 OpenAI又放大招:連接文本與圖像的CLIP
OpenAI又放大招:連接文本與圖像的CLIP
2020年,通用模型產生了經濟價值,特別是GPT-3,它的出現證明了大型語言模型具有驚人的語言能力,并且在執行其他任務方面也毫不遜色。
2021年,OpenAI 聯合創始人 Ilya Sutskever預測語言模型會轉向視覺領域。他說:“下一代模型,或許可以針對文本輸入,從而編輯和生成圖像。”
聽話聽音!OpenAI 踐行了這一想法,幾個小時前,OpenAI通過官方推特發布了兩個嶄新的網絡,一個叫DALL-E(參見今天推送的頭條),能夠通過給定的文本創建出圖片;一個叫CLIP,能夠將圖像映射到文本描述的類別中。
其中,CLIP可以通過自然語言監督有效學習視覺概念,從而解決目前深度學習主流方法存在的幾個問題:
1.需要大量的訓練數據集,從而導致較高的創建成本。
2.標準的視覺模型,往往只擅長一類任務,遷移到其他任務,需要花費巨大的成本。
3.在基準上表現良好的模型,在測試中往往不盡人意。
具體而言,OpenAI從互聯網收集的4億(圖像、文本)對的數據集,在預訓練之后,用自然語言描述所學的視覺概念,從而使模型能夠在zero-shot狀態下轉移到下游任務。這種設計類似于GPT-2和GPT-3的“zero-shot”。
這一點非常關鍵,因為這意味著,可以不直接針對基準進行優化,同時表現出了優越的性能:穩健性差距(robustness gap)縮小了75%,性能和ResNet507相當。換句話說。無需使用其訓練的128萬個訓練樣本中的任何一個,即可與原始ResNet-50 在 Image Net Zero-shot的精確度相匹配。
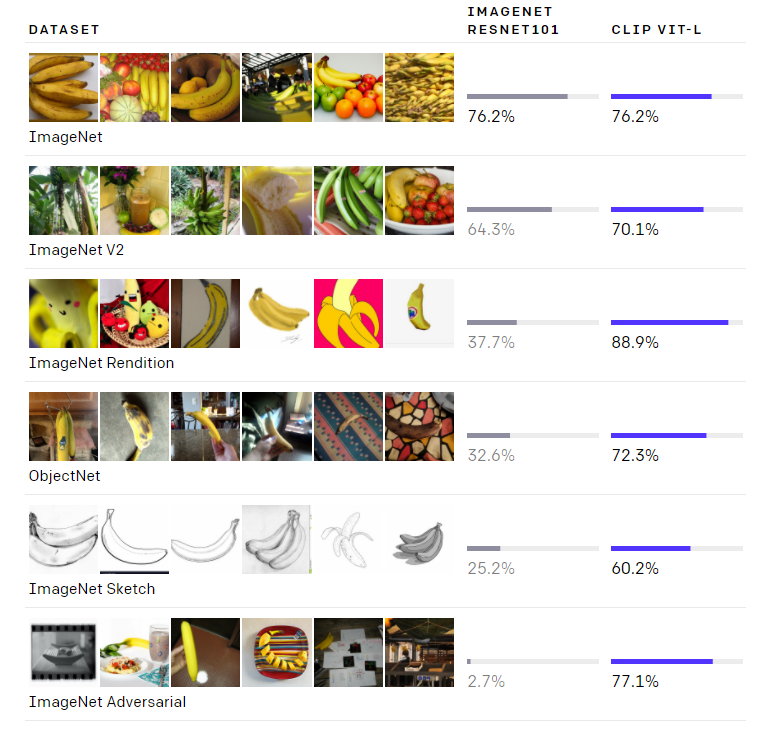
如上圖所示,雖然兩個模型在ImageNet測試集上的準確度相差無幾,但CLIP的性能更能代表在非ImageNet設置下的表現。
CLIP網絡中做了大量的工作是關于zero-shot 遷移的學習、自然語言監督、多模態學習。其實,關于零數據學習的想法可以追溯到十年前,但是最近在計算機視覺中火了起來。零數據學習的一個重點是:利用自然語言作為靈活的預測空間,從而實現泛化和遷移。另外,在2013年,斯坦福大學的Richer Socher通過訓練CIFAR-10上的一個模型,在詞向量嵌入空間中進行預測,并表明模型可以預測兩個“未見過”的類別。Richer的工作提供了一個概念證明。
CLIP是過去一年,從自然語言監督中學習視覺表征工作中的一部分。CLIP使用了更現代的架構,如Transformer,包括探索自回歸語言建模的Virtex,研究掩蔽語言建模的ICMLM等等。
1
方法
前面也提到,CLIP訓練的數據來源于互聯網上4億數據對。用這些數據,CLIP需要完成的任務是:給定一幅圖像,在32,768個隨機抽樣的文本片段中,找到能夠匹配的那一個。
完成這個任務,需要CLIP模型學會識別圖像中的各種視覺概念,并將概念和圖片相關聯。因此,CLIP模型可以應用于幾乎任意的視覺分類任務。
例如,如果一個數據集的任務是對狗與貓的照片進行分類,而CLIP模型預測 “一張狗的照片 ”和 “一張貓的照片 ”這兩個文字描述哪個更匹配。
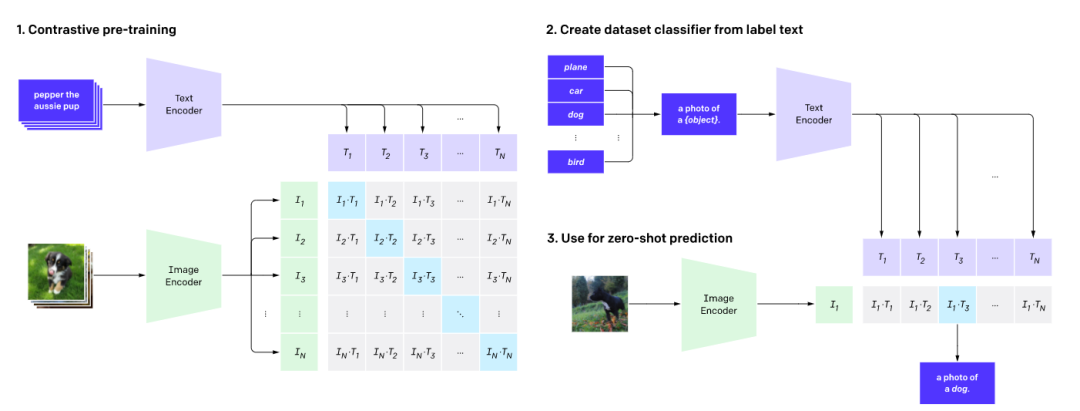
如上圖所示,CLIP網絡工作流程:預訓練圖編碼器和文本編碼器,以預測數據集中哪些圖像與哪些文本配對。然后,將CLIP轉換為zero-shot分類器。
此外,將數據集的所有類轉換為諸如“一只狗的照片”之類的標簽,并預測最佳配對的圖像。
總體而言,CLIP能夠解決:
1.昂貴的數據集:ImageNet中1400萬張圖片的標注,動用了25,000名勞動力。相比之下,CLIP使用的是已經在互聯網上公開提供的文本-圖像對。自我監督學習、對比方法、自我訓練方法和生成式建模也可以減少對標注圖像的依賴。
2.任務單一:CLIP可以適用于執行各種視覺分類任務,而不需要額外的訓練。
3.實際應用性能不佳:深度學習中“基準性能”與“實際性能”之間存在差距是一直以來的“痛”。這種差距之所以會出現,是因為模型“作弊”,即僅優化其在基準上的性能,就像一個學生僅僅通過研究過去幾年的試題就能通過考試一樣。
CLIP模型可以不必在數據上訓練,而是直接在基準上進行評估,因此無法以這種方式來“作弊”。此外,為了驗證“作弊的假設”,測量了CLIP在有能力“研究” ImageNet時性能會如何變化。
當線性分類器根據CLIP的特性安裝時,線性分類器能夠將CLIP在ImageNet測試儀上的準確性提高近10%。但是,在評估“魯棒性”的性能時,這個分類器在其余7個數據集的評估套件中并沒有取得更好的平均表現。
2
優勢1. CLIP非常高效
CLIP從未經過濾的、變化多端的、極其嘈雜的數據中學習,且希望能夠在零樣本的情況下使用。從GPT-2和GPT-3中,我們可以知道,基于此類數據訓練的模型可以實現出色的零樣本性能;但是,這類模型需要大量的訓練計算。為了減少所需的計算,我們專注研究算法,以提高我們所使用方法的訓練效率。我們介紹了兩種能夠節省大量計算的算法。
第一個算法是采用對比目標(contrastive objective),將文本與圖像連接起來。最初我們探索了一種類似于VirTex的圖像到文本的方法,但這種方法在拓展以實現最先進的性能時遇到了困難。在一些小型與中型實驗中,我們發現CLIP所使用的對比目標在零樣本ImageNet分類中的效率提高了4到10倍。
第二個算法是采用Vision Transformer,這個算法使我們的計算效率比在標準ResNet上提高了3倍。最后,性能最好的CLIP模型與現有的大規模圖像模型相似,在256個GPU上訓練了2周。我們最初是嘗試訓練圖像到字幕的語言模型,但發現這種方法在零樣本遷移方面遇到了困難。在16 GPU的日實驗中,一個語言在訓練了4億張圖像后,在ImageNet上僅達到16%的準確性。CLIP的效率更高,且以大約快10倍的速度達到了相同的準確度。
2. CLIP靈活且通用
由于CLIP模型可以直接從自然語言中學習許多視覺概念,因此它們比現有的ImageNet模型更加靈活與通用。我們發現,CLIP模型能夠在零樣本下執行許多不同的任務。為了驗證這一點,我們在30多個數據集上測量了CLIP的零樣本性能,任務包括細粒度物體分類,地理定位,視頻中的動作識別和OCR等。其中,學習OCR時,CLIP取得了在標準ImageNet模型中所無法實現的令人興奮的效果。
比如,我們對每個零樣本分類器的隨機非櫻桃采摘預測進行了可視化。這一發現也反映在使用線性探測學習評估的標準表示中。
我們測試了26個不同的遷移數據集,其中最佳的CLIP模型在20個數據集上的表現都比最佳的公開ImageNet模型(Noisy Student EfficientNet-L2)出色。
在27個測試任務的數據集中,測試任務包括細粒度物體分類,OCR,視頻活動識別以及地理定位,我們發現CLIP模型學會了使用效果更廣泛的圖像表示。與先前的10種方法相比,CLIP模型的計算效率也更高。
3
局限性
盡管CLIP在識別常見物體上的表現良好,但在一些更抽象或系統的任務(例如計算圖像中的物體數量)和更復雜的任務(例如預測照片中距離最近的汽車有多近)上卻遇到了困難。
在這兩個數據集上,零樣本CLIP僅僅比隨機猜測要好一點點。與其他模型相比,在非常細粒度分類的任務上,例如區分汽車模型、飛機型號或花卉種類時,零樣本CLIP的表現也不好。
對于不包含在其預訓練數據集內的圖像,CLIP進行泛化的能力也很差。
例如,盡管CLIP學習了功能強大的OCR系統,但從MNIST數據集的手寫數字上進行評估時,零樣本CLIP只能達到88%的準確度,遠遠低于人類在數據集中的99.75%精確度。
最后,我們觀察到,CLIP的零樣本分類器對單詞構造或短語構造比較敏感,有時還需要試驗和錯誤“提示引擎”才能表現良好。
4
更廣的影響
CLIP允許人們設計自己的分類器,且無需使用任務特定的訓練數據。
設計分類的方式會嚴重影響模型的性能和模型的偏差。例如,我們發現,如果給定一組標簽,其中包括Fairface種族標簽和少數令人討厭的術語,例如“犯罪”,“動物”等,那么該模型很可能將大約32.3%的年齡為0至20歲的人的圖像化為糟糕的類別。但是,當我們添加“兒童”這一類別時,分類比率將下降到大約8.7%。
此外,由于CLIP不需要任務特定的訓練數據,因此它可以更輕松地解鎖某些任務。
一些任務可能會增加隱私或監視相關的風險,因此我們通過研究CLIP在名人識別方面的表現來探索這一擔憂。對100個名人圖像進行識別時,CLIP實際分類的準確率最高為59.2%,對1000個名人進行識別時,準確率最高為43.3%。值得注意的是,盡管通過任務不可知的預訓練可以達到這些效果,但與廣泛使用的生產級別模型相比,該性能并不具有競爭力。
5
結論
借助CLIP,我們測試了互聯網的自然語言上與任務無關的預訓練(這種預訓練為NLP的最新突破提供了動力)是否可以用來改善其他領域的深度學習性能。
目前,CLIP應用于計算機視覺所取得的效果令我們非常興奮。像GPT家族一樣,CLIP在預訓練期間學習了我們通過零樣本遷移所展示的各種任務。
CLIP在ImageNet上的表現也令人驚喜,其中零樣本評估展示了CLIP模型的強大功能。
責任編輯:lq
-
語言模型
+關注
關注
0文章
530瀏覽量
10298 -
數據集
+關注
關注
4文章
1208瀏覽量
24740 -
OpenAI
+關注
關注
9文章
1100瀏覽量
6583
原文標題:OpenAI又放大招:連接文本與圖像的CLIP,在ImageNet上效果媲美ResNet50
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
OpenAI暫不推出Sora視頻生成模型API

請問TPA3244,RESET FAULT CLIP_OTW怎么跟MCU連接?
TAS5630電路PBTL接法,CLIP燈無法滅是怎么回事?
OpenAI承認正研發ChatGPT文本水印
OpenAI正深入探索文本水印技術的前沿領域
玩具反斗城使用OpenAI的Sora文本轉視頻工具制作"品牌電影"
OpenAI發布GPT-4o模型,支持文本、圖像、音頻信息,速度提升一倍,價格不變
OpenAI發布GPT-4o模型,供全體用戶免費使用
OpenAI發布圖像檢測分類器,可區分AI生成圖像與實拍照片
Mistral發布Mistral Large旗艦模型,但沒有開源
什么是OpenAI Sora?最佳OpenAI Sora替代推薦
谷歌Gemini 1.5深夜爆炸上線,史詩級多模態硬剛GPT-5!最強MoE首破100萬極限上下文紀錄






 工商網監
工商網監
評論