") Transformer深度學習架構(gòu)的應用指南介紹
Transformer深度學習架構(gòu)的應用指南介紹
近年來,自然語言處理(Natural Language Processing, NLP)模型在文本分類、機器翻譯、認知對話系統(tǒng)、自然語言理解(Natural Language Understanding, NLU)信息檢索和自然語言生成(Natural Language Generation, NLG)等語言和語義任務中取得了顯著的成功。這一壯舉主要歸功于開創(chuàng)性的Transformer架構(gòu),導致了諸如BERT、GPT (I、II、III)等設計。盡管這些大尺寸模型取得了前所未有的性能,但它們的計算成本很高。因此,一些最近的NLP架構(gòu)已經(jīng)使用了遷移學習、剪枝、量化和知識蒸餾的概念來實現(xiàn)適度的模型規(guī)模,同時保持與前人取得的性能幾乎相似。此外,為了從知識抽取的角度緩解語言模型帶來的數(shù)據(jù)量挑戰(zhàn),知識檢索器已經(jīng)被構(gòu)建,以更高的效率和準確性從大型數(shù)據(jù)庫語料庫中提取顯式數(shù)據(jù)文檔。最近的研究也集中在通過對較長的輸入序列提供有效注意的高級推理上。在本文中,我們總結(jié)并檢驗了目前最先進的(SOTA) NLP模型,這些模型已被用于許多NLP任務,以獲得最佳的性能和效率。我們提供了對不同體系結(jié)構(gòu)的詳細理解和功能、NLP設計的分類、比較評估和NLP的未來發(fā)展方向。
I.導言自然語言處理(NLP)是機器學習的一個領域,處理建立和發(fā)展語言模型的語言學。語言建模(LM)通過概率和統(tǒng)計技術確定單詞序列在句子中出現(xiàn)的可能性。由于人類語言涉及單詞序列,最初的語言模型是基于循環(huán)神經(jīng)網(wǎng)絡(RNNs)。由于rnn會導致長序列的消失和爆炸梯度,因此改進的循環(huán)網(wǎng)絡(如lstm和gru)被用來提高性能。盡管lstm有增強作用,但研究發(fā)現(xiàn),當涉及相對較長的序列時,lstm缺乏理解。這是由于稱為上下文的整個歷史是由單個狀態(tài)向量處理的。然而,更大的計算資源導致新的架構(gòu)的涌入,導致基于深度學習[1]的NLP模型迅速崛起。2017年,突破性的Transformer[2]架構(gòu)通過注意力機制克服了LSTM的上下文限制。此外,它提供了更大的吞吐量,因為輸入是并行處理的,沒有順序依賴關系。隨后在2018年推出的基于改進的Transformer模型,如GPT-I[3]和BERT[4],成為了NLP世界的轉(zhuǎn)折點。這些架構(gòu)是在大型數(shù)據(jù)集上訓練的,以創(chuàng)建預訓練模型。
隨后,遷移學習被用于針對特定任務特征的微調(diào)這些模型,從而顯著提高了幾個NLP任務[5],[6],[7],[8],[9],[10]的性能。這些任務包括但不限于語言建模、情感分析、問答和自然語言推理。這一成就未能實現(xiàn)遷移學習的主要目標,即用最小的微調(diào)樣本實現(xiàn)高模型精度。此外,模型性能需要跨多個數(shù)據(jù)集通用,而不是特定于任務或數(shù)據(jù)集的[11]、[12]、[13]。然而,由于越來越多的數(shù)據(jù)被用于訓練前和微調(diào)目的,高泛化和遷移學習的目標受到了影響。這使得是否應該合并更多的訓練數(shù)據(jù)或改進的體系結(jié)構(gòu)來構(gòu)建更好的SOTA語言模型的決定變得模糊。例如,隨后的XLNet[14]體系結(jié)構(gòu)擁有新穎而復雜的語言建模,這比僅用XLNet數(shù)據(jù)的10% (113GB)進行訓練的簡單BERT體系結(jié)構(gòu)提供了微小的改進。之后,通過引入RoBERTa[15],一個大型的基于BERT的模型訓練了比BERT (160GB)更多的數(shù)據(jù),表現(xiàn)優(yōu)于XLNet。因此,一個更一般化的體系結(jié)構(gòu),并在更大的數(shù)據(jù)上進行進一步訓練,就會產(chǎn)生NLP基準測試。
上述架構(gòu)主要是語言理解模型,其中自然方言被映射到正式解釋。這里的初始目標是將輸入用戶的話語翻譯成傳統(tǒng)的短語表示。對于自然語言理解(NLU),上述模型的最終目標的中間表示由下游任務決定。與此同時,對于NLU模型中的特定任務角色來說,微調(diào)逐漸成為一種挑戰(zhàn),因為它需要更大的樣本容量來學習特定的任務,這使得這種模型從泛化[16]中失去了。這引發(fā)了自然語言生成(NLG)模型的出現(xiàn),與NLU訓練相反,它從相應的被掩蓋或損壞的輸入語義中學習生成方言話語。這種模型與常規(guī)的粗略語言理解的下游方法不同,對于序列到序列的生成任務(如語言翻譯)是最優(yōu)的。T5[17]、BART[18]、mBART[19]、T-NLG[20]等模型在大量的損壞文本語料上進行預訓練,并通過去噪目標[21]生成相應的凈化文本。這種轉(zhuǎn)換很有用,因為NLU任務的額外微調(diào)層對于NLG來說并不需要。
這進一步提高了預測能力,通過零或幾次射擊學習(one-shot learning),使序列生成與最小或沒有微調(diào)。例如,如果一個模型的語義嵌入空間預先訓練了動物識別“貓”、“獅子”和“黑猩猩”,它仍然可以正確預測“狗”,而無需微調(diào)。盡管NLG具有優(yōu)越的序列生成能力,但隨著GPT-III[22]的后續(xù)發(fā)布,NLG的模型規(guī)模呈指數(shù)級增長,這是GShard[23]發(fā)布之前最大的模型。由于NLU和NLG的超大型模型需要加載幾個gpu,這在大多數(shù)實際情況下變得昂貴和資源限制。此外,當在GPU集群上訓練幾天或幾周時,這些巨大的模型需要耗費大量的能量。為了減少計算成本[24],我們引入了基于知識蒸餾(KD)[25]的模型,如蒸餾BERT[26]、TinyBERT[27]、MobileBERT[28],并降低了推理成本和規(guī)模。
這些較小的學生模型(student model)利用較大的教師模型(teacher model,如:BERT)的歸納偏見來實現(xiàn)更快的培訓時間。類似地,剪枝和量化[29]技術在建立經(jīng)濟規(guī)模模型方面得到了廣泛的應用。剪枝可以分為3類:權(quán)重剪枝、層剪枝和頭部剪枝,即將其中某些最小貢獻的權(quán)重、層和注意頭從模型中刪除。像剪枝一樣,訓練感知的量化被執(zhí)行以實現(xiàn)不到32位的精度格式,從而減少模型的大小。為了獲得更高的性能,需要更多的學習,這將導致更大的數(shù)據(jù)存儲和模型大小。
由于模型的龐大和隱性知識存儲,其學習能力在有效獲取信息方面存在缺陷。當前的知識檢索模型,如ORQA[30]、REALM[31]、RAG[32]、DPR[33],通過提供對可解釋模塊知識的外部訪問,試圖減輕語言模型的隱式存儲問題。這是通過用“知識檢索器”來補充語言模型的預訓練來實現(xiàn)的,它有助于模型從像維基百科這樣的大型語料庫中有效地檢索和參與明確的目標文檔。此外,Transformer模型無法處理超出固定標記范圍的輸入序列,這限制了它們從整體上理解大型文本主體。當相關單詞的間隔大于輸入長度時,這一點尤其明顯。因此,為了增強對語境的理解,我們引入了Transformer-XL[34]、Longformer[35]、ETC[36]、Big Bird[37]等架構(gòu),并修改了注意機制,以處理更長的序列。此外,由于對NLP模型的需求激增,以實現(xiàn)經(jīng)濟上的可行性和隨時可用的邊緣設備,創(chuàng)新的壓縮模型推出了基于通用技術。這些是前面描述的蒸餾、修剪和量化技術之外的技術。這些模型部署了廣泛的計算優(yōu)化程序,從散列[38]、稀疏注意[39]、因式嵌入參數(shù)化[40]、替換標記檢測[41]、層間參數(shù)共享[42],或上述的組合。
II. 相關綜述/分類我們提出了一種新的基于NLP的分類法,從六個不同的角度對當前的NLP模型進行了獨特的分類:(一)NLU模型:NLU善于分類,結(jié)構(gòu)化預測或查詢生成任務。這是通過由下游任務驅(qū)動的預培訓和微調(diào)來完成的。(二)NLG模型:與NLU模型不同,NLG模型在順序生成任務中表現(xiàn)突出。他們通過少量的、一次性的學習,從相應的錯誤話語中生成干凈的文本。(三)減少模型尺寸:采用KD、剪枝、量化等基于壓縮的技術,使大型模型更經(jīng)濟實用。它對于在邊緣設備上操作的大型語言模型的實時部署很有用。(四)信息檢索(Information Retrieval, IR):上下文開放域問答(Contextual open domain question answer, QA)依賴于有效、高效的文檔檢索。因此,IR系統(tǒng)通過優(yōu)越的詞匯和語義提取物理來自大型文本語料庫的文檔在QA領域中創(chuàng)建SOTA,其性能優(yōu)于當代語言模型。(五)長序列模型:基于注意力的Transformers模型的計算復雜度與輸入長度成二次關系,因此通常固定為512個tokens。這對于受益于較小輸入長度[43]的共引用解析任務來說是可以接受的,但是對于需要跨多個冗長文檔(例如HotpotQA數(shù)據(jù)集[44])進行推理的問答(QA)任務來說是不夠的。(六)有效率的計算架構(gòu):為了減少大型語言模型的高訓練時間,我們構(gòu)建了精度與大型語言模型相當?shù)膬?nèi)存效率架構(gòu)。
上述分類是一種廣義分類,而不是硬分類,一些模型可以互換使用,可能有雙重目的,但有明確的劃分,盡管不具有普遍性。圖1描述了這種分類法,給出了屬于不同類別的重要模型及其發(fā)布年份的可視化分類。
III.現(xiàn)代NLP體系結(jié)構(gòu)的雛形傳統(tǒng)的RNN編碼器-解碼器模型[45]由兩個遞歸神經(jīng)網(wǎng)絡(RNN)組成,其中一個生成輸入序列的編碼版本,另一個生成其解碼版本到一個不同的序列。為了使輸入序列的目標條件概率最大化,該模型與以下語言建模聯(lián)合訓練:
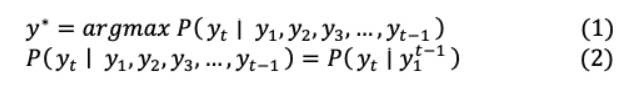
通過在機器翻譯、序列到序列映射或文本摘要任務中實現(xiàn)相位對的條件概率,這種系統(tǒng)得到了優(yōu)于普通rnn、lstm[46]或gru[47]的結(jié)果。
在上述架構(gòu)(圖2)中,編碼器的最后一層 +1從其最終隱藏的 +1層向解碼器傳輸信息,該層包含了通過概率分布對之前所有單詞的整個上下文理解。所有單詞的組合抽象表示被輸入到解碼器,以計算所需的基于語言的任務。就像它的前一層一樣,最后一層是相應的可學習參數(shù)為 +1和 +1在輸入和輸出分別在編碼器和 ‘ +1, ’ +1在解碼器。結(jié)合隱含狀態(tài)和偏差的權(quán)重矩陣,可以用數(shù)學表示為:
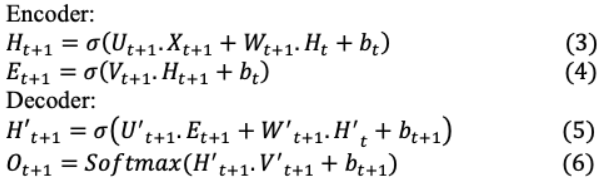
此后,在2014-15年注意力[48],[49]的導入克服了RNN編碼器-解碼器的限制,即先前的輸入依賴,使其難以推斷更長的序列,并遭受消失和爆炸梯度[50]。注意機制通過最后一個Encoder節(jié)點禁用整個輸入上下文來消除RNN依賴關系。它單獨權(quán)衡提供給解碼器的所有輸入,以創(chuàng)建目標序列。這導致了更大的上下文理解,也導致更好的預測目標序列的生成。首先,對齊決定了 th輸入和 th輸出之間的匹配程度,可以將其確定為

更準確地說,對齊得分以所有編碼器輸出狀態(tài)和之前解碼的隱藏狀態(tài)為輸入,表示為:
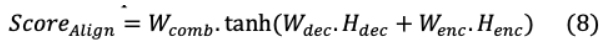 解碼器的隱藏狀態(tài)和編碼器輸出通過它們各自的線性層及其可訓練權(quán)值傳遞。每個編碼的隱藏表示h 的權(quán)重 計算為
解碼器的隱藏狀態(tài)和編碼器輸出通過它們各自的線性層及其可訓練權(quán)值傳遞。每個編碼的隱藏表示h 的權(quán)重 計算為

這一注意機制中產(chǎn)生的上下文向量由以下因素決定:
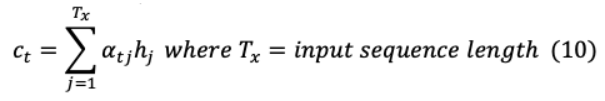
注意機制本質(zhì)上是根據(jù)不同位置的對齊分數(shù)計算出上下文向量的生成,如圖3所示。Luong的注意機制在對齊得分計算方面與上述的Bahdanau不同。它同時使用全局和局部注意,其中全局注意使用所有編碼器輸出狀態(tài),而局部注意關注單詞的一個小子集。這有助于實現(xiàn)較長的序列的高級翻譯。這些注意力設計導致了現(xiàn)代Transformer架構(gòu)的開發(fā),該架構(gòu)使用了一種增強的注意力機制,如下一節(jié)所述。
IV.NLU架構(gòu)NLU的神經(jīng)語言表征傳輸方法表明,與從頭學習[51],[52]相比,預訓練的嵌入可以改善下游任務的結(jié)果。隨后的研究工作加強了學習,以捕獲上下文化的單詞表示,并將它們轉(zhuǎn)移到神經(jīng)模型[53],[54]。最近的努力不僅限于[55]、[56]和[57],通過為下游任務添加端到端語言模型微調(diào),以及提取上下文單詞表示,進一步構(gòu)建了這些思想。這種工程進展,加上大量計算的可用性,使得NLU的最先進的方法從轉(zhuǎn)移詞嵌入到轉(zhuǎn)移整個數(shù)十億參數(shù)語言模型,在NLP任務中取得了前所未有的成果。現(xiàn)代NLU模型利用Transformer進行建模任務,并根據(jù)需求專門使用基于編碼器或解碼器的方法。這樣的模型將在下一節(jié)中進行生動的解釋。
IV-A TRANSFORMERSIV-A.1. The Architecture最初的Transformer是一個6層的編碼器-解碼器模型,它通過編碼器從源序列中通過解碼器生成目標序列。編碼器和解碼器在較高的層次上由自注意層和前饋層組成。在Decoder中,中間的額外關注層使其能夠?qū)⑾嚓P標記映射到Encoder,以實現(xiàn)轉(zhuǎn)換目的。“自我注意”可以在不同的位置查找剩余的輸入單詞,以確定當前處理的單詞的相關性。這是為所有輸入的單詞執(zhí)行的,這有助于實現(xiàn)一個高級編碼和上下文理解所有單詞。在RNN和LSTM的順序數(shù)據(jù)中,輸入標記被即時輸入,并通過編碼器同時生成相應的嵌入,構(gòu)建了Transformer架構(gòu)來引入并行性。這種嵌入將一個單詞(標記)映射到一個可以實時預訓練的向量,或者為了節(jié)省時間,實現(xiàn)了一個類似GloVe的預訓練嵌入空間。但是,不同序列中的類似標記可能有不同的解釋,這些解釋通過一個位置編碼器來解決,該編碼器生成關于其位置的基于上下文的單詞信息。然后,將增強的上下文表示反饋給注意層,注意層通過生成注意向量來進一步語境化,注意向量決定了 h單詞在一個與其他單詞相關的序列中的相關性。然后這些注意向量被輸入前饋神經(jīng)網(wǎng)絡,在那里它們被轉(zhuǎn)換成更容易理解的形式,用于下一個“編碼器”或解碼器的“編碼器-解碼器注意”塊。后者與編碼器輸出和解碼器輸入嵌入,執(zhí)行注意兩者之間。當解碼器在源和目標映射之間建立實際的向量表示時,這將確定Transformer的輸入標記與其目標標記的相關性。解碼器通過softmax預測下一個單詞,softmax在多個時間步長內(nèi)執(zhí)行,直到生成句子標記的末尾。在每個Transformer層,有剩余連接,然后進行層歸一化[58]步,以加快反向傳播過程中的訓練。圖4展示了所有Transformer體系結(jié)構(gòu)的細節(jié)。
IV-A.2. Queries, Keys, and ValuesTransformer的注意機制的輸入是目標tokens查詢向量 ,其對應的源tokens密鑰向量 和值 ,它們都是嵌入矩陣。在機器翻譯中,源標記和目標標記的映射可以通過內(nèi)點積來量化每個標記在序列中的相似程度。因此,要實現(xiàn)準確的翻譯,關鍵字應與其對應的查詢,通過兩者之間的高點積值。假設 ?{ , }和 ?{ , },其中 , 表示目標長度和源長度, 表示單詞嵌入維度。Softmax的實現(xiàn)是為了實現(xiàn)一個概率分布,其中所有查詢,密鑰相似點加起來為一個,并使注意力更集中于最佳匹配的密鑰。
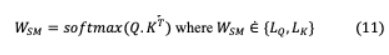
查詢?yōu)殒I分配匹配的概率,值通常與鍵相似,因此
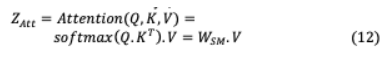
IV-A.3. Multi-Headed Attention (MHA) and MaskingMHA通過多次并行實現(xiàn)注意力,增強了模型強調(diào)序列不同標記位置的能力。由此產(chǎn)生的個人注意輸出或頭部通過一個線性層連接和轉(zhuǎn)換到預期的維度。每個頭部都可以從不同的角度參與序列部分,為每個標記提供類似的表示形式。這是執(zhí)行,因為每個標記的自我注意向量可能權(quán)衡它所代表的詞比其他由于高的結(jié)果點積。這是沒有效率的,因為目標是實現(xiàn)與所有tokens進行類似的評估交互。因此,計算8次不同的自我注意,得到8次單獨的注意用于計算最終結(jié)果的每個標記的向量注意向量通過所有8個向量的加權(quán)和tokens。由此產(chǎn)生的多重注意力載體是并行計算,饋給前饋層。每個后續(xù)目標tokens 都使用 +1生成編碼器中的許多源標記( 0,。。., + )。然而,在自回歸解碼器中,只有前一個時間步進考慮目標tokens( 0,。 。, t),為未來目標0 預測的目的被稱為因果掩蔽。提供此功能是為了最大限度地學習隨后轉(zhuǎn)換的目標標記。因此,在通過矩陣運算進行并行化的過程中,保證了后續(xù)的目標詞被屏蔽為零,從而使注意網(wǎng)絡無法預見未來。上面描述的Transformer導致了NLP領域的顯著改進。這導致了我們將在后續(xù)部分中描述的大量高性能體系結(jié)構(gòu)。
IV-B EMBEDDINGS FROM LANGUAGE MODELS: ELMoELMo[59]的目標是生成一個深度上下文的單詞表示,可以建模(i)單詞復雜的句法和語義特征(ii)一詞多義或詞匯歧義,發(fā)音相似的單詞在不同的上下文或位置可能有不同的含義。這些增強帶來了上下文豐富的單詞嵌入,這在以前的SOTA模型(如GloVe)中是不可用的。與使用預先確定的嵌入的模型不同,ELMo考慮所有 個tokens的出現(xiàn)( 1, 2,。 。 )為每個token 在創(chuàng)建嵌入之前的整個序列。作者假設該模型可以通過任務特定的雙向LSTM提取其體系結(jié)構(gòu)頂層的抽象語言屬性。這可以通過組合正向和反向語言模型實現(xiàn)。在時間步 ?1時,前向語言模型根據(jù)(13)所示的輸入序列的前一個觀察到的標記,預測下一個標記 _ 。同樣,在(14)中,倒序后向語言模型在給定未來標記的情況下預測之前的標記。
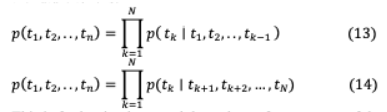
這是通過最終LSTM層之上的softmax進一步實現(xiàn)的,如圖5所示。
ELMo對每個令符表示 _ 在LSTM模型的每一層 上計算其中間雙向向量表示h_ , 為:
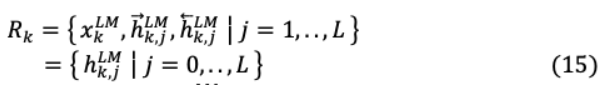
數(shù)學上h^{ }_{k,o}= _k將是最低級別的標記表示,可以概括為:
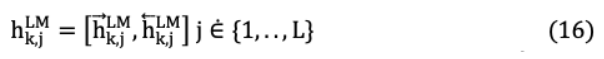
ELMo通過softmax ^{ }_{j}學習關于L層的歸一化權(quán)重層表示。這就產(chǎn)生了一個特定于任務的超參數(shù) ^ ,它支持任務的可伸縮性優(yōu)化。因此,對于一個特定的任務,不同層中的單詞表示差異表示為:
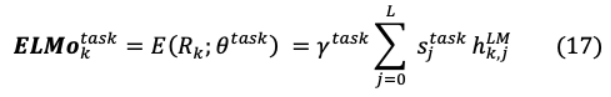
IV-B GENERATIVE PRE-TRAINING MODEL: GPT-I在第一階段,通過無監(jiān)督學習,基于解碼器的GPT-I在一個大數(shù)據(jù)集上進行預訓練。這促進了原始數(shù)據(jù)計算,消除了監(jiān)督學習的數(shù)據(jù)標注瓶頸。第二階段在具有邊際輸入變化的相當小的監(jiān)督數(shù)據(jù)集上執(zhí)行任務特定的微調(diào)。結(jié)果表明,與ELMo、ULMFiT[60]等SOTA模型相比,該模型在更復雜的任務(如常識推理、語義相似性和閱讀理解)中表現(xiàn)出更強的性能。GPT-I的預訓練可以被建模為一個無監(jiān)督標記的最大化函數(shù){ ,…, }。
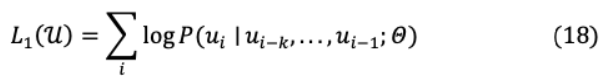
其中 為上下文窗口大小,條件概率通過 參數(shù)化。利用多頭注意和前饋層,通過softmax生成了基于目標標記的概率分布。
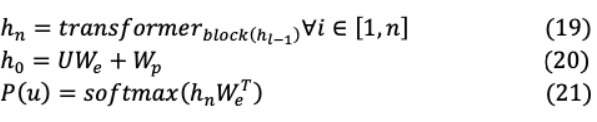
這里( = ? ,。 。, ?1)為上下文標記向量集, 為層數(shù), 和 分別為標記和位置嵌入矩陣。訓練后,對監(jiān)督結(jié)束任務進行參數(shù)調(diào)整。這里輸入序列( ^1,。 。, ^ ),將標記數(shù)據(jù)集 輸入到先前的預訓練模型,以獲得Transformer塊最終激活h^{ }_{l},輸入到參數(shù)化( _y)線性輸出層進行預測 。另外,目標 2( )是最大化如下
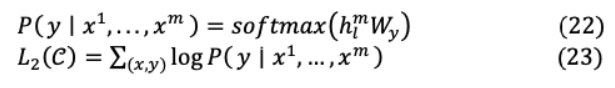
在微調(diào)過程中結(jié)合二級語言建模目標,通過更好地泛化監(jiān)督模型來增強學習,并加速收斂:

GPT執(zhí)行分類、蘊涵、相似度指數(shù)、選擇題(MCQ)等任務,如圖6所示。提取階段從文本主體中提取特征,然后在文本預處理過程中通過‘ Delimiter ’標記將文本分離。分類任務不需要這個tokens,因為它不需要測量多個序列之間的關系。此外,問答或文本蘊涵任務涉及定義輸入,如文檔中的有序句子對或三聯(lián)體。對于MCQ任務,需要在輸入時更改上下文以獲得正確的結(jié)果。這是通過基于Transformer的Decoder訓練目標來實現(xiàn)的,其中輸入轉(zhuǎn)換針對各自的答案進行了微調(diào)。
IV-C BIDIRECTIONAL ENCODER REPRESENTATIONS FROM TRANSFORMER: BERTBERT是一組預訓練的Transformer編碼器克服了先前模型的限制性表達,如:GPT缺乏雙向語境和ELMo的淺薄雙重上下文的連接。BERT的更深層次的模型提供具有多個上下文的tokens層和雙向模型提供了更豐富的學習環(huán)境。然而,雙向性引起了人們的關注,認為tokens可以隱式地預見未來的tokens在訓練期間,從而導致最少的學習和導致瑣碎預測。為了有效地訓練這樣一個模型,BERT實現(xiàn)掩碼語言建模(MLM)每個輸入序列中隨機輸入標記的15%。這種掩碼詞的預測是新要求不一樣的在單向LM中重建整個輸出序列。BERT在訓練前的掩碼,因此[MASK]標記在微調(diào)期間不顯示,從而產(chǎn)生不匹配的“masked”tokens不會被替換。為了克服這個差異,精細的建模修改被執(zhí)行在訓練前階段。如果一個token _i 被選擇為掩碼,那么80%的情況下它會被[MASK]替換token,10%的情況下選擇一個隨機token,剩下的10%沒有改變。此后 _i的交叉熵損失會預測原始的tokens,使用不變的token步長來保持對正確預測的偏差。這種方法為Transformer編碼器創(chuàng)造了一種隨機和不斷學習的狀態(tài),它必須維護每個token的分布式上下文表示。此外,由于隨機替換僅占所有tokens的1.5%(15%中的10%),這似乎不會損害語言模型的理解能力。語言建模不能明確地理解多個序列之間的關聯(lián);因此,它被認為是推理和問答任務的次優(yōu)選擇。為了克服這一問題,我們使用單語語料庫對BERT進行了預訓練,以完成二值化的下一句預測(NSP)任務。如圖7所示,句子 (He came [MASK] from home)和 (Earth [MASK] around Sun)沒有形成任何連續(xù)性或關系。由于 不是 后面實際的下一個句子,輸出分類標簽[NotNext]將被激活,而[IsNext]將在序列一致時被激活。
IV-D GENERALIZED AUTOREGRESSIVE PRETRAINING FOR LANGUAGE UNDERSTANDING: XLNeTXLNet在這兩個方面都取得了最好的效果,它保留了自回歸(AR)建模和雙向上下文捕獲的優(yōu)點。為了更好地理解XLNet為什么優(yōu)于BERT,請考慮5-tokens的序列(San, Francisco, is, a, city)。這兩個標記選擇預測(圣弗朗西斯科),因此BERT和XLNet最大化 ( | )如下:

對于目標( )和非目標標記集( ),以上可進一步一般化,BERT和XLNet將最大化日志 ( | ),并具有以下不同的可解釋性:
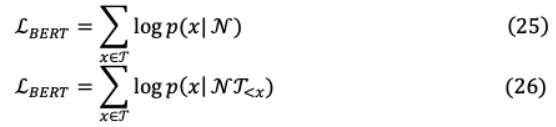
XLNet考慮用于預測的目標標記和其余標記,而BERT只考慮非目標標記。因此,XLNet捕獲對間依賴[San, Francisco],這與BERT不同,在BERT中[San]或[Francisco]都會導致正確的預測。此外,通過AR XLNet對所有可能的tokens排列執(zhí)行因式排序( !)= 5)的序列長度 設置即{(1、2、3、4、5),(1、2、5、4、3 ],。 。 。, [ 5、4、3、2、1]}?[,城市,圣弗朗西斯科)等。
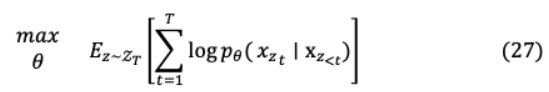
其中set _ 包含所有長度的置換序列 [1,2,。 。, ], _ 是引用標記。因此,目標學習從無數(shù)的組合獲得更豐富更符合實際的學習。此外,對于所有可置換的因子分解順序,模型參數(shù)被共享,以從所有因子中構(gòu)建知識和雙向上下文,如公式27所示。
IV-D.1. Masking由于不考慮決定自回歸的標記( _ ),因此很難確定序列中的詞序。這個詞序部分是通過位置編碼實現(xiàn)的,但是為了上下文理解XLNet使用了屏蔽。考慮一個在3-token序列中生成的排列[2,1,3],其中第一個token(即,2)沒有上下文,因此所有屏蔽結(jié)果都在3×3屏蔽矩陣的第二行[0,0,0]中。類似地,第2和第3個掩碼將導致查詢流(QS)掩碼矩陣的第1行和第3行中[0,1,0]和[1,1,0],tokens不能看到自己。帶有一個對角包含的QS矩陣構(gòu)成了內(nèi)容流(CS)屏蔽矩陣,每個標記都可以看到自己。這個3-token序列屏蔽如下面的圖8所示。
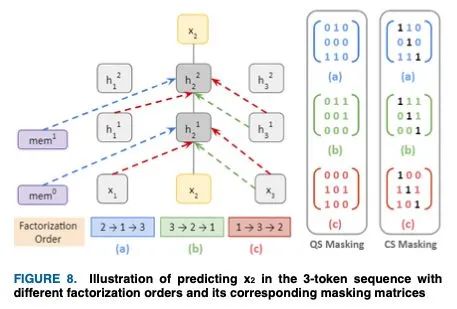
第一個引用‘ 2 ’沒有上下文,它是從對應的‘mem塊’中收集的,這是一個基于transformer-xl的擴展緩存內(nèi)存訪問。此后,它從tokens‘ 3 ’和‘ 1 ’,‘ 3 ’接收上下文,用于后續(xù)排序。
IV-D.2. Model Architecture圖9展示了模型的雙流注意框架,它由內(nèi)容和查詢流注意過程組成,通過上下文實現(xiàn)更好的理解。這個過程是通過目標感知的表示開始的,其中目標位置被烘烤到輸入中,用于后續(xù)的tokens生成目的。
(i)目標感知表示:一種普通的實現(xiàn)基于參數(shù)化的Transformer是不夠的復雜的基于排列的語言建模。這是因為下一個記號分布 ( ∣ )是 《 獨立于目標位置,即 。隨后,產(chǎn)生冗余分布,無法發(fā)現(xiàn)有效表示,因此,我們提出了下一個tokens分布的目標位置感知重參數(shù)化方法:
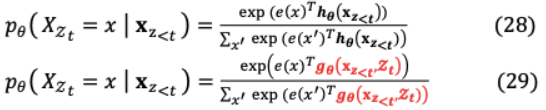
其中 (x 《 , )是一個修改過的表示,它另外將目標位置 視為輸入。(ii)two stream自我注意:盡管有上述解決方案,但 的表述仍然是一個挑戰(zhàn),因為目標是依靠目標位置 通過注意來收集語境信息 《 ,因此:預測其他token _ ,其中 》 , 應該編碼上下文 _ 提供完整的語境理解。為了進一步解決上述沖突,作者提出了以下兩組隱含表示:1)該隱藏內(nèi)容表示h ( 《 )?h that對上下文和內(nèi)容進行編碼2)查詢表示 ( 《 , )? 哪個單獨訪問上下文信息 《 和位置 ,沒有內(nèi)容以上兩個注意課程對每個自我注意層進行參數(shù)化共享和更新 為:

這種雙重關注如圖9所示。為簡單起見,考慮不允許從上一層訪問其對應嵌入的tokens 的預測。然而,為了預測 +1,tokens 需要訪問其嵌入,并且這兩個操作必須在一次傳遞中發(fā)生。因此,實現(xiàn)了兩個隱藏表示,其中h_ ( )通過令幣嵌入初始化, _ ( )通過加權(quán)轉(zhuǎn)換初始化。由上式h( )可以訪問包括當前位置在內(nèi)的歷史,而gzt(m)只能訪問以前的hzt(m)位置。tokens預測通過 ( )發(fā)生在最后一層。為了進行更大的序列長度處理,內(nèi)存塊來自Transformer-xl,它可以處理比標準Transformer輸入序列長度更長的數(shù)據(jù)。上面提到的隱藏表示也存儲在內(nèi)存塊中。
IV-E A Robustly Optimized BERT Pretraining Approach: RoBERTa這篇論文聲稱,BERT是相當缺乏訓練,因此,RoBERTa入了一個更大的訓練密集制度。這是為基于bert的模型,可以匹配或超過以前的方法。他們的改進包括:(i)更長的訓練時間和更大的數(shù)據(jù)和批量(ii)消除BERT的NSP目標(iii)更長的序列訓練(iv)動態(tài)修改的訓練數(shù)據(jù)掩蔽模式。作者聲稱,對于更多樣化和更大量的CC-News數(shù)據(jù)集,下游任務的性能優(yōu)于BERT。此外,BERT實現(xiàn)了一個低效的靜態(tài)屏蔽實現(xiàn),以避免冗余屏蔽。例如,在40個訓練時期,一個序列以10種不同的方式被掩蔽,訓練數(shù)據(jù)重復10次,每個訓練序列用相同的掩蔽被看到4次。RoBERTa通過合并動態(tài)掩蔽提供了略微增強的結(jié)果,在預訓練更大的數(shù)據(jù)集時,每次給模型輸入一個序列時都會生成一個掩蔽模式。最近的研究質(zhì)疑BERT的NSP[61]角色,該角色被推測在語言推理和問答任務中發(fā)揮關鍵作用。RoBERTa合并了這兩種假設,并提供了許多類似BERT的補充訓練格式,并且在不考慮NSP損失的完整句子訓練中表現(xiàn)優(yōu)于BERT。在GLUE基準測試以及RACE和SQUAD數(shù)據(jù)集上,RoBERTa提供的結(jié)果與BERT類似,但稍好于BERT,而無需對多個任務進行微調(diào)。
IV-E MEGATRON LANGUAGE MODEL (LM)Megatron在發(fā)布時是最大的模型,尺寸為24 × BERT和5.6 × GPT-2,不適合單獨的GPU。因此,關鍵的工程實現(xiàn)是歸納其8和64路模型,以及參數(shù)在(~512)gpu上拆分的數(shù)據(jù)并行版本。它保持了高性能(15.1千萬億次)和可伸縮效率(76%),而BERT則導致性能隨尺寸增長而下降。這一壯舉主要歸功于層的規(guī)范化和Transformer層內(nèi)剩余連接的重新排序。這導致在增加模型規(guī)模的下游任務上單調(diào)地優(yōu)越性能。Megatron通過將模型拆分到幾個加速器上,克服了先前模型的內(nèi)存限制。這不僅解決了內(nèi)存使用問題,而且增強了模型的并行性,與批處理大小無關。
它將分布式張量計算集成到涌流模型的大小或加速度中,并將注意頭計算并行化。這不需要新的編譯器或重寫代碼,并且可以通過一些參數(shù)實現(xiàn)。首先,多層感知器(Multi-Layer Perceptron, MLP)塊在兩列中并行劃分GEMM,使GeLU非線性獨立應用于每個劃分的GEMM。這個GeLU輸出被直接發(fā)送到行并行化的GEMM, GEMM的輸出在傳遞到dropout層之前通過一個前進和后退的all-reduce算子(g和f)來減少。自我關注塊中的并行性是通過按列為每個鍵、查詢和值集劃分GEMMs來實現(xiàn)的。因此,由于每個注意力頭在單個GPU上執(zhí)行矩陣乘法,工作負載被分散到所有GPU上。生成的GEMM輸出,像MLP一樣,經(jīng)過了全reduce操作,并跨行并行化,如圖10所示。這種技術消除了MLP和注意塊gem之間的同步需求。
V. NLG ARCHITECTURES在NLU模型中,學習大量經(jīng)過訓練的“微調(diào)”任務所需要的大量數(shù)據(jù)計算在參數(shù)上是低效的,因為每個任務都需要一個全新的模型。這些模型可以作為狹隘的專家而不是精通的多面手的例證。因此,NLG模型提供了一個向構(gòu)建通用系統(tǒng)的過渡,它可以完成幾個任務,而不必為每個任務手動創(chuàng)建和標記一個訓練數(shù)據(jù)集。此外,NLU模型中的傳銷不能捕獲多個序列之間的豐富關系。此外,最有效的NLU模型從傳銷模型變體中派生出其方法,傳銷模型變體是經(jīng)過文本重構(gòu)訓練的去噪自動編碼器,其中單詞的隨機子集被屏蔽掉。因此,在過去的幾年中,NLG模型在文本翻譯和摘要、問答、NLI、會話參與、圖片描述等方面取得了巨大的進展,其準確性達到了前所未有的水平。
V-A LANGUAGE MODELS ARE UNSUPERVISED MULTI- TASK LEARNERS: GPT-IIGPT-II[62]可能是隨著NLG模型的興起而出現(xiàn)的第一個模型。它在無監(jiān)督的情況下接受訓練,能夠?qū)W習包括機器翻譯、閱讀理解和摘要在內(nèi)的復雜任務,而無需進行明確的微調(diào)。其數(shù)據(jù)集對應的任務特異性訓練是當前模型泛化不足的核心原因。因此,健壯的模型可能需要各種任務領域的培訓和績效衡量標準。GPT-II集成了一個通用的概率模型,在該模型中可以執(zhí)行與 ( | , )相同的輸入的多個任務。隨著模型規(guī)模的擴大,訓練和測試集的性能得到了提高,結(jié)果,它在巨大的WebText數(shù)據(jù)集上得到了匹配。在前面提到的零射擊環(huán)境下的任務中,具有15億個參數(shù)的GPT-2在大多數(shù)數(shù)據(jù)集上都優(yōu)于它的前輩。它是GPT-I解碼器體系結(jié)構(gòu)的擴展,訓練了更大的數(shù)據(jù)。
V-B BIDIRECTIONAL AND AUTOREGRESSIVE TRANSFORMERS: BART去噪自動編碼器BART是一個序列到序列[63]模型,它包含兩個階段的預處理訓練:(1)通過隨機噪聲函數(shù)破壞原始文本,(2)通過訓練模型重建文本。噪聲的靈活性是該模型的主要好處,其中不限于對原始文本的長度更改的隨機轉(zhuǎn)換應用。兩個這樣的噪聲變化是原始句子的隨機順序重組和填充方案,其中任何長度的文本被隨機替換為一個mask標記。BART部署了所有可能的文檔損壞方案,如圖11所示,其中最嚴重的情況是所有源信息丟失,BART的行為就像一個語言模型。
這迫使模型在整個序列長度上開發(fā)更大的推理,從而實現(xiàn)更大的輸入轉(zhuǎn)換,從而得到比BERT更好的泛化。BART是通過優(yōu)化被破壞的輸入文檔上的重構(gòu)損失來進行預訓練的,即解碼器的輸出和原始文檔之間的交叉熵。對于機器翻譯任務,BART的編碼器嵌入層被替換為一個任意初始化的編碼器,該編碼器使用預先訓練的模型進行端到端訓練,如圖12所示。這個編碼器將它的外語詞匯映射到BART的輸入,然后去噪到它的目標語言英語。源編碼器的訓練分為兩個階段,這兩個階段共享BART輸出的交叉熵損失的反向傳播。首先,對大部分BART參數(shù)進行凍結(jié),僅對任意初始化的編碼器、BART的位置嵌入以及編碼器的自注意輸入投影矩陣進行更新;其次,對所有模型參數(shù)進行聯(lián)合訓練,迭代次數(shù)較少;BART在幾個文本生成任務上取得了最先進的性能,為NLG模型的進一步探索提供了動力。與RoBERTa相比,它在區(qū)分性任務上取得了比較結(jié)果。
V-C MULTILINGUAL DENOISING PRE-TRAINING FOR NEURAL MACHINE TRANSLATION: mBART
V-C.1. Supervised Machine TranslationmBART表明,通過自回歸預處理訓練BART,通過從公共爬行(CC-25)語料庫中對25種語言的去噪目標進行序列重構(gòu),與之前的技術相比,取得了相當大的性能增益[64]。mBART的參數(shù)微調(diào)可以是有監(jiān)督的,也可以是無監(jiān)督的,適用于任何沒有特定任務修改的語言對。例如,對語言對進行微調(diào),即(德語-英語),使模型能夠從單語訓練前集中的任何語言,即(法語-英語)進行翻譯,而無需進一步訓練。由于每種語言都包含具有顯著數(shù)字變化的標記,語料庫通過對每種語言 進行文本上/下采樣,其比例為 來進行平衡

其中 是數(shù)據(jù)集中每一種語言的百分比平滑參數(shù) = 0.7。培訓數(shù)據(jù)包含 語言: ={ 1,?, },其中每個 是 h語言的單語文檔集合。考慮一個文本破壞噪聲函數(shù) ( ),其中訓練模型預測原始文本 ,因此損失L 最大為:
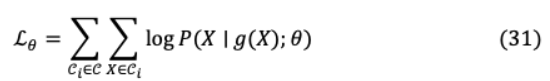
其中語言 有一個實例 和以上的分布 是通過序列到序列模型定義的。
V-C.2. Unsupervised Machine TranslationmBART是在目標雙文本或文本對在這三種不同格式中不可用的任務上進行評估的。1)沒有任何形式的雙文本是可用的,這里后面-翻譯(BT)[67],[68]是一個熟悉的解決方案。mBART提供了一個干凈而有效的初始化方案這樣的技術。2)目標對的雙文本是不可用的,然而,在目標語言的bi-text中可以找到這一對其他語言對的文本語料庫。3)bi-text文本對目標pair是不可用的可從不同語言翻譯到目標語言。這一新的評價方案顯示了mBART在缺乏源語言雙文本的情況下的遷移學習能力mBART是針對所有25種語言進行的預培訓,并針對目標語言進行了微調(diào),如圖13所示。
V-D EXPLORING THE LIMITS OF TRANSFER LEARNING WITH A TEXT-TO-TEXT TRANSFORMER: T5該模型是通過對最有效的遷移學習實踐的調(diào)查和應用建立的。在這里,所有的NLP任務都安排在同一個模型中,超參數(shù)被重新定義為一個統(tǒng)一的文本到文本設置,其中文本字符串是輸入和輸出。需要一個高質(zhì)量的、多樣化的、龐大的數(shù)據(jù)集來測量在110億個參數(shù)T5中訓練前的放大效果。因此,開發(fā)了巨型清潔爬行語料庫(C4),是維基百科的兩倍大。作者的結(jié)論是,因果掩蔽限制了模型的能力,只在 _ h輸入一個序列,這是有害的。因此,T5在序列的前綴部分(前綴LM)包含完全可見掩蔽,而因果掩蔽則用于訓練目標的預測。通過對遷移學習現(xiàn)狀的調(diào)查,我們得出以下結(jié)論。1)模型配置:通常帶有編碼器-解碼器架構(gòu)的模型優(yōu)于基于解碼器的語言模型。2)預訓練目標:去噪對于填空的角色是最有效的,在這個角色中,模型被預先訓練以一個可接受的計算成本來檢索輸入的遺漏詞域內(nèi)數(shù)據(jù)集:域內(nèi)數(shù)據(jù)訓練是有效的,但是預處理小數(shù)據(jù)集通常會導致過擬合。3)訓練方法:一個訓練前的、微調(diào)的多任務學習方法可能是有效的,但是,每個任務的訓練頻率需要被監(jiān)控。4)經(jīng)濟縮放:為了有效地訪問有限的計算資源,對模型尺寸縮放、訓練時間和集成模型數(shù)量進行了評估。
V-E TURING NATURAL LANGUAGE GENERATION: T- NLGT-NLG是一個基于78層變形器的生成語言模型,擁有170億個可訓練參數(shù),比T5更大。它擁有比英偉達的威震天(Megatron)更快的速度,威震天是基于通過低延遲總線互連多臺機器。T-NLG是一個逐漸變大的模型,它預先訓練了更多種類和數(shù)量的數(shù)據(jù)。它通過較少的微調(diào)示例在通用下游任務中提供優(yōu)越的結(jié)果。因此,它的作者概念化訓練一個巨大的集中多任務模型,它的資源在不同的任務之間共享,而不是為一個任務分配每個模型。因此,該模型可以在沒有背景的情況下有效地進行問答,從而增強了零射擊學習。零冗余優(yōu)化器(Zero)同時實現(xiàn)了模型和數(shù)據(jù)并行,這可能是訓練T-NLG高吞吐量的主要原因。
V-F LANGUAGE MODELS ARE FEW-SHOT LEARNERS: GPT-IIIGPT族(I、II和III)是基于Transformer解碼器塊的自回歸語言模型,不像基于去噪自編碼器的BERT。GPT-3從用于生成模型訓練示例的3000億個文本標記的數(shù)據(jù)集中訓練1750億個參數(shù)。由于GPT-3的大小是以前任何語言模型的10倍,并且對于所有任務和目的,它采用了通過文本界面的少量學習,沒有梯度更新或微調(diào),它實現(xiàn)了任務競爭。它采用無監(jiān)督的預訓練,語言模型獲得廣泛的技能和模式識別能力。這些都是在運行中實現(xiàn)的,以快速適應或識別所需的任務。GPT-3在幾個NLP任務中實現(xiàn)了SOTA,盡管它的幾次學習在其他任務中無法復制類似的結(jié)果。
V-G SCALING GIANT MODELS WITH CONDITIONAL COMPUTATION AND AUTOMATIC SHARDING: GShardGShard允許擴展超過6000億個參數(shù)通過稀疏門控混合的多語言機器翻譯在低計算的情況下,采用自動分片的方法對專家(MoE)進行分類成本和編譯時間。變形金剛的規(guī)模很小引入一個由 前饋網(wǎng)絡 ,。, E組成的位置混合專家層,通過其Transformer得到
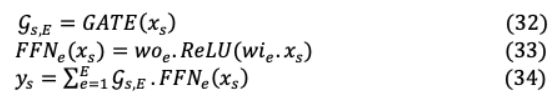
其中 和 是MoE層的標記化輸入和平均加權(quán)輸出, 和 是專家(前饋層)的輸入和輸出投影矩陣。門控網(wǎng)絡通過矢量 , 表示專家對最終輸出的貢獻。這將獲取tokens的非零值,這些tokens被分派給最多兩個專家,這些專家在稀疏矩陣中為非零值做出貢獻。為了實現(xiàn)跨TPU集群的高效并行化:(i)并行化的關注層沿著批處理維度被分割,權(quán)重被復制到所有設備上。(ii)由于大小的限制,不可能在所有設備上復制MoE層專家,因此專家需要在多個設備上分片,如下圖所示。
決定模型質(zhì)量的兩個因素是(i)具有大量訓練數(shù)據(jù)的高資源語言(ii)對數(shù)據(jù)有限的低資源語言的增強。在翻譯模型中,增加任務或語言對會對低資源語言產(chǎn)生積極的語言遷移[69]。對大量語言進行合理的培訓時間和效率的三個方面的策略是:(i)通過堆疊更多層來增加網(wǎng)絡深度(ii)通過復制專家來增加網(wǎng)絡寬度(iii)通過學習到的路由模塊將tokens稀疏地分配給專家。在一個12層的深度模型中,當每層的專家數(shù)量從128增加到512時,在100種語言的BLEU評分中發(fā)現(xiàn)了3.3的顯著性能提升。此外,寬度從512增加四倍到2048會導致BLEU增益減少1.3。將前面提到的專家寬度的層深度進一步增加三倍,從12到36,可以顯著提高低資源語言和高資源語言的性能。
然而,除非模型的容量約束(MoE寬度)不放松,否則增加模型深度并沒有效果。VI. MODEL SIZE REDUCTIONVI-A DISTILLATION知識蒸餾(KD)的目標是在一個更大、更準確的教師模型的監(jiān)督下,通過修正的損失函數(shù)訓練一個較小的學生模型,以在未標記樣本中實現(xiàn)類似的準確性。我們提供了預測的教師模型樣本,使學生能夠通過較軟的班級概率分布進行學習,同時通過一個單獨的損失函數(shù)通過硬目標分類進行預測。這種硬標簽到軟標簽的轉(zhuǎn)換使學生學習的信息變化更大,例如,硬目標將狗分類為{ , , , ∈0,1,0,0},軟目標為{10?6,0.9,0.1,10?9}。對于硬分類計算,深度神經(jīng)網(wǎng)絡的最后一個完全連接層是一個logits 向量,其中 是 h類的logit。因此,可以通過(35)中的softmax函數(shù)評估輸入符合 h類的概率 ,并引入溫度元件 來影響(36)中要轉(zhuǎn)移到學生模型學習中的每個軟目標的重要性。
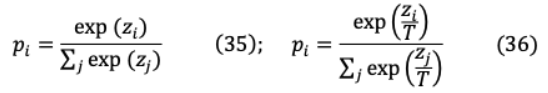
對于類上較軟的概率分布,需要較高的溫度( = )。實驗發(fā)現(xiàn),除了教師的軟標簽外,對學生模型進行正確(硬/地面真理)標簽的訓練是有效的。雖然學生模型不能完全匹配軟目標,但硬標簽訓練進一步幫助它不絆倒在不正確的預測。軟目標精餾損失( = )的計算方法是將教師模型與學生模型的對數(shù)匹配為:
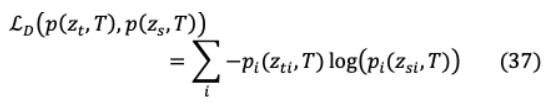
其中 和 分別表示教師模型和學生模型的對數(shù)。蒸餾機理如圖15所示。ground truth label 和學生模型的軟對數(shù)之間的交叉熵構(gòu)成了學生損失:
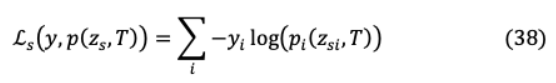
知識蒸餾的標準模型將蒸餾物和學生損失結(jié)合起來,如下圖所示,
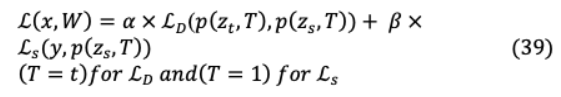
其中 ∈student參數(shù) 。在最初的平均用于 和 ,即 =1? ,為了得到最好的結(jié)果,觀察到 ? 。
VI-A.1. DistilBERTBERT的老師版本保留了BERT 97%的語言理解能力,推理時間更輕、更快,所需的培訓成本更低。通過KD,蒸餾BERT將BERT大小減少了40%,速度提高了60%,壓縮后的模型足夠小,可以在邊緣設備上運行。與BERT相比,蒸餾BERT的層深度被削減了一半,因為兩者具有相同的維度,并且通常具有相同的架構(gòu)。將其歸一化后進行層約簡,最終層線性優(yōu)化計算無效。為了最大化大型預訓練模型的歸納偏差,蒸餾器引入了三重損失函數(shù),將蒸餾(L )與監(jiān)督訓練(L )或掩體語言建模損失線性結(jié)合。我們觀察到用嵌入余弦損失(L )來補充先前的損失是有益的,因為它可以定向?qū)R教師和學生的隱狀態(tài)向量。VI-A.2. TinyBERT為了克服訓練前-微調(diào)范式的提煉復雜性,TinyBERT引入了一個清晰的知識轉(zhuǎn)移過程,通過引入3個損失函數(shù):(i)嵌入層輸出(ii)注意矩陣,(ii)Transformer的隱藏狀態(tài)(iii)輸出Logits這不僅使得TinyBERT在大幅縮減尺寸的情況下保留了BERT的96%以上的性能,而且在所有基于BERT的精餾模型中只部署了28%的參數(shù)和31%的推理時間。此外,它利用了BERT的已學習注意力權(quán)重中未挖掘的可提取潛力[70],對于( + 1) h層,通過最小化:
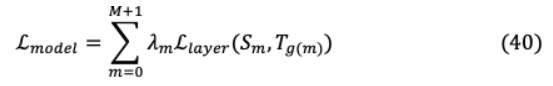
L 是Transformer或an的損耗函數(shù)嵌入層和超參數(shù) 表示 h層精餾的重要性。在TinyBERT中,BERT基于注意力的語言理解增強可以被合并為:
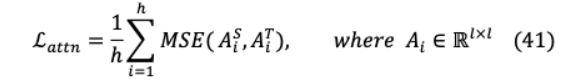
其中h表示正面次數(shù), 表示注意力矩陣對應學生或老師的 h頭, 表示輸入文本長度和均方誤差(MSE)損失函數(shù)。此外,TinyBERT提煉了知識從Transformer輸出層,可以表示為:
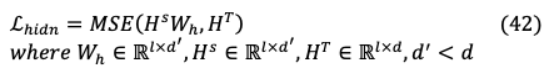
在這里 隱藏的狀態(tài)的學生和教師 ( )分別隱藏大小的教師模型和學生模型是通過標量值 ‘和 表示, 是一個可學習的h將學生網(wǎng)絡的隱藏狀態(tài)轉(zhuǎn)化為教師網(wǎng)絡的空間狀態(tài)。同樣,TinyBERT還對埋層進行蒸餾:

其中 和 分別是學生網(wǎng)絡和教師網(wǎng)絡的嵌入矩陣。除了模擬中間層的行為,TinyBERT通過學生和教師的對數(shù)之間的交叉熵損失實現(xiàn)KD來擬合教師模型的預測。
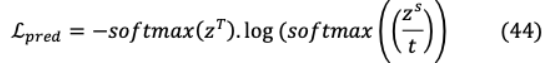
這里 和 分別是教師和學生模型預測的logit。
VI-A.3. MobileBERT與之前的蒸餾模型不同,MobileBERT從BERT中實現(xiàn)任務不可知壓縮,通過預測和蒸餾損失實現(xiàn)訓練收斂。為了訓練這樣一個非常瘦的模型,設計了一個獨特的倒置瓶頸教師模型,該模型結(jié)合了BERT (IB- BERT),知識轉(zhuǎn)移從BERT提煉到MobileBERT。它比BERT小4.3倍,快5.5倍,在基于glue的推理任務中,其競爭分數(shù)比BERT低0.6個單位。此外,Pixel 4手機上62毫秒的低延遲可歸因于用更簡單的Hadamard乘積(薄膜)線性轉(zhuǎn)換取代層歸一化和gelu激活。
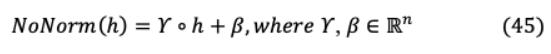
對于知識轉(zhuǎn)移,均方誤差之間將MobileBERT和bert的特征映射實現(xiàn)為遷移目標。
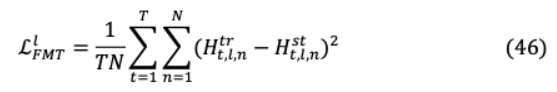
其中 是層索引, 是序列長度, 是特征地圖的大小。為了讓TinyBERT利用BERT的注意力能力,兩種模型的人均分布之間的KL-divergence最小,其中 表示注意頭的數(shù)量。
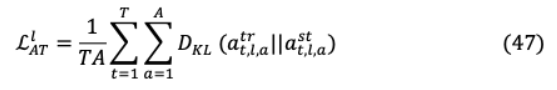
或者,在MobileBERT的預訓練過程中,通過BERT的傳銷和NSP損失的線性組合,可以實現(xiàn)新的KD損失,其中 是(0,1)之間的超參數(shù)。
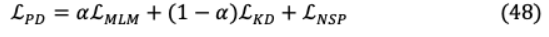 為實現(xiàn)上述目標,現(xiàn)提出3項培訓戰(zhàn)略:(i)輔助知識轉(zhuǎn)移:通過所有層轉(zhuǎn)移損失和蒸餾前訓練損失的線性組合進行中間轉(zhuǎn)移。(ii)聯(lián)合知識轉(zhuǎn)移:為了獲得更好的結(jié)果,提出了2個單獨的損失,其中MobileBERT與所有層聯(lián)合轉(zhuǎn)移損失并進行預先訓練的蒸餾。(iii)漸進式知識轉(zhuǎn)移:為了最大限度地減少自上而下的錯誤轉(zhuǎn)移,提出將知識轉(zhuǎn)移分為 分層 階段,每一層逐步訓練。
為實現(xiàn)上述目標,現(xiàn)提出3項培訓戰(zhàn)略:(i)輔助知識轉(zhuǎn)移:通過所有層轉(zhuǎn)移損失和蒸餾前訓練損失的線性組合進行中間轉(zhuǎn)移。(ii)聯(lián)合知識轉(zhuǎn)移:為了獲得更好的結(jié)果,提出了2個單獨的損失,其中MobileBERT與所有層聯(lián)合轉(zhuǎn)移損失并進行預先訓練的蒸餾。(iii)漸進式知識轉(zhuǎn)移:為了最大限度地減少自上而下的錯誤轉(zhuǎn)移,提出將知識轉(zhuǎn)移分為 分層 階段,每一層逐步訓練。
VI-B PRUNING修剪[71]是一種將不再是模型反向傳播的一部分的某些權(quán)重、偏差、層和激活置零的方法。這引入了這些元素的稀疏性,它們是可見的后ReLU層,將負值轉(zhuǎn)換為零(( ( ): (0, ))。迭代剪枝學習關鍵權(quán)值,根據(jù)閾值消除最不關鍵的權(quán)值,并重新訓練模型,使其能夠通過適應剩余的權(quán)值從剪枝中恢復。像BERT、RoBERTa、XLNet這樣的NLP模型被修剪了40%,并保留了98%的性能,這與蒸餾BERT相當。
VI-B.1 LAYER PRUNINGVI-B.1-A STRUCTURED DROPOUT該體系結(jié)構(gòu)[72]在訓練和測試時隨機丟棄層,使子網(wǎng)絡能夠選擇任何期望的深度,因為網(wǎng)絡已經(jīng)被訓練為具有修剪健壯性。這是對當前技術的升級,需要重新訓練一個新模型,而不是訓練一個網(wǎng)絡,從中提取多個淺層模型。這種子網(wǎng)絡抽樣,如Dropout[73]和DropConnect[74],如果聰明地選擇了同時權(quán)值組,就會構(gòu)建一個高效的健壯修剪網(wǎng)絡。形式上,正則化網(wǎng)絡的修剪魯棒性可以通過伯努利分布獨立地降低每個權(quán)值來實現(xiàn),其中參數(shù)p 》 0控制著跌落率。這相當于權(quán)矩陣 與任意采樣的{0,1)掩碼矩陣 , = ? 的點積。最有效的降層策略是每隔一層降一層,其中修剪率為 ,降層深度為 ,使 ≡0( ?1/ ?)。對于具有固定跌落比率 的 組,網(wǎng)絡訓練期間所利用的平均組數(shù)為 (1? ),因此對于 組的修剪大小,理想跌落率將為 ?= 1? / 。這種方法在許多NLP任務中都非常有效,并且已經(jīng)產(chǎn)生了與BERT精餾版本相當?shù)哪P停⑶冶憩F(xiàn)出更好的性能。
VI-B.1-B POOR MAN’S BERT由于深度神經(jīng)網(wǎng)絡的過度參數(shù)化,在推理時不需要所有參數(shù)的可用性,因此策略性地減少了幾個層,導致下游任務的競爭結(jié)果[75]。在所有任務中,奇數(shù)替代刪除策略的結(jié)果優(yōu)于頂部,甚至在間隔為 = 2的情況下進行替換。例如,在一個12層網(wǎng)絡中,刪除:top - {11,12};偶數(shù)交替- {10,12};奇交替-{9,11},得出的結(jié)論是(i)連續(xù)丟棄最后兩層比消除交替層更有害(ii)保留最后一層比保留頂層其他層更重要。
在 的較高值處,交替刪除方法表示性能下降很大,假設這是由于消除了較低的層造成的。對稱的方法強調(diào)頂層和底層的守恒,而中間層被去掉。這對BERT的影響很小,但卻大大降低了XLNet的性能,從而導致BERT的次優(yōu)策略即使去掉4層后也能給出健壯的結(jié)果。通過觀察,XLNet顯示出比BERT更大的修剪魯棒性,因為它的學習在接近其第7層時變得成熟,而BERT則一直學習到第11層。因此(i)與BERT相比,XLNet在較低的層收集面向任務的知識,(ii) XLNet的最終層可能會變得相當冗余,容易在性能沒有顯著下降的情況下被刪除。作者進一步對蒸餾器進行了下降實驗,在這里下降30%的層導致了最小的性能下降。像以前的模型一樣,頂層下降被證明是最可靠的,因為RoBERTa被證明比BERT更健壯,因為6層的RoBERTa表現(xiàn)出了與蒸餾RoBERTa相似的性能。所有的棄層策略都可以從上面的圖16中可視化。
VI-B.2 WEIGHT PRUNING先前的工作主要集中在非結(jié)構(gòu)化的個體權(quán)剪枝[76],[77],盡管其產(chǎn)生的有效的非結(jié)構(gòu)化稀疏矩陣在傳統(tǒng)硬件上處理具有挑戰(zhàn)性。這使得盡管模型減小了,但仍難以保證推理加速。相反,結(jié)構(gòu)化剪枝強制高度結(jié)構(gòu)化的權(quán)矩陣,當通過密集線性代數(shù)實現(xiàn)優(yōu)化時,會導致顯著的加速,但由于更大的約束,性能低于非結(jié)構(gòu)化剪枝。
VI-B.2-A STRUCTURED PRUNING為了克服上述缺點,本文采用了新穎的結(jié)構(gòu)引入了低秩剪枝范式[78]因式分解保留了稠密矩陣的結(jié)構(gòu)和 0規(guī)范,放松了通過結(jié)構(gòu)化強制執(zhí)行的約束修剪。權(quán)重矩陣被分解成乘積兩個小矩陣的對角掩模修剪而訓練通過 0正則化控制模型的末端稀疏性。這個泛型方法FLOP(Factorized 0 Pruning)可用于任何矩陣乘法。對于神經(jīng)網(wǎng)絡 (; )參數(shù)化 ={ } ,其中每個 表示單個重量 =1 或者一個權(quán)重塊(例如,列矩陣), 表示塊的數(shù)量。考慮一個精簡二值化變量 = ??{ }其中 ∈{0,1}, ={ }表示模型 =1 參數(shù)集,通過 0規(guī)范化后修剪。
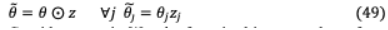 考慮一個矩陣 被分解成兩個的乘積較小的矩陣 和 ,其中 = 。和 表示 列數(shù)或 行數(shù)。每個組件的結(jié)構(gòu)化剪枝是通過剪枝變量 實現(xiàn)的
考慮一個矩陣 被分解成兩個的乘積較小的矩陣 和 ,其中 = 。和 表示 列數(shù)或 行數(shù)。每個組件的結(jié)構(gòu)化剪枝是通過剪枝變量 實現(xiàn)的
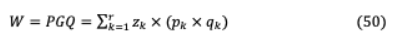
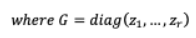 VI-B.3 HEAD PRUNING雖然某些模型在多頭注意力環(huán)境中對多頭注意力有更大的依賴性,但最近的研究表明,可以刪除相當一部分注意力頭,從而形成一個具有更高記憶效率、速度和準確性的精簡模型。在之前的研究中[79],[80]通過對特定位置所有頭部的注意力權(quán)重進行平均,或者根據(jù)最大注意力權(quán)重值來判斷頭部的重要性。然而,這兩種方法都沒有明確考慮不同頭部的波動意義。
VI-B.3 HEAD PRUNING雖然某些模型在多頭注意力環(huán)境中對多頭注意力有更大的依賴性,但最近的研究表明,可以刪除相當一部分注意力頭,從而形成一個具有更高記憶效率、速度和準確性的精簡模型。在之前的研究中[79],[80]通過對特定位置所有頭部的注意力權(quán)重進行平均,或者根據(jù)最大注意力權(quán)重值來判斷頭部的重要性。然而,這兩種方法都沒有明確考慮不同頭部的波動意義。
VI-B.3-A Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, Rest Can Be Pruned這個模型[81]發(fā)現(xiàn)了三個不同層次的頭部角色:(i)位置頭:用于處理相鄰標記(ii)句法頭:注意那些有句法的人(iii)稀有詞頭:最少指示序列中頻繁的標記。基于上述角色[81]這些總結(jié)為:(a)頭的一小部分是翻譯的關鍵(b)關鍵頭擁有一個單一,通常更專門化和可解釋的模型功能(c)頭部角色對應于相鄰標志的注意在顯式語法依賴關系中。高水頭基于層次關聯(lián)傳播(LRP)的可信度[82]與標記的注意力定義的比例有關作為其最大關注權(quán)值的中值計算總的來說,這對于任務來說是至關重要的。通過每個產(chǎn)品修改的Transformer架構(gòu)磁頭的計算表示h 和標量門 , ( , )= ( .h ) ,這里 是輸入獨立頭部特定參數(shù), 0正則化適用于 ,用于較不重要的頭需要被禁用,h∈( h )。
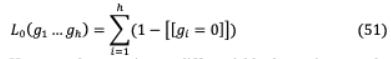
然而, 0 norm是不可微的;因此,它不能作為目標函數(shù)中的正則項歸納。因此,應用隨機松弛,每個門 從頭分布中隨機選取,頭分布是通過拉伸(0,1)到(?∈,1+∈),并將概率分布(?∈,1)坍塌到[1,1 +∈)到奇異點0和1得到的。這種修正的拉伸結(jié)果在[0,1]上的分布是離散-連續(xù)混合的。頭像非零的概率和可以實現(xiàn)為一個寬松的L0范數(shù)。
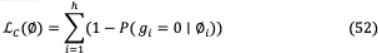
修改后的訓練方案可以表示為L( ,?)= L ( ,?)+ L (?),其中 為原Transformer參數(shù),L ( ,?)為平移模型的交叉熵損失,L (?)為正則器。
VI-B.3-B ARE 16 HEADS REALLY BETTER THAN ONE?在多頭注意力(MHA)中,考慮 的序列 -dimensional vectors = 1,。 。, ∈R ,查詢向量 ∈R 。MHA層參數(shù) h, h h h∈R h× 和 h∈R × h,當 = 。h為了掩蔽注意頭,原Transformer方程修改為:
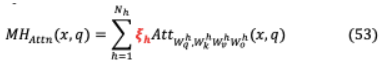
其中 h用值介于{0,1}之間的變量屏蔽, h( )是輸入 的頭h的輸出。以下實驗在測試時間修剪不同的頭數(shù)上獲得了最好的結(jié)果[83]:(i)僅修剪一個頭部:如果模型在屏蔽頭部h時性能顯著下降,則h為關鍵頭部,否則在給定模型的其余部分時,它是冗余的。當被從模型中移除時,僅僅8次(總共96次)正面就會引起表現(xiàn)的顯著變化,其中一半的結(jié)果是更高的BLEU分數(shù)。(ii)除1個注意頭外的所有注意頭修剪:在測試時間內(nèi),大多數(shù)層只修剪一個注意頭就足夠了,即使對于有12或16個注意頭的網(wǎng)絡,也會導致顯著的參數(shù)減少。然而,多個注意頭是特定層的需求,即編碼器-解碼器注意的最后一層,在單個注意頭上性能會降低13.5個BLEU點。模型對掩蔽的期望敏感性 被評估為頭部顯著性的代理評分。
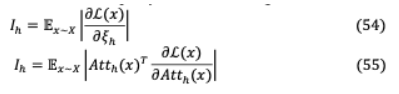
其中 為數(shù)據(jù)分布,L( )為樣本 上的損失。如果 h很高,那么修改 h可能會對模型產(chǎn)生顯著影響,因此,對 h值較低的頭進行迭代修剪。
VI-C QUANTIZATION32位浮點數(shù)(FP32)一直是深度學習的主要數(shù)字格式,然而當前減少帶寬和計算資源的浪潮推動了更低精度格式的實現(xiàn)。已經(jīng)證明通過8位整數(shù)(INT8)的權(quán)值和激活表示不會導致明顯的精度損失。例如,BERT量化為16/8位權(quán)值格式導致4×模型壓縮,精度損失最小,因此,一個擴展的BERT每天服務十億CPU請求。
VI-C.1 LQ-NETS該模型[84]通過深度神經(jīng)網(wǎng)絡的聯(lián)合訓練引入了簡單的網(wǎng)絡權(quán)值和激活機制。它具有可變比特精度的量化能力,這與固定或手動方案不同[85],[86]。一般來說,一個量化函數(shù)可以用幾個比特來表示浮點權(quán)重 ,激活 :
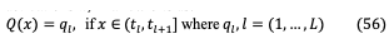
這里 和( , )是量化級別和區(qū)間, +1分別。為了保持快速的推理時間,量化函數(shù)需要與位操作兼容,這是通過均勻分布來實現(xiàn)的用規(guī)范化因子將浮點數(shù)映射到它們最近的定點整數(shù)。LQ可學習量化函數(shù)可以表示為:
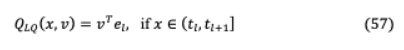
其中 ∈R 為可學浮點基, ∈{?1,1} for =(1,。 。)。, )枚舉 -bit二進制編碼從[?1,。。?1],[1 。 。 1]。量化權(quán)值和激活值的內(nèi)積計算由以下權(quán)值位寬為 的按位操作來計算。
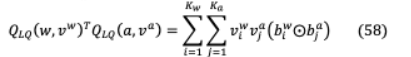
, ∈R 由向量編碼 , ∈{?1,1} , = 1,……, and = 1,…, 和 ∈R , ∈R ,?表示位內(nèi)積 操作。
VI-C.2 QBERTQBERT[87]通過基于交叉熵的損失函數(shù)部署了輸入 ∈ 的雙向BERT量化,其對應的標號y∈
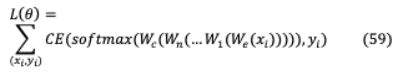
在這里 是嵌入表,編碼器層 , … 和分類器 。分配相同的位大小12 對不同結(jié)構(gòu)[5]不同編碼層不同靈敏度的表示是次優(yōu)的,對于要求超低精度的小目標尺寸(2/4位),它變得復雜。因此,通過Hessian Aware quantification (HAWQ),更多的比特被分配到更大的敏感層,以保持性能。Hessian矩陣是通過計算經(jīng)濟的無矩陣迭代技術計算的,其中第一層編碼器梯度 1為任意向量 :
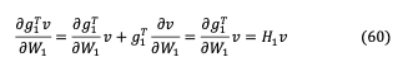
其中 1為第一個編碼器的Hessian矩陣, 獨立于 1,該方法確定不同層的頂部特征值,對特征值較小的層進行更積極的量化。為了進一步利用分組量化的方法進行優(yōu)化,將每個密集矩陣作為一個分組,并根據(jù)其量化范圍對每個連續(xù)輸出神經(jīng)元進行劃分。VI-C.3 Q8BERT為了將權(quán)值和激活量化為8位,實施了對稱線性量化[88],其中 是輸入 的量化縮放因子,( = 2 ?1?1)是量化為 位時的最高量化值。
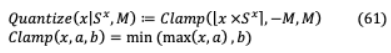
實現(xiàn)偽量化[89]和直通式估計器(STE)[90],推斷時間在訓練過程中以完全精度實現(xiàn)量化反向傳播使FP32權(quán)值克服錯誤。? 這里 = 1,其中 是虛假量化 的結(jié)果。
VII. INFORMATION RETRIEVAL對于高效的數(shù)據(jù)更新和檢索等知識密集型任務,需要大量的隱性知識存儲。標準語言模型不擅長這些任務,也不匹配特定任務的架構(gòu),而這些架構(gòu)對于開放領域的問答是至關重要的。例如,BERT可以預測句子中缺失的單詞,“the __ is the currency of the US”(答案是“dollar”)。然而,由于這些知識隱式地存儲在其參數(shù)中,因此大小會大幅增加,以存儲更多的數(shù)據(jù)。由于網(wǎng)絡的大小限制,存儲空間有限,因此這種約束會增加網(wǎng)絡延遲,并且存儲信息的代價非常昂貴。
VII-A GOLDEN RETRIEVER傳統(tǒng)的基于多跳的開放域QA涉及問題 和包含相關上下文 (gold)文檔 1,。 。,通過文本相似性形成一系列推理,最終得到首選答案 。然而,GoldEn retriver[91]的第一個跳生成一個搜索查詢 1,該查詢?yōu)榻o定的問題 檢索文檔 ,然后進行后續(xù)推理步驟( = 2,。 。)。查詢 由問題( )和可用上下文( 1,。 。)生成。, ?1)。GoldEn迭代地檢索上下文更大的文檔,同時將檢索到的上下文連接起來,以供QA模型回答。它獨立于數(shù)據(jù)集和特定于任務的IR模型,在這些模型中,對附加文檔或問題類型的索引會導致效率低下。采用輕量級RNN模型,從上下文數(shù)據(jù)中提取文本范圍,以潛在地減少龐大的查詢空間。目標是生成一個搜索查詢 ,它可以根據(jù)上下文的文本跨度為下面的推理步驟檢索 , 是從受過訓練的文檔讀者中選擇的。h = ( )[ ](65), ( )= h h(66)其中 和 矩陣將BERT輸出投射到 128 -維的向量。類似地,讀者是BERT的閱讀模型的跨度變體。h = ( )[ ( )],(67)H = ( , )[ ( )],(68)( , , ) ([h ;h ])(69)檢索模型使用反向完形任務(ICT)進行預先訓練,其中句子上下文在語義上是相關的,并用于推斷序列 中缺失的數(shù)據(jù)。( | )= exp( ( , ))(70)∑ ’∈ exp( ( ‘, ))其中 被視為偽問題, 是包圍 的文本, 是用于抽樣否定的一組證據(jù)塊。除了學習單詞匹配特征外,它還學習抽象表示,比如偽問題可能會出現(xiàn)在證據(jù)中,也可能不會。ICT之后,學習被定義為在答案推導上的分布。( | )=exp( ( ))∑ ‘∈ ( )∑ ‘∈ 的exp( ( ”、 ” ))(71)= ( )(62), + 1 = ( )在 查詢生成器和 ( )檢索文檔通過 。
VII-B ORQA組件讀取器和檢索器以端到端方式聯(lián)合訓練,其中實現(xiàn)BERT參數(shù)評分。它可以從開放的語料庫中檢索任何文本,而且不受像典型的IR模型那樣返回固定的文檔集的限制。檢索分數(shù)的計算是問題的 與證據(jù)塊 的密集內(nèi)積。

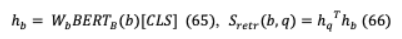 其中 和 矩陣將BERT輸出投射到 128 -維的向量。類似地,讀者是BERT的閱讀模型的跨度變體。
其中 和 矩陣將BERT輸出投射到 128 -維的向量。類似地,讀者是BERT的閱讀模型的跨度變體。
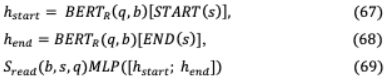
檢索模型使用反向完形任務(ICT)進行預先訓練,其中句子上下文在語義上是相關的,并用于推斷序列 中缺失的數(shù)據(jù)。
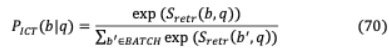
其中 被視為偽問題, 是包圍 的文本, 是用于抽樣否定的一組證據(jù)塊。除了學習單詞匹配特征外,它還學習抽象表示,比如偽問題可能會出現(xiàn)在證據(jù)中,也可能不會。ICT之后,學習被定義為在答案推導上的分布。
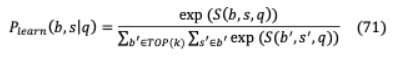
這里, ( )高級檢索模塊基于 。在這個框架中,從完整的維基百科中檢索證據(jù)是作為一個潛在變量來實現(xiàn)的,這是不可能從頭開始訓練的,因此使用ICT對檢索犬進行預先訓練
VII-C REALM這個框架明確地關注像Wikipedia這樣的龐大語料庫,然而,它的檢索器通過反向傳播學習,并通過余弦相似度執(zhí)行最大內(nèi)積搜索(MIPS)來選擇合適的文檔。檢索器的設計目的是緩存和異步更新每個文檔,以克服檢索候選文檔的數(shù)百萬次訂單的計算挑戰(zhàn)。在訓練前,模型需要通過 和 (MIPS)之間向量嵌入的內(nèi)積,即知識檢索相關度 ( , )來預測隨機隱藏token。為了實現(xiàn)基于知識的編碼器,將輸入 和來自語料庫?的檢索文檔 組合為一個序列,以對Transformer ( ∣ , )進行微調(diào),如圖17所示。這使得 和 之間能夠完全交叉關注,從而能夠預測輸出y在哪里:
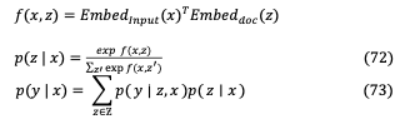
與ORQA一樣,BERT也是為嵌入而實現(xiàn)的:
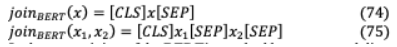 在BERT掩碼語言建模任務的預訓練中,需要將tokens 中的每個掩碼預測為:
在BERT掩碼語言建模任務的預訓練中,需要將tokens 中的每個掩碼預測為:
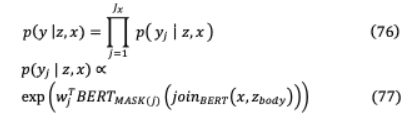
在 ( )代表了Transformer輸出對應于 h屏蔽tokens的向量。是總數(shù)[ ]符號的數(shù)量在 , 是學習詞 嵌入tokens 。對于開放式的Q&A微調(diào)任務,答案 以目標文檔 中的跨標記序列的形式出現(xiàn)。匹配 中 的span集 ( , )可以被建模為:

在 ,跨度 和 的起始標記和結(jié)束標記對應的Transformer輸出向量表示前饋神經(jīng)網(wǎng)絡。
VII-D RETRIEVAL AUGMENTED GENERATION: RAGRAG是“閉卷”(即參數(shù)化模型)和“開卷”(即檢索模型)方法的靈活組合,優(yōu)于當前的語言模型。參數(shù)記憶是一個序列到序列的預訓練模型,而維基百科表示通過一個密集的向量索引構(gòu)成非參數(shù)記憶,它是通過一個預訓練的神經(jīng)檢索器訪問。由于RAG是作為兩者的頂點而構(gòu)建的,它不需要預先訓練,因為與以前的非參數(shù)結(jié)構(gòu)不同,知識可以通過檢索的預先訓練數(shù)據(jù)獲得[92]。為了在輸出序列中實現(xiàn)更大的上下文( )生成,通用的RAG將檢索到的文本段落 用于給定的輸入 ,這涉及兩個主要組件:( )獵犬 ?( ∣ ),通過?參數(shù)化,它返回最匹配的文本段落的內(nèi)容查詢 這 檢索架構(gòu)的通道作為潛變量邊緣達到最大概率 ( ∣ )在top-K近似。
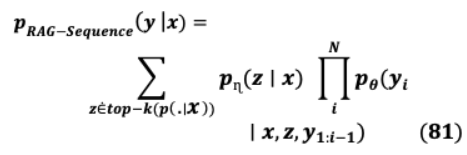
( )發(fā)電機 ( ∣ , , 1: ?1),通過θ參數(shù)化,生成當前tokens 之前的基于上下文表示 ?1tokens 1: ?1,輸入通道 和檢索。模型基于不同的潛在通道預測每個目標tokens,同時使生成器能夠從各種文檔中選擇主題。
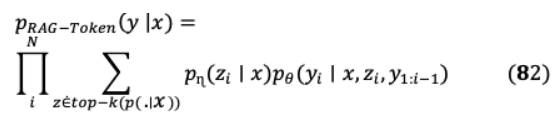
檢索模塊 ?( ∣ )基于密集通道檢索(DPR),其中 ( )是通過BERT生成的文檔密集表示, ( )是通過另一個BERT生成的查詢表示。
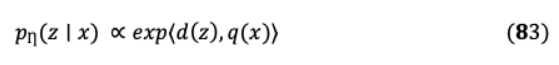
有效計算 ? ( ?(。∣ )元素 with the highest probability ?( ∣ )DPR采用MIPS指數(shù)在巴特用作發(fā)電機 ( ∣ , , 1: ?1)。檢索器和生成器結(jié)合訓練,以半無監(jiān)督的方式檢索目標文檔。
VII-D DENSE PASSAGE RETRIEVAL: DPRDPR使用雙編碼器方法增強開放域QA檢索,不像計算密集型ICT。它的密集編碼器 (·)在一個連續(xù)的、低維的( )空間中索引所有 段落,可以在運行時有效地檢索查詢的頂級相關段落。部署了一個單獨的編碼器 (·),用于在運行時映射查詢和d維向量,它檢索與問題向量最相關的 段落。查詢和段落之間的點積計算決定了它們的相似度。( , )= ( ) 。( )。目標是通過訓練編碼器學習更優(yōu)的嵌入函數(shù),該編碼涉及到創(chuàng)建向量空間,其中相關的問題,通道對具有更小的距離,即比不相關的更大的相似性。假設訓練數(shù)據(jù)與 實例 ={? , + ?,??, ??} ,1 , =1每個實例包含一個查詢 ,一個積極的(相關的)段落 +和 消極的(無關的)段落 ?。損耗函數(shù)可優(yōu)化為正通道的負對數(shù)似然。
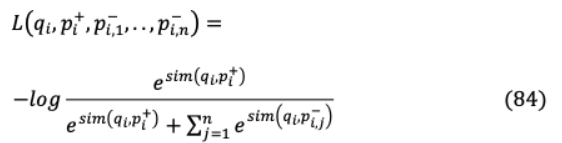
VIII. LONG SEQUENCE MODELS這種64層的Transformer[93]是基于對更長的序列具有更大的字符級建模的發(fā)現(xiàn)而建立的。與RNN的一元階躍級數(shù)相比,該信息在隨機距離上快速傳輸。然而,以下三個支持損耗參數(shù)被添加到普通的Transformer,加速收斂并提供訓練更深的網(wǎng)絡的能力。
(i) :一般因果預測發(fā)生在最后一層的一個位置,然而在這種情況下,所有的位置都是用于預測。這些輔助損失迫使模型在較小的背景下進行預測,并在沒有權(quán)重衰減的情況下加速訓練。(ii) :除最后一層外,對給定序列添加所有中間層的預測,隨著訓練的進行,較低層的權(quán)重逐漸減少。對于 層,在完成培訓 /2 后, h中間層的貢獻不再存在。(iii) :對模型進行修改,以生成兩個或更大的未來字符預測,其中每個新目標引入一個單獨的分類器。在添加到相應的層損失之前,額外的目標損失被稱量一半。上述3種實現(xiàn)如圖19所示。為序列長度 ,語言模型計算聯(lián)合標記序列上的概率自回歸分布。
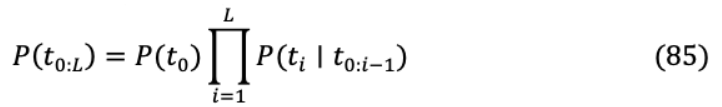
VIII-B TRANSFORMER-XL為了減輕普通transformer中的上下文碎片,XL集成了更長的依賴關系,在這些依賴關系中,它重用并緩存了先前的隱藏狀態(tài),數(shù)據(jù)從這些狀態(tài)通過遞歸傳播。給定標記語料庫 =( 1, 2…), ),一個語言模型自回歸計算聯(lián)合概率 ( ),其中上下文 《 被編碼成一個固定大小的隱藏狀態(tài)。
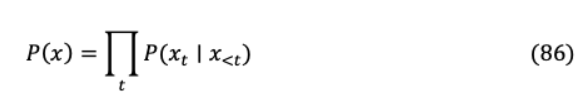
假設兩個連續(xù)的句子長度為 , =[ 1…, , ]and +1 =[ +1,1,…], +1, ]其中 h層由 h段 as產(chǎn)生的隱藏狀態(tài)序列H ? × ,其中 是隱藏的維度。的 h 段 +1的隱藏層狀態(tài)計算為如下:
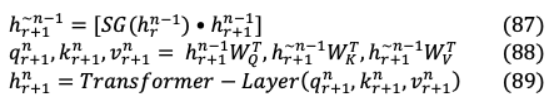
其中 (·)表示停止梯度,[h?h]是兩個 隱藏序列拼接,并將 作為模型參數(shù)。與原始Transformer的主要區(qū)別在于對密鑰 和價值 +1 +1進行建模關于擴展上下文h~ ?1,因此在前面 +1 h ?1被緩存。這可以從圖20 中演示出來在上面,后者緩存了先前的注意廣度形成一個延長的緩存機制。這種遞
歸適用于每兩個連續(xù)段創(chuàng)建段級遞歸通過隱藏州。在原來的Transformer注意力得分內(nèi)查詢( )和鍵向量( )之間的相同段是:
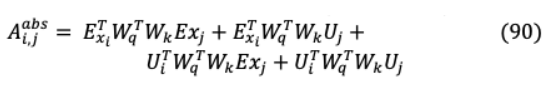
從相對位置編碼的角度來看,以上方程以以下方式重新構(gòu)造
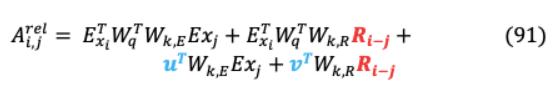
VIII-C LONGFORMER該體系結(jié)構(gòu)在識別相互關注的輸入位置對時提供了完整注意矩陣的稀疏性,并實現(xiàn)了三種注意配置:(i) :對于一個固定的窗口大小 ,每個tokens關注每一邊 /2的序列長度(n)。這導致 ( × )的計算復雜性隨輸入序列長度線性擴展,為了提高效率, 《 。一個堆疊的“ ”分層Transformer使大小為“ × ”的接收能力超過整個輸入“ ”跨越所有層。可以根據(jù)效率或性能選擇不同的“ ”值。(ii) :為了節(jié)省計算和擴展接受域大小的 × × ’,‘ 大小可變的差距在哪里引入窗口大小“ ”相呼應。增強的性能是通過允許少數(shù)無膨脹頭(較小的窗口大小)關注本地上下文(較低的層)和其余膨脹頭(增加窗口大小)關注較長的上下文(較高的層)來實現(xiàn)的。(iii) :前面的兩種實現(xiàn)對任務精確學習沒有足夠的靈活性。因此,“ ”是在少數(shù)預先指定的輸入tokens( )上實現(xiàn)的,其中tokens關注所有序列tokens,所有此類tokens也關注它。這使得本地和全球?qū)?( )的關注更加復雜。它的注意復雜度是局部和全局注意與RoBERTa的二次復雜度的總和,二次復雜度可以用下面的數(shù)學表達式來解釋。

全局關注使無塊文檔處理成為可能,但是,如果序列長度超過了窗口大小,那么它的時空復雜性將大于RoBERTa。
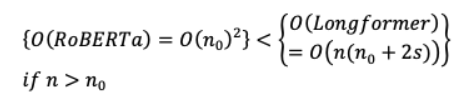
VIII-D EXTENDED TRANSFORMER CONSTRUCTION: ETCETC是Longformer設計的改良版,可接受全球( )和長( )輸入,其中 ? 。它計算四種全球-本地注意力變體:從全球到全球( 2 )、從全球到長( 2 )、從長到全球( 2 )和從長到長( 2 ),以實現(xiàn)長序列處理。全局輸入和其他三種變化具有無限的關注,以補償 2 ’ 固定半徑跨度,以實現(xiàn)性能和計算成本之間的平衡。此外,它用相對位置編碼取代了絕對編碼,后者提供有關彼此的輸入標記的信息。
VIII-E BIG BIRD在數(shù)學上,大鳥證明了隨機稀疏注意可以是圖靈完備的,并且表現(xiàn)得像一個輔助隨機注意的朗格爾人。它被設計為(i)一個全局tokens組 關注所有序列部分(ii)存在一組 隨機鍵,每個查詢 關注(iii)一個本地鄰居窗口 塊,每個本地節(jié)點關注。Big Bird的全局tokens是使用一種雙重方法構(gòu)造的(i) Big Bird-ITC:實現(xiàn)內(nèi)部Transformer構(gòu)造(ITC),其中當前tokens在整個序列中都是全局的。(ii) Big Bird-ETC:實現(xiàn)擴展Transformer構(gòu)造(ETC),關鍵的額外全球tokens 包括[ ],涉及所有現(xiàn)有tokens。它的最終關注過程包括以下屬性:查詢關注 隨機鍵,每個查詢關注 /2tokens在其位置的左右,并有 全局tokens,它從當前tokens派生或在需要時可以補充。
IX. COMPUTATIONALLY EFFICIENT ARCHITECTURESIX-A SPARSE TRANSFORMER該模型的經(jīng)濟性能是由于從完全自我注意程序的異化,該程序通過幾個注意步驟進行修改。模型的輸出結(jié)果來自完整輸入數(shù)組的一個因子,即(√ ),其中 ? h如圖22所示。這導致了與Transformer的 ( 2)相比, ( √ )的關注復雜性更低。此外,它能破譯的序列比之前的長30倍。它的因子化自我關注由 不同的頭組成“ h頭”的實質(zhì)是注意力指數(shù)的一個子集 ( )的實質(zhì)是“ ∶ ≤ ”的實質(zhì)。“Ai(m)”的實質(zhì)是“Ai(m)”的實質(zhì)是“ ”的實質(zhì)。跨越式注意在兩個維度上實現(xiàn)其中一個負責人負責以前的 地點和另一個關注每一個 h地點,在那里步幅 價值接近√ 。這表示為 (1)={ , + 1,。。, }for = (0, ? )和 (1)={ :( ? ) = 0}。這 線性變換導致了這種密集的注意:
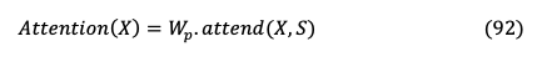
其中 是post - attention矩陣。同樣, 實現(xiàn)因子化注意頭,一種注意類型交替使用每個殘留塊或交錯或超參數(shù)決定比率。
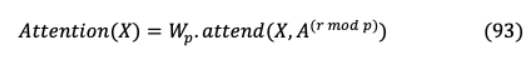
其中 是當前剩余塊索引, 是映像員工。另一種合并磁頭的方法包括一個磁頭處理兩個因數(shù)分解的磁頭處理的目標位置。這種方法在計算上要貴一個常數(shù)因子。
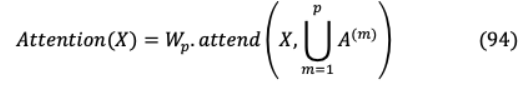
第三種選擇是使用多頭注意力,其中注意力產(chǎn)品( )是并行計算的,并沿特征維度連接。
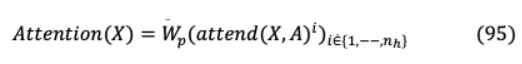
多個頭給出了更好的結(jié)果,而對于注意力決定計算的較長的序列,順序注意力是首選。
IX-B REFORMERReformer通過局部敏感散列(LSH)將Transformer的注意復雜度降低到 (L log L)。這將每個向量 賦值給一個哈希h( ),其中相鄰的向量在大小相似且概率高的哈希桶中獲得相同的哈希,而遠程的向量則不會。修正的LSH注意方程:
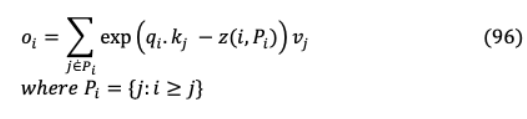
屬于 h職位查詢關注的集合, 是 一種配分函數(shù),它包含一個查詢要處理的鄰近鍵的范圍。為了進行批處理,注意 ={0,1? }? ,其中 是~ 的子集,不在 中的元素被屏蔽。
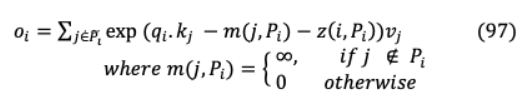
解碼器實現(xiàn)屏蔽,以防止訪問未來的查詢位置。通過在單個散列桶中啟用關注,設置的 目標項只能由位于 h位置的查詢參與。為了進一步降低相似項落在不同桶中的概率,使用不同的哈希函數(shù){h(1), h(2), 。 。進行多次并行哈希( )。}
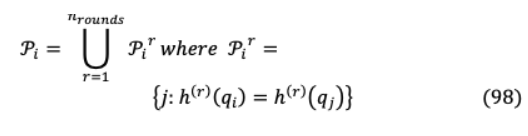
注意力集中在已排序的鍵查詢塊和要批量處理的鍵
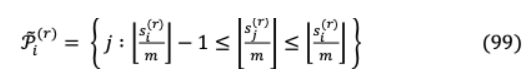
從(96)和(97)我們可以得到
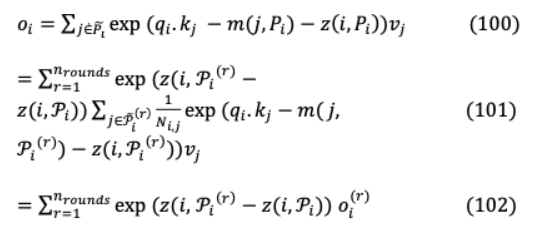
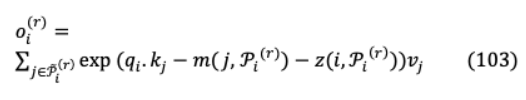
下面圖23的例子全面地展示了改革者的各種工作機制。可逆殘差網(wǎng)絡[94]是Reformer經(jīng)濟內(nèi)存消耗背后的另一個驅(qū)動力,其中激活值是在反向傳播期間動態(tài)重建的,不包括存儲中保存激活的要求。從圖24中,下面每一層的可逆塊從下一層的激活重新計算為:
IX-C A LITE BERT: ALBERTALBERT在一個單一模型中集成了以下兩參數(shù)縮減技術,結(jié)果僅得到12M參數(shù),如圖25所示。與BERT-base相比,這幾乎減少了90%的參數(shù),同時保持了具有競爭力的基準性能。(i) :為獲得最佳的結(jié)果,NLP任務需要大量詞匯 ,(嵌入大小) ≡ (隱層)和嵌入矩陣 × 大小可以規(guī)模數(shù)十億參數(shù)。ALBERT將嵌入空間 分解為兩個更小的矩陣,其中嵌入?yún)?shù)從 ( × )導出為 ( × + × )。(ii) ? h :阿爾BERT是建立跨層通過前饋網(wǎng)絡共享注意參數(shù)(FFN)。因此,它的層間過渡相當平滑,因為結(jié)果表明權(quán)值共享對網(wǎng)絡參數(shù)的穩(wěn)定作用。
與BERT的NSP一樣,ALBERT的句子順序預測(SOP)損失包含了從兩個正的連續(xù)文本片段中進行的雙分叉學習,其中也包括其相應的順序顛倒的負樣本,如圖26所示。這影響了模型在上下文中學習任何話語中更細粒度的差異,從而獲得更好的連貫性能。它的傳銷目標實現(xiàn) -gram掩蔽,包括多達3個字符序列,如“世界杯足球”或“自然語言處理”。
 IX-D ELECTRA它的優(yōu)勢在于通過有效的區(qū)分來進行情境學習,從所有的事物中學習。不同于BERT的輸入標記,BERT只從15%的屏蔽子集學習。ELCTRA實現(xiàn)了“被替換的tokens檢測”,如圖27所示,通過Generator( ),一個小的“屏蔽語言模型”,用有概率意義的替換替換少數(shù)隨機tokens,從而發(fā)生污染。
IX-D ELECTRA它的優(yōu)勢在于通過有效的區(qū)分來進行情境學習,從所有的事物中學習。不同于BERT的輸入標記,BERT只從15%的屏蔽子集學習。ELCTRA實現(xiàn)了“被替換的tokens檢測”,如圖27所示,通過Generator( ),一個小的“屏蔽語言模型”,用有概率意義的替換替換少數(shù)隨機tokens,從而發(fā)生污染。
同時,通過二值分類,聯(lián)合預訓練一個更大的模型Discriminator( )來預測每個標記是否通過生成器正確恢復。
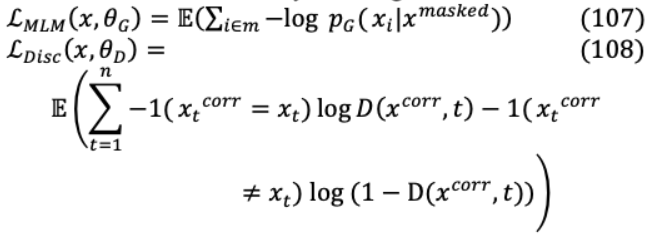
這兩個基于編碼器的網(wǎng)絡( , )轉(zhuǎn)換輸入tokens序列 =[ 1,。 。]h = [h1, 。 。]。h ]。通過Softmax, 產(chǎn)生 h位置令符 的可能性,其中 =[ ]。
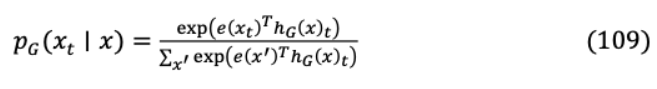
在一個大語料 上的聯(lián)合損失最小化為:
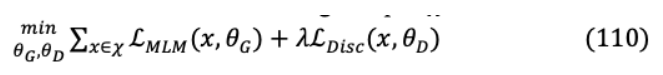
IX-E LINFORMER證明了[95],注意權(quán)值由少數(shù)關鍵項支配,通過低秩自注意將序列長度投影到目標輸出矩陣,實現(xiàn)了線性的時間和空間復雜度 (1)。在鍵和值的計算過程中,兩個線性投影矩陣相加 , ∈R × ,其中( × )? 尺寸鍵,值層 和 被投影 進入( × )?維度鍵,值層,之后結(jié)果( × )-維度上下文計算使用縮放的點積注意力。
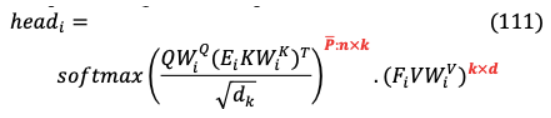
如果 《《 ,則內(nèi)存和空間顯著減少消費是實現(xiàn)。為了進一步有效優(yōu)化,投影之間的參數(shù)共享在3處執(zhí)行(i) Headwise Sharing:每一層有兩個投影矩陣 和 通過 = , = 共享所有頭 。(ii)鍵值共享:包括(i)鍵值投影是共享的,每一層的單一投影為每個鍵值投影 創(chuàng)建矩陣 = =(iii)層共享:一個單一的投影矩陣 實現(xiàn)所有層,頭,鍵和值。對于12層12頭Transformer(i), (ii), (iii)將分別包含24,12,1個不同的線性投影矩陣。
IX-E PERFORMER結(jié)果優(yōu)于 ( 2 ),其中 ? 。然而,在實現(xiàn)了softmax非線性函數(shù)后,將查詢鍵產(chǎn)品的注意力分解為原始形式是不可能的。然而,通過近似較低級別的查詢和鍵啟用,pre softmax注意力分解是可能的更高的效率,特別是‘ ? ( )? √ exp( )。通過核近似函數(shù) ( , )=?( ) ?( ),高維特征圖點積?。與增加維度的內(nèi)核技巧相反,Performer[96]分解注意力矩陣 ( , )= ( , )= ( , )?映射到低維特征。
X. MODELING CLASSIFICATION OF LMs從建模的角度來看,基于Transformer的語言模型(LM)可以分為3類[97]:(i)自回歸:這些是預先訓練的前饋模型,可以根據(jù)token的歷史預測未來的token。這里的輸出 依賴于即時 的輸入和以前的時間步長輸入 《 。這些主要是基于解碼器的變形金剛,合并了因果掩蔽,注意頭被阻止關注未來的代幣。這種模型通常用于文本生成目的進行微調(diào),并在GPT系列中部署零目標學習。(ii)自動編碼:這些基于編碼器的模型可以完全訪問輸入數(shù)組,沒有任何屏蔽。通過合并輸入tokens屏蔽方案對它們進行預訓練,然后進行微調(diào),以再現(xiàn)被屏蔽tokens作為輸出。這些模型(BERT)通常適用于序列或標記分類任務。(iii)序列到序列:這些基于編碼器-解碼器的生成模型從海量數(shù)據(jù)集創(chuàng)建數(shù)據(jù)后學習。與判別分布 ( | )不同,它們對輸入 和目標 的聯(lián)合分布 ( , )建模,其中輸入可能在幾種方案上被破壞。基于解碼器的因果掩蔽被部署以最大化后續(xù)目標生成的學習。像BART和T5這樣的模型在NMT、總結(jié)或QA任務上表現(xiàn)最好。圖29給出了上述建模分類的全面概述。
XI. LANGUAGE MODEL PERFORMANCE COMPARISON基于Glue和SuperGlue基準的少數(shù)幾個主要NLP模型的定量性能如圖28所示。這些基準測試包含各種數(shù)據(jù)集,這些數(shù)據(jù)集可以在幾個NLP任務中判斷模型。GPT-3的可訓練參數(shù)最多,是本次比較中最大的型號。因為GPT-3是這里最新的模型,所以它不參與舊的Glue基準測試。從定性的角度來看,同一模型中的T5在不同的任務中使用相同的損失函數(shù)和超參數(shù),從而形成一個多任務學習環(huán)境。這種可擴展的文本到文本生成(NLG)模型在訓練時將去噪目標與大量的未標記數(shù)據(jù)相結(jié)合,因此效果最好。相比于像RoBERTa這樣的NLU模型,這導致了更好的學習和更廣泛的表現(xiàn),而RoBERTa模型是在預處理后針對個別下游任務進行微調(diào)的。
在NLU模型中進行幾輪微調(diào)的主要動機是為了在多個任務上實現(xiàn)強大的性能。它的主要缺點是每個任務都需要一個新的、通常比較大的數(shù)據(jù)集。這放大了不合理的非分布泛化的可能性,導致與人類水平的能力進行不公平的比較。GPT-3不進行微調(diào),因為它的重點是提供任務不確定的執(zhí)行。然而,在GPT-3中有最小微調(diào)的范圍,這會導致一次或幾次學習。這個想法是在一個龐大的數(shù)據(jù)集上對一個巨大的模型進行預訓練后執(zhí)行零或最小的梯度更新。雖然GPT-3在SuperGlue基準測試中排名不高,但關鍵是這個生成模型在推理時學習任何任務的速度都是最快的。在一些NLP任務中,它匹配了SOTA微調(diào)模型在零、一和幾鏡頭設置下的性能。它還生成高質(zhì)量的樣本,并在動態(tài)定義的任務中提供可靠的定性性能。
XII. CONCLUSION AND FUTURE DIRECTIONS我們提供了導致當前SOTA在NLP性能方面的主要語言模型的全面和詳細的總結(jié)。自從Attention機制和Transformer架構(gòu)推出以來,NLP已經(jīng)取得了指數(shù)級的進步。我們提出了一種通過分類法進行模型分類的高級思維導圖。這些分類主要基于Transformer派生架構(gòu),用于特殊任務,如語言理解和生成、通過蒸餾、量化和剪枝縮小模型尺寸、信息檢索、長序列建模和其他廣義模型縮減技術。最近的語言模型主要是為了獲得更高的NLP性能,這需要大量的計算資源。因此,模型縮放已經(jīng)成為工業(yè)上的自然途徑。這種指數(shù)級的擴展加上更高的注意力復雜性使得這些模型無法在全球范圍內(nèi)訪問。隨后,在設計合理規(guī)模的模型和高效注意力計算方面做出了重大努力,以加快模型收斂速度,降低模型延遲。結(jié)合Mixture of Expert (MoE)[98]方法是大型模型實現(xiàn)計算效率的有效方法,因為每個輸入只激活神經(jīng)網(wǎng)絡的一個子集。因此,這導致稀疏性,雖然稀疏性訓練是一個活躍的研究領域,目前的gpu更適合密集矩陣計算。雖然MoE模型在訓練稀疏矩陣方面已經(jīng)顯示出了前景,但它們的通信成本和復雜性阻礙了大規(guī)模部署。此外,較大的模型容易記憶訓練數(shù)據(jù),導致過擬合和學習減少[99]。為了克服這一點,模型只在巨大數(shù)據(jù)集上的重復數(shù)據(jù)刪除實例上訓練一個epoch,因此顯示出最小的過擬合。因此,MoE設計與健壯的訓練范式相結(jié)合,在未來可能會產(chǎn)生高度可伸縮和高效的模型。這些模型將具有優(yōu)越的語言理解能力,因為數(shù)據(jù)記憶將被最小化。當前的SOTA模型方法依賴于大型數(shù)據(jù)集的監(jiān)督學習。在未來的自然語言處理中,一個很有前途的改進領域?qū)⑹窃跈C器翻譯、文本摘要和問答任務中結(jié)合強化學習。
模型描述任務語言建模類型
GPT-I, II, III?大型數(shù)據(jù)集的無監(jiān)督預訓練?自回歸語言建模和因果掩蔽問答,網(wǎng)絡機器翻譯,閱讀理解,文本總結(jié),常識推理,zero-shot基于Transformer的自回歸解碼器
XLNET?通過對輸入序列長度進行因式排序,提高語境學習效果?雙向上下文語言建模閱讀理解,自然語言推理,情感分析,問答基于Transformer的自回歸解碼器
REFORMER?注意通過本地敏感散列減少內(nèi)存占用?通過可逆剩余網(wǎng)絡重新計算權(quán)重和激活,繞過各自的存儲減少注意復雜性,使對實用記憶需求進行長時間的序列處理基于Transformer的自回歸解碼器
LONGFORMER?注意矩陣的稀疏性用于長序列加速和高效計算?對附近的tokens進行本地化關注,并對少數(shù)預選tokens進行全球化關注,以增強接受能力共引用決議,問答,文件分類。基于Transformer的自回歸解碼器
BERT?深度雙向語境化?用于持續(xù)學習的掩蔽語言建模(MLM)句子分類、問答、自然語言推理、基于Transformer的自動編碼-解碼器
RoBERTa?通過動態(tài)屏蔽的多樣化學習,每個時間布的token都被不同的屏蔽?更大的訓練前批量情感分析,問答,自然語言推理基于Transformer的自動編碼-解碼器
DistilBERT?生成與其較大的教師模型BERT相似的目標概率分布?生成學生和教師模型的隱藏狀態(tài)之間的余弦相似度語義文本相似性,語義關聯(lián),問答,文本蘊涵基于Transformer的自動編碼-解碼器
ALBERT?通過嵌入?yún)?shù)約簡,即因式參數(shù)化,更小、更高效的模型?通過跨層參數(shù)共享將層劃分為組,減少內(nèi)存占用閱讀理解,語義文本相似性,問答,語言推理基于Transformer的自動編碼-解碼器
ELECTRA?預測重新生成的損壞tokens是原始的還是通過預培訓生成器替換?通過替換標記檢測,有效且低成本的區(qū)分學習在情感分析、自然語言推理任務中提供具有競爭力的性能,計算效率為25%基于Transformer的自動編碼-解碼器
BART/mBART?通過更大的噪聲變化,優(yōu)越的序列生成質(zhì)量?靈活的去噪自編碼器作為最嚴厲的噪聲方案的語言模型監(jiān)督和非監(jiān)督多語言機器翻譯,問答,語義等價基于Transformer的生成式序列-序列模型
T5/mT5?在每一層學習位置編碼,以獲得更好的語義性能?以文本到文本的格式轉(zhuǎn)換所有任務,以合并大多數(shù)NLP任務品種。更多樣化和更具挑戰(zhàn)性的參考,內(nèi)涵,問答任務通過SuperGLUE基準基于Transformer的生成式序列-序列模型
原文標題:NLP實操手冊: 基于Transformer的深度學習架構(gòu)的應用指南(綜述)
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
責任編輯:haq
-
機器學習
+關注
關注
66文章
8408瀏覽量
132569 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113 -
nlp
+關注
關注
1文章
488瀏覽量
22033
原文標題:NLP實操手冊: 基于Transformer的深度學習架構(gòu)的應用指南(綜述)
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
NPU在深度學習中的應用
自動駕駛中一直說的BEV+Transformer到底是個啥?

AI大模型與深度學習的關系
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
PyTorch深度學習開發(fā)環(huán)境搭建指南
Transformer能代替圖神經(jīng)網(wǎng)絡嗎
深度學習中的時間序列分類方法
Transformer架構(gòu)在自然語言處理中的應用
深度學習與nlp的區(qū)別在哪
TensorFlow與PyTorch深度學習框架的比較與選擇
深度學習模型訓練過程詳解
深度學習的模型優(yōu)化與調(diào)試方法
深度解析深度學習下的語義SLAM

詳解深度學習、神經(jīng)網(wǎng)絡與卷積神經(jīng)網(wǎng)絡的應用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論