 深度解析TCP BBR技術
深度解析TCP BBR技術
今天推薦一篇在TCP BBR技術里面分析非常透徹的文章,希望大家可以學習到一些真正的知識,理解其背后的設計原理,才能應對各種面試和工作挑戰!
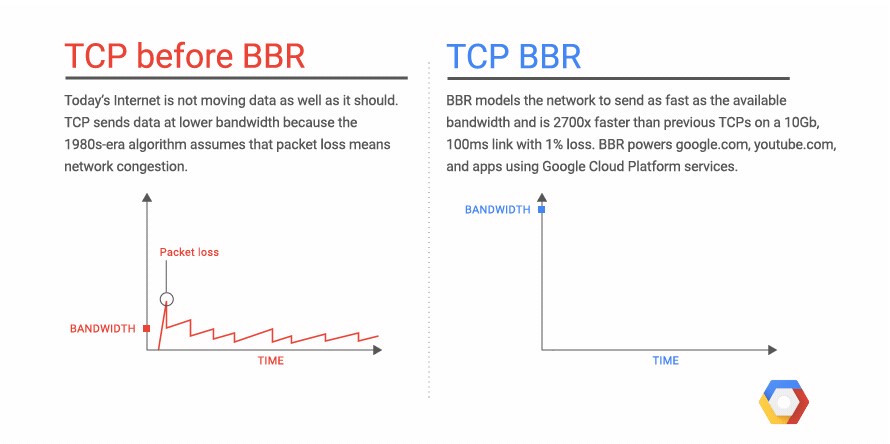
宏觀背景下的BBR
1980年代的擁塞崩潰導致了1980年代的擁塞控制機制的出爐,某種意義上這屬于見招拆招的策略,針對1980年代的擁塞,提出了1980年代的擁塞控制算法,即ss,ssthresh,congestion avoid這些。
說實話,這些機制完美適應了1980年代的網絡特征,低帶寬,淺緩存隊列,美好持續到了2000年代。
隨后互聯網大爆發,多媒體應用特別是圖片,音視頻類的應用促使帶寬必須猛增,而摩爾定律促使存儲設施趨于廉價而路由器隊列緩存猛增,這便是BBR誕生的背景。換句話說,1980年代的CC已經不適用了,2010年代需要另外的一次見招拆招。
如果說上一次1980年代的CC旨在收斂,那么這一次BBR則旨在 效能最大化,E,至少我個人是這么認為的,這也和BBR的初衷提高帶寬利用率相一致!
插個形象的gif:
正文開始
國慶節前,我看到了bbr算法,發現它就是那個唯一正確的做法(可能有點夸張,但起碼它是一個通往正確道路的起點!),所以花了點時間研究了一下它,包括其patch的注釋,patch代碼,并親自移植了bbr patch到更低版本的內核,在這個過程中,我也產生了一些想法,作為備忘,整理了一篇文章,記如下,多年以后,再看TCP bbr算法的資料時,我的記錄也算是中文社區少有的第一個吃螃蟹記錄了,也算夠了!
正文之前,給出本文的圖例:
BBR的組成
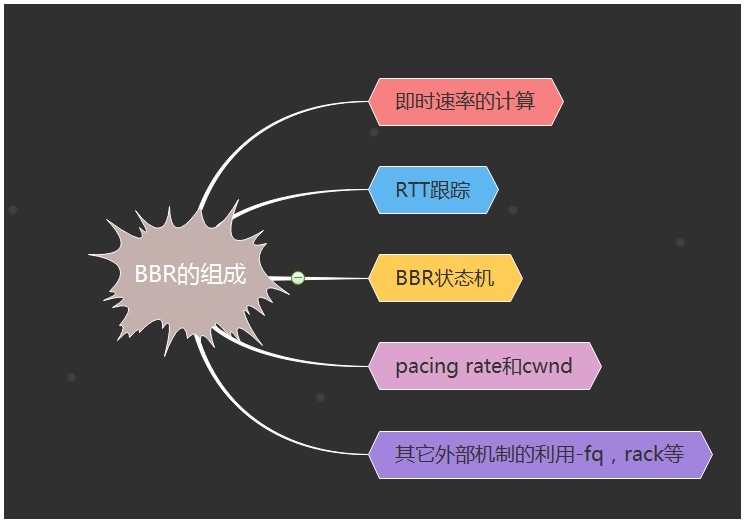
bbr算法實際上非常簡單,在實現上它由5部分組成:
BBR的組成
1.即時速率的計算
計算一個即時的帶寬bw,該帶寬是bbr一切計算的基準,bbr將會根據當前的即時帶寬以及其所處的pipe狀態來計算pacing rate以及cwnd(見下文),后面我們會看到,這個即時帶寬計算方法的突破式改進是bbr之所以簡單且高效的根源。計算方案按照標量計算,不再關注數據的含義。在bbr運行過程中,系統會跟蹤當前為止最大的即時帶寬。
2.RTT的跟蹤
bbr之所以可以獲取非常高的帶寬利用率,是因為它可以非常安全且豪放地探測到帶寬的最大值以及rtt的最小值,這樣計算出來的BDP就是目前為止TCP管道的最大容量。bbr的目標就是達到這個最大的容量!這個目標最終驅動了cwnd的計算。在bbr運行過程中,系統會跟蹤當前為止最小RTT。
3.BBR狀態機的維持
bbr算法根據互聯網的擁塞行為有針對性地定義了4中狀態,即STARTUP,DRAIN,PROBE_BW,PROBE_RTT。bbr通過對上述計算的即時帶寬bw以及rtt的持續觀察,在這4個狀態之間自由切換,相比之前的所有擁塞控制算法,其革命性的改進在于bbr擁塞算法不再跟蹤系統的TCP擁塞狀態機,而旨在用統一的方式來應對pacing rate和cwnd的計算,不管當前TCP是處在Open狀態還是處在Disorder狀態,抑或已經在Recovery狀態,換句話說,bbr算法感覺不到丟包,它能看到的就是bw和rtt!
4.結果輸出-pacing rate和cwnd
首先必須要說一下,bbr的輸出并不僅僅是一個cwnd,更重要的是pacing rate。在傳統意義上,cwnd是TCP擁塞控制算法的唯一輸出,但是它僅僅規定了當前的TCP最多可以發送多少數據,它并沒有規定怎么把這么多數據發出去,在Linux的實現中,如果發出去這么多數據呢?簡單而粗暴,突發!忽略接收端通告窗口的前提下,Linux會把cwnd一窗數據全部突發出去,而這往往會造成路由器的排隊,在深隊列的情況下,會測量出rtt劇烈地抖動。
bbr在計算cwnd的同時,還計算了一個與之適配的pacing rate,該pacing rate規定cwnd指示的一窗數據的數據包之間,以多大的時間間隔發送出去。
5.其它外部機制的利用-fq,rack等
bbr之所以可以高效地運行且如此簡單,是因為很多機制并不是它本身實現的,而是利用了外部的已有機制,比如下一節中將要闡述的它為什么在計算帶寬bw時能如此放心地將重傳數據也計算在內。。。
帶寬計算細節以及狀態機
1.即時帶寬的計算
bbr作為一個純粹的擁塞控制算法,完全忽略了系統層面的TCP狀態,計算帶寬時它僅僅需要兩個值就夠了:
1)。應答了多少數據,記為delivered;
2)。應答1)中的delivered這么多數據所用的時間,記為interval_us。
將上述二者相除,就能得到帶寬:
bw = delivered/interval_us
非常簡單!以上的計算完全是標量計算,只關注數據的大小,不關注數據的含義,比如delivered的采集中,bbr根本不管某一個應答是重傳后的ACK確認的,正常ACK確認的,還是說SACK確認的。bbr只關心被應答了多少!
這和TCP/IP網絡模型是一致的,因為在中間鏈路上,路由器交換機們也不會去管這些數據包是重傳的還是亂序的,然而擁塞也是在這些地方發生的,既然擁塞點都不關心數據的意義,TCP為什么要關注呢?反過來,我們看一下擁塞發生的原因,即數據量超過了路由器的帶寬限制,利用這一點,只需要精心地控制發送的數據量就好了,完全不用管什么亂序,重傳之類的。當然我的意思是說,擁塞控制算法中不用管這些,但這并不意味著它們是被放棄的,其它的機制會關注的,比如SACK機制,RACK機制,RTO機制等。
接下來我們看一下這個delivered以及interval_us的采集是如何實現的。還是像往常一樣,我不準備分析源碼,因為如果分析源碼的話,往往難以抓住重點,過一段時間自己也看不懂了,相反,畫圖的話,就可以過濾掉很多諸如unlikely等異常流或者當前無需關注的東西:
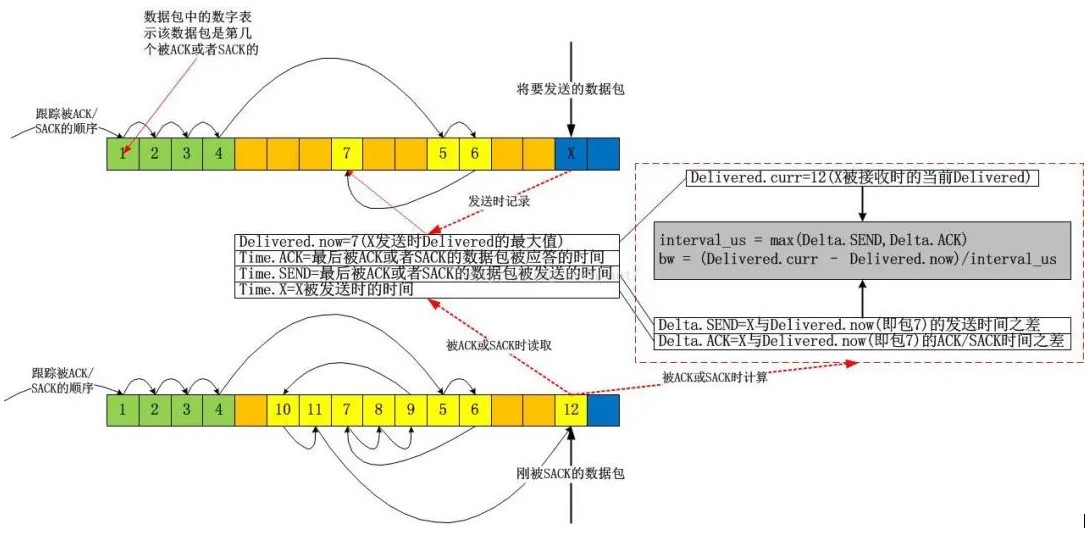
上圖中,我故意用了一個極端點的例子,在該例子中,我幾乎都是使用的SACK,當X被SACK時,我們可以根據圖示很容易算出從Delivered為7時的數據包被確認到X被確認為止,一共有 12-7=5個數據包被確認,即這段時間網絡上清空了5個數據包!我們便很容易算出帶寬值了。我的這個圖示在解釋帶寬計算方法之外,還有一個目的,即說明bbr在計算帶寬時是不關注數據包是否按序確認的,它只關注數量,即數據包被網絡清空的數量。實實在在的計算,不猜Lost,不猜亂序,這些東西,你再怎么猜也猜不準!
計算所得的bw就是bbr此后一切計算的基準。
2.狀態機
bbr的狀態機轉換圖以及注釋如下圖所示:
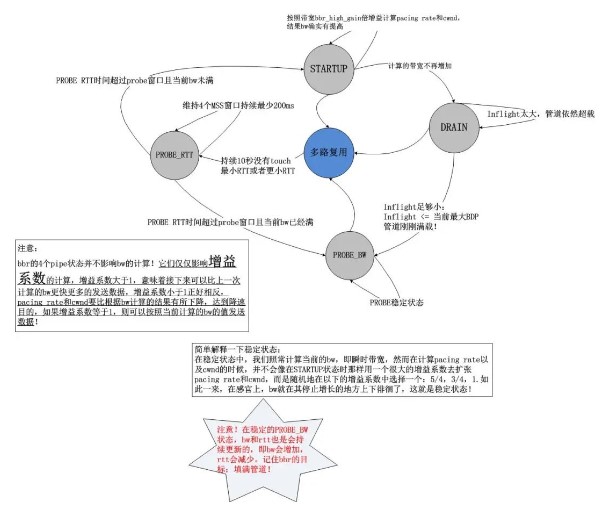
通過上述的狀態機以及上一節的帶寬計算方式,我們知道了bbr的工作方式:不斷地基于當前帶寬以及當前的增益系數計算pacing rate以及cwnd,以此2個結果作為擁塞控制算法的輸出,在TCP連接的持續過程中,每收到一個ACK,都會計算即時的帶寬,然后將結果反饋給bbr的pipe狀態機,不斷地調節增益系數,這就是bbr的全部,我們發現它是一個典型的封閉反饋系統,與TCP當前處于什么擁塞狀態完全無關,其簡圖如下:
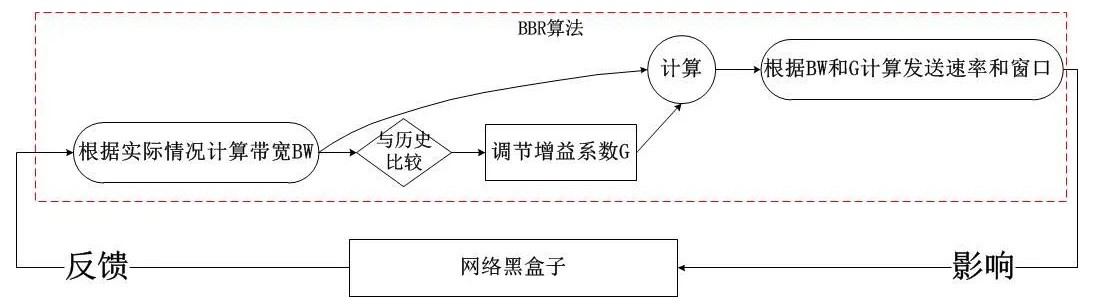
這非常不同于之前的所有擁塞控制算法,在之前的算法中,我們發現擁塞算法內部是受外部的擁塞狀態影響的,比如說在Recovery狀態下,甚至都不會進入擁塞控制算法,在bbr進入內核之前,Linux使用PRR算法控制了Recovery狀態的窗口調整,即便說這個時候網絡已經恢復,TCP也無法發現,因為TCP的Recovery狀態還未恢復到Open,這就是根源!
pacing rate以及cwnd的計算
這一節好像是重點中的重點,但是我覺得如果理解了bbr的帶寬計算,狀態機以及其增益系數的概念,這里就不是重點了,這里只是一個公式化的結論。
pacing rate怎么計算?很簡單,就是是使用時間窗口內(默認10輪采樣)最大BW。上一次采樣的即時BW,用它來在可能的情況下更新時間窗口內的BW采樣值集合。這次能否按照這個時間窗口內最大BW發送數據呢?這樣看當前的增益系數的值,設為G,那么BW*G就是pacing rate的值,是不是很簡單呢?!
至于說cwnd的計算可能要稍微復雜一點,但是也是可以理解的,我們知道,cwnd其實描述了一條網絡管道(rwnd描述了接收端緩沖區),因此cwnd其實就是這個管道的容量,也就是BDP!
BW我們已經有了,缺少的是D,也就是RTT,不過別忘了,bbr一直在持續搜集最小的RTT值,注意,bbr并沒有采用什么移動指數平均算法來“猜測”RTT(我用猜測而不是預測的原因是,猜測的結果往往更加不可信!),而是直接冒泡采集最小的RTT(注意這個RTT是TCP系統層面移動指數平均的結果,即SRTT,但brr并不會對此結果再次做平均!)。我們用這個最小RTT干什么呢?
當前是計算BDP了!這里bbr取的RTT就是這個最小RTT。最小RTT表示一個曾經達到的最佳RTT,既然曾經達到過,說明這是客觀的可以再次達到的RTT,這樣有益于網絡管道利用率最大化!
我們采用BDP*G‘就算出了cwnd,這里的G’是cwnd的增益系數,與帶寬增益系數含義一樣,根據bbr的狀態機來獲取!
BBR的細節淺述
該節的題目比較怪異,既然是細節為什么又要淺述??
這是我的風格,一方面,說是細節是因為這些東西還真的很少有人注意到,另一方面,說是淺述,是因為我一般都不會去分析代碼以及代碼里每一個異常流,我認為那些對于理解原理幫助不大,那些東西只是在研發和優化時才是有用的,所以說,像往常一樣,我這里的這個小節還是一如既往地去談及一些“細節”。
1.豪放且大膽的安全探測
在看到bbr之后,我覺得之前的TCP擁塞控制算法都錯了,并不是思想錯了,而是實現的問題。
bbr之所以敢大膽的去探測預估帶寬是因為TCP把更多的權力交給了它!在bbr之前,很多本應該由擁塞控制算法去處理的細節并不歸擁塞控制算法管。在詳述之前,我們必須分清兩件事:
1)。傳輸多少數據?
2)。傳輸哪些數據?
按照“上帝的事情上帝管,凱撒的事情凱撒管”的原則,這兩件事本來就該由不同的機制來完成,不考慮對端接收窗口的情況下,擁塞窗口是唯一的主導因素,“傳輸多少數據”這件事應該由擁塞算法來回答,而“傳輸哪些數據”這個問題應該由TCP擁塞狀態機以及SACK分布來決定,誠然這兩個問題是不同的問題,不應該雜糅在一起。
然而,在bbr進入內核之前的Linux TCP實現中,以上兩個問題并不是分得特別清。TCP的擁塞狀態只有在Open時才是上述的職責分離的完美樣子,一旦進入Lost或者Recovery,那么擁塞控制算法即便對“問題1):傳輸多少數據”都無能為力,在Linux的現有實現中,PRR算法將接管一切,一直把窗口下降到ssthresh,在Lost狀態則反應更加激烈,直接cwnd硬著陸!隨后等丟失數據傳輸成功后再執行慢啟動。。。。在重新進入Open狀態之前,擁塞控制算法幾乎不會起作用,這并不是一種高速公路上的模式(小碰擦,拍照后停靠路邊,自行解決),更像是鬧市區的交通事故處理方式(無論怎樣,保持現場,直到交警和保險公司的人來現場處置)。
bbr算法逃離了這一切錯誤的做法,在bbr的patch中,并非只是完成了一個tcp_bbr.c,而是對整個TCP擁塞狀態控制框架進行了大手術,我們可以從以下的擁塞控制核心函數中可見一斑:
static void tcp_cong_control(struct sock *sk, u32 ack, u32 acked_sacked, int flag, const struct rate_sample *rs){ const struct inet_connection_sock *icsk = inet_csk(sk); if (icsk-》icsk_ca_ops-》cong_control) { // 如果是bbr,則完全被bbr接管,不管現在處在什么狀態! /* 目前而言,只有bbr使用了這個機制,但我相信,不久的將來, * 會有越來越多的擁塞控制算法使用這個統一的完全接管機制! * 就我個人而言,在幾個月前就寫過一個patch,接管了tcp_cwnd_reduction * 這個prr的降窗過程。如果當時有了這個框架,我就有福了! */ icsk-》icsk_ca_ops-》cong_control(sk, rs); return; } // 否則繼續以往的錯誤方法! if (tcp_in_cwnd_reduction(sk)) { /* Reduce cwnd if state mandates */ // 非Open狀態中擁塞算法不受理窗口調整 tcp_cwnd_reduction(sk, acked_sacked, flag); } else if (tcp_may_raise_cwnd(sk, flag)) { /* Advance cwnd if state allows */ tcp_cong_avoid(sk, ack, acked_sacked); } tcp_update_pacing_rate(sk);}
在這個框架下,無論處在哪個狀態(Open,Disorder,Recovery,Lost.。。),如果擁塞控制算法自己聲明有這個能力,那么具體可以傳輸多少數據,完全由擁塞控制算法自行決定,TCP擁塞狀態控制機制不再干預!
2.為什么bbr可以忽略Recovery和Lost狀態
看懂了以上第1點,這一點就很容易理解了。
在第1點中,我描述了bbr確實忽略了Recovery等非Open的擁塞狀態,但是為什么可以忽略呢?一般而言,很多人都會質疑,會說bbr采用這么魯莽的方式,最終一定會讓窗口卡住不再滑動,但是我要反駁,你難道不知道cwnd只是個標量嗎?我畫一個圖來分析:

看懂了嗎?不存在任何問題!基本上,我們在討論擁塞控制算法的時候,會忽略流量控制,因為不想讓rwnd和cwnd雜糅起來,但是在這里,它們相遇了,幸運的是,并沒有引發沖突!
然而,這并不是全部,本節旨在“淺析”,因此就不會關注代碼處理的細節。在bbr的實現中,如果算法外部的TCP擁塞狀態已經進入了Lost,那么cwnd該是多少呢?在bbr之前的擁塞算法中,包括cubic在內的所有算法中,當TCP核心實現從將cwnd調整到1或者prr到ssthresh一直到恢復到Open狀態,擁塞算法無權干預流程,然而bbr不。雖然說進入Lost狀態后,cwnd會硬著陸到1,然而由于bbr的接管,在Lost期間,cwnd還是可以根據即時帶寬調整的!
這意味著什么?
這意味著bbr可以區別噪聲丟包和擁塞丟包了!
a)。噪聲丟包
如果是噪聲丟包,在收到reordering個重復ACK后,由于bbr并不區分一個確認是ACK還是SACK引起的,所以在bbr看來,即時帶寬并沒有降低,可能還有所增加,所以一個數據包的丟失并不會引發什么,bbr依舊會給出一個比較大的cwnd配額,此時雖然TCP可能已經進入了Recovery狀態,但bbr依舊按照自己的bw以及調整后的增益系數來計算cwnd的新值,過程中并不會受到任何TCP擁塞狀態的影響。
如此一來,所有的噪聲丟包就被區別開來了!bbr的宗旨是:“首先,在我的bw計算指示我發生擁塞之前,任何傳統的TCP擁塞判斷-丟包/時延增加,均全部失效,我并不care丟包和RTT增加”,隨后brr又會說:“但是我比較care的是,RTT在一段時間內(隨你怎么配,但我個人傾向于自學習)都沒有達到我所采集到的最小值或者更小的值!這也許意味著著鏈路真的發生擁塞了!”。。。
b)。擁塞丟包
將a)的論述反過來,我們就會得到奇妙的封閉性結論。這樣,bbr不光是消除了吞吐曲線的鋸齒(ssthresh所致,bbr并不使用ssthresh!),而且還消除了傳統擁塞控制算法(指bbr以及封閉的傻逼Appex之前)的判斷滯后性問題。在cubic發現丟包進而判斷為擁塞時,擁塞可能已經緩解了,但是cubic無法發現這一點。為什么?原因在于cubic在計算新的cwnd的時候,并沒有把當前的網絡狀態(比如bw)當作參數,而只是一味的按照數學意義上的三次方程去計算,這是錯誤的,這不是一個正確的反饋系統的做法!
基于a)和b),看到了吧,這就是新的擁塞判斷機制!綜合考慮丟包和RTT的增加:
b-1)。如果丟包時真的發生了擁塞,那么測量的即時帶寬肯定會減少,否則,丟包即擁塞就是謊言。
b-2)。如果RTT增加時真的發生了擁塞,那么測量的即時帶寬肯定會減少,否則,時延增加即擁塞就是謊言。
bbr測量了即時帶寬,這個統一cwnd和rtt的計量,完全忽略了丟包,因此bbr的算法思想是TCP擁塞控制的正軌!事實上,丟包本就不應該作為一種擁塞的標志,它只是擁塞的表現。
3.狀態機的點點滴滴
我在上文已經呈現了關于STARTUP,DRAIN,PROBE_BW,PROBE_RTT的狀態圖以及些許細節,當時我指出這個狀態圖的目標是為了完成bbr的目標,即填滿整個網絡!在這個狀態圖看來,所有已知的東西就是當前的即時帶寬,所有可以計算的東西就是增益系數,然后根據這兩個元素就可以輕易計算出pacing rate和cwnd,是不是很簡單呢?整體看來就是就是這么簡單,但是從細節上看,不同的pipe狀態中的增益系數的計算卻是值得推敲的,以下是bbr處在各個狀態時的增益系數:
STARTUP:2~3
DRAIN:pacing rate的增益系數為1000/2885,cwnd的增益系數為1000/2005+1。
PROBE_BW:5/4,1,3/4,bbr在PROBE_BW期間會隨機在這些增益系數之間選擇當前的增益系數。
PROBE_RTT:1。但是在探測RTT期間,為了防止丟包,cwnd會強制cut到最小值,即4個MSS。
我們可以看到,bbr并沒有明確的所謂“降窗時刻”,一切都是按照狀態機來的,期間絲毫不會理會TCP是否處在Open,Recovery等狀態。在此前的擁塞控制算法中,除了Vegas等基于延時的算法會在計算得到的target cwnd小于當前cwnd時視為擁塞而在算法中降窗外,其它的所有基于丟包的算法中均是檢測到丟包(RTO或者reordering個重復ACK)時降窗的,可悲的是,這個降窗過程并不受擁塞算法的控制,擁塞算法只能消極地給出一個ssthresh值,即降窗的目標,這顯然是令人無助的!
bbr不再關注丟包事件,它并不把丟包當成很嚴重的事,這事也不歸它管,只要TCP擁塞狀態機控制機制可以合理地將一些包標記為LOST,然后重傳它們便是了,bbr能做的僅僅是告訴TCP一共可以發出去多少數據,僅此而已!然而,如果TCP并沒有把LOST數據包合理標記好,bbr并不care,它只是根據當前的bw和增益系數給出下一個pacing rate以及cwnd而已!
4.關于Sched FQ
這里涉及的是bbr之外的東西,Fair queue!在bbr的patch最后,會發現幾行注釋:
NOTE: BBR *must* be used with the fq qdisc (“man tc-fq”) with pacing enabled, since pacing is integral to the BBR design andimplementation. BBR without pacing would not function properly, and may incur unnecessary high packet loss rates.
記住這幾行文字并理解它們。
這是bbr最為重要的一方面。雖然說Linux的TCP實現早就支持的pacing rate,但直到4.8版本都沒有在TCP層面支持它,很大的一部分原因是因為借助已有的FQ可以很完美地實現pacing rate!TCP可以借助FQ來實現平緩而非突發的數據發送!
關于FQ的詳細內容可以去看相關的manual和源碼,這里要說的僅僅是,FQ可以根據bbr設置的pacing rate將一個cwnd內的數據的發送從“突發到網絡”這種行為變換到“平緩發送到網路”的行為,所謂的平緩發送指的就是數據包是按照帶寬速率計算的間隔一個個發送到網絡的,而不是突發進網絡的!
這樣一來,就給了網絡緩存以緩解的機會!記住,關鍵問題是bbr會在每收到ACK/SACK時計算bw,這個精確的測量不會漏掉任何可乘之機,即便當前網絡擁塞了,它只要能在下一時刻恢復,bbr就可以發現,因此即時帶寬通常可以表現這一點!
5.其它
還有關于令牌桶監管發現(lt policed)的主題,long term采樣的主題,留到后面的文章具體闡述吧,本文已經足夠長了。
6.bufferbloat問題
關于深隊列,數據包如何如何長時間排隊但不丟包卻引發RTO,對于淺隊列,數據包如何如何頻繁丟包。。。談起這個話題我一開始想滔滔不絕,后來想罵人,現在我三緘其口!任何人都知道端到端的QoS是一個典型的反饋系統,但是任何人都只是夸夸其談,我選擇的是閉口不說,如果非要我說,我的回答就是:不知道!
這是一個怎么說都能對又怎么說都能錯的話題,就像股票預測那樣,所以我選擇閉嘴。
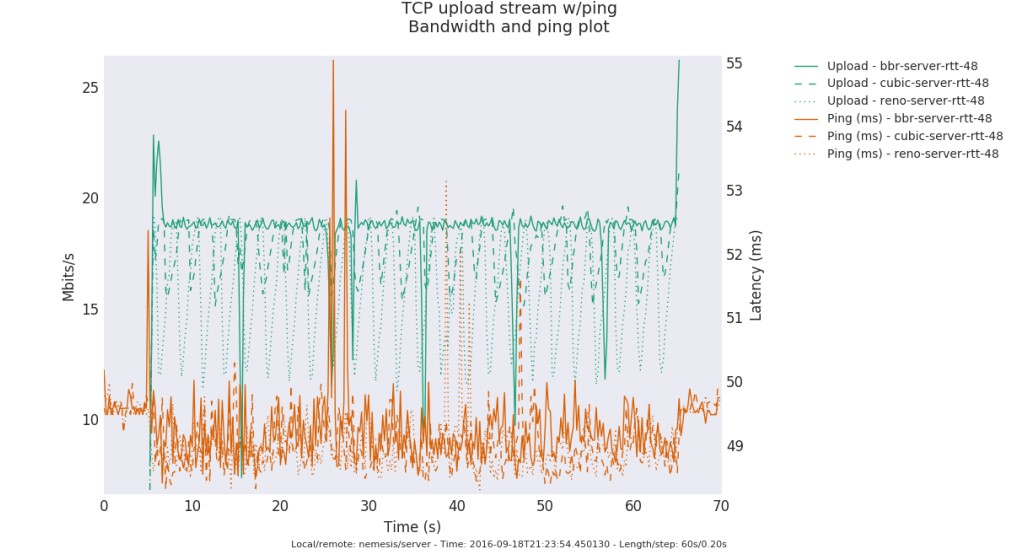
bbr算法到來后,單單從公共測試結果上看,貌似解決了bufferbloat問題,也許吧,也許。bbr好像真的開始在高速公路上飚車了。。。最后給出一個測試圖,來自《A quick look at TCP BBR》:
bbr代碼的簡單性和復雜性
我一向覺得TCP擁塞控制算法太過復雜,而復雜的東西基本上就是用來裝逼的垃圾,直到遇到了bbr。
Neal Cardwell提供的patch簡單而又直接,大家可以從該bbr的patch上一看究竟!在bbr模塊之外,Neal Cardwell主要更改了tcp_ack函數里面關于delivered計數的部分以及擁塞控制主函數,這一切都十分顯然,只要patch代碼就可以一目了然。在數據包被發送的時候-不管是初次發送還是重傳,均會被當前TCP的連接狀況記錄在該數據包的tcp_skb_cb中,在數據包被應答的時候-不管是被ACK還是被SACK,均會根據當前的狀態和其tcp_skb_cb中狀態計算出一個帶寬,這些顯而易見的邏輯相比任何人都應該知道哪里的代碼被修改了!
然而,這種查找和確認的工作太令人感到悲哀,讀懂代碼是容易的,移植代碼是無聊的,因為時間卡的太緊!我必須要說的是,如果一件感興趣的事情變成了必須要完成的工作,那么做它的激情起碼減少了1/4,OK,還不算太壞,然而如果這個必須完成的工作有了deadline,那么激情就會再減少1/4,最后,如果有人在背后一直催,那么完蛋,這件事可以瞬間完成,但是我可以鄭重說明這是湊合的結果!但是實際上,這件事本應該可以立即快速有高質量的完成并驗收!
寫在最后
我比較喜歡工匠精神,一種時間打磨精品的精神,一種自由引導創造的精神。
責任編輯:lq6
-
TCP
+關注
關注
8文章
1378瀏覽量
79206
原文標題:來自 Google 的 TCP BBR 擁塞控制算法深度解析
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何優化TCP協議的性能
背鉆設計與生產:技術解析及應用
深度解析研華全棧式AI產品布局
以太網和TCP/IP的關系解析
康謀技術 | 毫米波雷達技術解析

TCP協議是什么
MODBUS TCP 轉 CANOpen
EtherCAT轉Modbus TCP協議網關(JM-ECT-TCP)

EtherNet/IP轉Modbus-TCP協議網關(EtherNet/IP轉Modbus-TCP)
深度解析TCP與UDP協議
串口服務器和TCP/IP協議棧是什么關系
深度神經網絡(DNN)架構解析與優化策略
無線模塊通過TCP/IP協議實現與PC端的數據傳輸解析
深度解析深度學習下的語義SLAM






 工商網監
工商網監
評論