 了解信息抽取必須要知道關系抽取
了解信息抽取必須要知道關系抽取
本文主要詳細解讀關系抽取SOTA論文Two are Better than One:Joint Entity and Relation Extraction with Table-Sequence Encoders[1], 順帶簡要介紹關系抽取的背景,方便完全不了解童鞋。
信息抽取
我們說的信息抽取一般是指從文本數據中抽取特定數據結構信息的一種手段。對于不同結構形式的數據如結構化文本,半結構化文本,自由文本,有各自對應的方案,其中從自由文本中抽取難度最大。總之,我們的目的是希望在海量文本中,快速抽出我們關注的事實。
了解信息抽取必須要知道關系抽取。
關系抽取
大部分情況下,我們喜歡用三元組的數據結構來描述抽取到的信息
三元組
三元組的表達能力非常豐富,幾乎所有事情都可以自然或者強行的表達成三元組,比如隨便一句”今天天氣真冷“ 表達為天氣-狀態-冷。
三元組與后續的知識圖譜工作非常適配,如Neo4j等圖數據庫就是以三元組為存儲單位,圖譜的查詢推斷等工具使用三元組比普通的關系型數據庫來的方便的多。
三元組千千萬,我應該怎么抽?
Schema
當我們拿到一個信息抽取的任務,需要明確我們抽取的是什么,”今天天氣真冷“,我們要抽的天氣的狀態天氣-狀態-冷,而非今天-氣候-冷(雖然也可以這樣抽),因此一般會首先定義好我們要抽取的數據結構模式shcema, 會確定謂詞以及主語并與的類型
一個三元組schema的例子,其中Subject_type代表主語類型,Predicate是謂詞,Object_type指賓語類型:
Subject_type:人物 Predicate:出生地 Object_type:地點
確定了schema,我們一般如何抽取呢?
常規RE方案
目前主流關系抽取一般兩種解決方法
pipline兩步走:將關系抽取分解為NER任務和分類任務,NER任務標注主語或賓語,分類主要針對定義的schema中的有限個謂詞進行分類。根據具體任務不同,有些可能是兩步走或者三步走,pipline任務的順序先分類還是先標注也會有差異
Pipline優勢:每一步分別針對各個任務進行,表征是task-specific, 相對來說精度較高
Pipline缺陷:- 任務有順序會存在誤差傳遞問題,即在預測時下一步任務會受上一步誤差影響,而在訓練階段沒有這種誤差,因此存在訓練和預測階段的gap- 分開的任務在一句話中多個實體關系時,比較難解決實體和關系的對應問題,以及重疊關系
joint learning:joint learing可以理解為采用多任務的方式,同時進行NER和關系分類任務, 在眾多joint learning中最出眾的是采用tabel filled 方式,即任務的輸出是filled一張有text-sequence構成的表,在表中的位置表達除了詞與詞的連接,該位置的標注則標出了謂語(如下圖)
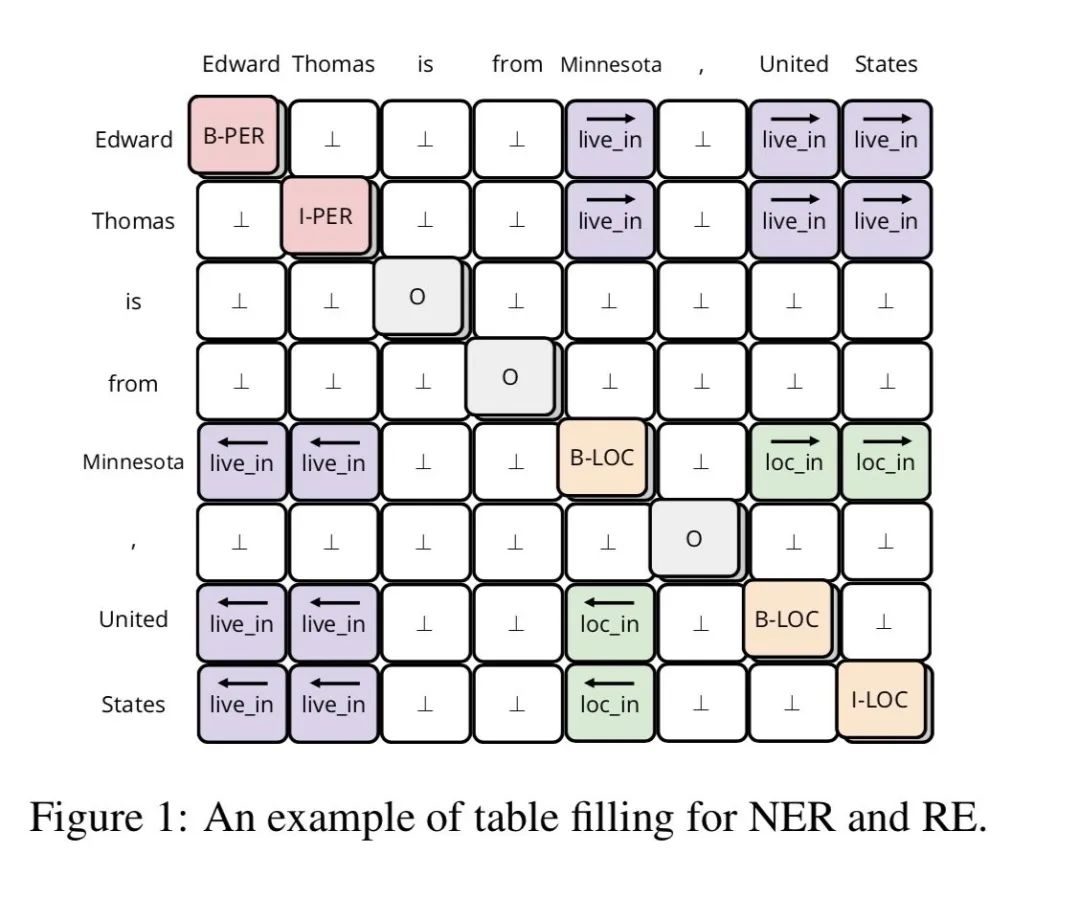
優勢:1. 兩個任務的表征有交互作用可能輔助任務的學習2. 不用訓練多個模型,一個模型解決問題,不存在訓練與預測時的gap
缺陷:1. 兩個任務的表征可能沖突,影響任務效果2. 解決了主謂賓之間的對應關系,無法解決重疊問題3. Fill table本質仍然是轉成sequence來fill,未能充分利用table結構信息(下文會解釋)
下面重點解讀table fill方式的一篇SOTA,解決了joint learning的多任務表征沖突以及為利用table結構信息
RE with Table Sequence
終于來到本篇的主題啦,為了解決一般filled table的問題, 作者提出table-sequence encoder的方法,分別對table和sequence做表征,本文的最大貢獻在于
分別對table和sequence做表征(encoder),并設計了一個Table-Guided Attention來對table和sequence進行交互,這樣即不會完全共享表征導致對不同的任務表征沖突,也不會丟失表征的相互指導作用
在table encoder中采用多維GRU來捕獲更多的句子結構信息
在架構上table encoder和 sequence encoder多層交互
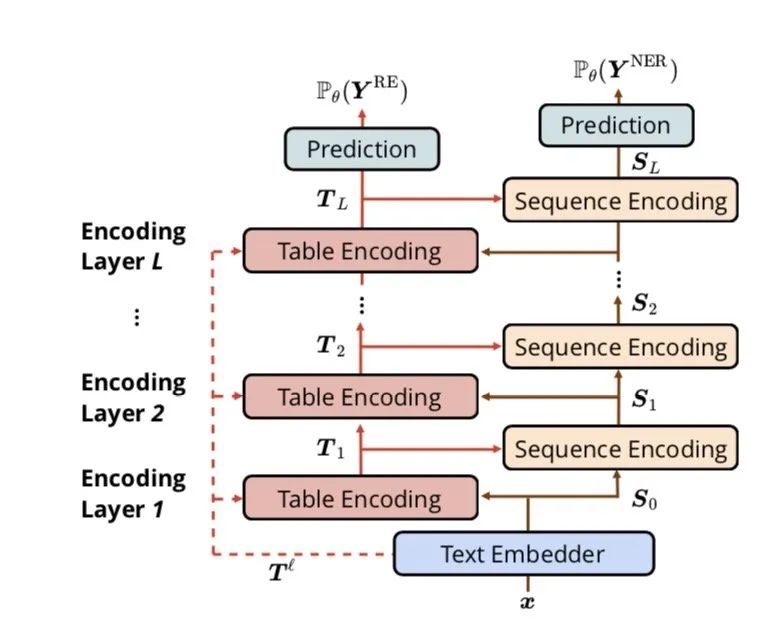
下面仔細介紹各個部分,看看它是如何神奇做到SOTA的
Text Embedder
在上圖的結構圖中,Text Embedder采用類似FLAT分別做了基于lstm的char()和word(),以及基于bert的word ()作為預訓練的embedding ,并拼接起來
圖中
Table Encoder
整個Table Encoder部分由多個Table Encoding的單元組成,每個Encoding單元的輸入分別是起始輸入,對應senquence結構的輸入,以及上一個Tabel Encoding單元的輸出,Table Encoding 采用MDRNN結構提取輸入的特征信息,作者在這選擇MDGRU(多維度GRU),tabel結構本身有2維,加上前后層實際有4維,但是層的維度信息單向流動,實際上是只用到了3個方向()
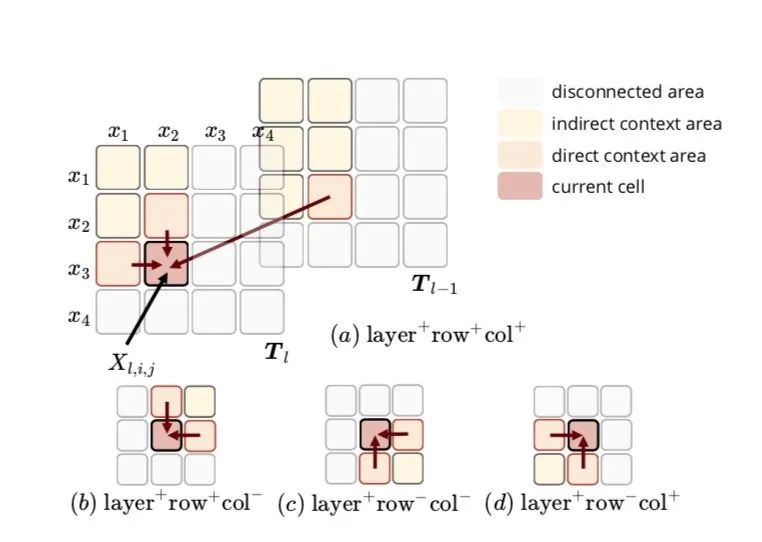
如圖所示,是來自sequence的輸入,作者分別測了使用所有方向和分別使用幾個方向,發現上圖中a,c效果類似,這種多維GRU全面的考慮了整個table的結構信息,即一個詞的狀態跟其他所有詞的狀態相關,并且受其他詞的不同程度的影響,這種影響程度由GRU門控機制控制
Sequence Encoder
sequence Encoder 也由多個sequence encoding夠成,sequence encoding結構直接采用transformer中的encoder
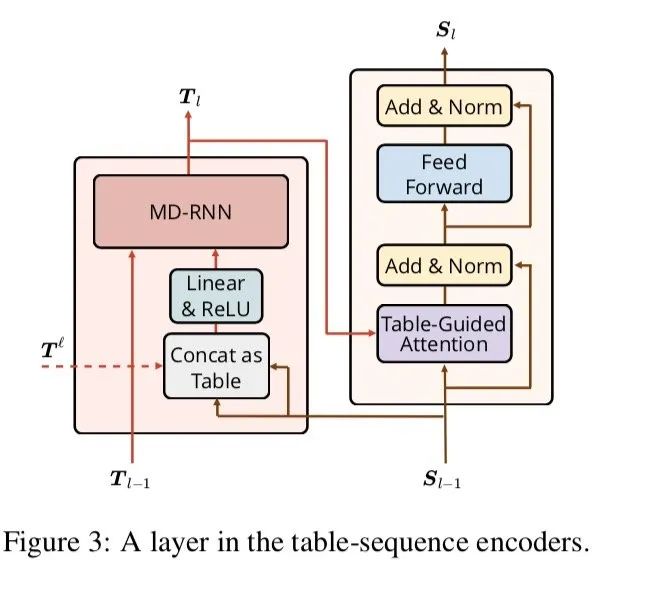
只不過將其中的self attention替換為table-guide attention,這種attention的改造非常巧妙,能更好捕捉word-word之間的關系
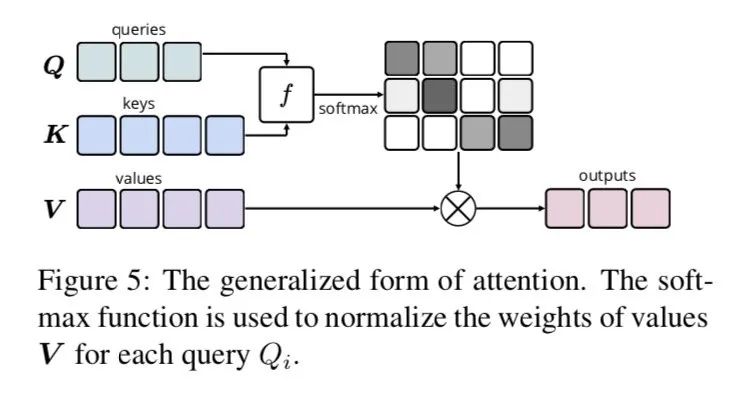
正常的dot attention如上圖
Table-Guided attention具體來說:
為參數矩陣
采用加性
是table encoder中的table的隱藏節點,該節點由多個方向的經過GRU編碼得到,不管是哪個方向它的來源始終是由構造而來,理論上是可以由擬合而來,因此這里直接由 來代替 ,也就是這個attention,其實是計算了table 結構中各個位置對該的權重,是一個四面八方attention
剩下就是transform中正常的LayerNorm 和殘差結構了
輸出和loss
輸出比較常規,loss采用常規
輸出:
loss:
實驗 and 效果
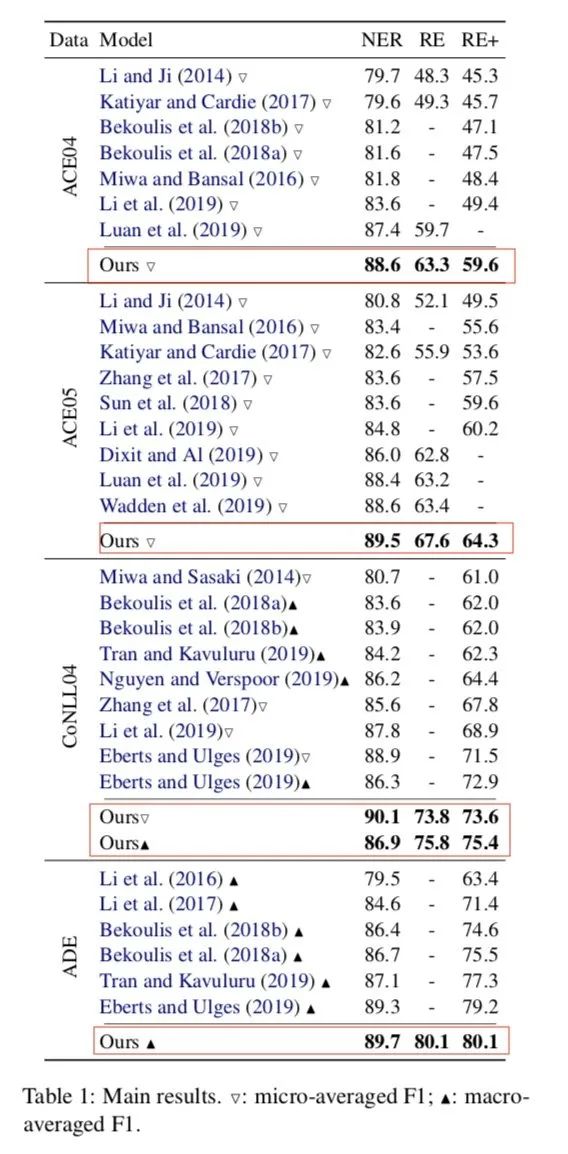
作者在各個數據集上進行實驗,對比各個目前SOTA分別有一定的提高,且時效果最佳,模型參數量不到5M,要什么自行車,附上開源地址[2],作者的代碼與論文在attention計算有一丟丟不一致,但是并不影響效果
責任編輯:lq
-
數據庫
+關注
關注
7文章
3794瀏覽量
64362 -
Gru
+關注
關注
0文章
12瀏覽量
7477 -
數據結構
+關注
關注
3文章
573瀏覽量
40123
原文標題:關系抽取一步到位!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
請問AMC1203文檔中的OSC過采樣率和sinc3濾波器中的抽取率是不是同一個概念?
軌道交通行業 ICY DOCK硬盤抽取盒解決方案

ADS1299用ADS采集數據,ADS可以不抽取看原始得數據嗎?
求助,關于AMC1306M25抽取率OSR的疑問求解
TLV320AIC3254內部中的ADC處理模塊和minidsp到底是什么關系?
有獎問卷:隨機抽取 30 名用戶送出快充數據線
求助,AD7190關于Σ-Δ ADC其中的抽取濾波器的數據轉換問題求解
防水和防振動功能2.5 英寸SAS/SATA硬盤抽取盒 非常適合車載數據存儲

學習鴻蒙必須要知道的幾個名詞

ICY DOCK Expresscage MB038SP-B硬盤抽取盒評測

用STM8做一個用于抽取頻譜的東西, 如何采樣128個點用于FFT數據計算?
企業級裝機必備推薦 不用拆機的4盤位U.2 硬盤抽取盒

【概念產品 CP133-1】2 盤位 EDSFF E1.S NVMe SSD 硬盤抽取盒






 工商網監
工商網監
評論