 Grace設計是為了填補英偉達人工智能服務器中CPU的空缺
Grace設計是為了填補英偉達人工智能服務器中CPU的空缺
4月12日上午,英偉達召開了春季GPU技術大會,圖形和加速器設計師宣布他們將再次設計自己的基于Arm的CPU。這款CPU以計算機編程先驅、美國海軍少將格蕾絲?霍珀(Grace Hopper)的名字命名,它是英偉達在全面垂直整合硬件堆棧方面的最新嘗試,能夠在提供常規GPU產品的同時提供高性能CPU。據英偉達介紹,該芯片是專為大規模神經網絡工作負載設計的,預計將于2023年在英偉達的產品中使用。
距離芯片準備就緒還有兩年的時間,英偉達這次表現得相對低調,只提供了芯片的部分細節。例如,它將基于Arm的Neoverse內核的未來迭代產品,因為目前更多關注的是英偉達未來的工作流模式,而不是速度和輸出。至少目前,英偉達已經明確表示,Grace是英偉達的內部產品,將作為其大型服務器產品的一部分。該公司并沒有直接瞄準英特爾Xeon或AMD EPYC服務器市場,相反,他們正在建造自己的芯片來補充他們的GPU產品,創造一種可以直接連接他們的GPU的專用芯片,幫助處理參數規模達到萬億級的人工智能模型。
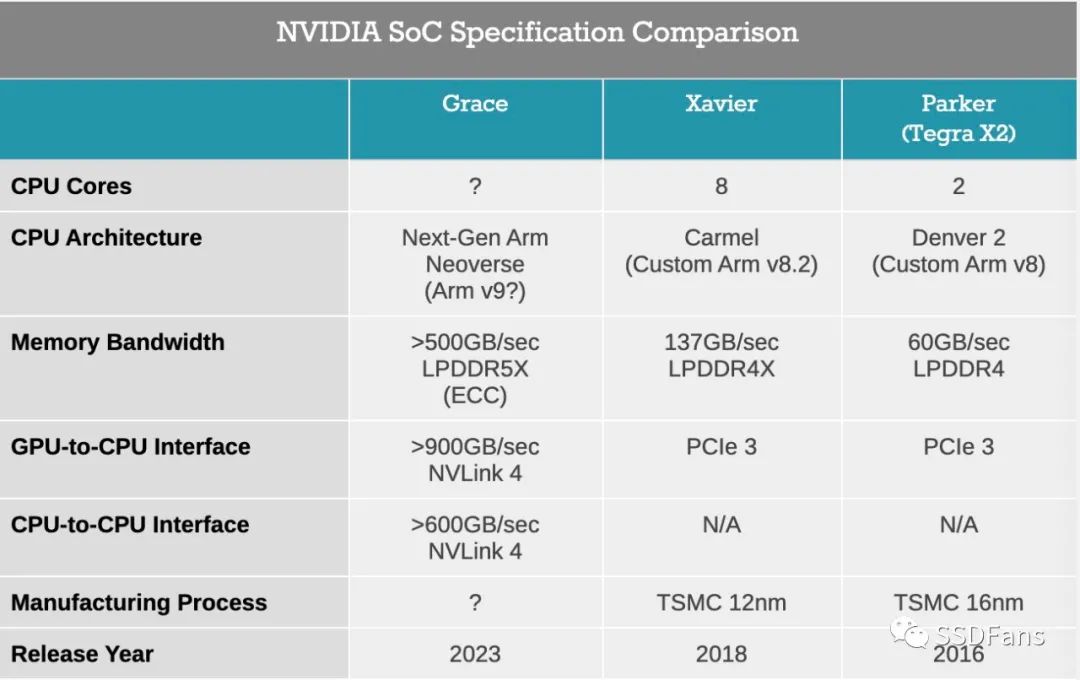
總的來說,Grace的設計是為了填補英偉達人工智能服務器中CPU的空缺。公司的GPU非常適合于特定的深度學習模型,但不是所有模型都必須依賴于GPU。英偉達當前的服務器產品通常依賴于AMD的EPYC處理器,該處理器對于一般的計算目的來說速度非常快,但缺少英偉達尋找的那種高速I/O和深度學習優化。更重要的是,英偉達目前因使用PCI Express進行CPU-GPU連接而遇到瓶頸。它們的GPU可以通過NVLink在彼此之間快速對話,但不能返回主機CPU或系統RAM。
這個問題的解決方案是使用NVLink進行CPU-GPU通信,就像Grace之前的情況一樣。正是出于這個原因,英偉達曾與OpenPOWER基金會合作,將NVLink引入到POWER9中。然而,隨著POWER的流行度下降,以及POWER10跳過了NVLink,這種關系似乎正在逐漸消失。而英偉達正在以自己的方式構建帶有NVLink功能的Arm服務器CPU。
根據英偉達的說法,最終的結果將是一種高性能、高帶寬的CPU與未來一代的英偉達服務器GPU協同工作。在英偉達談論將每個英偉達 GPU與一個Grace CPU集成在一塊板上的情況下(類似于今天的夾層卡),不僅CPU性能和系統內存隨GPU的數量而增加,而且通過回旋方式,Grace可以用作英偉達 GPU的各種協處理器。這是一個非常英偉達解決方案,不僅可以提高性能,而且在AMD或Intel的CPU與GPU嘗試類似的集成與融合的情況下,可以給他們一個反擊。
到2023年,英偉達將達到NVLink 4, SoC和GPU之間的累積帶寬將至少達到900GB/秒,Grace SoC之間的累積帶寬將超過600GB/秒。關鍵是,這大于SoC的內存帶寬,意味著英偉達的GPU將有一個到CPU的高速緩存鏈接,可以在全帶寬下訪問系統內存,同時也允許整個系統擁有一個單一的共享內存地址空間。英偉達將此描述為平衡系統中可用的帶寬數量。擁有內置CPU是增加內存有效量的主要手段,因為英偉達的GPU仍然是大型神經網絡的主要限制因素,由于內存容量的限制,只能有效地運行與本地內存池一樣大的網絡。
而且,這種以內存為中心的策略也反映在Grace的內存池設計中。由于英偉達將CPU與GPU放在一個共享的軟件包中,因此他們打算將RAM放在它旁邊。配備Grace的GPU模塊將包括一定數量的LPDDR5x內存,而英偉達的目標是至少500GB /秒的內存帶寬。在2023年,LPDDR5x可能會成為帶寬最高的非顯卡存儲器選項,此外,由于LPDDR5x技術的根源是移動設備,而且追蹤長度非常短,英偉達還在大力宣傳使用LPDDR5x可以提高能源效率。而且,由于這是服務器部分,Grace的內存也將啟用ECC。
至于CPU性能,實際上這是英偉達所說得最少的部分。該公司將使用下一代Arm的Neoverse CPU內核,,在這方面,最初的N1設計已經吸引了大量眼球。除此之外,該公司還表示,在SPECrate2017_int_base的吞吐量基準測試中,這款處理器的內核將突破300點,與AMD的一些第二代64核EPYC處理器相當。該公司也沒有透露太多關于CPU是如何配置的,或者針對神經網絡處理的優化是如何添加的。但由于Grace的目的是支持英偉達的GPU,預計它會在GPU普遍較弱的情況下變得更強。
另外,如前所述,英偉達為Grace設計的遠大目標是大大減少了大型神經網絡模型訓練所需的時間。英偉達的目標是在1萬億參數模型上提高10倍的性能,
而他們對64個模塊的Grace+A100系統(具有理論上的NVLink 4支持)的性能預測將把這種模型的訓練時間從一個月縮短至三天。或者,能夠在8個模塊的系統上對5000億個參數模型進行實時推斷。
總體而言,這是英偉達在數據中心CPU市場的第二次真正嘗試,也是第一次有可能成功。英偉達的Project Denver計劃最初是在十年前宣布的,但從未像英偉達預期的那樣取得真正的成果。定制的Arm內核家族從來都不夠好,也從未使用英偉達的移動SoC制成。相比之下,Grace對于英偉達來說是一個更安全的項目。它們只是授予Arm內核許可,而不是構建自己的內核,這些內核也將被其他許多方使用。因此,英偉達的風險降低了,主要是在I/O和內存方面做得很好,并保持最終設計的節能效果。
如果一切都按計劃進行,那么有望在2023年見到Grace。英偉達已經確認Grace模塊將可用于HGX載板,以及擴展為DGX和所有其他使用這些板的系統。因此,盡管我們還沒有看到英偉達Grace計劃的全部內容,但很明顯,他們正在計劃使其成為未來服務器產品的核心部分。
兩個超級計算機客戶:CSCS和LANL
盡管Grace要到2023年才能發貨,但英偉達已經找到了首批客戶,而且他們都是超級計算機的客戶。瑞士國家超級計算中心(CSCS)和洛斯阿拉莫斯國家實驗室今天宣布,他們將訂購基于Grace的超級計算機。這兩套系統都將由惠普的克雷集團(Cray group)建造,預計將于2023年上線。
CSCS的系統稱為Alps,將替換其當前的Piz Daint系統,即Xeon和英偉達 P100集群。根據兩家公司的說法,Alps將提供20 ExaFLOPS的AI性能,大概是CPU,CUDA內核和張量內核吞吐量的組合。推出時,Alps應該是世界上最快的以人工智能為中心的超級計算機。
有趣的是,CSCS對系統的雄心壯志不僅限于機器學習工作負載。該研究所表示,他們將把Alps作為通用系統,從事更傳統的HPC類型任務以及以AI為重點的任務。這包括CSCS對天氣和氣候的傳統研究,而AI之前的Piz Daint也已用于該研究。
如前所述,Alps將由HPE建造,后者將基于其先前宣布的Cray EX架構。這將使英偉達的Grace與AMD的EPYC處理器一起成為Cray EX的第二個CPU選項。
與此同時,Los Alamos的系統正在開發,作為實驗室與英偉達之間持續合作的一部分,而LANL將成為美國第一個使用Grace系統的客戶。盡管實驗室計劃利用Grace提供的最大數據集規模來計劃將其用于3D仿真,但LANL并未討論系統的預期性能是否超出“領導級別”的事實。LANL系統定于2023年初交付。
原文標題:Grace:英偉達數據中心CPU市場的第一次成功嘗試!
文章出處:【微信公眾號:ssdfans】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
cpu
+關注
關注
68文章
10855瀏覽量
211603 -
英偉達
+關注
關注
22文章
3771瀏覽量
90993
原文標題:Grace:英偉達數據中心CPU市場的第一次成功嘗試!
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論