

1.Transformer為何使用多頭注意力機制?(為什么不使用一個頭)
答:多頭可以使參數矩陣形成多個子空間,矩陣整體的size不變,只是改變了每個head對應的維度大小,這樣做使矩陣對多方面信息進行學習,但是計算量和單個head差不多。
2.Transformer為什么Q和K使用不同的權重矩陣生成,為何不能使用同一個值進行自身的點乘?
答:請求和鍵值初始為不同的權重是為了解決可能輸入句長與輸出句長不一致的問題。并且假如QK維度一致,如果不用Q,直接拿K和K點乘的話,你會發現attention score 矩陣是一個對稱矩陣。因為是同樣一個矩陣,都投影到了同樣一個空間,所以泛化能力很差。
3.Transformer計算attention的時候為何選擇點乘而不是加法?兩者計算復雜度和效果上有什么區別?
答:K和Q的點乘是為了得到一個attention score 矩陣,用來對V進行提純。K和Q使用了不同的W_k, W_Q來計算,可以理解為是在不同空間上的投影。正因為 有了這種不同空間的投影,增加了表達能力,這樣計算得到的attention score矩陣的泛化能力更高。
4.為什么在進行softmax之前需要對attention進行scaled(為什么除以dk的平方根),并使用公式推導進行講解
答:假設 Q 和 K 的均值為0,方差為1。它們的矩陣乘積將有均值為0,方差為dk,因此使用dk的平方根被用于縮放,因為,Q 和 K 的矩陣乘積的均值本應該為 0,方差本應該為1,這樣可以獲得更平緩的softmax。當維度很大時,點積結果會很大,會導致softmax的梯度很小。為了減輕這個影響,對點積進行縮放。
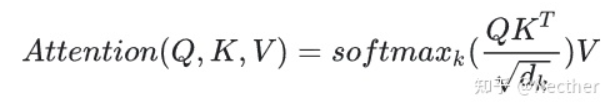
5.在計算attention score的時候如何對padding做mask操作?
答:對需要mask的位置設為負無窮,再對attention score進行相加
6.為什么在進行多頭注意力的時候需要對每個head進行降維?
答:將原有的高維空間轉化為多個低維空間并再最后進行拼接,形成同樣維度的輸出,借此豐富特性信息,降低了計算量
7.大概講一下Transformer的Encoder模塊?
答:輸入嵌入-加上位置編碼-多個編碼器層(每個編碼器層包含全連接層,多頭注意力層和點式前饋網絡層(包含激活函數層))
8.為何在獲取輸入詞向量之后需要對矩陣乘以embedding size的開方?
embedding matrix的初始化方式是xavier init,這種方式的方差是1/embedding size,因此乘以embedding size的開方使得embedding matrix的方差是1,在這個scale下可能更有利于embedding matrix的收斂。
9.簡單介紹一下Transformer的位置編碼?有什么意義和優缺點?
答:因為self-attention是位置無關的,無論句子的順序是什么樣的,通過self-attention計算的token的hidden embedding都是一樣的,這顯然不符合人類的思維。因此要有一個辦法能夠在模型中表達出一個token的位置信息,transformer使用了固定的positional encoding來表示token在句子中的絕對位置信息。
10.你還了解哪些關于位置編碼的技術,各自的優缺點是什么?
答:相對位置編碼(RPE)1.在計算attention score和weighted value時各加入一個可訓練的表示相對位置的參數。2.在生成多頭注意力時,把對key來說將絕對位置轉換為相對query的位置3.復數域函數,已知一個詞在某個位置的詞向量表示,可以計算出它在任何位置的詞向量表示。前兩個方法是詞向量+位置編碼,屬于亡羊補牢,復數域是生成詞向量的時候即生成對應的位置信息。
11.簡單講一下Transformer中的殘差結構以及意義。
答:encoder和decoder的self-attention層和ffn層都有殘差連接。反向傳播的時候不會造成梯度消失。
12.為什么transformer塊使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
答:多頭注意力層和激活函數層之間。CV使用BN是認為channel維度的信息對cv方面有重要意義,如果對channel維度也歸一化會造成不同通道信息一定的損失。而同理nlp領域認為句子長度不一致,并且各個batch的信息沒什么關系,因此只考慮句子內信息的歸一化,也就是LN。
13.簡答講一下BatchNorm技術,以及它的優缺點。
答:批歸一化是對每一批的數據在進入激活函數前進行歸一化,可以提高收斂速度,防止過擬合,防止梯度消失,增加網絡對數據的敏感度。
14.簡單描述一下Transformer中的前饋神經網絡?使用了什么激活函數?相關優缺點?
答:輸入嵌入-加上位置編碼-多個編碼器層(每個編碼器層包含全連接層,多頭注意力層和點式前饋網絡層(包含激活函數層))-多個解碼器層(每個編碼器層包含全連接層,多頭注意力層和點式前饋網絡層)-全連接層,使用了relu激活函數
15.Encoder端和Decoder端是如何進行交互的?
答:通過轉置encoder_ouput的seq_len維與depth維,進行矩陣兩次乘法,即q*kT*v輸出即可得到target_len維度的輸出
16.Decoder階段的多頭自注意力和encoder的多頭自注意力有什么區別?
答:Decoder有兩層mha,encoder有一層mha,Decoder的第二層mha是為了轉化輸入與輸出句長,Decoder的請求q與鍵k和數值v的倒數第二個維度可以不一樣,但是encoder的qkv維度一樣。
17.Transformer的并行化提現在哪個地方?
答:Transformer的并行化主要體現在self-attention模塊,在Encoder端Transformer可以并行處理整個序列,并得到整個輸入序列經過Encoder端的輸出,但是rnn只能從前到后的執行
18.Decoder端可以做并行化嗎?
訓練的時候可以,但是交互的時候不可以
19.簡單描述一下wordpiece model 和 byte pair encoding,有實際應用過嗎?
答“傳統詞表示方法無法很好的處理未知或罕見的詞匯(OOV問題)
傳統詞tokenization方法不利于模型學習詞綴之間的關系”BPE(字節對編碼)或二元編碼是一種簡單的數據壓縮形式,其中最常見的一對連續字節數據被替換為該數據中不存在的字節。后期使用時需要一個替換表來重建原始數據。優點:可以有效地平衡詞匯表大小和步數(編碼句子所需的token次數)。
缺點:基于貪婪和確定的符號替換,不能提供帶概率的多個分片結果。
20.Transformer訓練的時候學習率是如何設定的?Dropout是如何設定的,位置在哪里?Dropout 在測試的需要有什么需要注意的嗎?
LN是為了解決梯度消失的問題,dropout是為了解決過擬合的問題。在embedding后面加LN有利于embedding matrix的收斂。
21.bert的mask為何不學習transformer在attention處進行屏蔽score的技巧?
答:BERT和transformer的目標不一致,bert是語言的預訓練模型,需要充分考慮上下文的關系,而transformer主要考慮句子中第i個元素與前i-1個元素的關系。
責任編輯:lq
-
編碼器
+關注
關注
45文章
3780瀏覽量
137300 -
矩陣
+關注
關注
1文章
434瀏覽量
35077 -
Transformer
+關注
關注
0文章
151瀏覽量
6413
原文標題:21個Transformer面試題的簡單回答
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【硬件方向】名企面試筆試真題:大疆創新校園招聘筆試題
硬件工程師面試必看試題(經典)
【面試題】人工智能工程師高頻面試題匯總:概率論與統計篇(題目+答案)
transformer專用ASIC芯片Sohu說明

Redis使用重要的兩個機制:Reids持久化和主從復制

【面試題】人工智能工程師高頻面試題匯總:機器學習深化篇(題目+答案)
【面試題】人工智能工程師高頻面試題匯總:Transformer篇(題目+答案)
人工智能工程師高頻面試題匯總——機器學習篇


自動駕駛中一直說的BEV+Transformer到底是個啥?

程序員去面試只需一個技能征服所有面試官!






 工商網監
工商網監

評論