


本文主要是對eBPF進行介紹,帶大家了解eBPF是什么、通過eBPF可以做些什么事情。
1.BPF起源
BPF源頭起源于一篇1992年的論文,這篇論文主要提出一種新的網絡數據包的過濾的框架,如下圖所示。
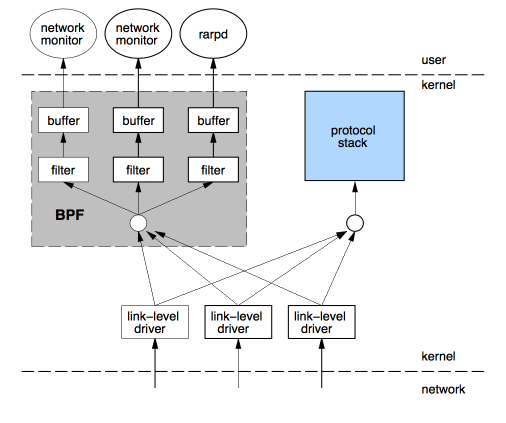
提出bpf的原因其實也很簡單,早期我們從網卡中接收到很多的數據包,我們要想從中過濾出我們想要的數據包,我們需要將網卡接收的數據包都要從內核空間拷貝一份到用戶空間。然后,用戶程序在對這些進行過濾。那么,我們可以從中就能夠發現一個問題。數據包必須全部拷貝。然后再過濾出所需的數據包,那么對于那些不需要的數據包,我們拷貝的操作是無效的、浪費的。并且對于內存數據的拷貝是很費cpu系統的資源的。所以,這篇論文,就提出了一種新的框架,在內核中直接過濾,這也可以避免一些無用的、浪費的拷貝。
其背后的思想其實就是:與其把數據包復制到用戶空間執行用戶態程序過濾,不如把過濾程序灌進內核去。
這種新的框架,其實還是很容易理解的。大概的理解就是,當我們從網卡接收到一個數據包的時候,我們數據鏈路層,將數據包額外的拷貝一份。然后這個新的數據包就交給BPF程序進行處理,這個BPF根據用戶編寫的過濾規則對這個新的數據包進行匹配。如果符合此規則就將數據包放到接收隊列中,那么用戶事后就可以從接收隊列中將這個數據包從內核空間拷貝到用戶空間,這樣就減少了無用的數據包的拷貝。
像tcpdump/wireshark等用戶工具就是基于BPF框架實現的。其大概實現的過程就是,編寫BPF指令集的過濾規則,然后創建raw/packet類型的套接字socket,將網卡設置為混雜模式。在通過setsockopt函數將BPF代碼拷貝到內核,并attach到相關聯的socket套接字上。當網卡接收到數據包的時候,因為設置的混雜模式,那么就會額外的拷貝一份新的數據包,然后在根據BPF的代碼進行過濾,將符合規則的數據包接收到socket套接字的接收隊列里面。最后用戶程序就可以從這個接收隊列獲取到過濾后的數據包了。這類工具的實現流程就是大概這個樣子。
2.偽機器碼、BPF指令集、JIT
使用過tcpdump工具的應該都見過在tcpdump命令后面會加一些表達式,用來表示過濾規則。
如:sudo tcpdump -d -i lo tcp and dst port 7070
注意不要以為這個表達式就是BPF程序了,其實這不是的。這個表達式是要經過編譯過后才會變成BPF程序的。在我們早期是生產這類編譯器,那么是如何將這個表達式編譯出BPF指令集的呢?
tcpdump的實現是基于libcap庫的,tcpdump使用的過濾表達式是使用libcap庫進行解析的,生成我們BPF指令集。那為什么沒有單獨做成一個這類的編譯器?究其原因就是但是的BPF框架使用的功能較少,只用在了網絡的數據包過濾方面。除此之外,當時的BPF指令集個數很少,所以沒有必要花費大量的資源單獨做一個編譯器。但是隨著BPF的發展,指令集的復雜、支持的BPF程序類型越來越多,就急需要一個編譯器了。那這個就是我們后面將要提到的eBPF和clang/llvm編譯器了。
偽機器碼:假的機器碼,機器碼都是能夠在物理機上直接執行的,偽機器碼不能夠直接執行,需要在虛擬機上執行。
BPF指令集:BPF指令集就是一個偽機器碼,是不能夠在物理機上直接執行的,需要一個虛擬機才能夠執行。我們都知道不同的處理器體系結構有自己的不同指令集,這邊的BPF指令集可以理解為在BPF虛擬機上執行的指令集。
JIT:just in time 的縮寫,我們將編譯好的BPF指令集需要在虛擬機上執行,虛擬機需要一條一條的解析為本機機器碼才能夠執行,所以這個執行效率會很低,但是如果我們的處理器有了JIT就能夠將我們BPF直接直接編譯為能夠在機器直接執行的機器碼,這樣大大提高了執行的速度。
3.eBPF介紹
eBPF是extend BPF的簡稱,擴展的BPF。我們剛了解BPF了,都知道BPF的功能比較單一只能夠作用于網路的數據包的過濾上,但是擴展后的BPF的功能得到了很大的豐富,可以這樣說基本上可以使用在Linux各個子系統中。除了功能上的擴展,BPF程序的指令集也變得相當復雜了,所以就出現了專門用于編譯BPF程序的clang/llvm編譯。在框架上BPF的框架也發生了變化,所以擴展后的BPF不再是早期的BPF的可以比擬的。因而,早期的BPF被稱為cBPF,擴展后的BPF被稱為eBPF。
現在看下擴展后的BPF的框架,如下圖所示:
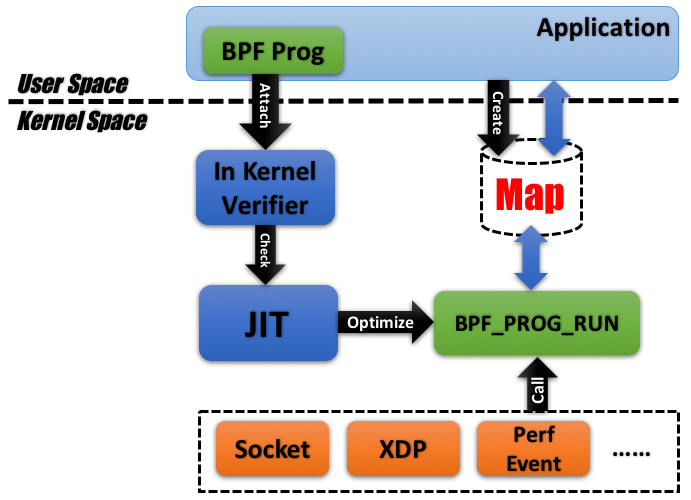
注意:我們后面說的BPF指的是cBPF和eBPF的統稱,除非特別說明。
雖然,框架發生變化,但是其基本的思想還沒有發生變化的。都是將BPF程序進行編譯后生成字節碼,然后將BPF字節碼注入到內核中,當發生事件觸發的時候,我們就會執行相應的BPF程序。
現在,我們對cBPF和eBPF進行對比:
一、cBPF支持的功能比較單一,只能夠作用于網絡的數據包的過濾上。而eBPF除了能夠支持網絡的數據包的過濾上,也支持其他的事件類型,如上圖中的XDP、Perf Event、kprobe、tracepoint等等。cBPF的功能在eBPF其實對應的就是Socket的部分。
二、引入Map機制。在cBPF我們通過接收隊列將過濾后數據獲取出來,但是在eBPF我們可以將數據放到Map空間中。Map空間是用戶空間和內核空間共享的,所以一般是在內核中將數據存入到Map空間中,然后在用戶空間取出數據。
三、指令集變得更復雜了,與此同時,有了專門的用于編譯BPF字節碼的編譯器clang/llvm。
四、還有在安全機制方面等等一些改變。
4.eBPF類型和Map機制
首先,看下eBPF支持的類型,其中BPF_PROG_TYPE_SOCKET_FILTER對應的就是早期cBPF的功能。只不過在eBPF中使用的框架不再是以前的cBPF的框架了,但是其實現的功能是一樣的。
bpf_prog_typeBPF prog 入口參數(R1)程序類型
BPF_PROG_TYPE_
SOCKET_FILTERstruct __sk_buff用于過濾進出口網絡報文,功能上和 cBPF 類似。
BPF_PROG_TYPE_
KPROBEstruct pt_regs用于 kprobe 功能的 BPF 代碼。
BPF_PROG_TYPE_
TRACEPOINT這類 BPF 的參數比較特殊,根據 tracepoint 位置的不同而不同。用于在各個 tracepoint 節點運行。
BPF_PROG_TYPE_
XDPstruct xdp_md用于控制 XDP(eXtreme Data Path)的 BPF 代碼。
BPF_PROG_TYPE_
PERF_EVENTstruct bpf_perf_event_
data用于定義 perf event 發生時回調的 BPF 代碼。
BPF_PROG_TYPE_
CGROUP_SKBstruct __sk_buff用于在 network cgroup 中運行的 BPF 代碼。功能上
和 Socket_Filter 近似。具體用法可以參考范例
test_cgrp2_attach。
BPF_PROG_TYPE_
CGROUP_SOCKstruct bpf_sock另一個用于在 network
cgroup 中運行的 BPF 代碼,范例 test_cgrp2_sock2 中就展示了一個利用 BPF 來控制 host 和 netns 間通信的例子。
Map機制的優勢:
Map機制引入的原因,其中一個最大的原因就是通信。對于Map空間是用戶和內核共享的,我們可以在內核中將處理后的數據直接存入Map空間。然后,可以從用戶空間中進行獲取。這樣就是大大方便了通信。除此之外,我們在內核中進行數據處理后,相應的數據的占用的空間就會變小的很多,然后,在將數據存入到Map空間中。想比較于cBPF需要將數據獲取到后,在進行處理,這樣可以大大節省存儲空間。
Map機制下的常見的數據類型:
CategorySourceBpf_map_type用途
ArrayArraymap.cBPF_MAP_TYPE_ARRAY
BPF_MAP_TYPE_CGROUP_ARRAY BPF_MAP_TYPE_PERF_EVENT_ARRAY BPF_MAP_TYPE_PERCPU_
ARRAY BPF_MAP_TYPE_
ARRAY_OF_MAPS實際就是數組,所以所有的 key 必須是整數。
BPF_MAP_TYPE_PROG_
ARRAY該類型是一個特例,主要用于自定義函數,利用
JUMP_TAIL_CALL令跳轉
HashHashmap.cBPF_MAP_TYPE_HASH
BPF_MAP_TYPE_PERCPU_HASH BPF_MAP_TYPE_
LRU_PERCPU_HASH BPF_MAP_TYPE_HASH_OF_
MAPS真正意義上的 map 數據類型,如果 key 值為整數以外的類型必須使用
Stack
TraceStackmap.cBPF_MAP_TYPE_STACK_TRACE真正意義上的 map 數據類型,如果 key 值為整數以外的類型必須使用存儲特定應用在某一特定時間點的棧狀態(包括內核態和用戶態),key 只有兩個:分別為內核棧 id 和
用戶棧 id,利用 bpf_get_stackid()獲取;
Longest Prefix
Match
TrieLpm_trie.cBPF_MAP_TYPE_LPM_
TRIE基于 Longest Prefix
Match 前綴樹實現,適宜處理以 CIBR 為鍵值時的情況
5.BPF程序編寫使用的語言
對于早期的cBPF程序的編寫,一般都是直接使用BPF指令集來編寫程序。像tcpdump這類工具,提供的使用方法可以類似于高級語言的人性化的表達式的使用,但是其實還是一樣的,只不過是讓libcap進行解析了。BPF程序的編寫難度是極高的。
后來,由于BPF的擴展,急需要一種高級語言來編寫BPF程序,就出現了c語言的編程。通過c語言進行編寫,然后,通過clang/llvm將c語言編譯為BPF字節碼,然后在注入到內核中。但是對于注入的方式,還是需要通過自己手動的方式才能夠注入。
后來,就出現了BPF Compiler Collection(BCC),BCC 是一個 python 庫,但是其中有很大一部分的實現是基于 C 和 C++的,python 只不過實現了對 BCC 應用層接口的封裝而已。使用bcc的最大好處是,用戶只需要關注BPF程序的設計,對于剩余的工作都不用管,包括編譯、解析 ELF、加載 BPF 代碼塊以及創建 map 等等基本可以由 BCC 一力承擔,無需多勞開發者費心。
6.BPF工作原理總結
首先,看下BPF框架圖,如下圖所示:
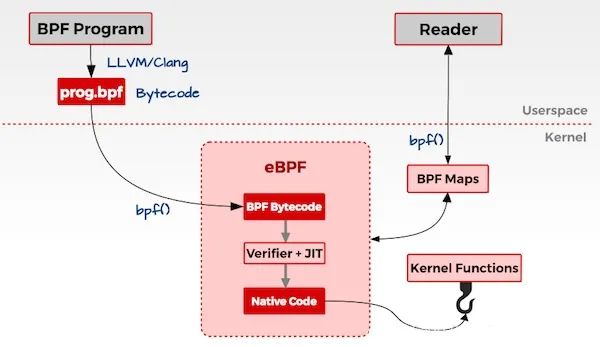
一般我們都是通過c語言編寫BPF程序,然后通過clang/llvm編譯器,將BPF程序編譯為BPF字節碼。然后通過bpf系統調用,將BPF字節碼注入到內核中,在注入的時候,我們必須要經過BPF程序的驗證,來保證我們寫的BPF程序沒有問題,以防干掉我們的系統。然后,在判斷是否開啟了JIT,然后開啟了,還需要將BPF字節碼編譯為本機機器碼,以加快運行速度。
當我們BPF程序attach的事件觸發了,就會執行我們的BPF程序,然如是經過JIT編譯過后的就能夠直接執行,然后沒有開啟JIT就需要通過虛擬機進行解析在執行。在執行BPF程序的過程中,會將需要保存的數據存儲到map空間中,用戶時候可以從map空間讀取出數據。BPF程序的大致流程就是這個樣子。
注意:BPF是基于事件觸發的。這是什么意思呢?
就是如果我們將BPF程序attach到某個事件上,當這個事件觸發的時候,就會執行我們這個BPF程序。其實這就是BPF的工作原理。
如,我們將BPF程序attach到kprobe類型的事件上,這個kprobe事件是個函數,當cpu執行到這個函數的時候,就會觸發。然后就會執行我們的BPF程序。
7.eBPF的作用
eBPF能夠用于內核追蹤、應用性能調優/監控、流量控制等方面,是非常有用的。
針對用于監控、跟蹤使用的eBPF程序來說,主要是通過在內核運行的過程中,來獲取內核運行時的一些參數和統計信息。例如:系統調用的參數值、返回值,然后通過Map空間,將得到的信息傳遞給用戶態的程序,進而可以在用戶程序中在進行邏輯處理。
eBPF除了能夠獲取內核運行的狀態信息,也能夠改變內核的處理流程,可以在內核某些路徑上加入直接的處理邏輯,來改變內核的運行的流程。例如:XDP,就是在網卡驅動中,在進入內核協議棧之前插入eBPF的擴展的網絡包的過濾和轉發功能。
編輯:lyn
-
Linux
+關注
關注
87文章
11519瀏覽量
214010 -
Extended
+關注
關注
0文章
2瀏覽量
7658 -
MAP
+關注
關注
0文章
49瀏覽量
15531 -
BPF
+關注
關注
0文章
26瀏覽量
4367
原文標題:eBPF介紹
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
隔離式收發器的工作原理與作用
倍頻器的工作原理及作用
光學儀器的工作原理 光學儀器的種類及功能
超級電容電池的工作原理
輔助電源的工作原理
補償電容的作用和工作原理是什么
工業廠房人員定位管理系統的工作原理、功能及作用





 工商網監
工商網監

評論