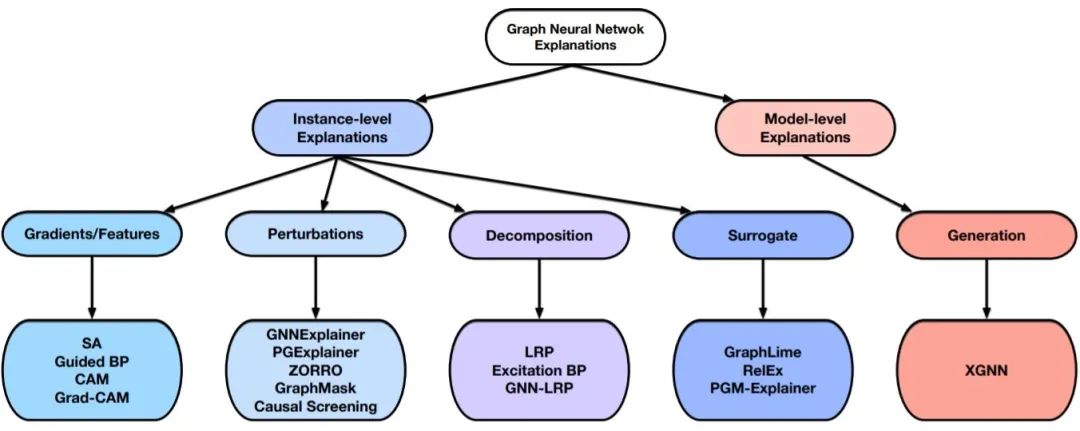
圖1 GNN 解釋性方法分類框架
1)實例級方法
實例級方法與特征工程的思想有些類似,旨在找到輸入數據中最能夠影響預測結果的部分特征,為每個輸入圖提供 input-dependent 的解釋。給定一個輸入圖,實例級方法旨在探究影響模型預測的重要特征實現對深度模型的解釋。根據特征重要性分數的獲得方式,作者將實例級方法分為四個不同的分支:
基于梯度/特征的方法[49],[50],采用梯度或特征值來表示不同輸入特征的重要程度。
基于擾動的方法[42],[43],[51],[52],[53],監測在不同輸入擾動下預測值的變化,從而學習輸入特征的重要性分數。
基于分解的方法[49],[50],[54],[55],首先將預測分數,如預測概率,分解到最后一個隱藏層的神經元。然后將這樣的分數逐層反向傳播,直到輸入空間,并將分解分數作為重要性分數。
基于代理的方法[56],[57],[58],首先從給定例子的鄰居中抽取一個數據集的樣本。接下來對采樣的數據集合擬合一個簡單且可解釋的模型,如決策樹。通過解釋代理模型實現對原始預測的解釋。
2)模型級方法
模型級方法直接解釋圖神經網絡的模型,不考慮任何具體的輸入實例。這種 input-independent 的解釋是高層次的,能夠解釋一般性行為。與實例級方法相比,這個方向的探索還比較少。現有的模型級方法只有XGNN[41],它是基于圖生成的,通過生成 graph patterns使某一類的預測概率最大化,并利用 graph patterns 來解釋這一類。
總的來說,這兩類方法從不同的角度解釋了深度圖模型。實例級方法提供了針對具體實例的解釋,而模型級方法則提供了高層次的見解和對深度圖模型工作原理的一般理解。
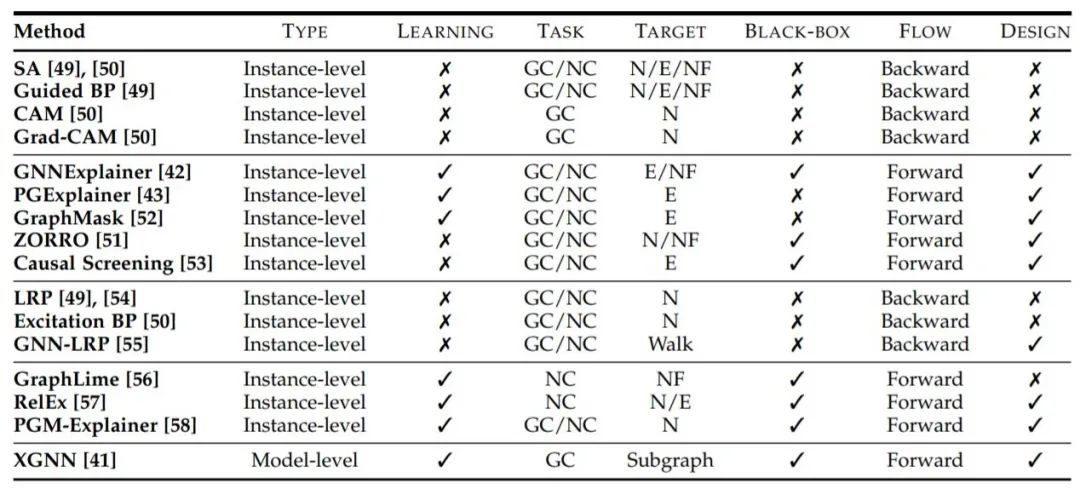
”Type “表示提供什么類型的解釋,”Learning “表示是否涉及學習過程,”Task “表示每種方法可以應用于什么任務(GC表示圖分類,NC表示節點分類),”Target “表示解釋的對象(N表示節點,E表示邊,NF表示節點特征,Walk表示圖游走),”Black-box “表示在解釋階段是否將訓練好的GNNs作為黑盒處理,”Flow “表示解釋的計算流程,”Design “表示解釋方法是否有針對圖數據的具體設計。
3.方法介紹
3.1 基于梯度/特征的方法(Gradients/Features-Based Methods)
采用梯度或特征來解釋深度模型是最直接的解決方案,在圖像和文本任務中被廣泛使用。其關鍵思想是將梯度或隱藏的特征圖值作為輸入重要性的近似值。一般來說,在這類方法中,梯度或特征值越大,表示重要性越高。需要注意的是,梯度和隱藏特征都與模型參數高度相關,那么這樣的解釋可以反映出模型所包含的信息。本文將介紹最近提出的幾種方法,包括:SA[49]、Guided BP[49]、CAM[50]和Grad-CAM[50]。這些方法的關鍵區別在于梯度反向傳播的過程以及如何將不同的隱藏特征圖結合起來。
1)SA
SA[49]直接采用梯度的平方值作為不同輸入特征的重要性得分。輸入特征可以是圖節點、邊或節點特征。它假設絕對梯度值越高,說明相應的輸入特征越重要。雖然它簡單高效,但有幾個局限性:1)SA方法只能反映輸入和輸出之間的敏感程度,不能很準確地表達重要性(敏感度不等于重要性)。2)還存在飽和問題[59]。即在模型性能達到飽和的區域,其輸出相對于任何輸入變化的變化都是十分微小的,梯度很難反映輸入的貢獻程度。
2)Guided BP
Guided BP[49]與SA有著相似的思想,但修改了反向傳播梯度的過程。由于負梯度很難解釋,Guided BP只反向傳播正梯度,而將負梯度剪成零。因此Guided BP與SA有著相同的局限性。
3)CAM
CAM [50] 將最后一層的節點特征映射到輸入空間,從而識別重要節點。它要求GNN模型采用全局平均池化層和全連接層作為最終分類器。CAM將最終的節點嵌入,通過加權求和的方式組合不同的特征圖,從而獲得輸入節點的重要性分數。權重是從與目標預測連接的最終全連接層獲得的。該方法非常簡單高效,但仍有幾大限制:1)CAM對GNN結構有特殊要求,限制了它的應用和推廣。2)它假設最終的節點嵌入可以反映輸入的重要性,這是啟發式的,可能不是真的。3)它只能解釋圖分類模型,不能應用于節點分類任務中。
4)Grad-CAM
Grad-CAM [50] 通過去除全局平均池化層的約束,將CAM擴展到一般圖分類模型。同樣,它也將最終的節點嵌入映射到輸入空間來衡量節點重要性。但是,它沒有使用全局平均池化輸出和全連接層輸出之間的權重,而是采用梯度作為權重來組合不同的特征圖。與CAM相比,Grad-CAM不需要GNN模型在最終的全連接層之前采用全局平均池化層。但它也是基于啟發式假設,無法解釋節點分類模型。
3.2 基于擾動的方法(Perturbation-Based Methods)
基于擾動的方法[14],[15],[60]被廣泛用于解釋深度圖像模型。其根本動機是研究不同輸入擾動下的輸出變化。當重要的輸入信息被保留(沒有被擾動)時,預測結果應該與原始預測結果相似。論文 [14],[15],[60]學習一個生成器來生成掩碼,以選擇重要的輸入像素來解釋深度圖像模型。然而,這種方法不能直接應用于圖模型,圖數據是以節點和邊來表示的,它們不能調整大小以共享相同的節點和邊數,結構信息對圖來說至關重要,可以決定圖的功能。
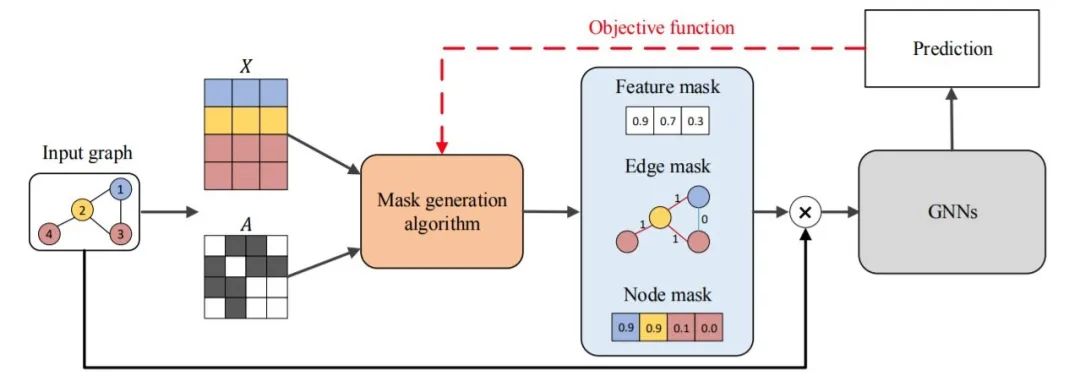
圖2 基于擾動方法的一般流程
基于擾動的方法采用不同的掩碼生成算法來獲得不同類型的掩碼。需要注意的是,掩碼可以對應節點、邊或節點特征。在這個例子中,我們展示了一個節點特征的軟掩碼,一個邊的離散掩碼和一個節點的近似離散掩碼。然后,將掩碼與輸入圖結合起來,得到一個包含重要輸入信息的新圖,遮蔽掉不需要的信息。
最終將新圖輸入到訓練好的GNN中,評估掩碼并更新掩碼生成算法。本文將介紹幾種基于擾動的方法,包括:GNNExplainer[42]、PGExplainer[43]、ZORRO[51]、GraphMask[52],Causal Screening[53]。直觀地講,掩碼捕捉到的重要輸入特征應該傳達關鍵的語義意義,從而得到與原圖相似的預測結果。這些方法的區別主要在于三個方面:掩碼生成算法、掩碼類型和目標函數。
軟掩碼包含[0,1]之間的連續值,掩碼生成算法可以直接通過反向傳播進行更新。但軟掩碼存在 ”introduced evidence “的問題[14],即掩碼中任何非零或非一的值都可能給輸入圖引入新的語義或新的噪聲,從而影響解釋結果。同時,離散掩碼只包含離散值0和1,由于沒有引入新的數值,可以避免 ”introduced evidence “問題。
但是,離散掩碼總是涉及到不可微的問題,如采樣。主流的解決方法是策略梯度技術[61]。論文[45],[62],[63]提出采用重參數化技巧,如Gumbel-Softmax估計和稀疏松弛,來逼近離散掩碼。需要注意的是,輸出的掩碼并不是嚴格意義上的離散掩碼,而是提供了一個很好的近似值,這不僅可以實現反向傳播,而且在很大程度上緩解了”introduced evidence“的問題。
接下來將詳細的介紹目前存在的幾種基于擾動的解釋性方法,我們可以重點關注它們的作用對象(節點或邊或節點特征),以及它們的掩碼生成算法、掩碼類型和目標函數。
1)GNNExplainer
GNNExplainer [42] 學習邊和節點特征的軟掩碼,通過掩碼優化來解釋預測。軟掩碼被隨機初始化,并被視為可訓練變量。然后通過元素點乘將掩碼與原始圖結合。最大化原始圖的預測和新獲得的圖的預測之間的互信息來優化掩碼。但得到的掩碼仍然是軟掩碼,因此無法避免 ”introduced evidence“問題。此外,掩碼是針對每個輸入圖單獨優化的,因此解釋可能缺乏全局視角。
2)PGExplainer
PGExplainer[43]學習邊的近似離散掩碼來解釋預測。它訓練一個參數化的掩碼預測器來預測邊掩碼。給定一個輸入圖,首先通過拼接節點嵌入來獲得每個邊的嵌入,然后預測器使用邊嵌入來預測邊掩碼。預測器使用邊嵌入來預測每個邊被選中的概率(被視為重要性分數)。通過重參數化技巧對近似的離散掩碼進行采樣。最后通過最大化原始預測和新預測之間的相互信息來訓練掩碼預測器。需要注意的是,即使采用了重參數化技巧,得到的掩碼并不是嚴格意義上的離散掩碼,但可以很大程度上緩解 ”introduced evidence“的問題。由于數據集中的所有邊都共享相同的預測器,因此解釋可以提供對訓練好的GNN的全局理解。
3)GraphMask
GraphMask[52]是一種事后解釋GNN各層中邊重要性的方法。與PGExplainer類似,它訓練一個分類器來預測是否可以丟棄一條邊而不影響原來的預測。然而,GraphMask為每一層GNN獲取邊掩碼,而PGExplainer只關注輸入空間。此外,為了避免改變圖結構,被丟棄的邊被可學習的基線連接所取代,基線連接是與節點嵌入相同維度的向量。需要注意的是,采用二進制Concrete分布[63]和重參數化技巧來近似離散掩碼。此外,分類器使用整個數據集通過最小化一個散度項來訓練,用于衡量網絡預測之間的差異。與PGExplainer類似,它可以很大程度上緩解 ”introduced evidence“問題,并對訓練后的GNN進行全局理解。
3)ZORRO
ZORRO[51]采用離散掩碼來識別重要的輸入節點和節點特征。給定一個輸入圖,采用貪心算法逐步選擇節點或節點特征。每一步都會選擇一個fidelity score最高的節點或一個節點特征。通過固定所選節點/特征,并用隨機噪聲值替換其他節點/特征,來衡量新的預測與模型原始預測的匹配程度。由于不涉及訓練過程,因此避免了離散掩碼的不可微限制。此外,通過使用硬掩碼,ZORRO不會受到 ”introduced evidence “問題的影響。然而,貪婪的掩碼選擇算法可能導致局部最優解釋。此外,由于掩碼是為每個圖形單獨生成的,因此解釋可能缺乏全局的理解。
4)Causal Screening
Causal Screening[53]研究輸入圖中不同邊的因果歸因。它為 explanatory subgraph 確定一個邊掩碼。關鍵思想是:研究在當前 explanatory subgraph 中增加一條邊時預測的變化,即所謂的因果效應。對于每一步,它都會研究不同邊的因果效應,并選擇一條邊添加到子圖中。具體來說,它采用個體因果效應(ICE)來選擇邊,即測量在子圖中添加不同邊后的互信息(原圖與解釋子圖的預測之間)差異。與ZORRO類似,Causal Screening是一種貪心算法,不需要任何訓練過程就能生成離散掩碼。因此,它不會受到 ”introduced evidence “問題的困擾,但可能缺乏全局性的理解,而停留在局部最優解釋上。
3.3 基于代理的方法(Surrogate Methods)
由于輸入空間和輸出預測之間的復雜和非線性關系,深度模型的解釋具有挑戰性。代理方法能夠為圖像模型提供實例級解釋。其基本思想是化繁為簡,既然無法解釋原始深度圖模型,那么采用一個簡單且可解釋的代理模型來近似復雜的深層模型,實現輸入實例的鄰近區域預測。
需要注意的是,這些方法都是假設輸入實例的鄰近區域的關系不那么復雜,可以被一個較簡單的代理模型很好地捕獲。然后通過可解釋的代理模型的來解釋原始預測。將代理方法應用到圖域是一個挑戰,因為圖數據是離散的,包含拓撲信息。那么如何定義輸入圖的相鄰區域,以及什么樣的可解釋代理模型是合適的,都是不清楚的。
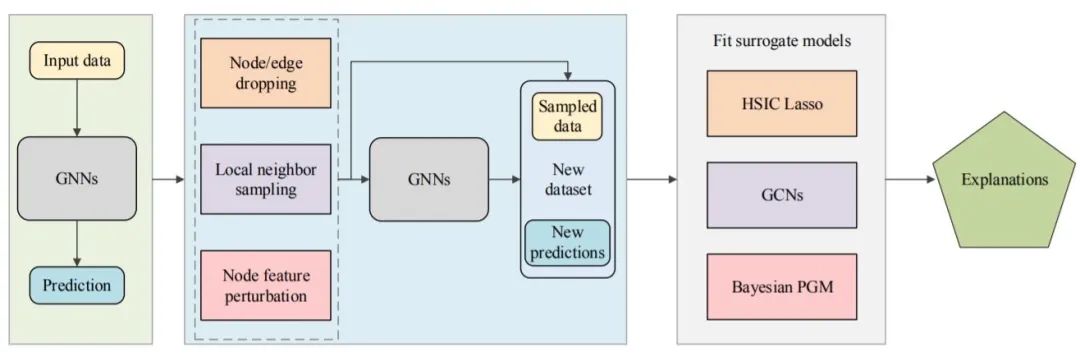
圖3 代理模型的一般框架
給定一個輸入圖及其預測,它們首先對一個局部數據集進行采樣,以表示目標數據周圍的關系。然后應用不同的代理方法來擬合局部數據集。需要注意的是,代理模型一般都是簡單且可解釋的ML模型。最后,代理模型的解釋可以看作是對原始預測的解釋。本文將介紹最近提出的幾種代理方法,包括:GraphLime[56]、RelEx[57]和PGM-Explainer[58]。
這些方法的一般流程如圖3所示。為了解釋給定輸入圖的預測,它們首先獲得一個包含多個相鄰數據對象及其預測的局部數據集。然后擬合一個可解釋模型來學習局部數據集。來自可解釋模型的解釋被視為原始模型對輸入圖的解釋。不同代理模型關鍵的區別在于兩個方面:如何獲得局部數據集和選擇什么代理模型。
1)GraphLime
GraphLime[56]將LIME[64]算法擴展到深度圖模型,并研究不同節點特征對節點分類任務的重要性。給定輸入圖中的一個目標節點,將其N-hop 鄰居節點及其預測值視為局部數據集,其中N的合理設置是訓練的GNN的層數。然后采用非線性代理模型HSIC Lasso[65]來擬合局部數據集。根據HSIC Lasso中不同特征的權重,可以選擇重要的特征來解釋HSIC Lasso的預測結果。這些被選取的特征被認為是對原始GNN預測的解釋。但是,GraphLime只能提供節點特征的解釋,卻忽略了節點和邊等圖結構,而這些圖結構對于圖數據來說更為重要。另外,GraphLime是為了解釋節點分類預測而提出的,但不能直接應用于圖分類模型。
2)RelEx
RelEx[57]結合代理方法和基于擾動的方法的思想,研究節點分類模型的可解釋性。給定一個目標節點及其計算圖(N-hop鄰居),它首先從計算圖中隨機采樣連接的子圖,獲得一個局部數據集,并將這些子圖喂入訓練好的GNN,以獲得其預測結果。從目標節點開始,它以BFS的方式隨機選擇相鄰節點。采用GCN模型作為代理模型來擬合局部數據集。與GraphLime不同,RelEx中的代理模型是不可解釋的。訓練后,它進一步應用前述基于擾動的方法,如生成軟掩碼或Gumbel-Softmax掩碼來解釋預測結果。該過程包含了多個步驟的近似,比如使用代理模型來近似局部關系,使用掩碼來近似邊的重要性,從而使得解釋的說服力和可信度降低。由于可以直接采用基于擾動的方法來解釋原有的深度圖模型,因此沒有必要再建立一個不可解釋的深度模型作為代理模型來解釋。
3)PGM-Explainer
PGM-Explainer[58]建立了一個概率圖形模型,為GNN提供實例級解釋。局部數據集是通過隨機節點特征擾動獲得的。具體來說,給定一個輸入圖,每次PGM-Explainer都會隨機擾動計算圖中幾個隨機節點的節點特征。然后對于計算圖中的任何一個節點,PGM-Explainer都會記錄一個隨機變量,表示其特征是否受到擾動,以及其對GNN預測的影響。通過多次重復這樣的過程,就可以得到一個局部數據集。通過Grow-Shrink(GS)算法[66]選擇依賴性最強的變量來減小局部數據集的大小。最后采用可解釋的貝葉斯網絡來擬合局部數據集,并解釋原始GNN模型的預測。PGM-Explainer可以提供有關圖節點的解釋,但忽略了包含重要圖拓撲信息的圖邊。此外,與GraphLime和RelEx不同的是,PGM-Explainer可以同時用于解釋節點分類和圖形分類任務。
3.4 分解方法(Decomposition Methods)
分解方法是另一種比較流行的解釋深度圖像分類器的方法,它通過將原始模型預測分解為若干項來衡量輸入特征的重要性。然后將這些項視為相應輸入特征的重要性分數。這些方法直接研究模型參數來揭示輸入空間中的特征與輸出預測之間的關系。需要注意的是,這些方法要求分解項之和等于原始預測得分。由于圖包含節點、邊和節點特征,因此將這類方法直接應用于圖域是具有挑戰性的。很難將分數分配給不同的邊,圖數據邊包含著重要的結構信息,不容忽視。
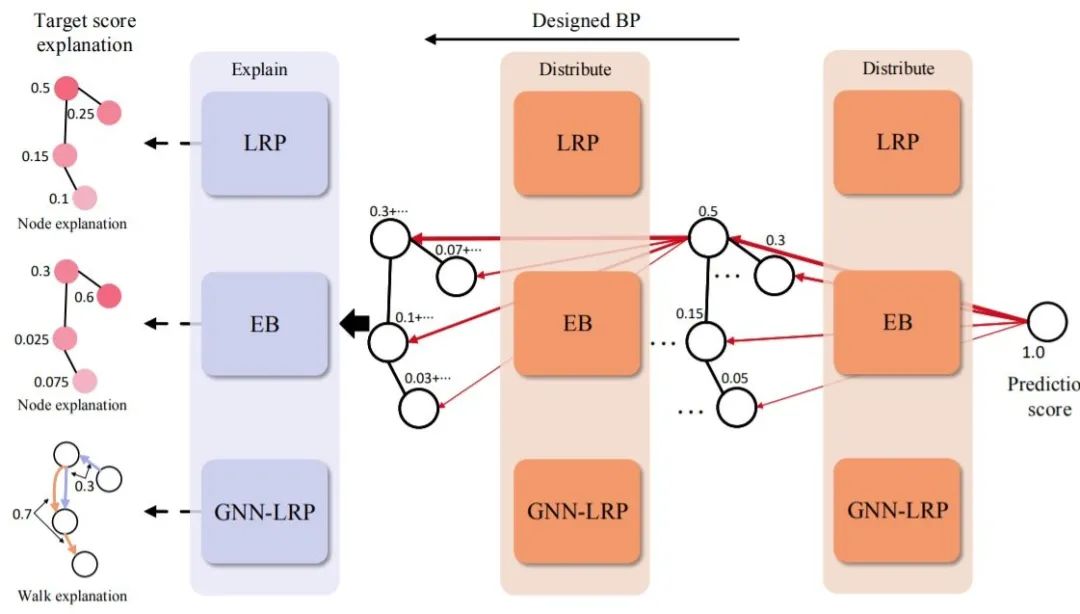
圖5 分解方法的一般流程
本文將介紹最近提出的幾種用于解釋深層圖神經網絡泛讀分解方法,包括:Layerwise Relevance Propagation(LRP)[49]、[54]、Excitation BP[50]和GNN-LRP[55]。這些算法的主要思想是建立分數分解規則,將預測分數分配到輸入空間。這些方法的一般流程如圖4所示。
以反向傳播的方式逐層分發預測得分,直到輸入層。從輸出層開始,將模型的預測結果作為初始目標分數。然后將分數進行分解,并按照分解規則分配給上一層的神經元。通過重復這樣的過程,直到輸入空間,它們可以得到節點特征的重要性分數,這些分數可以組合起來表示邊重要性、節點重要性和游走重要性。但是這些算法都忽略了深度圖模型中的激活函數。不同分解方法的主要區別在于分數分解規則和解釋的目標。
1)LRP
LRP[49],[54]將原來的LRP算法[67]擴展到深度圖模型。它將輸出的預測分數分解為不同的節點重要性分數。分數分解規則是基于隱藏特征和權重制定的。對于一個目標神經元,其得分表示為上一層神經元得分的線性近似。目標神經元激活貢獻度較高的神經元獲得的目標神經元得分比例較大。為了滿足保守屬性,在事后解釋階段將鄰接矩陣作為GNN模型的一部分,這樣在分數分配時就可以忽略它,否則,鄰接矩陣也會收到分解后的分數,從而使保守屬性失效。由于LRP是直接根據模型參數開發的,所以其解釋結果更具有可信度。但它只能研究不同節點的重要性,不能應用于圖結構,如子圖和游走。該算法需要對模型結構有全面的了解,這就限制了它對非專業用戶的應用,如跨學科研究人員。
2)Excitation BP
Excitation BP[50]與LRP算法有著相似的思想,但它是基于全概率法則開發的。它定義了當前層中一個神經元的概率等于它輸出給下一層所有連接神經元的總概率。那么分數分解規則可以看作是將目標概率分解為幾個條件概率項。Excitation BP的計算與LRP中的z+規則高度相似。因此它與LRP算法有著相同的優點和局限性。
3)GNN-LRP
GNN-LRP[55]研究了不同圖游走的重要性。由于在進行鄰域信息聚合時,圖游走對應于消息流,因此它對深層圖神經網絡更具有一致性。得分分解規則是模型預測的高階泰勒分解。研究表明,泰勒分解(在根零處)只包含T階項,其中T是訓練的GNN的層數。那么每個項對應一個T階圖游走,可以視為其重要性得分。由于無法直接計算泰勒展開給出的高階導數,GNN-LRP還遵循反向傳播過程來逼近T階項。GNN-LRP中的反向傳播計算與LRP算法類似。然而,GNN-LRP不是將分數分配給節點或邊,而是將分數分配給不同的圖游走。它記錄了層與層之間的消息分發過程的路徑。這些路徑被認為是不同的游走,并從它們對應的節點上獲得分數。雖然GNN-LRP具有堅實的理論背景,但其計算中的近似值可能并不準確。由于每個游走都要單獨考慮,計算復雜度很高。此外,對于非專業人員來說,它的使用也具有挑戰性,尤其是對于跨學科領域。
4. 模型級方法與實例級方法不同,模型級方法旨在提供一般性的見解和高層次的理解來解釋深層圖模型。它們研究什么樣的輸入圖模式可以導致GNN的某種行為,例如最大化目標預測。輸入優化[16]是獲得圖像分類器模型級解釋的一個熱門方向。但是,由于圖拓撲信息的離散性,它不能直接應用于圖模型,從而使GNN在模型層面的解釋更具挑戰性。它仍然是一個重要但研究較少的課題。據我們所知,現有的解釋圖神經網絡的模型級方法只有XGNN[41]。
1)XGNN
XGNN[41]提出通過圖生成來解釋GNN。它不是直接優化輸入圖,而是訓練一個圖生成器,使生成的圖能夠最大化目標圖預測。然后,生成的圖被視為目標預測的解釋,并被期望包含判別性的圖模式。在XGNN中,圖形生成被表述為一個強化學習問題。對于每一步,生成器都會預測如何在當前圖中增加一條邊。然后將生成的圖輸入到訓練好的GNN中,通過策略梯度獲得反饋來訓練生成器。此外,還加入了一些圖規則,以鼓勵解釋既有效又能被人類理解。XGNN是一個生成模型級解釋的通用框架,因此可以應用任何合適的圖生成算法。該解釋是通用的,并且提供了對訓練的GNNs的全局理解。然而XGNN只證明了其在解釋圖分類模型方面的有效性,XGNN是否可以應用于節點分類任務還不得而知,這是未來研究中需要探索的重要方向。
5. 評估模型由于缺乏 ground truths,因此不容易對解釋方法的結果進行評估,作者討論并分析了幾種常用的數據集和度量標準。
5.1. Datasets
需要選擇合適的數據集來評估不同的解釋技術,并且希望數據是直觀的,易于可視化的。應該在數據實例和標簽之間蘊含人類可以理解的理由,這樣專家就可以驗證這些理由是否被解釋算法識別。為了評估不同的解釋技術,通常采用幾種類型的數據集,包括合成數據、情感圖數據和分子數據。
5.1.1. Synthetic data
利用現有的合成數據集來評估解釋技術[42],[43]。在這樣的數據集中,包含了不同的 graph motifs,可以通過它們確定節點或圖的標簽。數據實例和數據標簽之間的關系由人類定義。即使經過訓練的GNNs可能無法完美地捕捉到這樣的關系,但graph motifs 可以作為解釋結果的ground truths 的合理近似值。這里我們介紹幾種常見的合成數據集。
BA-shapes:它是一個節點分類數據集,有4個不同的節點標簽。對于每個圖形,它包含一個基礎圖(300個節點)和一個類似房子的5節點 motif。需要注意的是,基礎圖是由Barab′asi-Albert(BA)模型獲得的,它可以生成具有優先附加機制的隨機無標度網絡[68]。motif 被附加到基圖上,同時添加隨機邊。每個節點根據其是否屬于基礎圖或motif 的不同空間位置進行標注。
BA-Community:這是一個有8個不同標簽的節點分類數據集。對于每個圖,它是通過組合兩個隨機添加邊的BA-shapes圖獲得的。節點標簽由BA-shapes圖的成員資格及其結構位置決定。
Tree-Cycle:它是一個有兩個不同標簽的節點分類數據集。對于每個圖,它由深度等于8的基平衡樹圖和6節點周期 motif 組成。這兩部分是隨機連接的。基圖中節點的標簽為0,否則為1。
Tree-Grids:它是一個有兩個不同標簽的節點分類數據集。它與 Tree-Cycle 數據集相同,只是Tree-Grids數據集采用了9節點網格 motifs 而不是周期 motifs 。
BA-2Motifs:它是一個具有2種不同圖標簽的圖形分類數據集。有800個圖,每個圖都是通過在基礎BA圖上附加不同的motif來獲得的,如house-like motif 和 five-node cycle motif。不同的圖是根據motif 的類型來標注的。
在這些數據集中,所有節點特征都被初始化為全1向量。訓練好的GNNs模型要捕捉圖結構來進行預測。然后根據每個數據集的構建規則,我們可以分析解釋結果。例如,在BA-2Motifs數據集中,我們可以研究解釋是否能夠捕獲motif結構。然而,合成數據集只包含圖和標簽之間的簡單關系,可能不足以進行綜合評估。
5.1.2 Sentiment graph data
由于人類只有有限的領域知識,傳統的圖數據集在理解上具有挑戰性,因此需要構建人類可理解的圖數據集。文本數據具有人類可理解的語義的單詞和短語組成,因此可以成為圖解釋任務的合適選擇,解釋結果可以很容易地被人類評估。因此我們基于文本情感分析數據構建了三個情感圖數據集,包括SST2[69]、SST5[69]和Twitter[70]數據集。

圖5 文本情感圖
對于每個文本序列,將其轉換為一個圖,每個節點代表一個單詞,而邊則反映不同單詞之間的關系。作者采用Biaffine解析器[71]來提取詞的依賴關系。圖5中展示了生成的情感圖的一個例子。生成的圖是有向的,但邊標簽被忽略了,因為大多數GNNs不能捕獲邊標簽信息。用BERT[72]來學習單詞嵌入,并將這種嵌入作為圖節點的初始嵌入。建立一個模型,采用預訓練好的BERT作為特征提取器,采用一層平均池化的GCN作為分類器。最后預訓練的BERT為每個詞提取768維的特征向量,作為情感圖數據中的節點特征。
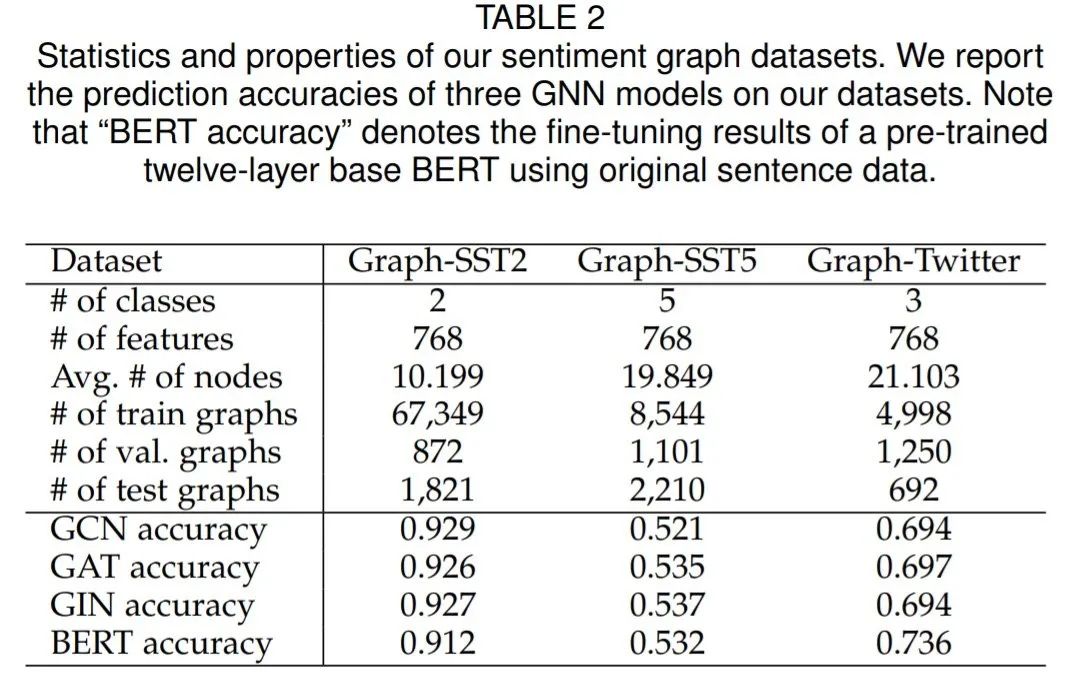
作者建立了三個情感圖數據集,分別為Graph-SST2、Graph-SST5和Graph-Twitter ,并即將公開,可以直接用于研究不同的可解釋技術。這些數據集的統計和屬性如表2所示。為了驗證本文生成的情感數據集具有可解釋信息,作者分別再新生成的情感數據集和原始數據集進行實驗。
作者展示了兩層GNNs在這些數據集上的預測精度,包括GCNs、GATs和GINs。還展示了使用原始句子數據集的預訓練的BERT[72]的微調精度。結果表明,與原始句子數據集相比,作者構建的情感圖數據集可以達到具有競爭力的性能這些數據集是實現圖模型解釋的合理選擇。根據不同詞的語義和情感標簽,我們可以研究可解釋方法是否能識別出具有關鍵意義的詞以及不同詞之間的關系
5.1.3 Molecule data
分子數據集也被廣泛用于解釋任務,如MUTAG[73]、BBBP和Tox21[74]。這類數據集中的每個圖對應一個分子,其中節點代表原子,邊是化學鍵。分子圖的標簽一般由分子的化學功能或性質決定。采用這樣的數據集進行解釋任務需要領域知識,例如什么化學基團對其官能性更具有鑒別性。例如,在數據集MUTAG中,不同的圖形是根據它們對細菌的誘變作用來標注的。例如,已知碳環和NO2化學基團可能導致誘變效應[73],那么可以研究可解釋方法是否能識別出對應類別的 patterns
(在不同的領域中,不同的局部結構是具有區分力的,可解釋方法是否能夠識別這些模式?)
5.2 Evaluation Metrics
即使可視化的結果可以讓人理解解釋性方法是否合理,但由于缺乏 ground truths,這種評估并不完全可信。為了比較不同的解釋性方法,我們需要研究每個輸入樣例的結果,這很耗時。因此評估度量對于研究可解釋方法至關重要。好的度量方法應該從模型的角度來評估預測結果,比如解釋是否忠實于模型[75],[76]。作者將介紹最近提出的幾種針對解釋性問題的評估度量方法。
5.2.1 Fidelity/Infidelity
首先,從模型的預測結果上分析解釋性方法的性能,解釋應該忠于模型,解釋方法應該識別對模型重要的輸入特征。為了評估這一點,最近提出了Fidelity[50]度量方法。關鍵思想在于如果解釋技術所識別的重要輸入特征(節點/邊/節點特征)對模型具有判別力,那么當這些特征被移除時,模型的預測結果應該會發生顯著變化。因此,Fidelity被定義為原始預測與遮蔽掉重要輸入特征后的新預測之間的精度之差[50],[77],即衡量兩種預測結果的差異性。
可解釋方法可以看作是一個硬重要性映射 ,其中元素為 0(表示特征不重要)或1(表示特征重要)。對于現有方法,例如ZORRO[51] 和 Causal Screening[53] 等方法,生成的解釋是離散掩碼,可以直接作為重要性映射 。對于 GNNExplainer[42] 和 GraphLime[56] 等方法,重要性分數是連續值,那么可以通過歸一化和閾值化得到重要性地映射。最后,預測精度的Fidelity得分可以計算為:
其中是圖的原始預測,是圖的數量。表示去掉重要輸入特征的補全掩碼,是將新圖輸入訓練好的GNN 時的預測值。指示函數如果和相等則返回1,否則返回0。注意,指標研究的是預測精度的變化。通過對預測概率的關注,概率的Fidelity可以定義為:
其中,代表基于互補掩碼,保留的特征得到的新圖。需要注意的是,監測的是預測概率的變化,比更敏感。對于這兩個指標來說,數值越高,說明解釋結果越好,識別出的判別特征越多。
Fidelity度量通過去除重要節點/邊/節點特征來研究預測變化。相反,Infidelity度量通過保留重要的輸入特征和去除不重要的特征來研究預測變化。直觀地講,重要特征應該包含判別信息,因此即使去掉不重要的特征,它們也應該導致與原始預測相似的預測。從形式上看,度量Infidelity可以計算為:
其中是根據映射保留的重要特征時的新圖,是新的預測值。需要注意的是,對于和來說,數值越低,說明去掉的特征重要信息越少,這樣解釋結果越好
5.2.2 Sparsity
從輸入圖數據的角度來分析解釋性方法的性能,解釋性方法應該是稀疏的,這意味著它們應該捕捉最重要的輸入特征,而忽略不相關的特征,可以用稀疏度(Sparsity)指標衡量這樣個特性。具體來說,它衡量的是被解釋方法選擇為重要特征的分數[50]。形式上,給定圖和它的硬重要性映射 ,稀疏度度量可以計算為:
其中表示中識別的重要輸入特征(節點/邊/節點特征)的數量,表示原始圖 中特征的總數。請注意,數值越高表示解釋方法越稀疏,即往往只捕捉最重要的輸入信息。
5.2.3 Stability
好的解釋應該是穩定的。當對輸入施加小的變化而不影響預測時,解釋應該保持相似。最近提出的穩定性度量標準來衡量一個解釋方法是否穩定[78]。給定一個輸入圖,它的解釋被認為是真實標簽。然后對輸入圖進行小的改變,比如附加新的節點/邊,得到一個新的圖。需要注意的是,和需要有相同的預測。然后得到的解釋,表示為 。通過比較和之間的差異,我們可以計算出穩定性得分。請注意,數值越低表示解釋技術越穩定,對噪聲信息的魯棒性越強。
5.2.4 Accuracy
針對合成數據集提出了精度度量方法[42]、[78]。在合成數據集中,即使不知道GNN是否按照我們預期的方式進行預測,但構建這些數據集的規則,如 graph motifs,可以作為 ground truths 的合理近似。然后對于任何輸入圖,我們都可以將其解釋與這樣的 ground truths進行比較。例如,在研究重要邊的時候,可以研究解釋中的重要邊與 ground truths 的邊的匹配率。這種比較的常用指標包括一般精度、F1得分、ROC-AUC得分。匹配率數值越高,說明解釋結果越接近于 ground truths,認為是較好的解釋方法。
6. Conclusion圖神經網絡近來被廣泛研究,但對圖模型的可解釋性的探討還比較少。
為了研究這些黑箱的潛在機制,人們提出了幾種解釋圖模型的方法,包括XGNN、GNNExplainer等。這些方法從不同的角度和動機來解釋圖模型,但是缺乏對這些方法的全面研究和分析。在這項工作中,作者對這些方法進行了系統全面的調研。首先對現有的GNN解釋方法進行了系統的分類,并介紹了每一類解釋方法背后的關鍵思想。
然后詳細討論了每一種解釋方法,包括方法、內涵、優勢和缺點,還對不同的解釋方法進行了綜合分析。并且介紹和分析了常用的數據集和GNN解釋方法的評價指標。最后從文本數據出發,建立了三個圖形數據集,這些數據集是人類可以理解的,可以直接用于GNN解釋任務bj
編輯:jq
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100715 -
SA
+關注
關注
3文章
128瀏覽量
37956 -
GNN
+關注
關注
1文章
31瀏覽量
6335
原文標題:【GNN綜述】圖神經網絡的解釋性綜述
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
卷積神經網絡與傳統神經網絡的比較
數據智能系列講座第3期—交流式學習:神經網絡的精細與或邏輯與人類認知的對齊






 工商網監
工商網監
評論