


機器學習在鐵路缺陷檢測中的實際應用
本文介紹了在鐵軌的超聲波檢測過程中有效使用機器學習技術自動檢測缺陷的經驗,并提出了一種使用數學建模為神經網絡創建訓練數據集的有效方法,為實際缺陷圖的識別提供了更高精度的指標。文中訓練神經網絡運算的原型實例,其實際缺陷圖的預測精度高達92%。
鐵軌在列車行進過程中往往承受著巨大的壓力,而這一過程可能會產生導致火車發生事故的缺陷。
鐵軌缺陷與預防性檢測是鐵路安全領域的一個極其重要的領域。本文將對廣泛應用于火車鐵軌診斷的超聲波檢測技術進行闡述和分析。
分析缺陷檢測結果面臨的一個主要問題是,目前缺乏在數百公里的鐵軌上捕獲缺陷數據的自動檢測能力。而在人工搜索缺陷時,遺漏缺陷的可能性很高,并且其結果主要取決于檢測人員的經驗和人為因素。
問題陳述
在這項工作中,主要的任務是創建一個神經網絡的工作原型,以自動檢測鐵軌超聲檢測圖上的缺陷,其準確性需要超過85%。
超聲波檢測中的鐵軌缺陷的分類
為了訓練神經網絡,需要以數字形式對鐵軌進行超聲波檢查的初始數據,這些數據可以使用相應的缺陷圖的檢測儀獲得,這些檢測儀以B掃描(BSCAN)的形式顯示。
BSCAN形成的原理是將脈沖超聲波信號以一定的角度和距離輸入到鐵軌中,并記錄其反射信號(如圖2所示)。在反射信號強度圖中,不同的輸入角度的信號生成不同亮度的點。使用不同輸入角度的超聲波信號探測是由于缺陷具有不同性質,而反映信號的深度取決于缺陷的深度和形狀。
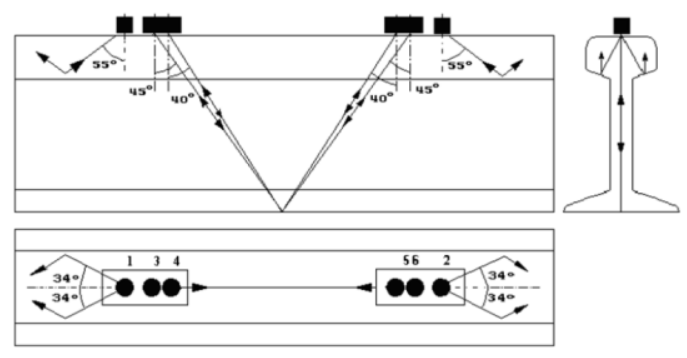
圖2:使用六個傳感器的鐵軌測深方案示例
為了對缺陷進行分類,需要考慮鐵軌缺陷分類的原則。而根據PJSC俄羅斯鐵路公司2017年推出的文件“關于無損鐵軌檢測結果解密的聲明”,其分類的所有鐵軌缺陷都用三位數字進行編碼。
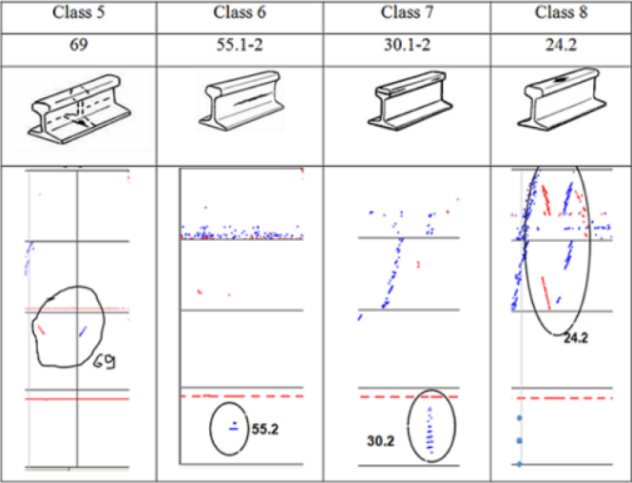
為了創建數據集,以下選擇了8個最常見的缺陷。表1和表2顯示了所選鐵軌缺陷的視圖、缺陷代碼以及BSCAN的外觀。
表1:缺陷代碼及其缺陷圖列表的第1部分
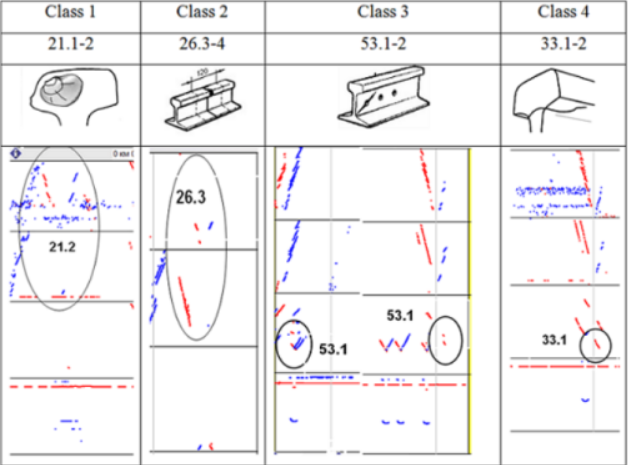
表2:缺陷代碼及其缺陷圖列表的第2部分
在實際缺陷圖框架上訓練的神經網絡第一版
對現有缺陷圖數據庫的分析表明,由于各種制造商生產的設備具有各種信號處理算法、不同數量的發射器和接收器,因此無法同時使用它們。對于每個缺陷組都采用了Avikon-11檢測儀,根據估計,在兩個車站之間的鐵軌獲得的缺陷不會超過20個,而這對于創建有效的神經網絡來說,這些缺陷的數量非常少。因此,在特定位置的參考缺陷鐵軌的現有站點上也采用了一組缺陷圖。這樣的一段鐵路被稱為“控制死區”。圖3顯示了一條鐵軌控制死區的缺陷圖。
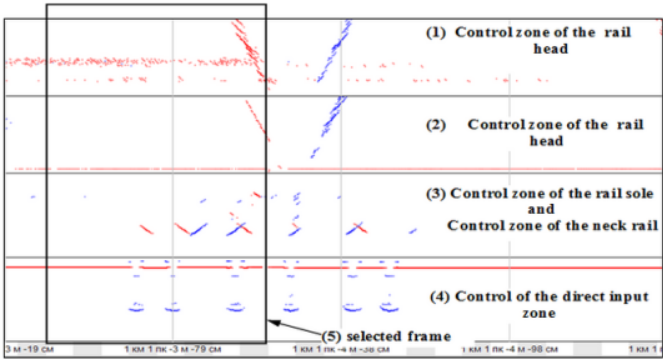
圖3:采用Avikon-11檢測儀顯示的一根鐵軌截面的缺陷圖
可以將連續的缺陷圖“切割”為單獨的片段,然后將其分類并保存為單獨的文件——幀。圖3(第5點)所示的每個切割的幀同時包括沿其鐵軌截面的所有檢查區域。其測量通道的這種綜合考慮允許使用所有可用的信息特征來對缺陷圖幀進行分類。而[500,800]個條件點組成的幀數量很大,在訓練神經網絡時需要大量的時間和計算成本。此外,它還需要較大的數據集。為了擴大帶有缺陷的數據集規模,可以使用一種偏移幀方法,如圖4所示。因此可以在一個缺陷上獲得50個以上的幀。這種方法允許將9個類的數據集從1,000個增加到60,000個,其中0類是無缺陷的鐵軌。
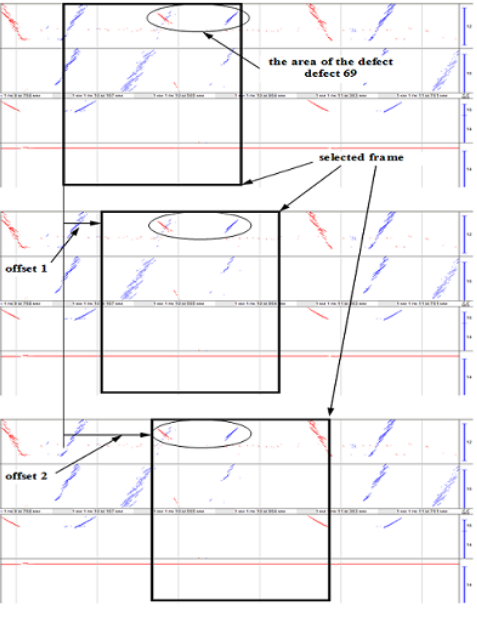
圖4:用于創建帶有缺陷的擴展數據集的幀
在這一過程中,合成了一個卷積神經網絡用于無歧義的分類,其輸出端有一個完全連接的分類器(CNN)。經過訓練的神經網絡在驗證數據上顯示35%的準確性。而每個可用的9類的準確率比純粹的隨機分類器要高出3倍。由于選擇了神經網絡的結構和超參數,因此無法提高識別精度。在這一階段,缺少規模足夠大的通用數據集是導致神經網絡效率低下的關鍵因素。
基于模型數據訓練的神經網絡第二版
基于模型數據訓練的神經網絡第一版的效率比較低下的原因并不是因為使用的算法不佳,而是由于缺乏針對其訓練的代表性的數據集,這才是關鍵因素。在測試鐵軌時,由于獲得新數據而導致數據集的增加是一個漫長的過程,可能會持續數年的時間。在這里實施的任務是考慮使用模型數據訓練神經網絡的可能性。
建模是加快增加數據集過程的一種方法,因此有必要基于數學模型,來獲得具有不同類別的缺陷圖幀的樣本。
建模類型選擇
神經網絡操作及其訓練的主要原理是抽象化在輸入端接收到的可見圖像,將其轉換為高級視覺概念,并同時過濾不重要的視覺細節。神經網絡應該只記住圖像,而細節只會妨礙它識別,這就是不必在鐵軌中創建精確的超聲波傳播物理模型的原因。超聲波在鐵軌中傳播的物理模型不能解決導致各種形式的缺陷及其位置的問題。此類缺陷需要人工創建,數量多達數萬個。而在鐵軌中引入超聲波并測量反射信號的模型、隨機性、對許多因素(生成器位置等)的依賴性等問題也沒有得到解決。
在這項工作中提出了一種方法,該方法包括創建參數仿真模型,基于該模型可以生成一個數據集,用于訓練處理數以千計的每類缺陷的神經網絡。
為了構建這種神經網絡的工作原型,選擇了超聲波輸入角為α=0(嚴格向下)的通道。其幀長(沿鐵軌長度)增加到1000個條件點,這對識別的準確性非常重要。
數學模型是在LabVIEW環境中開發的,用于原型設計和建模。所獲得的數學模型不僅考慮從反射器獲得的波形,而且考慮振幅的分布。在公共參數模型的輸出處獲得的每個幀都是唯一的,這是因為該模型的每個參數都有隨機生成器。表3和表4顯示了鐵軌中各個異質結構的測量數據和模型數據的BSCAN示例。
表3:鐵軌螺栓孔的實測數據和模型數據的BSCAN示例
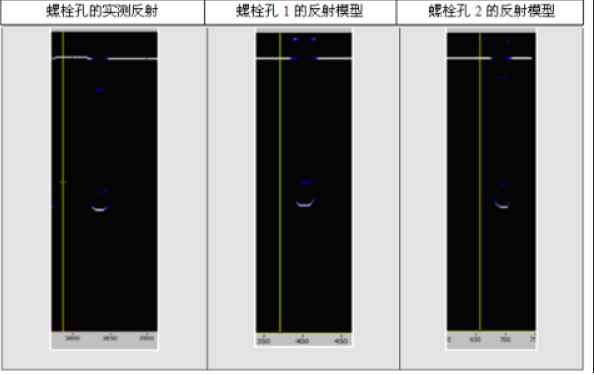
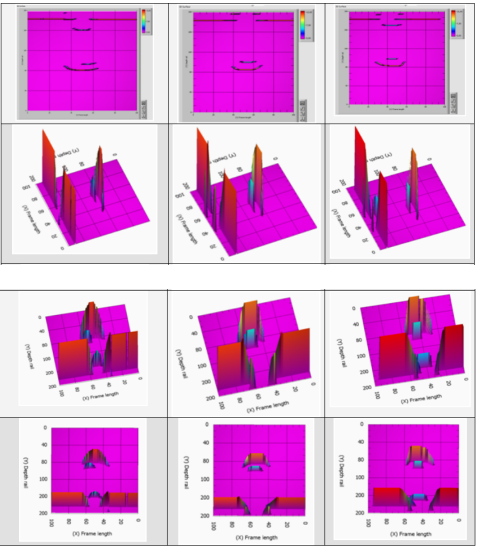
表4:30組實測缺陷和模型缺陷掃描(表面缺陷和軌頭缺陷)

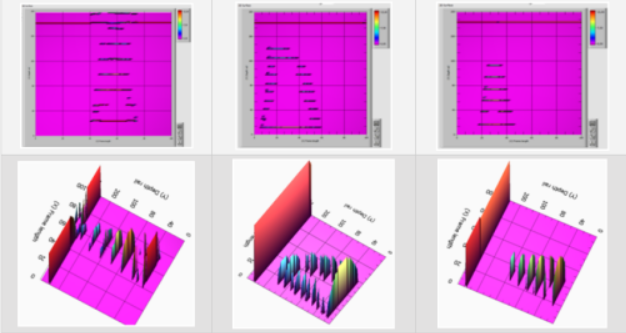
將單個鐵軌故障的超聲波檢查的測量數據與獲得的模型數據進行比較,可以了解它們的相似性。建議基于神經網絡識別實際缺陷的準確性指標來檢查所獲得模型的適當性,該神經網絡將從模型數據中學習。
從不同的鐵軌故障模型中,可以獲得對鐵軌進行超聲波檢查的幀。與此同時,模型的參數將會發生變化,以獲得在實際條件下可能發生的各種組合,也就是:
各種深度的缺陷;
各種坐標的缺陷;
以螺栓孔的形式存在的缺陷和過程反射器的各個相對位置;
根據螺栓孔數的不同,螺栓連接的組合方式不同;
鐵軌中不同形式的缺陷和工藝異質結構;
鐵軌中所有異類結構的振幅響應隨機性。
模型數據樣本的示例
圖5顯示了具有30組缺陷-表面缺陷和軌頭缺陷模型幀的樣本。
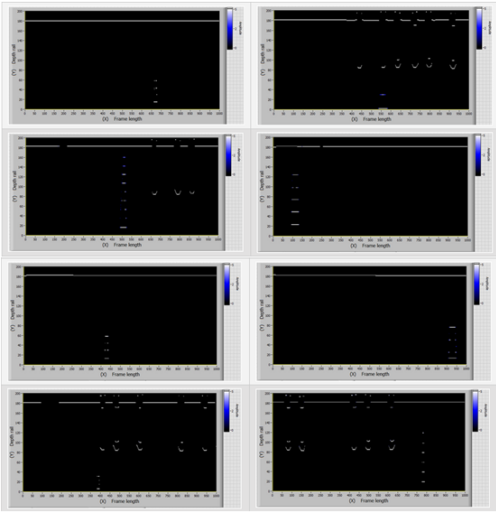
圖5:具有30組缺陷的模型幀樣本—表面缺陷和軌頭缺陷
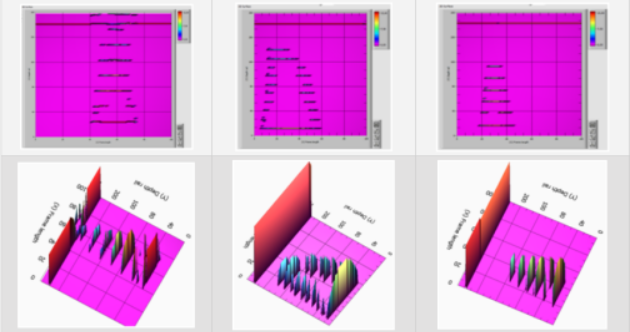
為了進行比較,圖6顯示了來自Avikon-11檢測儀的實際數據。

圖6:具有第30組缺陷的真實幀的樣本—表面缺陷(軌頭缺陷)
圖7顯示了具有33組缺陷—軌頸缺陷模型幀的樣本。
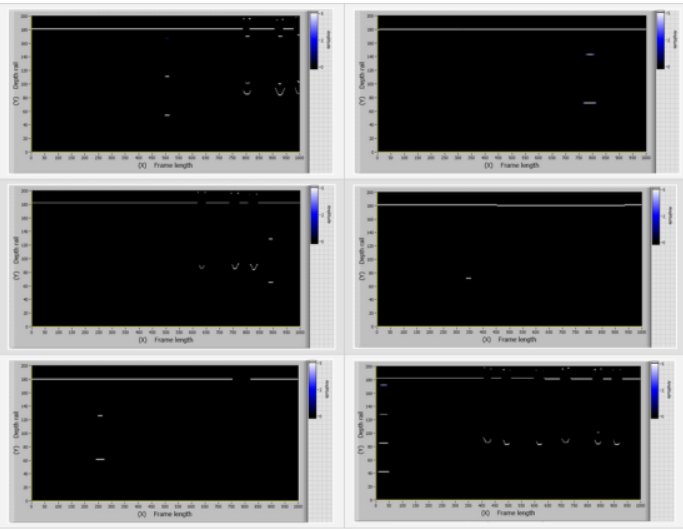
圖7:具有33組缺陷—軌頸缺陷模型幀的樣本
為了進行比較,圖8顯示了來自Avikon-11檢測儀的實際數據。

圖8:具有33組缺陷-軌頸缺陷實際幀的樣本
圖9顯示了具有55組缺陷(軌頸中的缺陷)模型幀的樣本。圖10顯示了具有55組缺陷的實際幀。

圖9:具有55組缺陷-—軌頸缺陷模型幀的樣本
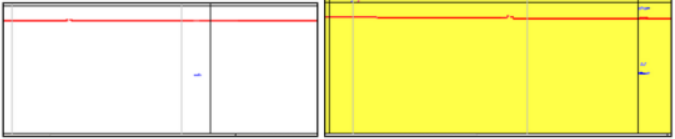
圖10:具有55組缺陷—-軌頸缺陷實際幀的樣本
圖11顯示了具有無缺陷條件(帶有和不帶有螺栓孔)模型幀的樣本。
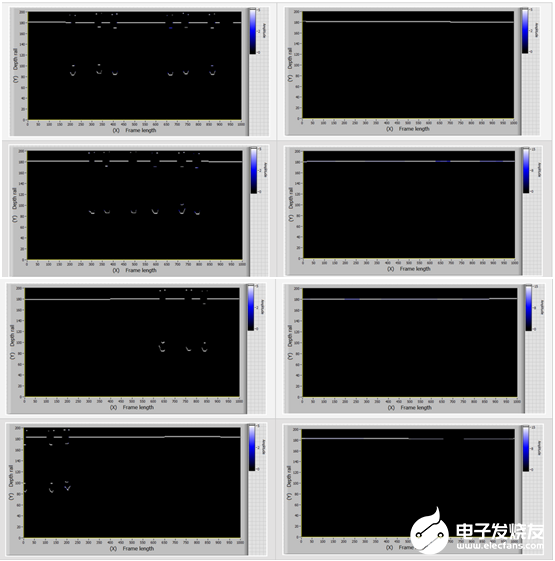
圖11:處于無缺陷狀態(有螺栓孔和不帶有螺栓孔)模型幀的樣本
根據表5為每組模型幀分配一個類別編號(編碼標記)
表5-分配類別
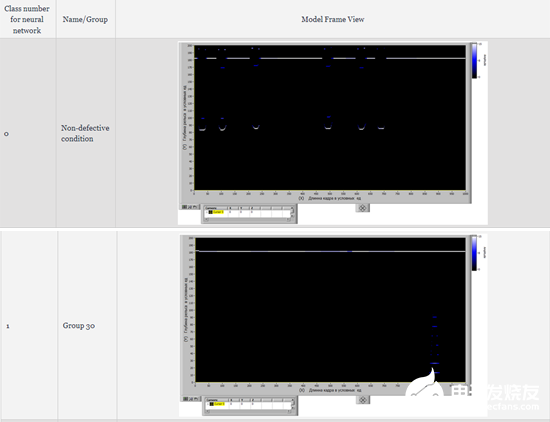
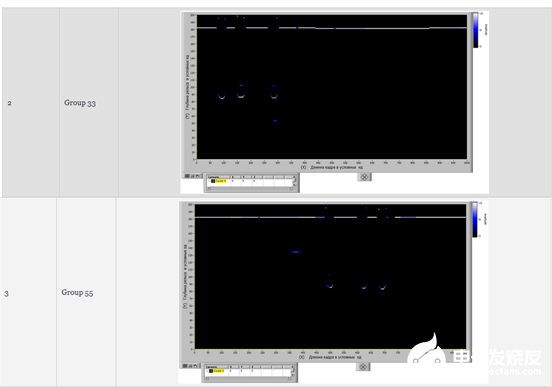
創建的數學模型使得有可能針對4個給定的類別(如上表中的0、1、2、3)生成10000個訓練數據、1000個驗證數據和1000個測試數據的平衡集。這樣一個數據集的生成時間為10分鐘。
想法的有效性
此外,這項工作還進行了卷積神經網絡(CNN)模型的綜合、訓練以及對創建的數據集的綜合(模型)數據的驗證。實踐表明,其訓練數據的識別準確率為98%,測試數據的識別準確率為97%。
為了檢查識別實際缺陷幀(由檢測儀測量)的準確性,將來自控制死區的標記幀(通過Avikon-11檢測儀檢查數據集,這里有3000個樣本)提供給所創建的神經網絡的輸入。對Avikon-11型檢測儀實測數據的識別準確率為92%。
獲得的精度是一個很好的結果。但是采用一些方法可以提高精度。失配矩陣(如圖12所示)有助于了解神經網絡在哪些幀上出錯。
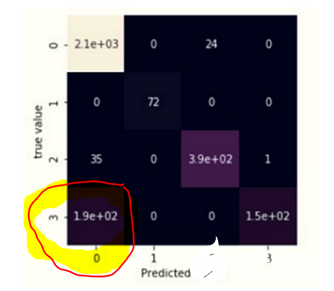
圖12:失配矩陣
在分析矩陣之后,很明顯,神經網絡會在3類(缺陷組-55)的幀中做出主要預測誤差,而在0類(無缺陷狀態)的幀中進行預測,神經網絡將其識別為一個螺栓孔的位置。由于其相似性,導致第55組出現缺陷(如圖13所示)。在這種情況下,有必要添加其他通道的信息符號,從而提高預測的準確性(在這種情況下通常是軌頸控制通道,這是由于存在螺栓孔)。這對圖13進行了解釋。
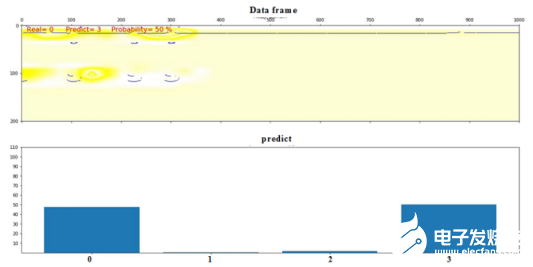
圖13:將幀錯誤分配給3類的示例
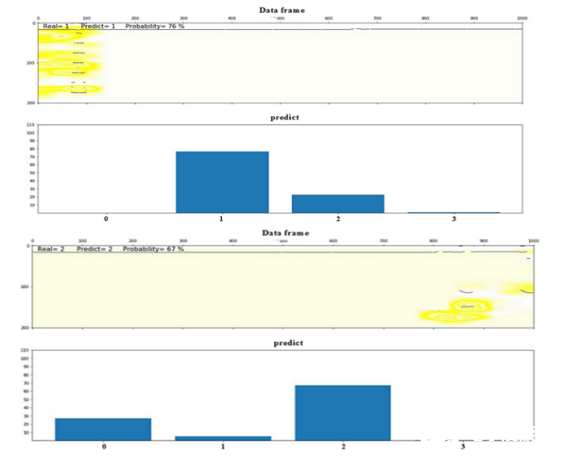
目前,在識別系統中已添加了在神經網絡已“決定”分類的幀上突出顯示信息符號的算法(圖14中的黃色背景)。
結論和進一步的發展策略
獲得的92%的準確度表明了將模型數據用于訓練網絡的可能性,并將其應用于自動識別鐵軌超聲檢測的實際缺陷圖,從而解決了訓練數據量少的問題,這將顯著加快采用自動缺陷識別系統生成軟件的進程。這一想法的進一步發展包括以下步驟:
(1)軌頭控制通道、軌頸控制通道、軌底控制通道的模型綜合。
(2)調整模型以消除噪音。
(3)將生成的缺陷“植入”(放置和引入)到實際缺陷圖(具有引入缺陷的真實噪聲圖)。
(4)改進模型以提高神經網絡的精度。
工作原型所提出的發展階段將允許增加:
缺陷識別的準確性
已識別的缺陷類別的數量
創建一個完整的系統,以通過所選檢測儀的所有測量通道來自動檢測缺陷。
所獲得的模型可以適合所需的檢測儀。
編輯:lyn
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103828 -
超聲波檢測
+關注
關注
0文章
23瀏覽量
8739 -
機器學習
+關注
關注
66文章
8507瀏覽量
134735
發布評論請先 登錄
FLIR Si1-LD聲學成像儀在鐵路行業中的應用優勢
大模型在半導體行業的應用可行性分析
機器學習異常檢測實戰:用Isolation Forest快速構建無標簽異常檢測系統


高光譜相機在工業檢測中的應用:LED屏檢、PCB板缺陷檢測

cmp在機器學習中的作用 如何使用cmp進行數據對比
傅立葉變換在機器學習中的應用 常見傅立葉變換的誤區解析
eda在機器學習中的應用
鐵路位移檢測識別攝像機

機器視覺檢測應用場景:缺陷檢測、尺寸測量、引導定位、運動控制
ATA-8202射頻功率放大器在應力導波缺陷檢測研究中的應用





 工商網監
工商網監

評論