") 詞匯知識融合可能是NLP任務的永恒話題
詞匯知識融合可能是NLP任務的永恒話題
得益于BERT的加持,Encoder搭配CRF的結構在中文NER上通常都有不錯的表現,而且BERT使用方便,可以迅速微調上線特定服務;在好的基準條件下,我們也能把精力放在更細節(jié)的問題中,本文并不以指標增長為目標,而是從先驗知識融合與嵌套實體問題兩方面討論,希望可以從這兩個方向的工作中獲得解決其他問題的啟發(fā)
融合詞匯知識
Chinese NER Using Lattice LSTM
融合詞匯知識的方法可能適用于NLP問題的每個子方向,也是近幾年中文NER問題的大方向之一;因為中文分詞的限制,加之有BERT的加成,如今基本默認基于字符比基于分詞效果更好,這種情況下,引入詞匯知識對模型學習實體邊界和提升性能都有幫助,Lattice LSTM是這一方向的先行者
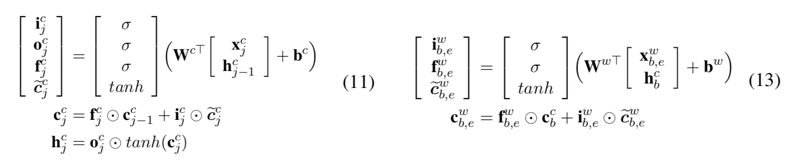
相比于char和word級的RNN,Lattice LSTM加入了針對詞匯的cell,用以融合詞匯信息;計算上比char-cell少一個output gate,此外完全一致,可以理解為在傳統(tǒng)LSTM鏈路中插入了一組LSTMCell,具體可以對照原文公式10-15理解(下圖公式11為LSTMCell,公式13為WordLSTMCell):
FLAT: Chinese NER Using Flat-Lattice Transformer
Lattice LSTM驗證了融合詞匯信息提升中文NER任務的可行性,就是有點慢,每句話要加入的詞匯不一樣,無法直接batch并行,此外Lattice LSTM沒法套BERT,現成的BERT不能用太不甘心;于是就有了同時彌補這兩點的FLAT,并且其融合詞匯的實現方式也簡單的多:如圖,FLAT融合詞匯的方式就是拼接,詞匯直接拼在輸入里,此外只需改造Postion Embedding,將原始的位置編碼改為起止位置編碼
不過Postion Embedding的改造還不止于此,為了讓模型學習到詞匯span的交互信息,這里還引入了相對位置編碼:如圖,長度為N的輸入會產生4個N * N的相對位置矩陣,分別由:head-head,head-tail,tail-head,tail-tail產生
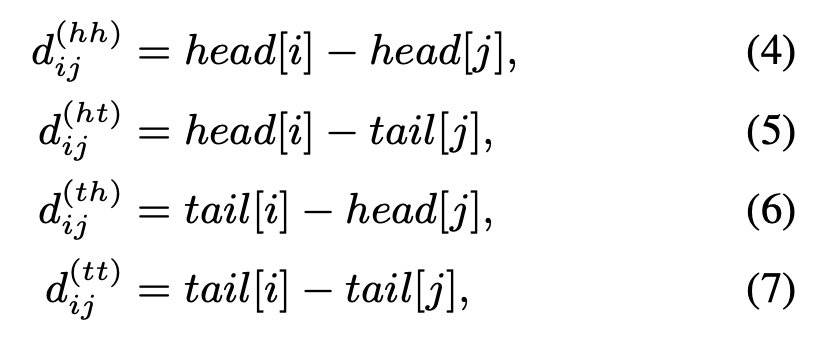
綜上,基于Transformer的FLAT可batch并行,速度自然優(yōu)于Lattice LSTM,同時又可以套用BERT,在常用中文NER數據集上都有非常出色的表現;FLAT的顯存占用比較高,但用顯存換來的推理時間減少肯定是值得的
Leverage Lexical Knowledge for Chinese Named Entity Recognition via Collaborative Graph Network
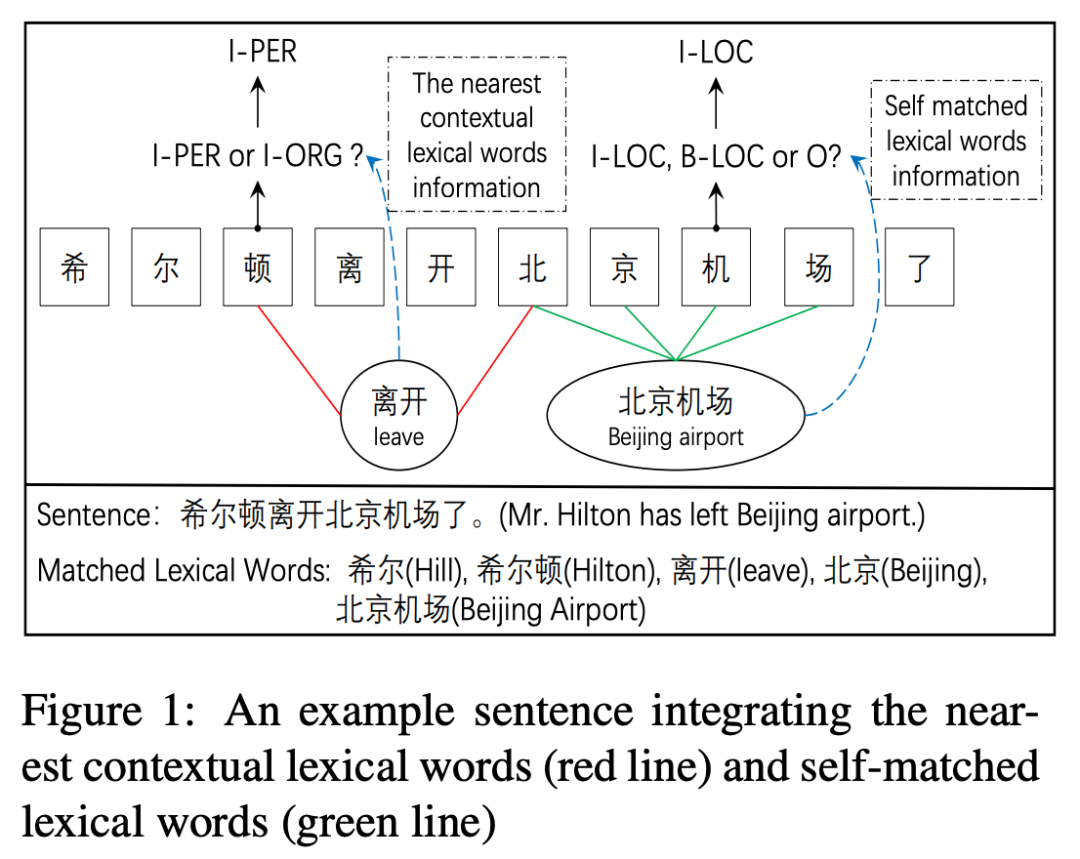
通過詞匯增強模型識別邊界的能力很重要,然而Lattice LSTM在這方面還存在信息損失,受限于構造方式,詞匯表示只能加給最后一個字,這樣有什么問題呢?以本文CGN中提到的“北京機場”為例,想要成功標出“北京機場”而非“北京”,需要模型將“機”識別為“I-LOC”,而非“O”或“B-LOC”,然而Lattice LSTM中的詞匯并不影響“機”的encoding;此外,Lattice LSTM的融合方式說明詞匯只對實體本身有幫助,然而正確識別實體可能也需要臨近詞匯的幫助,例如下圖的“離開”表明“希爾頓”是人名而非酒店
復雜的字詞關系無法通過RNN結構表示,選擇Graph更為靈活,本文通過融合三種圖結構學習復雜關系,利用GAN提取特征,獲得倍數于Lattice LSTM的速度提升
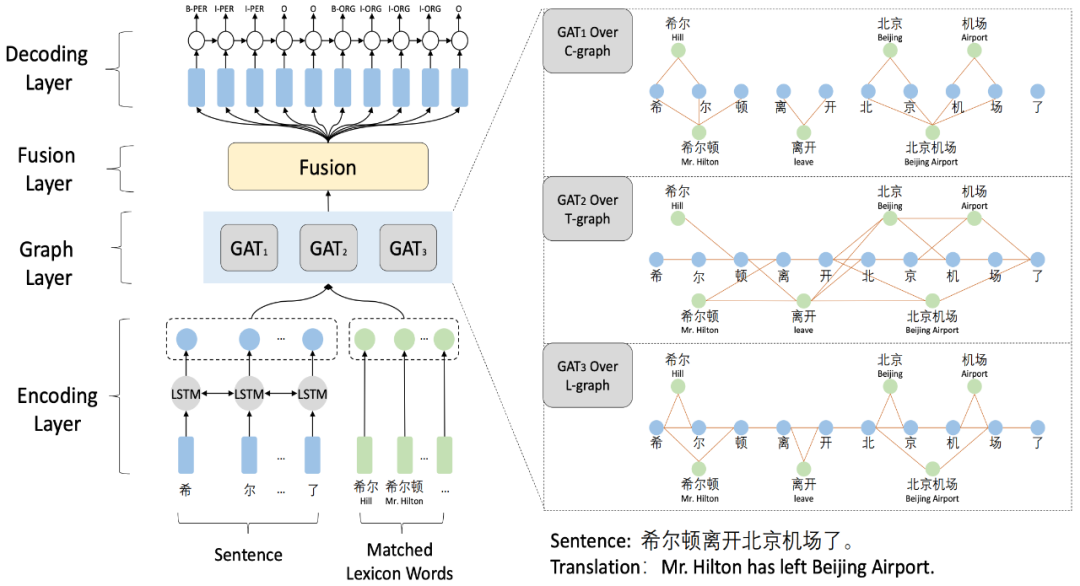
如圖所示,在LSTM編碼輸入文本并傳入詞匯表示后,模型會經過三種策略的構圖層:
Word-Character Containing graph(C-graph):負責學習自匹配特征和詞匯邊界信息
Word-Character Transition graph(T-graph):負責構造字詞相互之間的上下文鄰接關系
Word-Character Lattice graph(L-graph):負責捕捉自匹配特征和隱含的詞匯鄰接關系
圖表示完成后,通過Fusion層的線性結構融合特征,再傳給CRF做標簽decoding即可;雖然流程上比FLAT復雜一些,但一方面其非batch并行版的速度更快(不知道算不算建圖的時間),另外文中提供的各種詞匯融合思路也值得學習借鑒,從詞匯邊界和覆蓋本身考慮,上下文語義貢獻的作用,已經圖結構帶來的額外特征或許可以作為特定任務的預訓練過程拆解使用
嵌套實體問題
嵌套實體在標注應用場景下很少被顧及,一方面?zhèn)鹘y(tǒng)序列標注模型也只能選擇一個,另外標注數據時我們就只根據語義選擇其中一個;但嵌套實體本身是存在的,比如醫(yī)療場景下的疾病詞常由身體部位和其他詞構成,即便不作為NER任務本身看待,讓模型能學習標識嵌套實體,對實際場景中的其他任務也大有益處
Pyramid: A Layered Model for Nested Named Entity Recognition
通過多層結構抽取嵌套實體是一種容易理解的模型,2007年就有工作通過堆疊傳統(tǒng)NER層處理嵌套問題,不過之前的工作都無法處理嵌套實體重疊的情況,并且往往容易在錯誤的層級生成嵌套實體(即實體本身存在,但不該在當前層識別到,否則會影響后續(xù)層的識別,從而破壞整體模型效果);本文針對這兩個問題提出的金字塔結構
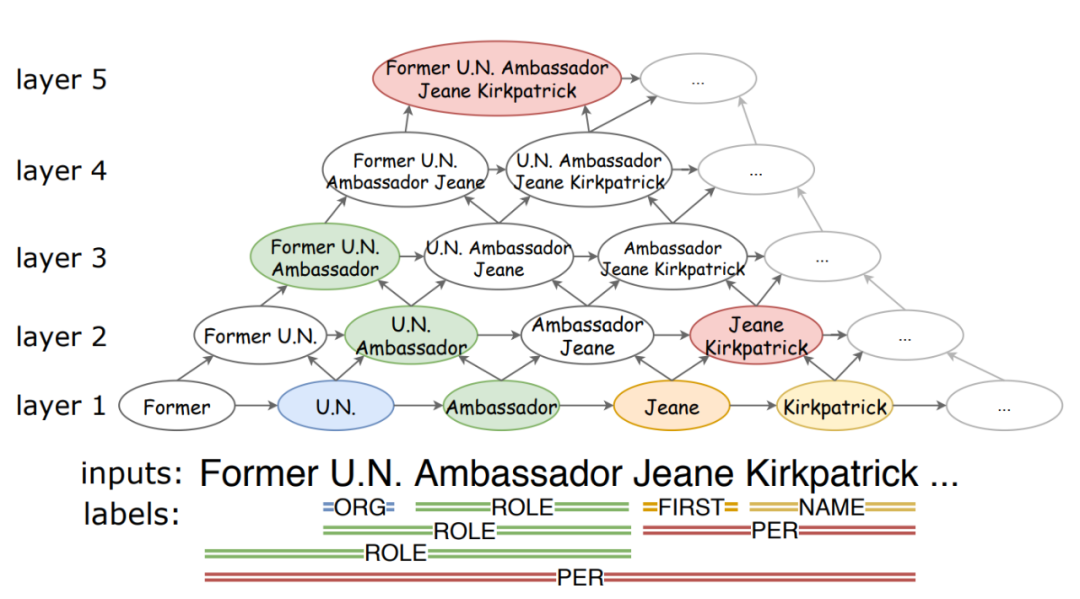
金字塔結構的思想如圖所示,最底層為最小的文本單元,每一層負責長度為L的實體的識別,通過CNN向上聚合,模型不會遺漏重疊實體span,同時由于L的限制,該結構不會在錯誤的層生成不對應的實體;作者還認為高層span的信息對底層也有幫助,所以還設計了逆向金字塔結構,具體實現如下
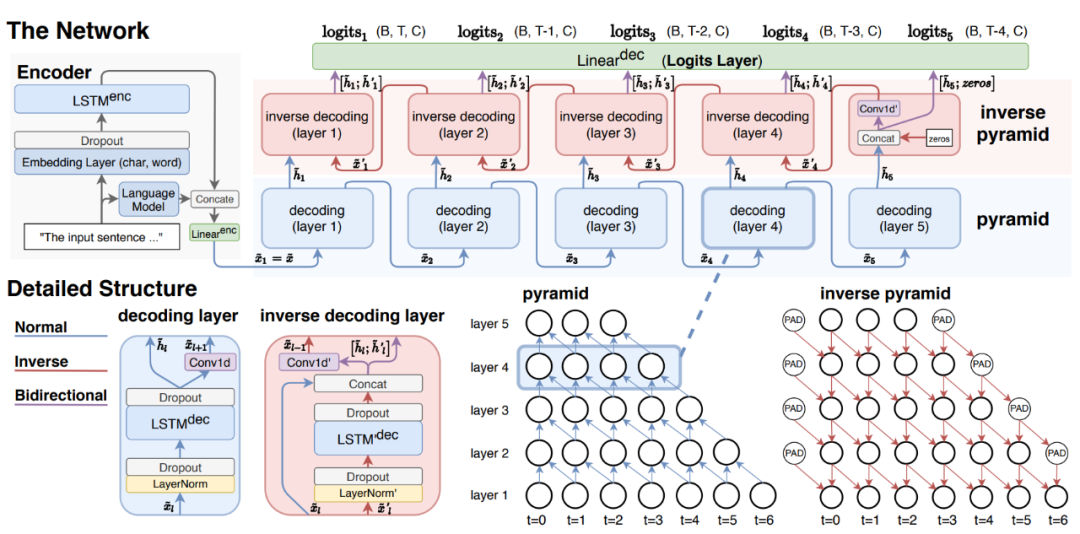
在經過LSTM編碼后,自底向上的Decoding層為每一層預測對應標簽,因為按長度區(qū)分,所以理論上只需要預測“B-”,但這樣模型就必須堆疊N層才能覆蓋全部span,不然就無法預測長度超過l的實體,所以作者設計了補救措施,在最高層同時預測“B-”和“I-”

Pyramid表現了處理嵌套問題的重要方向,即構造和編碼潛在實體span,下面的工作也都遵循這一點設計實現各種模型結構
A Unified MRC Framework for Named Entity Recognition
本文徹底放棄了序列標注模型,用閱讀理解的方法處理嵌套實體,即預測起止位置和實體分類;由起止位置標識的實體當然允許覆蓋,自然就解決了嵌套問題;熟悉MRC的同學很快就會發(fā)現,通常的MRC只有一個答案span,然而一句話中可能存在多個實體span,怎么表示多個實體?因此本文修改了MRC的結構,首先起止位置預測:
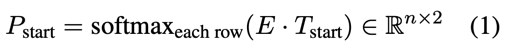
預測P_end也是同樣的結構,這里類似序列標注,表示每個char為起止位置的概率分布,這樣就產生了a個起始位置和b個終止位置,理論上存在 a * b 個實體span;而后還需要一個模塊計算a * b個匹配中有多少個真的是實體,即:
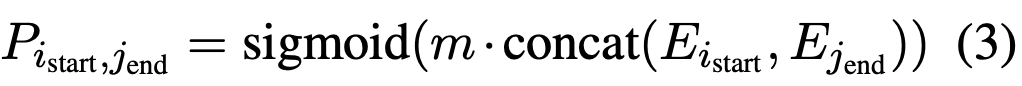
到此便解決了預測起止位置識別實體的問題,下面需要對每個實體span分類;通常的做法都是設計分類器,區(qū)別僅在于傳入分類器的表示,本文的分類則十分新穎,也十分MRC,即:給輸入文本拼接一個指向特定實體的問題,在這個問題下找出的span都屬于這一類
本文思路新穎,實現簡單且可套用BERT等不同Encoder,在傳統(tǒng)NER和Nested-NER數據集上都有sota或接近的水準;唯一的遺憾是不適合多實體類別的應用服務,因為針對K個類別都要單獨設計問題,所以相當于在預測時把每個問題都問一遍,時間開銷或顯存開銷擴大K倍是無法避免的
TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
本文是實體關系聯(lián)合抽取的工作,雖然思路上基本遵循實體識別-》關系分類的流程,但實現上于尋常工作有巨大差別;雖然并不是中文數據集上的工作,但在嵌套實體的處理思路上,本文與尋常工作也有巨大差別,很有借鑒意義;這里首先介紹對普通實體,頭實體,尾實體的標識方法:
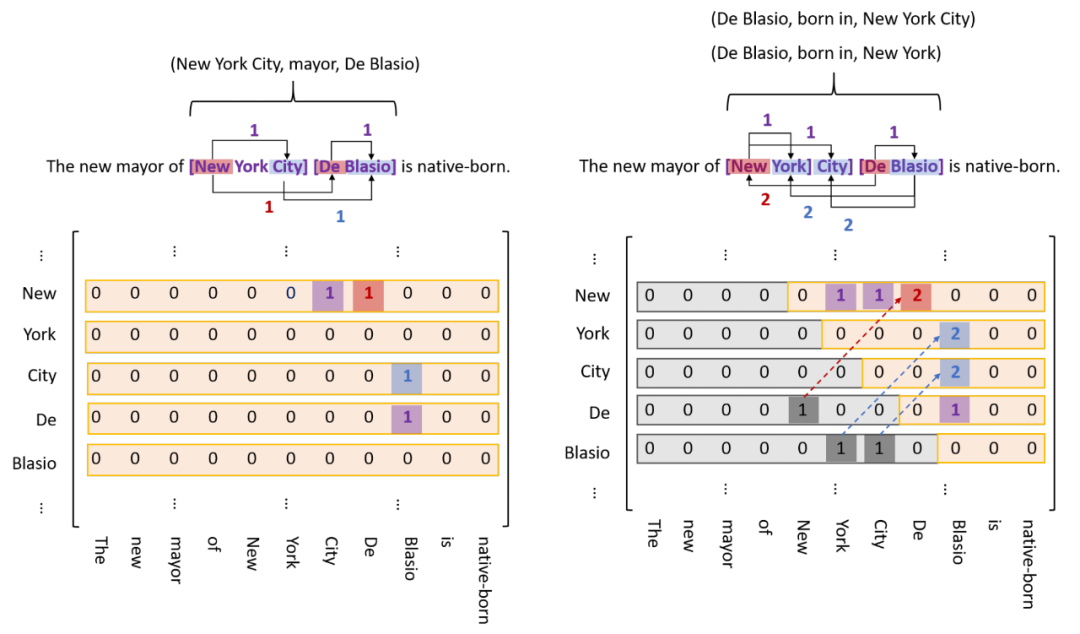
如圖所示,既然存在嵌套實體,那么不妨假設任意兩個char都可能構成實體,這樣就形成左圖的N * N矩陣,模型通過二分類即可標識出存在的實體;不過文本是單向的,所以實體的start一定在end前面,這樣就有了右圖,即矩陣包括主對角線的下三角矩陣可以忽略,這樣矩陣flat后的長度就從N * N減少到 (N + 1) * N / 2;因為是實體關系聯(lián)合抽取,所以分別用三種顏色標識,紫色標記普通實體,紅色標記同一關系下的頭實體,藍色標記尾實體,代碼實現上對應三種分類器;另外由于一對實體可能存在多種關系,所以需要為每種關系準備一個分類器,如下圖
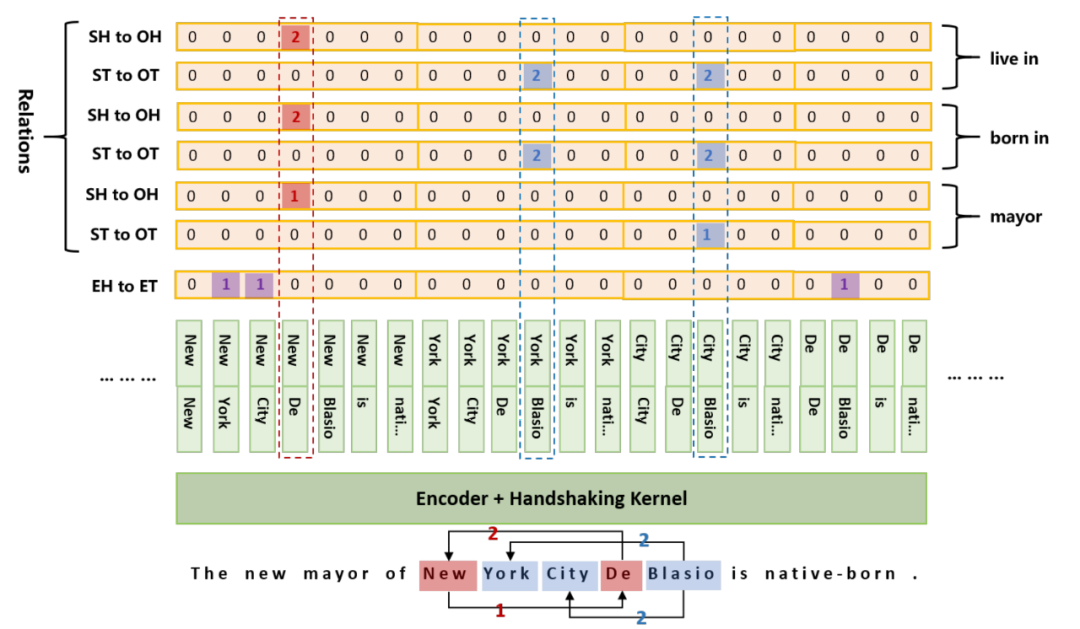
筆者認為TPlinker處理嵌套問題的思路與MRC頗有幾分相似,矩陣中每個元素都是一個span,既然存在嵌套,我們就不得不假設任意兩個char都可能構成實體;此外,雖然最終要在 (N + 1) * N / 2長的序列上預測實體,但顯存占用之類的問題并沒有那么明顯,因為這個平方級的序列是在Encoder輸出后拼成的,我們還可以通過設置一些約束進一步減少長度;不過要注意,這個長序列的預測可能非常稀疏(一句話里的實體很少,按長度平方后0占比更大)
Span-based Joint Entity and Relation Extraction with Transformer Pre-training
本文同樣是實體關系聯(lián)合抽取,處理嵌套問題的思路與TPlinker類似,窮舉出全部的潛在實體,然后用分類器識別;如下圖所示
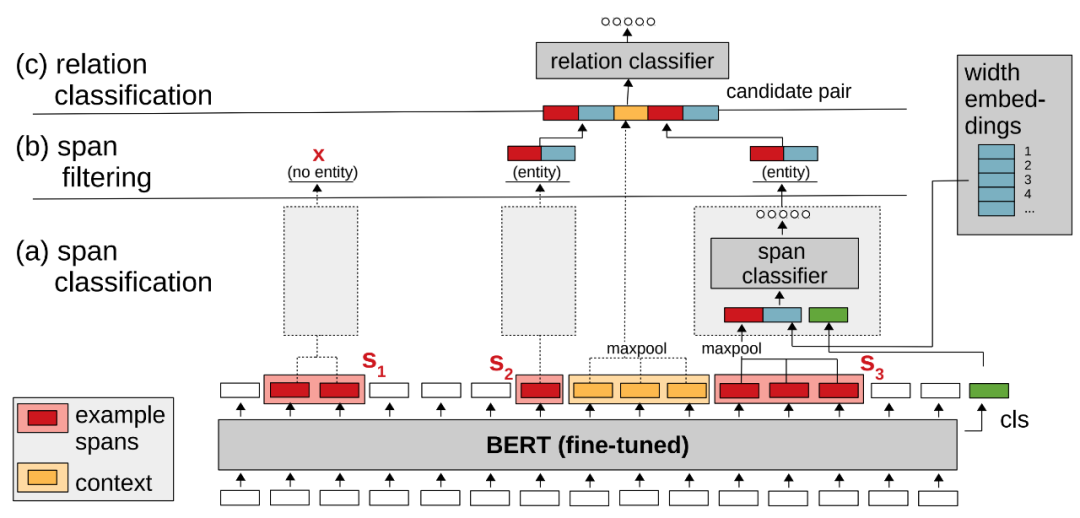
與TPlinker類似,在輸入文本經過BERT后,sequence_output被用來構造潛在實體,理論上所有的ngram都是潛在實體,所以這里需要拼出全部ngram再通過span分類器識別實體,過濾非實體;文中提到一個小trick,給span classifier傳入的向量表示除了sequence_output[span]和[CLS]外,還包含一個width embeddings向量,因為某些長度的span不大可能的實體,希望模型可以學到這一點;那么對于TPlinker和spERT,我們也都可以通過長度約束減少span的個數,手工降低模型的計算開銷;最后關系分類的做法很直觀,融合各路語義向量表示,通過sigmoid生成對應K個關系的1維向量,每個維度通過閾值判定是否存在該類關系
總的來說,Pyramid、MRC、TPLinker、spERT處理嵌套問題的出發(fā)點基本一致,從傳統(tǒng)的token級標注轉變?yōu)閷撛趯嶓wspan的標注;實現上各有特點,Pyramid設計了分層結構,TPlinker的矩陣構造非常靈性,不過平方級長度的序列太過稀疏;spERT雖然理論上也有平方級數量的span,但真實訓練可以通過負采樣降低訓練壓力;MRC做分類的想法很是獨特,不過對于多類別場景可能計算壓力過大,或許可以分離entity識別和分類,避免多次BERT計算的開銷
總結
詞匯知識融合可能是NLP任務的永恒話題,利用詞匯知識增強NER模型的想法也非常自然,Lattice LSTM及其后續(xù)工作展開了一個很好的方向,引入詞匯關聯(lián)結構提升模型也許在其他任務上也有很大收益;嵌套實體問題在當前的實際應用場景也許重視度還不夠,但問題本身切實存在,這方面的工作往往在潛在實體span的識別上有獨特的創(chuàng)新點,通過拆解和重組傳統(tǒng)的序列分類和標注模塊,引入MRC機制等思路,為我們解決復雜NLP問題帶來新的思路
原文標題:中文NER碎碎念—聊聊詞匯增強與實體嵌套
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
深度學習
+關注
關注
73文章
5504瀏覽量
121222 -
nlp
+關注
關注
1文章
489瀏覽量
22049
原文標題:中文NER碎碎念—聊聊詞匯增強與實體嵌套
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦





 工商網監(jiān)
工商網監(jiān)
評論