

本篇目錄
1. 內存占用
1.1 FPGA程序中內存的實現方式
1.2 Zynq的BRAM內存大小
1.3 一個卷積操作占用的內存
2. PipeCNN可實現性
PipeCNN論文解析:用OpenCL實現FPGA上的大型卷積網絡加速
2.1 已實現的PipeCNN資源消耗
3. 實現大型神經網絡的方法
4. Virtex-7高端FPGA概覽、7系列FPGA相關文檔
正文
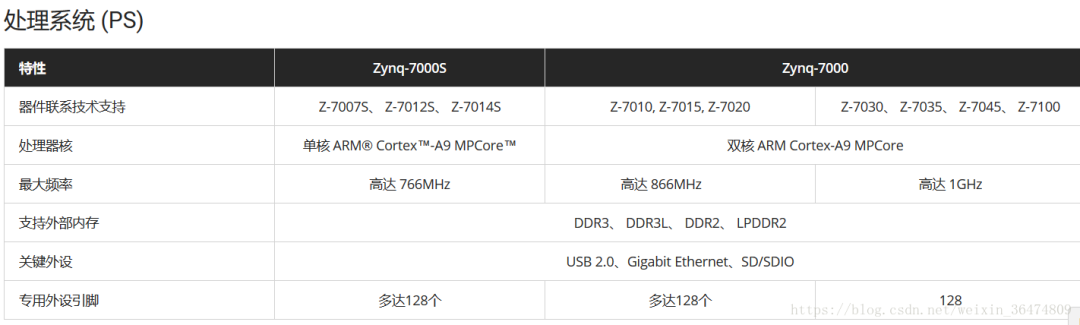
0Zynq7000系列概覽
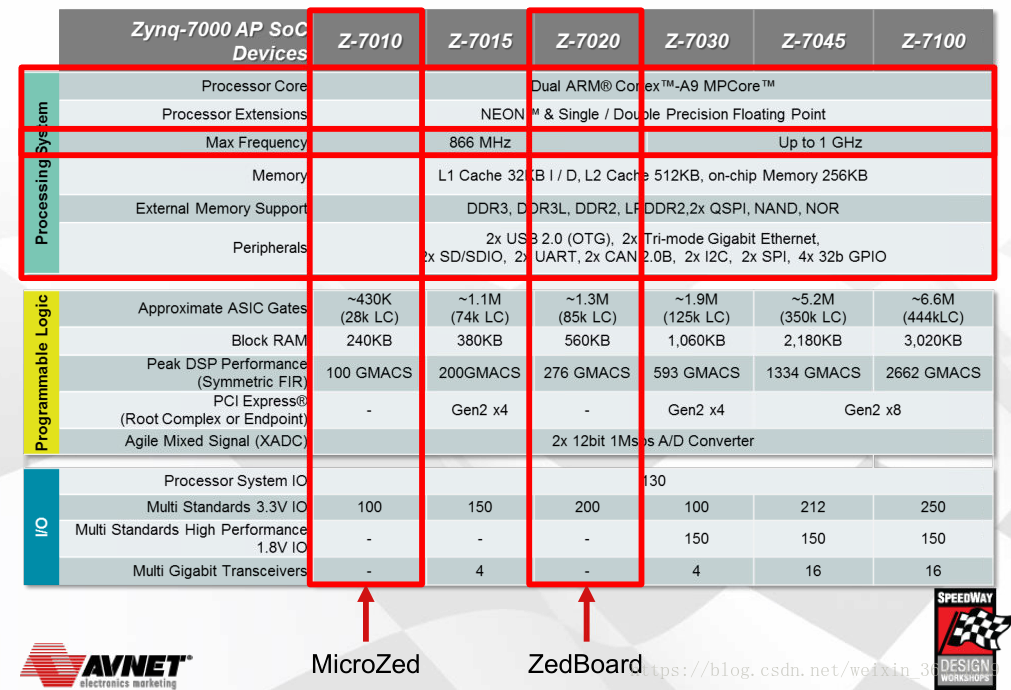
1內存占用
1.1 FPGA程序中內存的實現方式
參閱xilinx文檔UG998

FPGA并沒有像軟件那樣用已有的cache,FPGA的HLS編譯器會在FPGA中創建一個快速的memory architecture以最好的適應算法中的數據樣式(data layout)。因此FPGA可以有相互獨立的不同大小的內部存儲空間,例如寄存器,移位寄存器,FIFOs和BRAMs。
寄存器:最快的內存結構,集成在在運算單元之中,獲取不需要額外的時延。
移位寄存器:可以被當作一個數據序列,每一個數據可以在不同的運算之中被重復使用。將其中所有數據移動到相鄰的存儲設備中只需要一個時鐘周期。
FIFO:只有一個輸入和輸出的數據序列,通常被用于循環或循環函數,細節會被HLS編譯器處理。
BRAM:集成在FPGA fabric模塊中的RAM,每個xilinx的FPGA中集成有多個這樣的BRAM。可以被當作有以下特性的cache:1.不支持像處理器cache中那樣的緩存一致性(cache coherency,collision),不支持處理器中的一些邏輯類型。2.只在設備有電時保持內存。3.不同的BRAM塊可以同時傳輸數據。
1.2 Zynq的BRAM內存大小
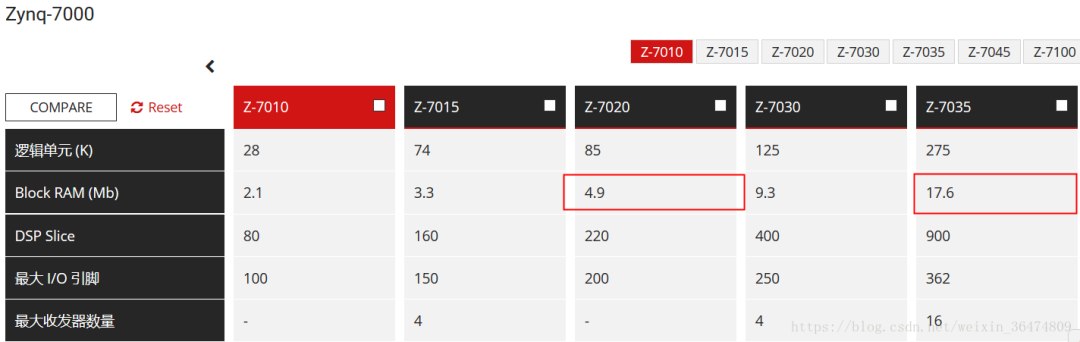
zynq 7z020的BRAM為4.9Mb,7z035的BRAM為17.6Mb(2.2MB)
1.3 一個卷積操作占用的內存
例如,我們實現的卷積函數,輸入27×600,卷積核16×27,輸出16×600,數據類型為float。
//convolution operation for (i = 0; i 《 16; i++) { for (j = 0; j 《 600; j++) { result = 0; for (k = 0; k 《 27; k++) { temp = weights[i*27+k] * buf_in[k*600+j]; result += temp; } buf_out[i*600+j] = result; } }
在HLS中生成的IPcore占用硬件資源為:
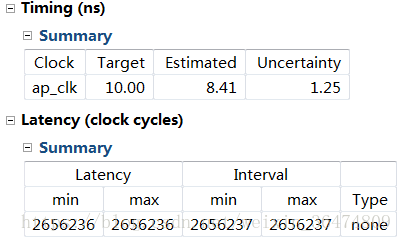
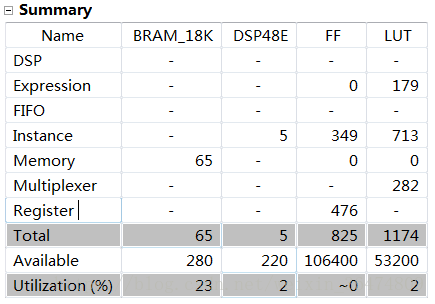
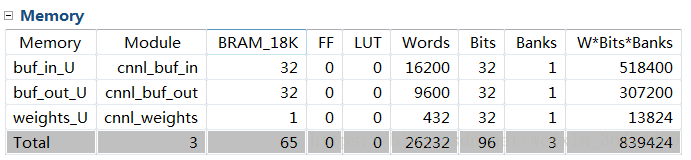
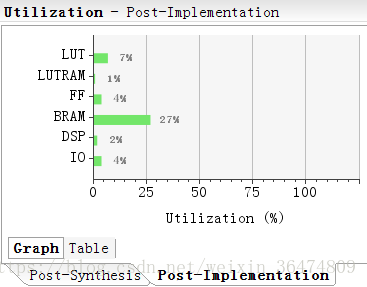
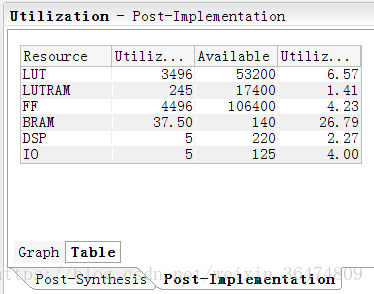
在vivado中搭建好系統,占用的資源為:
2PipeCNN可實現性
PipeCNN是一個基于OpenCL的FPGA實現大型卷積網絡的加速器。
PipeCNN解析文檔:
PipeCNN論文解析:用OpenCL實現FPGA上的大型卷積網絡加速
github地址:https://github.com/doonny/PipeCNN#how-to-use
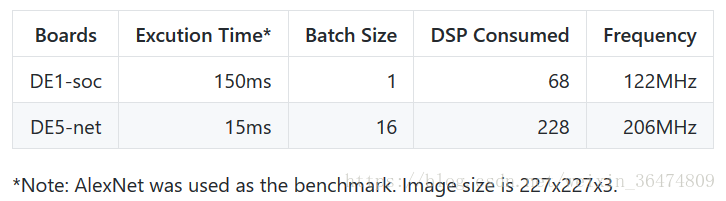
2.1 已實現的PipeCNN資源消耗
對于Altera FPGA,運用 Intel‘s OpenCL SDK v16.1 toolset.
對于Xilinx FPGAs, the SDAccel development environment v2017.2 can be used.

Xilinx’s KCU1500 (XCKU115 FPGA)(已經有xilin的板子實現過pipeCNN,但是型號比zynq高很多)
硬件資源可以被三個宏調控,device/hw_param.cl. Change the following macros
VEC_SIZE
LANE_NUM
CONV_GP_SIZE_X
消耗資源為:
3實現大型神經網絡的方法
方案一:壓縮模型到《2.2MB,可實現在BRAM中
優點:1.速度快 2.實現方便
缺點:1.模型壓縮難度 2.難以實現大型網絡
方案二:用FPGA調用DDR
優點:1.速度中等 2.可實現大型網絡
缺點:調用DDR有難度,開發周期長
方案三:用片上單片機調用DDR(插入SD卡)分包傳入IPcore運算
優點:可實現大型網絡
缺點:速度較慢
4Virtex-7高端FPGA概覽
Virtex-7為高端FPGA,比Zynq高了一個檔次。
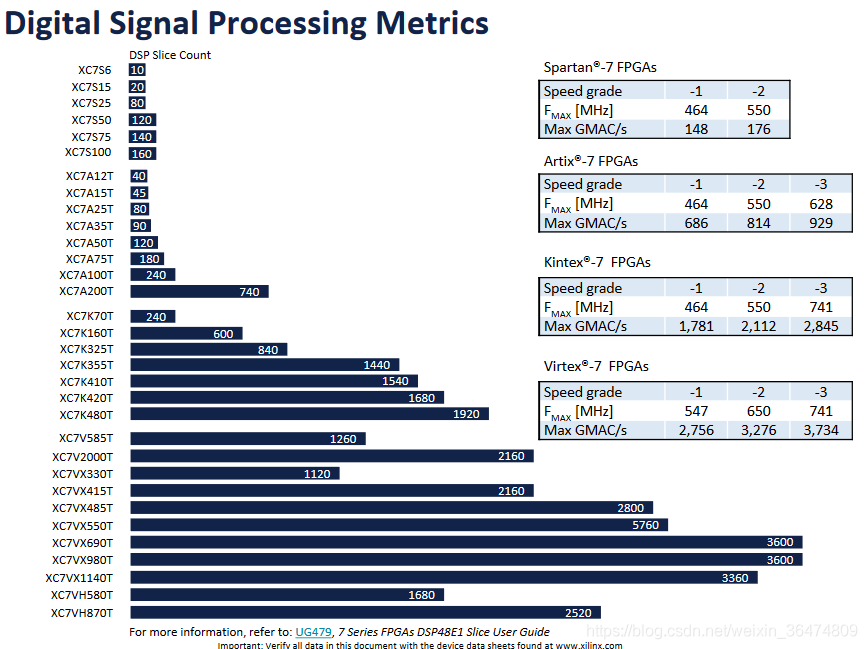
7系列FPGA相關文檔:

原文標題:Xilinx Zynq系列FPGA實現神經網絡中相關資源評估
文章出處:【微信公眾號:FPGA之家】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
FPGA
+關注
關注
1643文章
21952瀏覽量
613812 -
神經網絡
+關注
關注
42文章
4806瀏覽量
102703
原文標題:Xilinx Zynq系列FPGA實現神經網絡中相關資源評估
文章出處:【微信號:zhuyandz,微信公眾號:FPGA之家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何使用MATLAB實現一維時間卷積網絡
FPGA圖像處理基礎----實現緩存卷積窗口





 工商網監
工商網監

評論