 一種簡單而高效的QoS機制:IEEE802.1Q下的預整形機制
一種簡單而高效的QoS機制:IEEE802.1Q下的預整形機制
1.案例背景汽車工業正在迅速向以太網作為車載通信的高速通信網絡發展,因此這需要超出傳統以太網且必須提供的協議,以便為諸如ADAS系統(高級駕駛員輔助系統)或音頻/視頻流等要求苛刻的應用提供額外的QoS。
當前為此目的考慮的主要協議是IEEE802.1Q,具有基于信用的整形器機制的AVB/CBS(IEEE802.1Qav)和具有其時間感知整形器的TSN/TAS(IEEE802.1Qbv)。AVB / CBS和TSN / TAS都提供有效的QoS機制,并且可以組合使用,這為設計人員提供了許多可能性。
但是,使用它們需要專用的硬件和軟件組件,在TAS的情況下需要時鐘同步。先前的研究還表明,這些協議的效率在很大程度上取決于手頭的應用和配置參數的值。
在此次案例中,探索在IEEE802.1Q下針對突發流量(例如音頻/視頻流)使用預整形策略,作為AVB / CBS和TSN / TAS的一種簡單有效的替代方法。
預整形意味著在發送突發的連續幀之間(例如,在發送攝像頭報文幀時發生的情況下)在發送方進行“精心選擇”的插入,然后將流量的所有其他特征保持不變。我們在雷諾汽車案例研究中展示了如何對音頻/視頻流使用預整形如何在最大程度上減少盡力而為流的通信等待時間,同時滿足其余流量的時序約束。
2.現有解決方案的局限性雖然現階段使用的的QoS協議(優先級機制、CBS、TAS)在某些情況下有效,但它們各自都有缺點和局限性:
僅使用優先級會導致性能下降,即嚴重的抖動和最大延遲,并且可能導致低優先級流量(以下也稱為盡力而為流量)的匱乏。此外,當流量(例如視頻流)突發時,交換機中避免丟包所需的內存可能變得很重要;
到現在為止,AVB / CBS確保盡力而為流量的性能要好得多,但是標準的AVB類不夠靈活,無法滿足所有通信需求。使用AVB自定義類有助于最大程度地發揮AVB的作用,但這并不總是足夠的。此外,為自定義類定義參數需要最壞情況的可調度性分析和用于設置CBS IdleSlopes的優化算法;
TSN / TAS,特別是與CBS結合使用時,提供了很多可能性,但是,為了使其有效,必須對所有發送者和交換機共同完成TAS門調度表的配置,這會導致復雜的優化問題。同樣,TSN / TAS需要同步協議來建立和維護全局時鐘,這會導致一些開銷和復雜性,并降低系統的整體魯棒性。
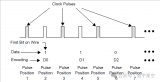
3.預整形機制預整形機制將標準靜態優先級調度與流量整形相結合,流量的所有其他特征保持不變。利用插入的空閑時間更快地傳輸穿過預整形流路徑的較低優先級或相同優先級的幀。 預整形并不是針對提高優先級較高的流量的通信延遲,而是可以與幀搶占結合使用,配置為屬于流集合的預整形流,而不是被高優先級搶占。在汽車領域,可以在中間件級別或通信驅動程序級別的軟件中實現預整形。預整形機制的系統模型:
T是分段報文的周期
N是組成報文的幀數
D是報文的相對截止時間,即報文釋放后的時間,所有接收站必須已接收到報文最后一幀
I是插入報文的每個幀之間的空閑時間
E是報文幀的最長傳輸時長(E = L / C,當C為鏈路傳輸速率,L為幀長:包括幀間間隙和前導碼)
形成報文的幀數N取決于每個幀中包含的數據有效載荷。設計者還可以在協議允許的間隔內(即46到1500字節)確定此參數。較小的數據有效載荷會導致較高的開銷,同時對其余流量的干擾也較小。最簡單,最實用的方法是本研究案例中嘗試的方法,它是不更改幀的大小,而僅使用報文的連續幀之間的空閑時間來實現流量整形。
假設攝像頭數據幀以周期T進行發送。每條數據流均以N幀的形式發送,每N個時間單位將其釋放以進行發送。報文的最后一幀將在時間(N-1)?I釋放,并且必須在截止時間之前接收。在Image數據流發布后,最后一幀將排隊在(I + E)·(N-1)個時間單位。因此,如果最后一幀的通信等待時間受Rmax限制,則必須在0和(D-Rmax)/(N-1)– E之間選擇空閑時間I。
后一個上限將連續傳輸擴展到最長時間間隔確保在截止時間之前完成,從而為位于優先級較低的流量類別中的幀提供最大可能的帶寬。本研究中使用的工具RTaW-Pegase中可用的PRESH算法的基礎策略。
4.案例:雷諾原型以太網網絡架構4.1 拓撲結構和流量案例研究是雷諾汽車的一個原型以太網網絡,包括5個交換機和14個節點:4個攝像頭(CAM),4個顯示器(Display),3個控制單元(ECU)和3個域主站(DM),如圖5所示。域主機3(DM3) 和交換機3之間鏈路上的傳輸速率為1Gbit/s,其他所有鏈路上的數據傳輸速率均為100Mbit/s。
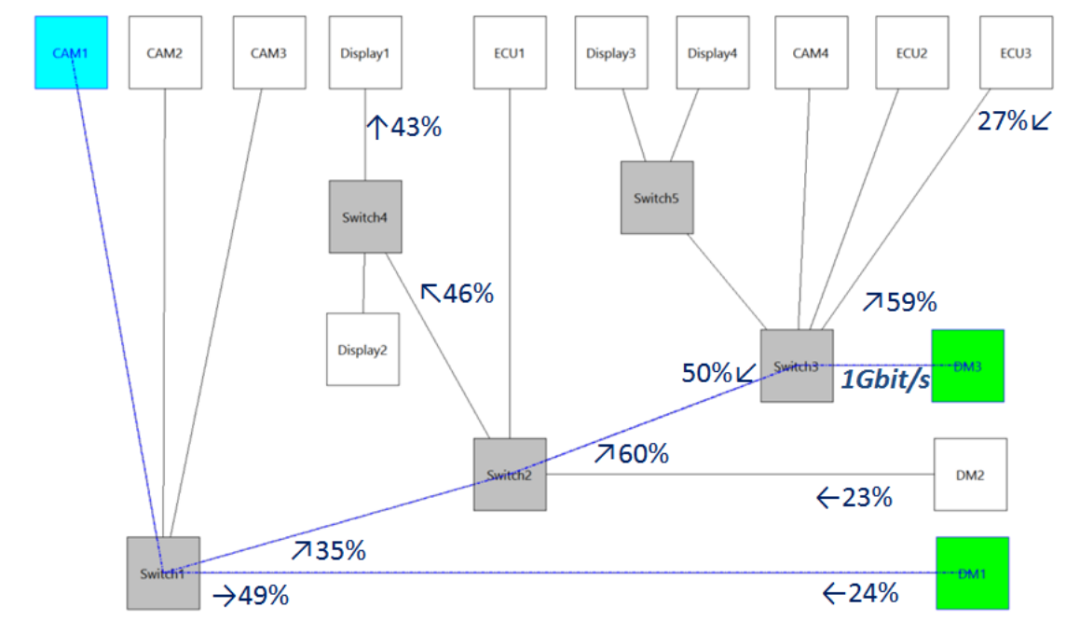
案例研究使用的原型網絡拓撲結構(RTaW-Pegase軟件截圖)
上圖顯示的多播流從攝像機1到域主機1和3,該圖顯示了10個負載最大的鏈路(最大負載為60%)和單個速率為1Gbit / s鏈路。流量由四個類別組成,總共41個流,其特征下表中進行了概述:音頻流8個數據流
128和256字節幀
截止時間:10ms以下
軟實時要求
視頻流2個ADAS流+ 6個vision流
每16ms(60FPS)或每33ms
(30FPS)最多30 * 1446byte幀
截止時間:10ms(ADAS),30ms(Vision)
硬實時+軟實時要求
Command & Control11個流,256到1024字節幀
截止時間:10ms以下
硬實時要求
盡力而為流:File, data transfer, diagnostics14個流,包括TFTP流量模式
0.2ms的周期
吞吐量保證(每個流高達20Mbits)
軟實時要求
4.2驗證技術和協議配置這項研究是使用時序精確的仿真和最先進的網絡演算實現方法進行的最壞情況遍歷時間(WCTT)分析進行的。兩種技術是互補的,雖然WCTT是最安全的方法,但是其本質上是考慮的最壞情況。此外,它不提供諸如延遲分布之類的統計信息,也不提供對類似FTP的流可以實現的吞吐量的準確評估。
使用的設計和時序分析工具是RTaW-Pegase v2.4.5,模擬樣本是通過長時間的模擬(2天不間斷運行,在500ms的最低頻率幀進行約35萬次傳輸)收集的,每個站點的時鐘漂移設為±200ppm ,在本研究的其余部分中,我們將比較以下QoS協議的性能:
靜態優先級以太網,不進行預整形(以下稱為IEEE802.1Q),其優先級分配按優先級降序排列, 優先級從高到低為:命令和控制(最高優先級),然后是音視頻,最后是盡力而為流(最低優先級);
具有預整形的靜態優先級以太網(稱為具有預整形的IEEE802.1Q),用于視頻流。使用預整形機制一節中描述的策略完成了預整形配置,從而使下圖中所示的配置符合所有性能約束。對于沒有預先成形的解決方案,優先級分配保持不變;
具有自定義類的AVB / CBS,不使用標準的125 / 250us CMI和標準的空閑斜率。在交換機和發送節點中都使用CBS,路徑上每個輸出端口上的CBS空閑斜率已使用RTaW-Pegase中實現的嚴格空閑斜率算法進行了設置。該算法計算出可能的最小空閑斜率,從而滿足AVB流量的時序約束,從而將對較低優先級流產生的干擾降至最低。就優先級而言,音頻流的優先級最高(AVB為最高優先級),其次為視頻流(AVB為第二優先級),然后是命令與控制,最后是盡力而為流。
4.3 盡力而為流的平均延遲下圖顯示了所研究的三種協議下所有盡力而為流的平均通信延遲。與標準IEEE802.1Q(黑色曲線)相比,預整形(紅色曲線)將盡力而為流的平均延遲平均提高了54%,最高可提高86%。如果不進行預整形,IEEE802.1Q將是不可行,因為無法滿足盡力而為流的吞吐量限制。
預整形機制和AVB自定義類在這里都是可行的解決方案,它們在盡力而為流的平均延遲方面的表現幾乎相同。但是,除了不需要專用硬件外,預整形還具有優于AVB的性能,即命令和控制流以最高優先級發送,從而減少了等待時間。對于系統的魯棒性也是有益的。
4.4盡力而為流的最壞情況延遲下圖顯示了所有盡力而為流的最壞情況下的通信延遲。IEEE802.1Q下的預整形可將盡力而為流的最壞情況延遲平均提高66%,最高可提高90%。再次,可觀察到預整形和AVB自定義類之間的相似性能。該實驗表明,通過預整形,還可以顯著降低延遲的變化,從而降低接收時的抖動。
4.5對Command & Control流的影響下圖顯示了以下兩種情況下C&C流的最壞情況網絡遍歷時間(WCTT)和平均網絡遍歷時間(AVRG):
具有和不具有預整形的IEEE802.1Q;
AVB / CBS,用于音頻/視頻流,配置有嚴格的空閑斜率機制。
流量類別的相對優先級如協議配置小節中所定義。我們首先觀察到的是,預整形對C&C流量的WCTT沒有影響。這可以很好的解釋,因為在WCTT計算中較低優先級幀的干擾僅通過阻塞因子,即最大的較低優先級幀的大小(其值在預成形時保持不變)。
當將AVB tight IdleSlope用于音頻/視頻流時,C&C的WCTT明顯大于IEEE802.1Q(平均增加 42%,最高129%)。這可以通過AVB流量類別帶來的干擾來解釋,該類別的優先級高于C&C流量。在平均通信延遲方面,這對于C&C幀通常不是最重要的指標,這三種解決方案的效果都非常好,幾乎是等效的。
4.6交換機中的內存使用情況到目前為止,已經假定不會由于沒有足夠的存儲器來存儲等待傳輸的數據包而發生數據包丟失,無論該數據包是在終端系統中還是在交換機中。在實踐中,確定內存量的大小以使數據包不丟失對于交換機尤為重要。
通過網絡演算分析獲得的交換機輸出端口中內存使用率的上限。帶有預整形的AVB / CBS和IEEE802.1Q都以有效的方式對流量進行整形,從而導致最低的內存使用量。在柱形圖的另一端,沒有預整形的IEEE802.1Q會生成幀突發,這些突發會累積在交換機中。
與不進行預整形的IEEE802.1Q相比,在傳輸中具有預整形的IEEE802.1Q平均將內存使用量提高了兩倍。AVB Tight Idle-Slope可能會在出口端口之間的傳輸之間插入延遲,因此比具有預整形的IEEE802.1Q所需的內存更多(平均增加28%)。
5.案例總結
在實際案例研究中進行的實驗表明,將預整形應用于生成幀突發的流是減少較低優先級流的通信延遲的有效機制。另外,預整形不需要專用硬件,并且可以以最小的開銷在軟件中實現。在這方面,它與CAN中的偏移機制具有相似之處,該機制已在汽車工業中成功使用了多年。 雖然簡單有效,但具有靜態優先級調度的預整形策略將具有一些局限性:
該節點會發送超出其規范的幀。例如,由于硬件或軟件故障而將繼續發送幀并淹沒網絡的節點。可以使用兩種解決方案:按類整形(如在AVB中使用CBS)或按流整形(如在AFDX或PSFP(IEEE802.1Qci)中);
添加新功能或新ECU(這會導致向系統中添加框架)可能會要求重新配置所有流的預整形參數,因為最大通信延遲會發生變化。此限制不是特定于預整形的,它會影響大多數QoS協議,除了具有最高優先級的AVB類的標準AVB之外;
當通過反復試驗手動完成時,為要受預整形機制影響的流設置參數是一項耗時的任務,并且可能不會導致最佳結果。設置參數的過程需要專用的工具支持;
從OEM的角度來看,預整形對ECU供應商提出了額外的要求,這也就相應的增加l成本。其次,就像CAN中的傳輸偏移一樣,預整形只能在減少的節點子集上實現,例如在我們的案例中,研究14個節點中只有5個在傳輸中使用了預整形。
編輯:jq
-
存儲器
+關注
關注
38文章
7484瀏覽量
163764 -
CAN
+關注
關注
57文章
2744瀏覽量
463621 -
ecu
+關注
關注
14文章
886瀏覽量
54485 -
AVB
+關注
關注
0文章
12瀏覽量
5187
原文標題:【虹科】RTaW-Pegase應用案例 | 一種簡單而高效的QoS機制:IEEE802.1Q下的預整形機制
文章出處:【微信號:Hongketeam,微信公眾號:廣州虹科電子科技有限公司】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
PCIe熱插拔機制介紹

一種基于光強度相關反饋的波前整形方法
一種簡單高效配置FPGA的方法
單片機的中斷機制
基于GPU器件行為的創新分布式功能安全機制為智能駕駛保駕護航

TPS65311-Q1/TPS65310A-Q1監控和診斷機制定義

詳解linux內核的uevent機制
VeriStand的執行機制
TSN網絡中時間感知整形器的性能驗證實測

BP神經網絡的學習機制
光學雨量計雨量傳感器的原理與工作機制

一種簡單的降壓開關穩壓器TL2575HV-33-Q1and TL2575HV-05-Q1數據表
基于IEEE Clause 28雙絞線的以太網自協商機制解析(一)
IEEE 802.1Qbv標準解析:為實時應用提供可靠網絡基礎設施





 工商網監
工商網監
評論