") 分享pandas中超級好用的str矢量化字符串函數(shù)
分享pandas中超級好用的str矢量化字符串函數(shù)
本文介紹
你有沒有這樣一種感覺,為什么到自己手上的數(shù)據(jù),總是亂七八糟? 作為一個數(shù)據(jù)分析師來說,數(shù)據(jù)清洗是必不可少的環(huán)節(jié)。有時候由于數(shù)據(jù)太亂,往往需要花費(fèi)我們很多時間去處理它。因此掌握更多的數(shù)據(jù)清洗方法,會讓你的能力調(diào)高100倍。 本文基于此,講述pandas中超級好用的str矢量化字符串函數(shù),學(xué)了之后,瞬間感覺自己的數(shù)據(jù)清洗能力提高了。
1個數(shù)據(jù)集,16個Pandas函數(shù)
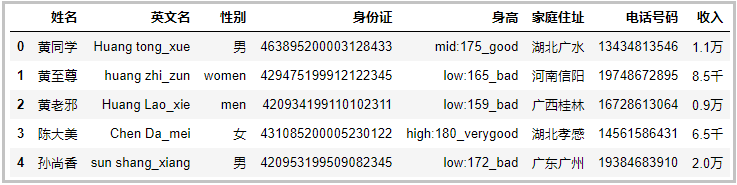
數(shù)據(jù)集是黃同學(xué)精心為大家編造,只為了幫助大家學(xué)習(xí)到知識。數(shù)據(jù)集如下:
① cat函數(shù):用于字符串的拼接

② contains:判斷某個字符串是否包含給定字符
df["家庭住址"].str.contains("廣") 結(jié)果如下:

③ startswith/endswith:判斷某個字符串是否以…開頭/結(jié)尾
#第一個行的“黃偉”是以空格開頭的 df["姓名"].str.startswith("黃") df["英文名"].str.endswith("e") 結(jié)果如下:

④ count:計(jì)算給定字符在字符串中出現(xiàn)的次數(shù)
df["電話號碼"].str.count("3") 結(jié)果如下:

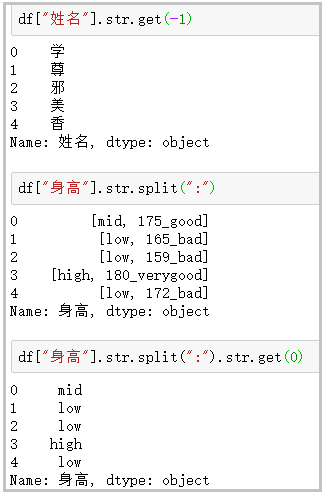
⑤ get:獲取指定位置的字符串
df["姓名"].str.get(-1) df["身高"].str.split(":") df["身高"].str.split(":").str.get(0) 結(jié)果如下:
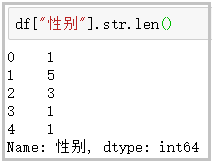
⑥ len:計(jì)算字符串長度
df["性別"].str.len() 結(jié)果如下:
⑦ upper/lower:英文大小寫轉(zhuǎn)換
df["英文名"].str.upper() df["英文名"].str.lower() 結(jié)果如下:

⑧ pad+side參數(shù)/center:在字符串的左邊、右邊或左右兩邊添加給定字符
df["家庭住址"].str.pad(10,fillchar="*")#相當(dāng)于ljust() df["家庭住址"].str.pad(10,side="right",fillchar="*")#相當(dāng)于rjust() df["家庭住址"].str.center(10,fillchar="*") 結(jié)果如下:

⑨ repeat:重復(fù)字符串幾次
df["性別"].str.repeat(3) 結(jié)果如下:

⑩ slice_replace:使用給定的字符串,替換指定的位置的字符
df["電話號碼"].str.slice_replace(4,8,"*"*4) 結(jié)果如下:

? replace:將指定位置的字符,替換為給定的字符串
df["身高"].str.replace(":","-") 結(jié)果如下:
? replace:將指定位置的字符,替換為給定的字符串(接受正則表達(dá)式)
replace中傳入正則表達(dá)式,才叫好用;
先不要管下面這個案例有沒有用,你只需要知道,使用正則做數(shù)據(jù)清洗多好用;
df["收入"].str.replace("d+.d+","正則") 結(jié)果如下:

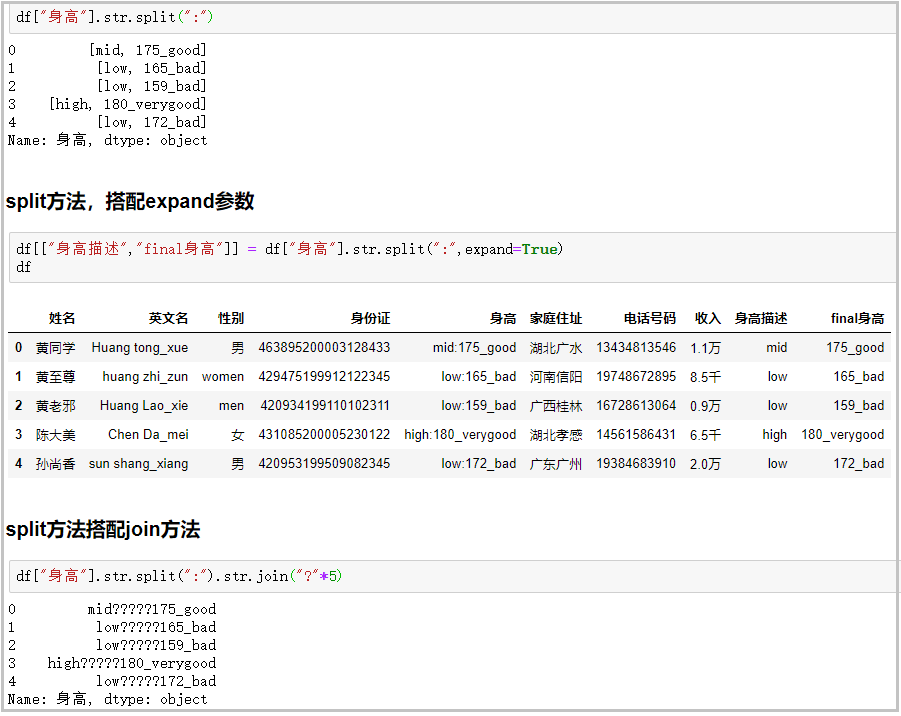
? split方法+expand參數(shù):搭配join方法功能很強(qiáng)大
#普通用法 df["身高"].str.split(":") #split方法,搭配expand參數(shù) df[["身高描述","final身高"]]=df["身高"].str.split(":",expand=True) df #split方法搭配join方法 df["身高"].str.split(":").str.join("?"*5) 結(jié)果如下:
? strip/rstrip/lstrip:去除空白符、換行符
df["姓名"].str.len() df["姓名"]=df["姓名"].str.strip() df["姓名"].str.len() 結(jié)果如下:

? findall:利用正則表達(dá)式,去字符串中匹配,返回查找結(jié)果的列表
findall使用正則表達(dá)式,做數(shù)據(jù)清洗,真的很香!
df["身高"] df["身高"].str.findall("[a-zA-Z]+") 結(jié)果如下:

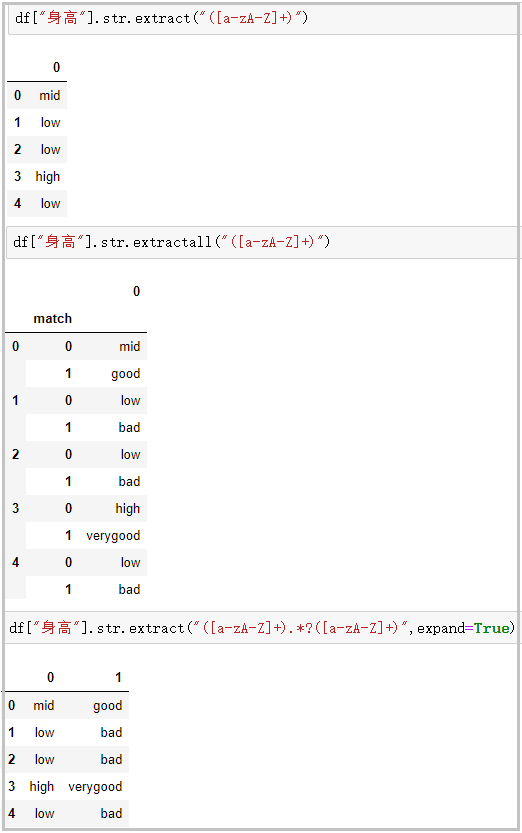
? extract/extractall:接受正則表達(dá)式,抽取匹配的字符串(一定要加上括號)
df["身高"].str.extract("([a-zA-Z]+)") #extractall提取得到復(fù)合索引 df["身高"].str.extractall("([a-zA-Z]+)") #extract搭配expand參數(shù) df["身高"].str.extract("([a-zA-Z]+).*?([a-zA-Z]+)",expand=True) 結(jié)果如下:
今天的文章,就講述到這里,希望能夠?qū)δ阌兴鶐椭?/p>
編輯:jq
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7002瀏覽量
88943 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4327瀏覽量
62573 -
矢量化
+關(guān)注
關(guān)注
0文章
5瀏覽量
6202
原文標(biāo)題:詳解16個 pandas 函數(shù),讓你的 “數(shù)據(jù)清洗” 能力提高100倍!
文章出處:【微信號:DBDevs,微信公眾號:數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
base64字符串轉(zhuǎn)換為二進(jìn)制文件
MATLAB(5)--字符串處理
labview字符串數(shù)組轉(zhuǎn)化為數(shù)值數(shù)組
labview字符串如何轉(zhuǎn)換為16進(jìn)制字符串
labview中如何實(shí)現(xiàn)字符串換行
labview中常用的字符串函數(shù)有哪些?
labview字符串的四種表示各有什么特點(diǎn)
如何提取串口接收字符串數(shù)組里的某個字符串?
C語言字符串編譯函數(shù)介紹






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論