


DeBERTa刷新了GLUE的榜首,本文解讀一下DeBERTa在BERT上有哪些改造
DeBERTa對(duì)BERT的改造主要在三點(diǎn)
分散注意力機(jī)制
為了更充分利用相對(duì)位置信息,輸入的input embedding不再加入pos embedding, 而是input在經(jīng)過transformer編碼后,在encoder段與“decoder”端 通過相對(duì)位置計(jì)算分散注意力
增強(qiáng)解碼器(有點(diǎn)迷)
為了解決預(yù)訓(xùn)練和微調(diào)時(shí),因?yàn)槿蝿?wù)的不同而預(yù)訓(xùn)練和微調(diào)階段的gap,加入了一個(gè)增強(qiáng)decoder端,這個(gè)decoder并非transformer的decoder端(需要decoder端有輸入那種),只是直觀上起到了一個(gè)decoder作用
解碼器前接入了絕對(duì)位置embedding,避免只有相對(duì)位置而丟失了絕對(duì)位置embedding
其實(shí)本質(zhì)就是在原始BERT的倒數(shù)第二層transformer中間層插入了一個(gè)分散注意力計(jì)算
訓(xùn)練trick
訓(xùn)練時(shí)加入了一些數(shù)據(jù)擾動(dòng)
mask策略中不替換詞,變?yōu)樘鎿Q成詞的pos embedding
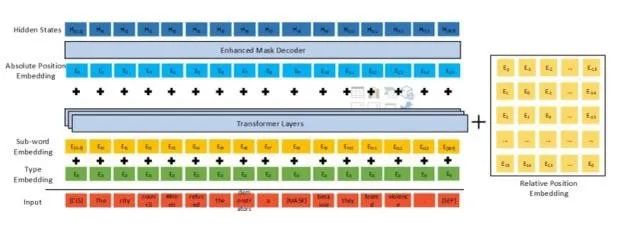
分散注意力機(jī)制
motivation
BERT加入位置信息的方法是在輸入embedding中加入postion embedding, pos embedding與char embedding和segment embedding混在一起,這種早期就合并了位置信息在計(jì)算self-attention時(shí),表達(dá)能力受限,維護(hù)信息非常被弱化了
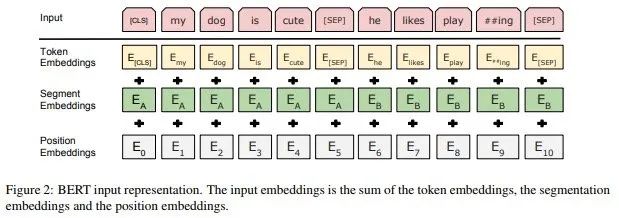
BERT embedding
本文的motivation就是將pos信息拆分出來,單獨(dú)編碼后去content 和自己求attention,增加計(jì)算 “位置-內(nèi)容” 和 “內(nèi)容-位置” 注意力的分散Disentangled Attention
Disentangled Attention計(jì)算方法
分散注意力機(jī)制首先在input中分離相對(duì)位置embedding,在原始char embedding+segment embedding經(jīng)過編碼成后,與相對(duì)位置計(jì)算attention,
即是內(nèi)容編碼,是相對(duì)的位置編碼, attention的計(jì)算中,融合了位置-位置,內(nèi)容-內(nèi)容,位置-內(nèi)容,內(nèi)容-位置
相對(duì)位置的計(jì)算
限制了相對(duì)距離,相距大于一個(gè)閾值時(shí)距離就無效了,此時(shí)距離設(shè)定為一個(gè)常數(shù),距離在有效范圍內(nèi)時(shí),用參數(shù)用控制
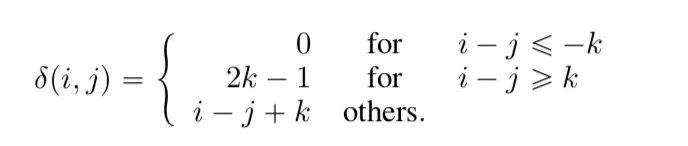
增強(qiáng)型解碼器
強(qiáng)行叫做解碼器
用 EMD( enhanced mask decoder) 來代替原 BERT 的 SoftMax 層預(yù)測(cè)遮蓋的 Token。因?yàn)槲覀冊(cè)诰{(diào)時(shí)一般會(huì)在 BERT 的輸出后接一個(gè)特定任務(wù)的 Decoder,但是在預(yù)訓(xùn)練時(shí)卻并沒有這個(gè) Decoder;所以本文在預(yù)訓(xùn)練時(shí)用一個(gè)兩層的 Transformer decoder 和一個(gè) SoftMax 作為 Decoder。其實(shí)就是給后層的Transformer encoder換了個(gè)名字,千萬別以為是用到了Transformer 的 Decoder端
絕對(duì)位置embedding
在decoder前有一個(gè)騷操作是在這里加入了一層絕對(duì)位置embedding來彌補(bǔ)一下只有相對(duì)位置的損失,比如“超市旁新開了一個(gè)商場(chǎng)”,當(dāng)mask的詞是“超市”,“商場(chǎng)”,時(shí),只有相對(duì)位置時(shí)沒法區(qū)分這兩個(gè)詞的信息,因此decoder中加入一層
一些訓(xùn)練tricks
將BERT的訓(xùn)練策略中,mask有10%的情況是不做任何替換,這種情況attention偏向自己會(huì)非常明顯,DeBeta將不做替換改成了換位該位置詞絕對(duì)位置的pos embedding, 實(shí)驗(yàn)中明顯能看到這種情況下的attention對(duì)自身依賴減弱
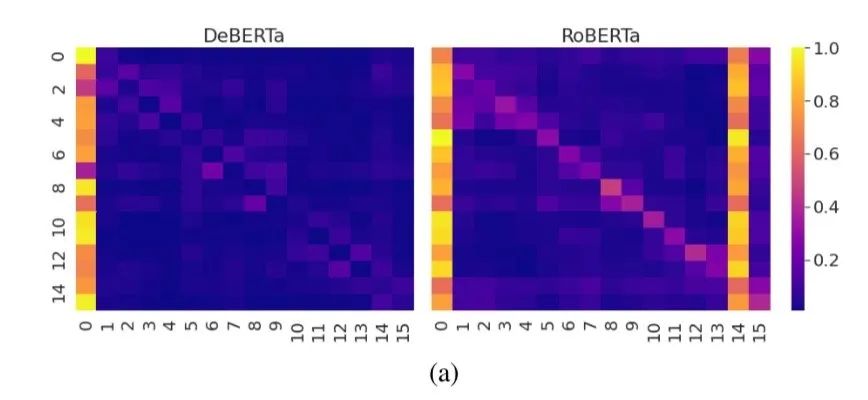
在訓(xùn)練下游任務(wù)時(shí),給訓(xùn)練集做了一點(diǎn)擾動(dòng)來增強(qiáng)模型的魯棒性
效果
DeBERTa large目前是GLUE的榜首,在大部分任務(wù)上整體效果相比還是有一丟丟提升
責(zé)任編輯:lq
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7259瀏覽量
92033 -
編碼
+關(guān)注
關(guān)注
6文章
969瀏覽量
55822 -
Decoder
+關(guān)注
關(guān)注
0文章
25瀏覽量
10903
原文標(biāo)題:SOTA來啦!BERT又又又又又又魔改了!DeBERTa登頂GLUE~
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
“碰一下”支付終端應(yīng)用在酒店:智能無卡入住與客房控制

上電時(shí)GPIO控制的LED偶爾詭異地亮了一下
碰一下終端,讓自助售貨機(jī)秒變 “家里的冰箱”
你家也有“隱形守護(hù)者”?Rd-03雷達(dá)模組了解一下

請(qǐng)教一下,兩片ADS8568在PCB布線是應(yīng)該注意什么
“碰一下”支付背后的4G技術(shù)
支付寶發(fā)布新一代AI視覺搜索“探一下”
在逆變器應(yīng)用中提供更高能效,這款I(lǐng)GBT模塊了解一下
一文解讀SPI

建議DFM工具里的拼版在完善一下
在WORD里面插入波形圖中遇到的問題麻煩大佬幫忙看一下
內(nèi)置誤碼率測(cè)試儀(BERT)和采樣示波器一體化測(cè)試儀器安立MP2110A






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論