


引言
2020年,自然語言處理領域頂級的國際學術會議EMNLP(Conference on Empirical Methods in Natural Language Processing)共錄取論文751篇
開放域信息抽取是信息抽取任務的另一個分支任務,其中抽取的謂語和實體并不是特定的領域,也并沒有提前定義好實體類別。更一般的,開放域信息抽取的目的是抽取出所有輸入的文本中的形如 《主語,謂語,賓語》 的三元組。開放域信息抽取對于知識的構建至關重要,可以減少人工標注的成本和時間。
本次Fudan DISC實驗室將分享EMNLP2020中關于開放域信息抽取和文本知識結構化的3篇論文,介紹最新的開放域信息抽取的研究。
文章概覽
關于開放域信息抽取神經網絡結構和訓練方式的系統比較 (Systematic Comparison of Neural Architectures and Training Approaches for Open Information Extraction)
該文將神經網絡基礎的OpenIE框架系統分解為三個基本模塊:嵌入塊、編碼塊和預測模塊。在探究各種組合時,他們發現:pre-training的語言模型+Transformer編碼器+LSTM預測層在OpenIE2016基準上有了巨大的改進(提升200%)。此外,他們還提到,NLL損失函數可能更偏向淺層預測。
OpenIE6:開放域信息的迭代網格標記抽取以及并列短語分析 (OpenIE6: Iterative Grid Labeling and Coordination Analysis for Open Information Extraction)
該文將OpenIE任務的三元組抽取構建為2-D(#extraction #words)網格標記任務,使得通過迭代抽取可以將一個句子中的所有三元組都有概率被模型識別出來。該文將他們的抽取方式稱為IGL(Iterative Grid Labeling),并在計算損失函數的時候加4種入關于詞性的軟約束,并在最終的loss計算時加起來作為約束懲罰項。實驗結果表明了他們模型的有效。
DualTKB: 在文本和知識庫之間進行雙重學習 (DualTKB: A Dual Learning Bridge between Text and Knowledge Base)論文地址:https://www.aclweb.org/anthology/2020.emnlp-main.694.pdf
該文建立了多個任務將某些文本(選項A)或KB中的路徑三元組(選項B)作為輸入,然后兩個解碼器分別生成文本(A)或另一個三元組(B)。也就是說,你可以有多種路線,例如A-B(從文本中提取三元組)或B-B(知識圖譜補全)等。重復這個過程,你可以從文本中迭代提取更多三元組,或者對知識圖譜反向解碼為文本。
論文細節
1

任務定義
現有的OpenIE的任務定義主要分為兩種:1)序列標注、2)子序列提取
其中序列標注框架最為常見,下圖為用序列標注任務設定的開放域信息抽取。例子中一共有7類標簽

子序列通過模型生成大量的可能的子序列三元組組合,模型負責給這些候選組合進行打分,并選出概率最高的幾個三元組作為抽取結果。
作者通過比較這兩種任務設定,總結出統一的OpenIE的任務設定:OpenIE任務將每一個問題定義為一個元組《X,Y》,其中將一個句子表示成有很多個詞語的序列,定義了一個合法的抽取結果集合。如果是建模為序列標注問題,則是BIO標簽;如果看作子序列提取問題,則是子序列集合。
方法
模型結構:文中對神經網絡OpenIE的方法進行全方位的總結,作者將目前的框架分為了三個模塊:1)Embedding Module;2)Encoding Module;3)Prediction Module;各模塊的種類如下圖。
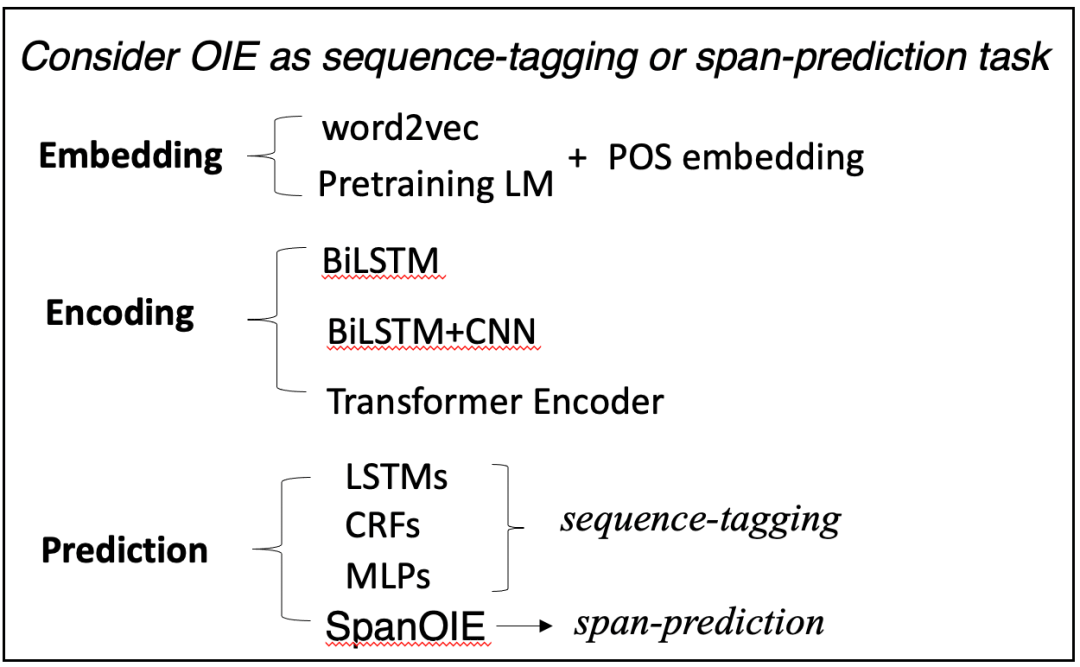
作者針對以上三個模塊進行了不同組合,做了很多實驗進行比較哪種組合方式是最好的。
訓練方法:在進行訓練的時候會遇到標簽分類負樣本標簽的數量遠遠大于其他標簽數量的情況,作者對這個問題提出了三種解決方案。如下圖所示,第一種解決方案是在計算損失函數時不計算預測出標簽的數據;第二種是計算預測出標簽和非標簽的邊緣部分的損失函數;第三種是只計算邊緣部分的非部分的損失函數值。
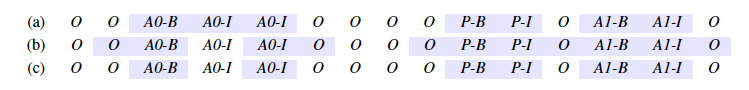
數據集和評價指標數據集來自于OIE16的benchmark 數據集,評價指標采用F1值和AUC-PR。
實驗結果
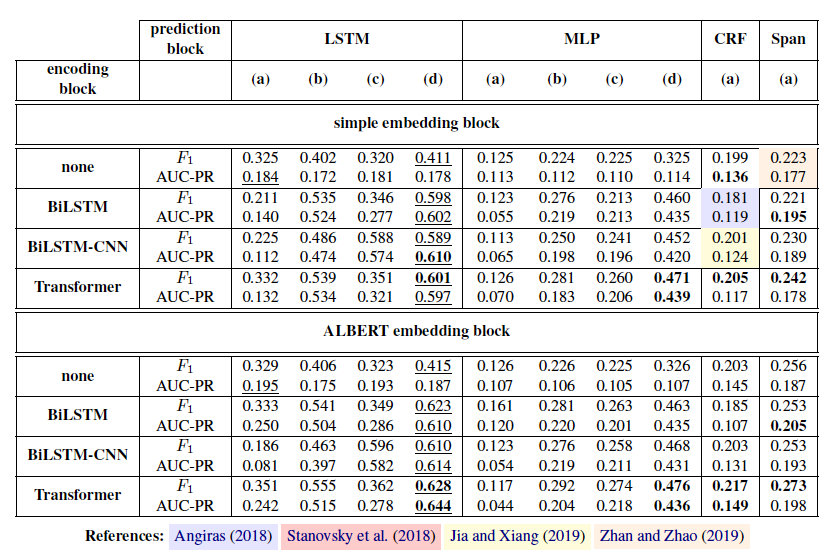
從主實驗可以看出最優的組合是 ALBERT+Transformer+LSTM,并且用最后一種訓練方式訓練的模型。
作者對每個模塊和訓練方式還進行了消融實驗如下。

該實驗說明,embedding層使用Transformer效果最好。
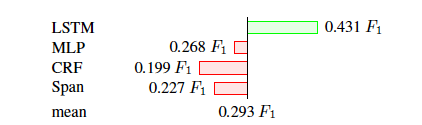
該實驗說明,預測層使用LSTM效果最好。
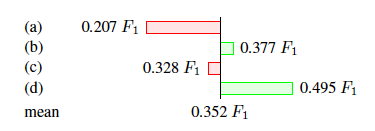
該實驗說明,使用最后一種訓練方式的效果是最好的。
2
論文動機
文中介紹了目前OpenIE最主流的兩種框架:1)生成類的系統(通過迭代多次編碼輸入的文本,以進行多次抽取);2)序列標注系統。這兩種框架都存在弊端:1)生成系統多次重復encoding輸入的文本,會造成抽取速度慢,并不能很好的適應大數據時代的大量網頁抽取場景;2)而序列標注系統,對于每個抽取都是獨立的,并不能獲取其他抽取內容的信息。
任務定義
給定一句話作為輸入,然后抽取出一個集合作為抽取的結果,其中每個是一個的三元組。由于一句話中可能含有多個可抽取的三元組,如下圖。
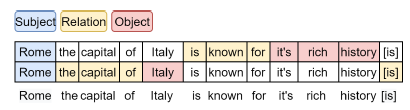
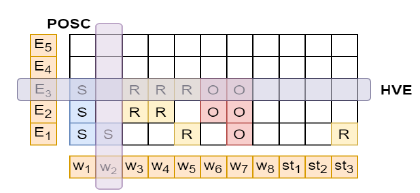
作者將這個任務建模為一個在2-D網格上進行迭代抽取的任務,網格的大小為,橫坐標為句子分詞,縱坐標為抽取出的結果。例如,坐標為的網格代表第n個詞的第m次的預測標簽,如下圖。
方法
模型(Iterative Grid Labeling)
作者提出了一個迭代網格抽取方法,去完成這個網格抽取任務,其實就是利用迭代抽取,然后將上一節定義的的網格填滿預測標簽,模型圖如下:
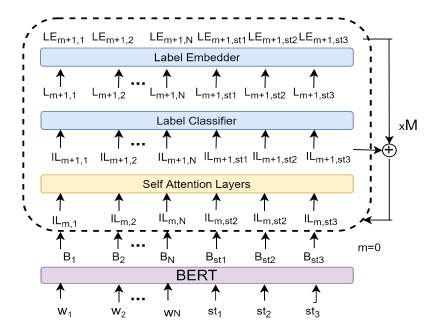
該結構一共迭代M次,每一次詞向量都需要經過一個相同結構的模塊如上圖,模塊中包含一個transformer 編碼器的self-att層、一個又多層感知機組成的標簽分類器和一個標簽嵌入層。每次迭代后詞向量編碼器的輸出會加入下一次的輸入中去,以達到迭代信息傳遞的作用。文中作者將該方法稱做IGL-OIE,訓練得到的損失函數為。
網格約束
在進行抽取的時候,作者提出了四種軟約束來限制抽取的結果,一共有四種:1)POS Coverage(POSC);2)Head Verb Coverage(HVC);3)Head Verb Exclusivitu(HVE);4)Extraction Count(EC)。POSC約束了句子中的每個名詞、動詞、形容詞和副詞至少有一個要出現在抽取結果中;HVC約束了句中每一個頭動詞(有意義的動詞)至少出現在其中一個抽取結果的關系中;HVE約束了每個抽取結果的關系只能有一個動詞;EC約束了所有抽取結果的數量要少于句中所有頭動詞的數量。作者根據以上定義的約束,制定了以下四種損失函數懲罰項:
,
,
,
,
,
。
將以上約束和抽取訓練的loss加起來得到總的損失:
并列連詞檢測
作者利用網格抽取和前人的并列連詞抽取工具,設計了并列連詞檢測的方法稱做IGL-CA,如下圖
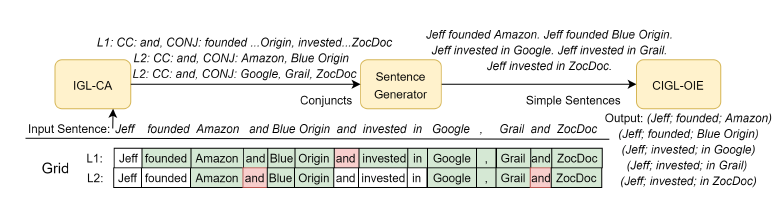
真正訓練的時候先用IGL-CA將長句根據并列連詞位置拆成簡單句,再進行IGL-OIE進行抽取。
數據集和實驗準備
訓練數據集來自于Open-IE4,同時也是用來訓練IMoJIE的數據集。用于比較的模型有IMoJIE、RnnOIE、SenceOIE、SpanOIE、MinIE、ClasusIE、OpenIE4和OpenIE5。實驗評價在CaRB、CaRB(1-1)、OIE6-C和Wire57-C上,并以F1和AUC作為評價指標。
實驗結果
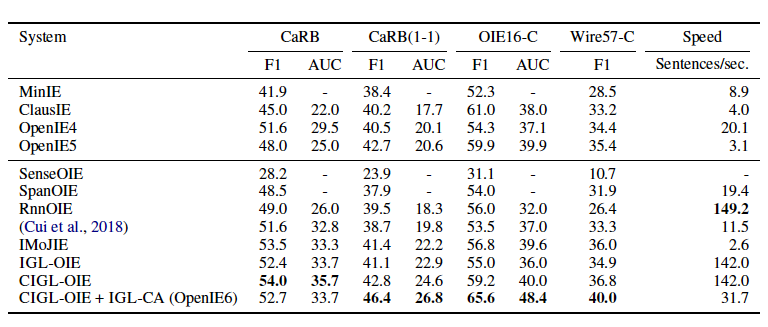
從實驗結果看出本文提出的OpenIE6在三個評價數據集上都取得了最好的成績,而且當加入了軟約束后速度加快了5倍,該模型在準確率不降的基礎上,加快了推理速度。
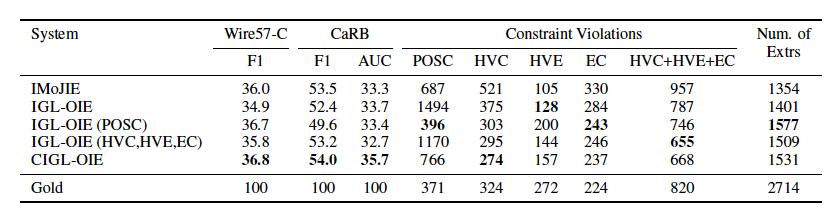
作者還分析了各約束間的關系,發現最有用的是POSC約束。
3

動機和貢獻
構建知識圖譜是一項很費人力的事情,這項工作提出了一種知識的轉換器,用于轉換純文本和知識圖。換句話說,如果給模型很多句子,模型就可以把這些句子變成一個圖存儲成知識圖譜。反過來,給模型一個圖,可以利用圖中節點和邊的關系,將圖還原成帶有知識的句子。
任務定義
任務1(文本路徑):
給定一句話,然后生成一個具有格式正確的實體和關系的路徑,該路徑和實體可以屬于已經構造的KB,也可以以一種實際有意義的方式對其進行擴展。此條件生成被構造為稱為的翻譯任務,其中。
任務2(路徑文本):
給定KB路徑,則生成描述性句子,將路徑中的實體和關系連貫地合并。此條件生成是稱為的翻譯任務,其中。
下圖給定了一些標記符號:

方法
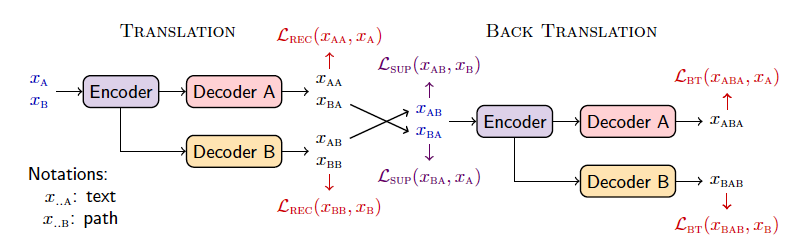
由于缺少KB和文本對應的數據集,所以作者首先想到了采用自編嗎器的方式設計了四個無監督的任務:(1)文本到文本(AA)(2)圖到圖(BB)(3)文本到圖到文本(ABA)(4)圖到文本到圖(BAB)。這四個任務分別對應上圖的、、和。計算公式如下:
由于作者采用的數據集是ConceptNet,然后作者找到了構建ConceptNet的語料集合,然后作者采用實體和關系在文本中進行模糊匹配的方式對齊了一些圖路徑和文本的訓練對,由于這個轉換是不準確的所以只能是弱監督學習,在模型圖中對應的任務是(1)圖到文本(BA)和(2)文本到圖(AB),損失函數如下:
實驗設計
本文的實驗選取了常識領域的文本數據OMCS,和常識知識圖譜ConceptNet(CN600K)。因為CN600K中的部分三元組是從OMCS中抽取得來,所以部分文本和路徑所表達的知識是相同的。對于弱監督數據,文中使用Fuzzy Matching的方式對齊文本和路徑。需要注意的是,因為對齊的數據是基于路徑和文本之間的相似度進行選擇的,所以對齊的數據是有噪聲的。
文中涉及文本生成任務和知識圖譜補全任務,所以評價指標根據任務的不同有著變化。總體來說,生成任務包括BLEU2、BLEU3、Rougel和F1;知識圖譜補全任務采用了常用的MRR和HITS@N指標。由于作者還設計了一個通過一堆句子生成新圖的任務,所以需要一個指標來評價新圖和原來的圖有多少不同,因此引入了圖編輯距離(GED)來評價這個任務。
實驗結果
文本路徑互轉的性能

從文本到文本的效果很好,但是如果通過中間圖轉化的話效果就會差很多,說明跨模態的知識遷移能力需要提高。
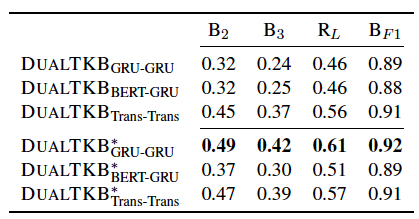
如果直接用路徑生成文本,效果就更差了,但是本文提出了一種新穎的思想。
知識圖譜補全任務
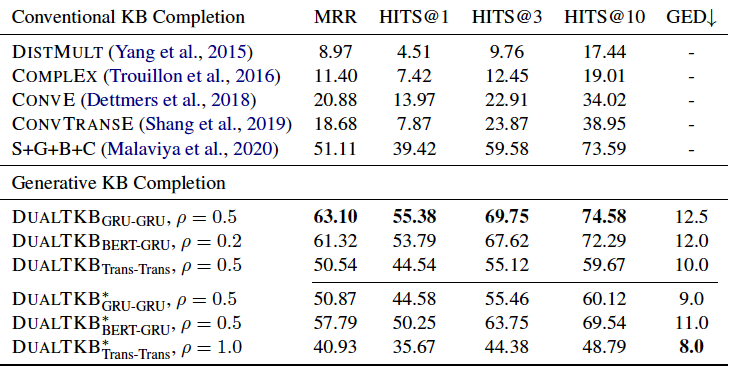
在知識圖譜補全任務上,本文提出的模型優于前人的baseline,值得注意的是,代表了弱監督的比例,從實驗結果來看,并不是弱監督越多越好,因為帶有很多噪音。因此作者還對應該加入多少弱監督進行了探索,實驗結果如下:
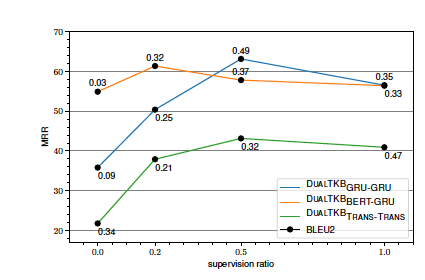
發現大致是加入0.5比例的監督效果是在最好的模型上表現提升較多。
編輯:lyn
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103804 -
LSTM
+關注
關注
0文章
60瀏覽量
4060
發布評論請先 登錄
理想汽車八篇論文入選ICCV 2025
智能體AI面臨非結構化數據難題:IBM推出解決方案
云知聲四篇論文入選自然語言處理頂會ACL 2025

從零到一:如何利用非結構化數據中臺快速部署AI解決方案
AI知識庫的搭建與應用:企業數字化轉型的關鍵步驟
非結構化數據中臺:企業AI應用安全落地的核心引擎
了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
迅為RK3568開發板篇OpenHarmony實操HDF驅動控制LED-接口函數
結構化布線在AI數據中心的關鍵作用
TSMI252012PMX-3R3MT功率電感詳細解析






 工商網監
工商網監

評論