


論文標題:Learning Sentence Embeddings with Auxiliary Tasks for Cross-Domain Sentiment Classification
會議/期刊:EMNLP-2016
團隊:Singapore Management University
主要思想: 通過構造兩個輔助任務(auxiliary tasks)來從學習句子表示,預測一個句子是否包含有通用情感詞。這些句子表示可以增強原本情感分類模型中的句子表示,從而提升模型的總體領域適應能力。
論文要點一覽:
1. 借鑒了2006年EMNLP的Structural Correspondence Learning的思想
SCL是2016EMNLP的一篇解決領域適應的論文,想法很新穎。核心想法是,不同領域的文本,通常會有一些通用的“指示詞”(稱為pivot words/features),比方在詞性標注任務中,雖然同一個詞性的詞可能在不同領域文本中千差萬別,但是提示詞性的特征往往是類似的,這些共同的特征就稱為pivot features。然后,那些隨著領域變化的,但跟這些pivot features高度相關的詞,就被稱為“聯系詞/對應詞”(correspondences),比方在詞性標注任務中那些關注的詞性對應的詞。
領域適應中,麻煩的就是這些隨著領域變化的correspondences,它們往往潛藏著類別的信息,但是從表面上看是很領域性的,所以如果有辦法把這些詞中潛藏著的通用的類別信息給提取出來,或者把它們給轉化成通用的信息,那這些領域性的詞就變得通用了,就可以適應不同領域了。
這個想法,確實很有意思,值得我們學習。所以這個SCL要解決的關鍵問題就是,如何讓模型看到這些領域詞,能轉化成通用詞。比如在情感分類中,看到評論“這個電腦運行很快!”就能反應出來這個就是“這個電腦好!”。SCL的方法就是,我有一個通用詞的list,把這些詞從句子中挖去,然后讓剩下的部分來預測出是否包含這個詞。構造這樣的任務,就相當于學習一個“通用語言轉化器”,把個性化的語言,轉化成通用的語言。
當然,由于是2006年的論文,所以是采用傳統的機器學習方法來做,得到句子表示也是通過矩陣分解這樣的方法。這個16年的新論文,則是使用的深度學習的方法進行改良和簡化,讓它變得更強大。
2. 跟傳統經典方法的的主要不同
本文提到的主要傳統方法有兩個,一個就是著名的06年的SCL,一個是大名鼎鼎的Bengio團隊在11年ICML的使用auto-encoder的工作。
這兩個工作的一個共同點是,是分兩步進行的,即是一個序列化的方法(learn sequentially),先得到一個特征表示,改善原來的文本特征,然后再使用經典的模型進行預測。
本論文提出的方法,既可以是兩步走的序列化方法,也可以是joint learning,讓輔助任務跟主任務共同學習。
另外,之前的auto-encoder的做法,在數據預處理的步驟,沒有考慮情感分類任務,也就是跟最終要做的任務無關,這當然也不夠好。
3. 本文是一個transductive方法,即訓練的時候要利用到全局數據
訓練可用的數據包括:
有標簽的訓練集(source domain)
無標簽的測試集(target domain)
4. 輔助任務的設計&對原句子表示的加強
作者設計了兩個輔助任務:預測一句話中是否有正/負的通用情感詞。
當然,預測前,需要把句子中的通用情感詞給挖掉,用剩下的詞來預測。這樣設計的依據是什么呢?如果一句話中包含來通用情感詞,比如“好”,那么這句話多半就是正面的情感,那么這句話剩下的其他的部分,應該也大概率會包含一些領域特定的反應情感的詞,比如“(電腦)很快”。那么我們訓練一個能夠使用這些領域特定的詞預測通用情感詞的模型,就可以得到一個“通用情感轉化器”,把各種不同領域的句子,轉化成通用的表示。
輔助任務的損失函數如下:
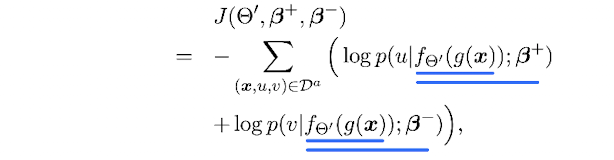
就是二分類交叉熵損失之和。
如下圖所示,左半邊就是一個傳統的分類模型。右邊的就是輔助任務對應的模型。
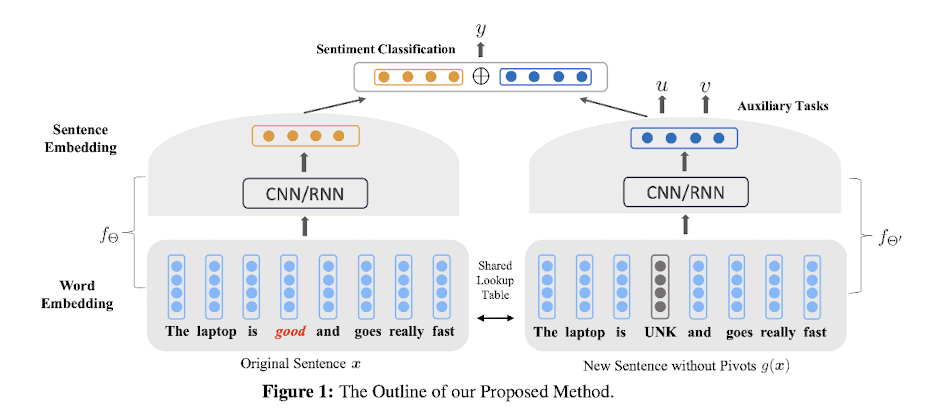
通過把原句子的通用情感詞替換成[UNK],然后使用輔助任務訓練一個新的模型,就可以得到一個通用的句子表示向量,也就是圖中的藍色的向量。
最后,把這個向量,跟原句子向量拼接起來,就得到來加強版的句子表示,最終使用這個句子表示來做情感分類任務。
5. 聯合訓練joint learning
上面講的方法,依然是分兩步做的,這樣會有些麻煩。其實整個框架可以同時訓練,也就是把兩部分的損失函數合在一起進行優化:
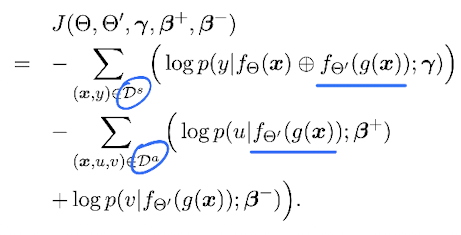
注意,兩部分的loss,分別來自不同的數據集,但是在輔助模型分布,是兩部分數據都會使用的,見圖中畫藍線的地方。
就是代碼實現上,我一開始想不通如何讓兩個不同的數據集(labeled source data和unlabeled target data)放在一起同時訓練,看了看作者的代碼也沒看明白(基于Lua的torch寫的),直到我看到了作者readme最后寫了一個提示:

就是說,所謂的joint learning,并不是真正的joint,相當于一種incremental learning(增量學習)。每個epoch,先把source部分的數據給訓練了,然后再輸入target部分來優化auxiliary部分的模型。
6. 如何選擇pivot words
本文使用了一種叫weighted log-likelihood ratio(WLLR)的指標來選擇最通用的情感詞作為pivot words。這個WLLR的公式如下:
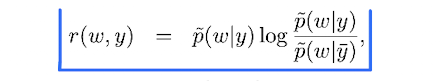
公式里的y就是標簽,而y一杠是相反的標簽。w則代表某個詞。從公式可以看出,當一個詞在一個標簽的文本中經常出現,而在相反標簽的文本中出現很少,那么這個詞的WLLR值就高。
在SCL論文中,使用的是互信息,但是作者發現互信息偏愛那些低頻詞,相比之下WLLR則公平一些,因此作者選擇WLLR。
7. 數據集和實驗結果
實驗結果主要表明,Joint Learning確實可以。但Sequential則效果不敢恭維。。。這一點是我覺得容易讓人詬病的地方,畢竟按照前文中介紹的,即使是Sequential,也因為學習到了很好的句子表示,應該效果也很不錯才對。
另外實驗結果中,對比一下機器學習方法和深度學習方法可以看出,只是用離散特征,效果完全比不是深度學習使用連續特征的方法。注意,這里的NN是指CNN,使用了詞向量,而詞向量相當于已經擁有了很多外部知識了,所以一個單純的CNN,不進行任何的domain adaptation的設計,都比傳統的SCL等方法都好。
作者還做了一些“使用部分target標注數據來訓練”的實驗:發現,也有微弱的提升(0.6%實在不算多哈)。并且,隨著標注數據量的提升,差距還在縮小:
8. Case Study
這里的case study值得學習,分析的很細致,邏輯清晰,還印證了論文的理論假設。即,作者對比了單純的CNN和使用了輔助任務來訓練的CNN,在分類時的重要詞匯是哪些,發現了一些有趣的現象。
我們這里稱單純的CNN為NaiveNN,使用輔助任務的序列化方法為Sequential,聯合訓練的則為Joint。其中,Sequential和Joint又可以把模型分成兩個部分,分別為-original和-auxiliary。
總結一下:
NaiveNN抽取出來的,多半都是“通用情感詞”;
Sequential-original提取出來的跟NaiveNN類似;
Sequential-auxiliary提取出的,多半是“領域詞”,包括“領域情感詞”和“領域類型詞”,后者是該領域的一些特征詞,但并不是情感詞,所以是個噪音,可能會對情感模型產生負面影響;
Joint-auxiliary則提取出的基本都是“領域情感詞”,即相比于sequential少了噪音;
Joint-original則可提取出“通用情感詞”和“領域情感詞”,因為它跟aux部分共享了sentence embedding。
雖然case study一般都是精挑細選過的,但至少作者分析總結的還是很到位,也就姑且信了。
最后:
總的來說,這是一個想法較為新穎,方法較為實用,思路也make sense的工作。巧妙地借用了SCL的思想,并做了合理的簡化和升級,取得了還不錯的效果。
編輯:jq
-
數據集
+關注
關注
4文章
1224瀏覽量
25480 -
SCL
+關注
關注
1文章
243瀏覽量
17568 -
cnn
+關注
關注
3文章
354瀏覽量
22765
原文標題:使用輔助任務來提升情感分類領域適應
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
51Sim利用NVIDIA Cosmos提升輔助駕駛合成數據場景的泛化性
NVIDIA如何讓靈巧機器人更加適應環境
DevEco Studio AI輔助開發工具兩大升級功能 鴻蒙應用開發效率再提升
基于Raspberry Pi 5的情感機器人設計

xgboost在圖像分類中的應用
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
【「大模型啟示錄」閱讀體驗】如何在客服領域應用大模型
基于LSTM神經網絡的情感分析方法
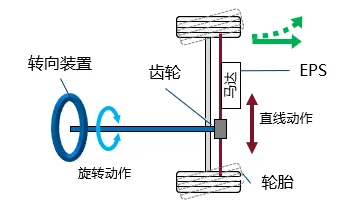
什么是EPS?通過馬達來輔助轉向操作的系統





 工商網監
工商網監

評論