


1. 簡介
本文提出了一種新的梯度Boosting框架,將淺層神經(jīng)網(wǎng)絡(luò)作為“弱學(xué)習(xí)者”。在此框架下,我們考慮一般的損失函數(shù),并給出了分類、回歸和排序的具體實例。針對經(jīng)典梯度boosting決策樹貪婪函數(shù)逼近的缺陷,提出了一種完全修正的方法。在多個數(shù)據(jù)集的所有三個任務(wù)中,該模型都比最新的boosting方法都得了來更好的結(jié)果。
2. 背景
盡管在理論上和實踐中都有著無限的可能性,但由于其固有的復(fù)雜性,為新應(yīng)用領(lǐng)域開發(fā)定制的深度神經(jīng)網(wǎng)絡(luò)仍然是出了名的困難。為任何給定的應(yīng)用程序設(shè)計架構(gòu)都需要極大的靈活性,往往需要大量的運氣。
在本文中,我們將梯度增強的能力與神經(jīng)網(wǎng)絡(luò)的靈活性和多功能性相結(jié)合,引入了一種新的建模范式GrowNet,它逐層建立DNN。代替決策樹,我們使用淺層神經(jīng)網(wǎng)絡(luò)作為我們的弱學(xué)習(xí)者,在一個通用的梯度增強框架中,可以應(yīng)用于跨越分類、回歸和排名的各種任務(wù)。
我們做了進(jìn)一步創(chuàng)新,比如在訓(xùn)練過程中加入二階統(tǒng)計數(shù)據(jù),同時還引入了一個全局校正步驟,該步驟已在理論和實際評估中得到證明,對提高效果并對特定任務(wù)進(jìn)行精確微調(diào)。
我們開發(fā)了一種現(xiàn)成的優(yōu)化算法,比傳統(tǒng)的深度神經(jīng)網(wǎng)絡(luò)更快、更容易訓(xùn)練。
我們引入了新的優(yōu)化算法,相較于傳統(tǒng)的NN,它更快也更加易于訓(xùn)練;此外我們還引入了二階統(tǒng)計和全局校正步驟,以提高穩(wěn)定性,并允許針對特定任務(wù)對模型進(jìn)行更細(xì)粒度的調(diào)整。
我們通過實驗評估證明了我們的技術(shù)的有效性,并在三種不同的ML任務(wù)(分類、回歸和學(xué)習(xí)排名)中的多個真實數(shù)據(jù)集上顯示了優(yōu)異的結(jié)果。
3. 相關(guān)工作
3.1 Gradient Boosting Algorithms
Gradient Boosting算法是一種使用數(shù)值優(yōu)化的函數(shù)估計方法,決策樹是梯度提升框架中最常用的函數(shù)(predictive learner)。梯度提升決策樹(GBDT),其中決策樹按順序訓(xùn)練,每棵樹通過擬合負(fù)梯度來建模。本文中,我們將XGBoost作為基線。和傳統(tǒng)的GBDT不一樣,本文提出了Gradient Boosting Neural Network,使用千層的NN來訓(xùn)練gradient boosting。
我們認(rèn)為神經(jīng)網(wǎng)絡(luò)給我們一種優(yōu)于GBDT模型的策略。除了能夠?qū)⑿畔南惹暗念A(yù)測器傳播到下一個預(yù)測器之外,我們可以在加入新的層時糾正之前模型(correct step)。
3.2 Boosted Neural Nets
盡管像決策樹這樣的弱學(xué)習(xí)者在boosting和集成方法中很受歡迎,但是將神經(jīng)網(wǎng)絡(luò)與boosting/集成方法相結(jié)合以獲得比單個大型/深層神經(jīng)網(wǎng)絡(luò)更好的性能已經(jīng)做了大量的工作。在之前開創(chuàng)性工作中,全連接的MLP以一層一層的方式進(jìn)行訓(xùn)練,并添加到級聯(lián)結(jié)構(gòu)的神經(jīng)網(wǎng)絡(luò)中。他們的模型并不完全是一個boosting模型,因為最終的模型是一個單一的多層神經(jīng)網(wǎng)絡(luò)。
在早期的神經(jīng)網(wǎng)絡(luò)設(shè)計中,集成的策略可以帶來巨大的提升,但是早期都是多數(shù)投票,簡單的求均值或者加權(quán)的均值這些策略。在引入自適應(yīng)的boosting算法之后(Adaboost),就有一些工作開始將MLP和boosting相結(jié)合并且取得了很棒的效果。
在最新的一些研究中,AdaNet提出自適應(yīng)地構(gòu)建神經(jīng)網(wǎng)絡(luò)層,除了學(xué)習(xí)網(wǎng)絡(luò)的權(quán)重,AdaNet調(diào)整網(wǎng)絡(luò)的結(jié)構(gòu)以及它的增長過程也有理論上的證明。AdaNet的學(xué)習(xí)過程是boosting式的,但是最終的模型是一個單一的神經(jīng)網(wǎng)絡(luò),其最終輸出層連接到所有的底層。與AdaNet不同的是,我們以梯度推進(jìn)的方式訓(xùn)練每一個弱學(xué)習(xí)者,從而減少了entangled的訓(xùn)練。最后的預(yù)測是所有弱學(xué)習(xí)者輸出的加權(quán)和。我們的方法還提供了一個統(tǒng)一的平臺來執(zhí)行各種ML任務(wù)。
最近有很多工作來解釋具有數(shù)百層的深度殘差神經(jīng)網(wǎng)絡(luò)的成功,表明它們可以分解為許多子網(wǎng)絡(luò)的集合。
4. 模型
在每一個boosting步驟中,我們使用當(dāng)前迭代倒數(shù)第二層的輸出來增強原始輸入特性。
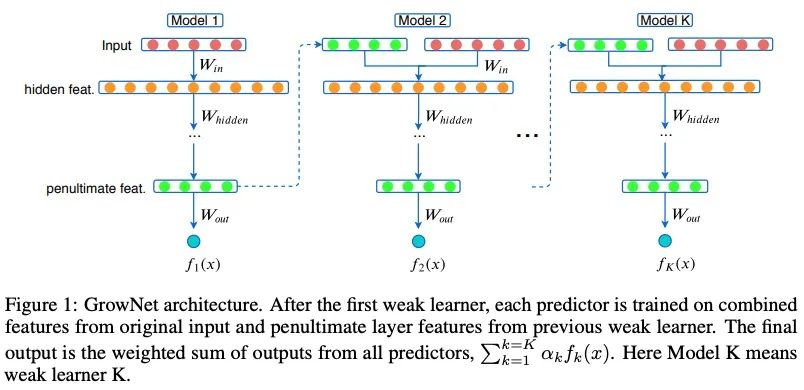
通過使用當(dāng)前殘差的增強機制,將增強后的特征集作為輸入來訓(xùn)練下一個弱學(xué)習(xí)者。模型的最終輸出是所有這些順序訓(xùn)練模型的得分的加權(quán)組合。
4.1 Gradient Boosting Neural Network: GrowNet
我們假設(shè)有一個數(shù)據(jù)集,里面有個維度的特征空間,,GrowNet使用個加法函數(shù)來預(yù)測最終的輸出:
其中是多層感知機的空間,是步長,每個函數(shù)表示一個獨立的,淺層的網(wǎng)絡(luò),對于一個給定的樣本,模型在GrowNet中計算的加權(quán)和。
我們令是一個可微的凸損失函數(shù),我們的目標(biāo)是學(xué)習(xí)一個函數(shù)集合(淺層的網(wǎng)絡(luò)),我們的目標(biāo)就是學(xué)習(xí)一個函數(shù)的集合來最小化下面的等式:
和GBDT很像,此處我們采用加法的形式對其進(jìn)行訓(xùn)練,我們令:
為GrowNet關(guān)于樣本在第步輸出,我們貪心地搜索下一個弱學(xué)習(xí)器,,即:
此外,采用了損失函數(shù)的泰勒展開,來降低計算復(fù)雜度。由于二階優(yōu)化技術(shù)優(yōu)于一階優(yōu)化技術(shù),收斂步驟少,因此,我們用Newton-Raphson步長對模型進(jìn)行了訓(xùn)練。因此,無論ML任務(wù)如何,通過對GrowtNet輸出的二階梯度進(jìn)行回歸,優(yōu)化各個模型參數(shù)。關(guān)于弱學(xué)習(xí)器的目標(biāo)函數(shù)可以簡化為:
其中,和分別是目標(biāo)函數(shù)在處的一階和二階梯度。
4.2 Corrective Step (C/S)
傳統(tǒng)的boosting框架,每個弱學(xué)習(xí)器都是貪心學(xué)習(xí)的,這意味著只有第個弱學(xué)習(xí)器是不變的。
短視學(xué)習(xí)過程可能會導(dǎo)致模型陷入局部極小,固定的增長率會加劇這個問題。因此,我們實施了一個糾正步驟來解決這個問題。
在糾正步驟中,我們允許通過反向傳播更新先前t-1弱學(xué)習(xí)者的參數(shù),而不是修復(fù)先前t-1弱學(xué)習(xí)者。
此外,我們將boosting rate 納入模型參數(shù),并通過修正步驟自動更新。
除了獲得更好的性能之外,這一舉措可以讓我們避免調(diào)整一個微妙的參數(shù)。
C/S還可以被解釋為一個正則化器,以減輕弱學(xué)習(xí)器之間的相關(guān)性,因為在糾正步驟中,我們主要的訓(xùn)練目標(biāo)變成了僅對原始輸入的特定任務(wù)損失函數(shù)。這一步的有用性在論文《Learning nonlinear functions using regularized greedy forest》中對梯度提升決策樹模型進(jìn)行了實證和理論研究。
5. 模型應(yīng)用
5.1 回歸的GrowNet
此處我們以MSE為案例。
我們對數(shù)據(jù)集 通過最小平方回歸訓(xùn)練下一個弱分類器,在Corrective Step,在GrowNet中對所有模型參數(shù)都可以使用MSE損失進(jìn)行優(yōu)化。
5.2 分類的GrowNet
為了便于說明,讓我們考慮二元交叉熵?fù)p失函數(shù);注意,可以使用任何可微損失函數(shù)。我們選擇標(biāo)簽,這樣我們的一階和二階的梯度和就是:
下一個弱學(xué)習(xí)器使用二階梯度統(tǒng)計通過使用最小平方回歸進(jìn)行擬合。在 corrective step,所有疊加的預(yù)測函數(shù)的參數(shù)通過使用二元交叉熵?fù)p失函數(shù)在整個模型重新訓(xùn)練。這一步根據(jù)手上任務(wù)的主要目標(biāo)函數(shù),即在這種情況下的分類,稍微修正權(quán)重。
5.3 LTR的GrowNet
假設(shè)對于某個給定的query,一對文件和被選擇。假設(shè)我們對于每個文檔和有一個特征向量,我們令和表示對于樣本和的模型輸出,一個傳統(tǒng)的pairwise loss可以被表示為下面的形式:
其中表示文件相關(guān)性的差值。是sigmoid函數(shù)。因為損失函數(shù)是堆成的,它的梯度可以通過下面的方式計算得到:
我們用表示下標(biāo)對的集合,其中對于某個query,我們希望排名不同于,對于某個特定的文件,損失函數(shù)以及它的一階以及二階統(tǒng)計函數(shù)可以通過下面的形式獲得。
6. 實驗
6.1 實驗效果
模型中加入的預(yù)測函數(shù)都是具有兩個隱層的多層感知器。我們將隱藏層單元的數(shù)量設(shè)置為大約輸入特征維數(shù)的一半或相等。當(dāng)模型開始過擬合時,更多的隱藏層會降低效果。我們實驗中采用了40個加法函數(shù)對三個任務(wù)進(jìn)行測試,并根據(jù)驗證結(jié)果選擇了測試時間內(nèi)的弱學(xué)習(xí)器個數(shù)。Boosting rate最初設(shè)置為1,并在校正步驟中自動調(diào)整。我們只訓(xùn)練了每個預(yù)測函數(shù)一個epoch,整個模型在校正過程中使用Adam optimizer也訓(xùn)練了一個epoch。epoch的個數(shù)在ranking任務(wù)中被設(shè)置為2;
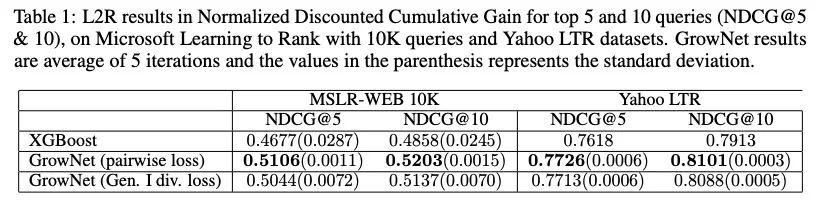
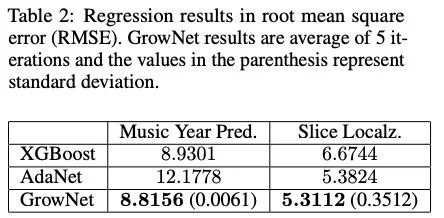
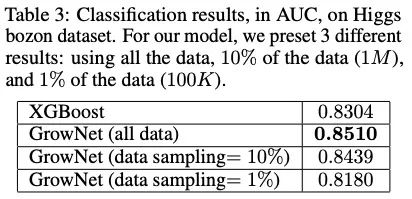
該方法在諸多方案上都取得了好于XGBoost的效果。
6.2 消融實驗
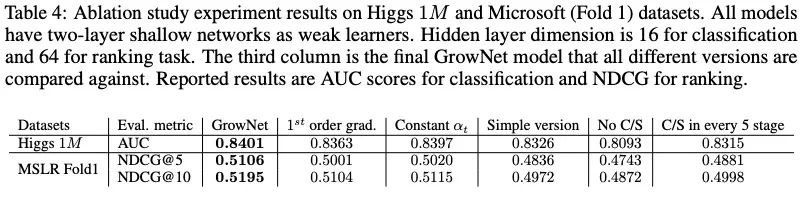
C/S的影響非常大;C/S模式緩解了learner之間潛在的相關(guān)性;
二階導(dǎo)數(shù)是有必要的;
自動化學(xué)習(xí)是有價值的;我們加了boosting rate ,它是自動調(diào)整的,不需要任何調(diào)整;
6.3 隱藏單元的影響
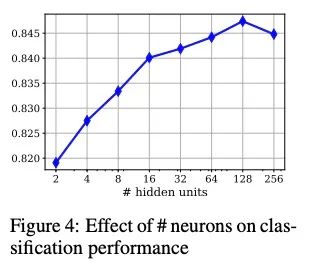
改變隱藏單元的數(shù)量對效果的影響較小。
測試了具有不同隱藏單元的最終模型(具有兩個隱藏層的弱學(xué)習(xí)者)。Higgs數(shù)據(jù)有28個特征,我們用2、4、8、16、32、64、128和256個隱藏單元對模型進(jìn)行了測試。隱層維度越小,弱學(xué)習(xí)者獲得的信息傳播越少。另一方面,擁有大量的單元也會導(dǎo)致在某個點之后過度擬合。
上圖顯示了這個實驗在Higgs 1M數(shù)據(jù)上的測試AUC分?jǐn)?shù)。最高的AUC為0.8478,只有128個單元,但當(dāng)數(shù)量增加到256個單元時,效果會受到影響。
6.4 GrowNet versus DNN
如果我們把所有這些淺層網(wǎng)絡(luò)合并成一個深神經(jīng)網(wǎng)絡(luò),會發(fā)生什么?
這種方法存在幾個問題:
對DNN參數(shù)進(jìn)行優(yōu)化非常耗時,如隱藏層數(shù)、每個隱藏層單元數(shù)、總體架構(gòu)、Batch normalization、dropout等;
DNN需要巨大的計算能力,總體運行速度較慢。我們將我們的模型(30個弱學(xué)習(xí)器)與DNN進(jìn)行了5、10、20和30個隱藏層配置的比較。
在1000個epoch,在Higgs的1M數(shù)據(jù)上,最好的DNN(10個隱藏層)得到0.8342,每個epoch花費11秒。DNN在900個epoch時取得了這一成績(最好)。GrowtNet在相同的配置下取得了0.8401 AUC;
7. 小結(jié)
本文提出了GrowNet,它可以利用淺層神經(jīng)網(wǎng)絡(luò)作為梯度推進(jìn)框架中的“弱學(xué)習(xí)者”。這種靈活的網(wǎng)絡(luò)結(jié)構(gòu)使我們能夠在統(tǒng)一的框架下執(zhí)行多個機器學(xué)習(xí)任務(wù),同時結(jié)合二階統(tǒng)計、校正步驟和動態(tài)提升率,彌補傳統(tǒng)梯度提升決策樹的缺陷。
我們通過消融研究,探討了神經(jīng)網(wǎng)絡(luò)作為弱學(xué)習(xí)者在boosting范式中的局限性,分析了每個生長網(wǎng)絡(luò)成分對模型性能和收斂性的影響。結(jié)果表明,與現(xiàn)有的boosting方法相比,該模型在回歸、分類和學(xué)習(xí)多數(shù)據(jù)集排序方面具有更好的性能。我們進(jìn)一步證明,GrowNet在這些任務(wù)中是DNNs更好的替代品,因為它產(chǎn)生更好的性能,需要更少的訓(xùn)練時間,并且更容易調(diào)整。
原文標(biāo)題:【前沿】Purdue&UCLA提出梯度Boosting網(wǎng)絡(luò),效果遠(yuǎn)好于XGBoost模型!
文章出處:【微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4812瀏覽量
103327 -
框架
+關(guān)注
關(guān)注
0文章
404瀏覽量
17861
原文標(biāo)題:【前沿】Purdue&UCLA提出梯度Boosting網(wǎng)絡(luò),效果遠(yuǎn)好于XGBoost模型!
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
神經(jīng)網(wǎng)絡(luò)壓縮框架 (NNCF) 中的過濾器修剪統(tǒng)計數(shù)據(jù)怎么查看?
如何優(yōu)化BP神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)率
什么是BP神經(jīng)網(wǎng)絡(luò)的反向傳播算法
BP神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)的關(guān)系
人工神經(jīng)網(wǎng)絡(luò)的原理和多種神經(jīng)網(wǎng)絡(luò)架構(gòu)方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論