 Transformers在計算機視覺領域的應用情況
Transformers在計算機視覺領域的應用情況
CV(計算機視覺)領域一直是引領機器學習的弄潮兒。近年來更是因為Transformers模型的橫空出世而掀起了一陣腥風血雨。小編今天就帶大家初步認識一下這位初來乍到的CV當紅炸子雞~本文主要介紹Transformers背后的技術思想,Transformers在計算機視覺領域的應用情況、最新動態以及該架構相對于CNN的優勢。讀完這篇文章之后,你將能知道:
為什么Transformers模型在NLP自然語言處理任務中能夠力壓群雄,變成SOTA模型的必備組件之一。
Transformers模型的計算原理。
為什么說Transformers是對CNN的當頭棒喝,Transformers是怎么針對CNN的各種局限性進行補全的。
計算機視覺領域的最新模型是如何應用Transformers提升自己的。
1
長期依賴和計算效率之間的權衡取舍
在自然語言處理領域中,一個重要的技術基礎就是創建合理的Embedding。Embedding是NLP系統的根基,一個好的Embedding需要能夠將原始文本中盡可能多的語義片段進行有效編碼。
這些語義信息其實并不只是代表一個詞的定義跟含義,很多時候是需要結合上下文進行聯系的。比如當我們孤零零的得到一個詞“快”的時候,我們不知道它是指Fast還是Almost,基于這樣沒有上下文的孤零零的單詞的Embedding,很多時候是盲目并且沒有意義的。又比如說這句話:“Transformers特別牛,因為它在很多項目中都能大幅提高模型的性能”。
讀了這句話,我們知道文中的“它”是指Transformers,但是如果沒有這一整句話的承載,而是孤零零的給你一個詞“它”,估計誰都不曉得這個家伙指代的是誰,那如此Embedding出來的結果也將毫無意義。
一個好的機器學習模型應該能夠準確表達單詞之間的依賴關系,不論是在超大型的文本中,還是在比較簡短的文字片段中都是如此。
這就像是一個伏筆,作者在第一章中埋下了一個伏筆,隔了四五十頁之后再次提及起它的時候,讀者會覺得這是神來之筆,因為能夠聯系起它和當前文字之間的關系。機器學習模型也應該具備這種記憶能力,以及超遠文字之間的記錄和依賴表達能力。或者換句話說,好的模型應該具有“長期依賴性的編碼能力”。
在詳細介紹Transformers之前,我們先來梳理一下NLP領域在Transformers技術誕生之前所面臨的問題,尤其是在挖掘數據之間的長期依賴性時所面臨的問題。
循環神經網絡的問題
在NLP領域中,以LSTMs和GRU為代表的循環神經網絡曾經風光無限,它們的結構內部有極其巧妙的長期狀態輸入和輸出,能夠讓模型從文本中提取豐富的上下文語義。
它們的工作方式都是串行的,一次處理一個單詞或者輸入單元,并且設計了記憶結構來存儲已經看到的內容的抽象特征,這些長時的抽象信息能夠在之后的數據處理中幫助模型理解當前輸入,或者處理長期的數據依賴,從而將前文中的語義信息添加到當前的結果輸出之中。
RNN結構能夠將前文的信息寫入到記憶模塊之中,是因為它們內部有各種門結構。其中輸入門能夠讓神經網絡有選擇性的記錄一些長時的有效信息,遺忘門會有針對性地拋棄一些無關的冗余信息,更新門還可以讓網絡對自身當前的狀態根據輸入進行實時更新。
相對于普通RNNs來說,加入了各種門結構的LSTM和GRU更受世人的喜愛,這是因為它們能夠解決梯度爆炸和梯度消失的問題,模型的魯棒性得到了明顯提升。
梯度爆炸和梯度消失是長久以來困擾RNNs的一大問題。LSTM和GRU能夠利用自身模型結構給梯度“續命”,有效追蹤序列數據中相當長時間數據之間的依賴關系。
但是我們還是發現,這種序列式的網絡,以及將有效信息存儲到各個零散的神經元的方式,并不能有效地保存那些超長的數據依賴。
此外,序列式的網絡結構也難以讓LSTM和GRU網絡有效地進行擴展和并行化計算。
因為每一個前向的傳遞都是依賴于前一個時間步的處理結果,每得到一個輸入,模型只能給出一步的輸出。也就是每一步的計算都只能顧及當前輸出,得到一個Embedding結果。
卷積神經網絡的問題
卷積神經網絡也是 NLP 系統中的常客,尤其是對于那些使用 GPUs 訓練的模型任務來說更是如此。這是因為 CNNs 和 GPU 的組合能夠天然耦合兩者在計算伸縮性和高效性上的特點,所以二者逐漸成為形影不離的好基友。
CNNs 常被用在圖像特征提取上,與此類似,在 NLP領域中,網絡也會利用 CNNs 的一維濾波器從文本中提取有效信息,此時的文本就對應地以一維時間序列的形式進行表示了。
所以圖像處理中使用2D CNN , NLP 中就使用1D CNN ~CNN的感受野(就是CNN能夠看到的局部信息大小)是由卷積核/濾波器的尺寸,以及濾波器的通道數所決定的。
增加卷積核的尺寸或者濾波器的通道數會增加模型的大小,也會讓模型的復雜度大幅增加。這也許會導致梯度消失的問題,從而引發讓整個網絡無法訓練收斂的嚴重后果。
為解決這個問題,殘差連接 Residual connections 和空洞卷積 Dilated Convolutions 應運而生。它們能夠在一定程度上增強梯度的傳播深度,從而在一定程度上擴大模型的感受野(后面的層就能看到更多的局部信息了嘛)。
但是,卷積神經網絡畢竟只是關注局部信息的網絡結構,它的這種計算機制導致了它在文本信息處理上難以捕捉和存儲長距離的依賴信息。人們一方面想擴大卷積核、增加通道數來捕捉長期依賴,一方面還害怕由于擴大模型所導致的維度災難。
2
Transformers橫空出世
扯了半天終于要介紹我們今天的主角——Transformer 了。2017年的時候 Transformer 橫空出世,當時的它被定位成一種簡單并且可擴展的自然語言翻譯方法,并且很快被應用到各類 NLP 任務之中,逐漸成為 SOTA 模型中的必備成員(比如 GLUE 、SQuAD 或者 sWAG )。
但并不是所有任務都是有能夠喂飽深度網絡的數據資本的,所以很多任務都會基于上述SOTA模型公開版本的半成品進行微調( finetuning ),從而適配自己的任務。
這種做法十分常見并且有效,因為它大幅的節省了訓練所需的數據量。這些模型有的已經有著數十億個參數量了,但是似乎還沒有達到性能的天花板。
隨著模型參數量的增加,模型的結果還會持續上升,模型由此而表現的一些新特性和學習到的新知識也會越來越豐富,具體可以看GPT3的文章。
Transformer模型
當我們給定了一個包含N個單詞的文本輸入時,對于每個單詞W,Transformers會為文本中的每個單詞Wn創建N個權重,每個權重的值取決于單詞在上下文中的依賴關系(Wn),以此來表示正在處理的單詞的語義信息W。下圖表述了這個想法,其中,藍色線條的顏色深度表示分配給某個單詞的注意力Attention的權重。
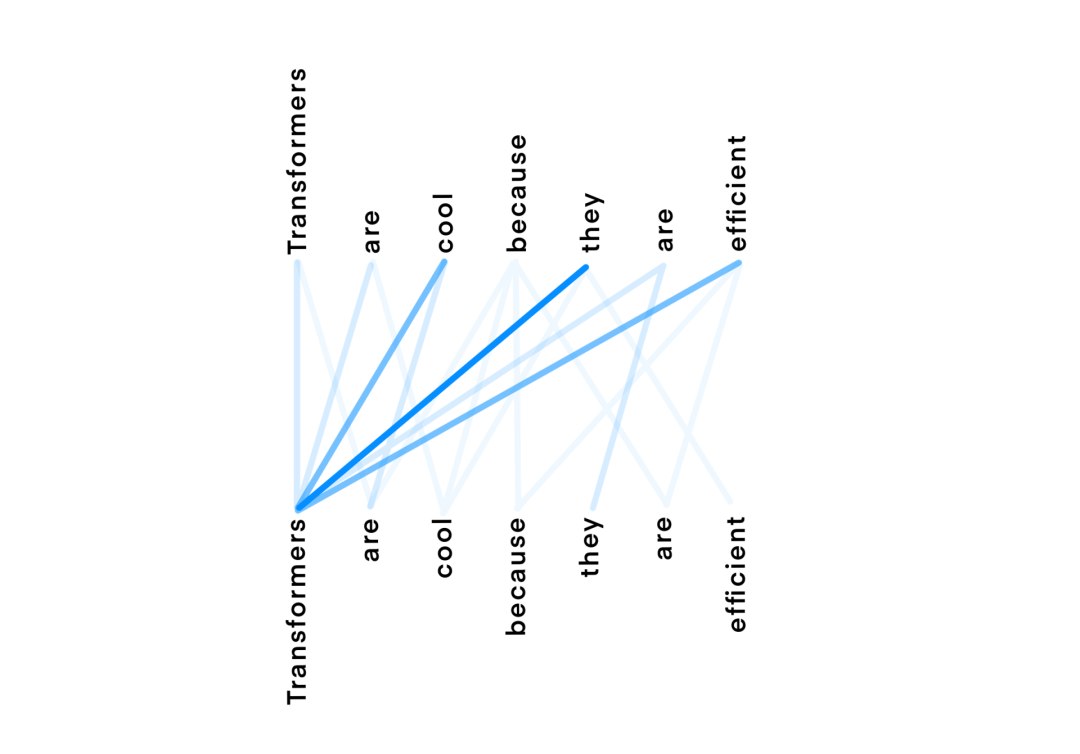
在這里,上面一行表示正在處理的單詞,下面一行表示用作上下文的單詞(注意,有些單詞是相同的,但是如果它們正在被處理或被用于處理另一個單詞的時候,它們的地位和處理方式將會有所差異)。
請注意,上面一行的“They ”、“Cool”或者“Efficient”有很高的權重指向“Transformer”,因為這確實是它們所引用的目標單詞。然后,這些權重被用來組合來自每對單詞的值,并為每個單詞( W )生成一個更新的嵌入,該單詞( W )現在包含關于這些重要單詞( Wn )在特定單詞( W )上下文中的信息。
其實,在這些現象的背后,transformers 使用了 self attention 即自注意力技術來計算這些更新的 Embedding 。
Self Attention 是一種計算效率很高的模型技術,它可以并行地更新輸入文本中每個單詞的嵌入結果。
自注意力機制
假設我們得到了一段輸入文本,并且從文本中的單詞嵌入 W 開始。我們需要找到一種 Embedding 方法來度量同一文本中其他單詞嵌入相對于 W 的重要度,并合并它們的信息來創建更新的嵌入W‘。
自注意力機制會將 Embedding 輸入文本中的每個單詞線性投影到三個不同的空間中,從而產生三種新的表示形式:即查詢query、鍵key和值value。這些新的嵌入將用于獲得一個得分,該得分將代表 W 和每個Wn 之間的依賴性(如果 W 依賴于 W’,則結果為絕對值很高的正數,如果 W 與W‘不相關,則結果為絕對值很高的負值)。
這個分數將被用來組合來自不同 Wn 單詞嵌入的信息,為單詞 W 創建更新的嵌入W’。下面這張圖展示了如何計算兩個單詞之間的 Attention 得分:
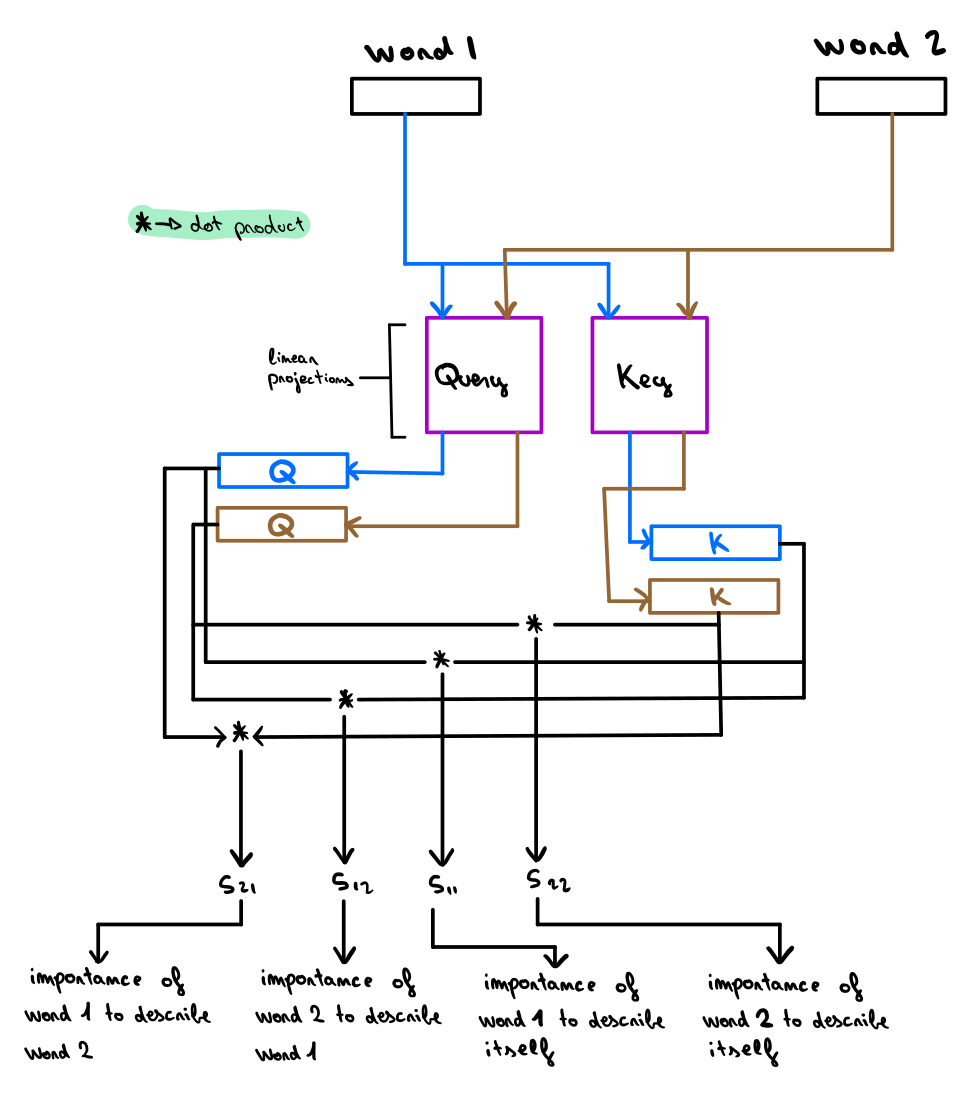
作者親繪
圖中的藍色線段表示來自第一個單詞 W 的信息流,棕色線代表來自第二個單詞 Wn 的信息流。每個單詞的嵌入將乘以一個鍵和一個查詢矩陣,從而得到每個單詞的查詢值和鍵值。
為了計算 W 和 Wn 之間的分數,將W(W_q)的查詢嵌入發送到 Wn ( Wn_k )的密鑰嵌入,并為兩個張量使用點積相乘。點積的結果值是它與自身之間的得分,表示 W 相對于 Wn 的依賴程度。需要注意的是,我們還可以將第二個單詞作為W,以及將第一個單詞作為 Wn 。
這樣的話,我們就可以另外計算出一個分數,表示第二個單詞對第一個單詞的依賴性。我們甚至可以用同一個詞 W 和 Wn 來計算這個詞本身對它的定義有多重要~很巧妙吧。
自注意力機制能夠計算文本中每對單詞之間的注意力得分。該得分將被軟最大化處理 (Softmaxed),也就是將其轉換為0到1之間的權重。下圖展示了如何使用這些權重獲得每個單詞的最終詞嵌入:
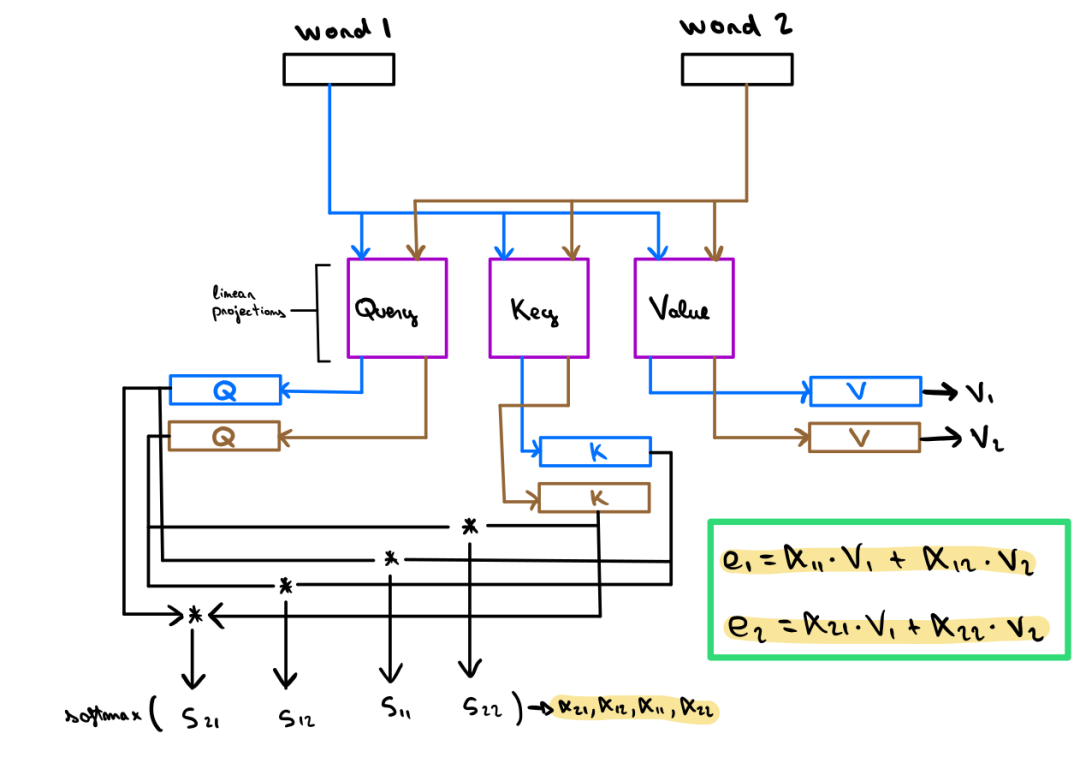
作者親繪
請注意,每個單詞的 Embedding 現在需要乘以第三個矩陣來生成它們的值表示。這個結果將用于計算每個單詞的最終嵌入。對于每個單詞 W,文本 Wn 中每個單詞的計算權重將乘以其相應的值表示(Wn_v),然后將它們相加。這個加權和的結果將用于更新嵌入單詞 W (圖中用e1和e1表示)。
這里我們只是簡單的對計算過程進行介紹,如果有小伙伴對其中的具體過程感興趣的話,可以看看 Jay Alamar 下面的這篇文章:https://jalammar.github.io/illustrated-transformer/。
3
卷積歸納偏差
卷積網絡模型多年來在計算機視覺領域是絕對的大哥大,獲得了無數的成功,收獲了無數的好評。GPU 作為 CNN 的好基友,由于可以進行有效的并行卷積計算而身價瘋長。此外,CNN 也會在圖像特征提取的過程中提供適當的歸納偏差( Inductive Biases )。CNN 中的卷積運算由于使用了兩個重要的空間約束,從而有助于視覺特征的學習和提取:
由于 CNN 權重共享機制,卷積層所提取的特征便具有平移不變性,它們對特征的全局位置不感冒,而只在乎這些決定性的特征是否存在。
由于卷積算子的性質,所以卷積的特征圖具有局部敏感性,也就是每次卷積操作只會考慮原始數據的一小部分的局部信息。
正是由于此,CNN 的歸納偏差缺乏對輸入數據本身的整體把握。
它很擅長提取局部的有效信息,但是沒能提取全局數據之間的長距離特征。比如,當我們使用 CNN 去訓練一個人臉識別模型時,卷積層可以有效的提取出眼睛大小、鼻子翹不翹、嘴巴顏色等小器官的特征,但是無法將他們聯系起來,無法形成“眼鏡在鼻子上”、“嘴巴在眼睛下面”的這種長距離的特征。
因為每個卷積核都很局部,沒辦法同時處理這么多個特征。為了提取和跟蹤這些原始數據中的長相關特征,模型需要擴大自己的感受野,這就需要使用一些更大的卷積核,以及更深的卷積。但是由此會帶來計算效率的大幅下降,會讓模型的復雜度劇烈上升,甚至會讓模型產生維度災難從而無法收斂訓練。
這種顧此失彼的權衡是不是聽起來很耳熟?
4
計算機視覺領域中的Transformers
受到 Transformer 論文中使用自注意力機制來挖掘文本中的長距離相關依賴的啟發,很多計算機視覺領域的任務提出使用自注意力機制來有效克服卷積歸納偏差所帶來的局限性。
希望能夠將這種 NLP 領域中的技術思想借鑒到視覺領域中,從而提取長時依賴關系。功夫不負有心人,Transformer為視覺領域帶來了革新性的變化,它讓視覺領域中目標檢測、視頻分類、圖像分類和圖像生成等多個領域有了長足的進步。
這些應用了 Transformer 技術的模型有的識別能達到甚至超越該領域 SOTA 解決方案的效果。
更讓人興奮的是,這些技術有的甚至干脆拋棄了 CNN,直接單單使用自注意力機制來構建網絡。
目標檢測:https://arxiv.org/pdf/2005.12872.pdf
視頻分類:https://arxiv.org/pdf/1711.07971.pdf
圖像分類:https://arxiv.org/pdf/1802.05751.pdf
圖像生成:https://arxiv.org/pdf/2010.11929.pdf
這些使用了自注意力機制所生成的視覺特征圖不會像卷積計算一樣具有空間限制。相反,它們能夠根據任務目標和網絡中該層的位置來學習最合適的歸納偏差。
研究表明,在模型的前幾層中使用自注意力機制可以學習到類似于卷積計算的結果。
如果小伙伴想具體了解這一領域最近的動態,可以查看這篇由 Gbriel | lharco
撰寫的推文:https://arxiv.org/pdf/1911.03584.pdf
自注意力層
計算機視覺領域中的自注意力層的輸入是特征圖,目的是計算每對特征之間的注意力權重,從而得到一個更新的特征映射。其中每個位置都包含關于同一圖像中任何其他特征的信息。
這些層可以直接代替卷積或與卷積層相結合,它們也能夠處理比常規卷積更大的感受野。因此這些模型能夠獲取空間上具有長距離間隔的特征之間的依賴關系。
比如Non-local Netorks和Attention Augmented Convolutional Networks文章中所述,自注意力層最基本的實現方法是將輸入特征圖的空間維度展開成為一系列的 HWxF 的特征序列,其中 HW 表示二維空間維度, F 表示特征圖的深度。自注意力層可以直接作用在序列數據上來獲取更新后的特征圖表示。
想具體了解這兩篇論文的小伙伴請戳這里Non-local Netorks:https://arxiv.org/pdf/1711.07971.pdfAttention Augmented Convolutional Networks:https://arxiv.org/abs/1904.09925
但是實際上,對于高分辨率的輸入來說,自注意力機制層的計算量很大,因此它只適用于較小的空間維度輸入的數據場景。
很多工作也注意到這個問題,并且提出了一些解決方案,比如Axial DeepLab,它們沿著兩個空間軸順序計算Attention,而不是像普通自注意力機制一樣直接處理整個圖像數據,這使得計算更加高效。還有一些其他的優化解決方案,比如只處理較小的特征圖Patch,而不是處理整個特征圖空間。
但是這樣操作的代價是感受野比較小,這是在論文Stand-Alone Self-Attention in Vision Models中提出的。但是即便這樣的感受野受到了限制,也比卷積操作的卷積核的感受野要大得多。
Axial DeepLab:https://arxiv.org/pdf/2003.07853.pdfStand-Alone Self-Attention in Vision Models:https://arxiv.org/pdf/1906.05909.pdf
當我們在模型的最后一層是用自注意力機制來將前面的各種卷積層相融合的時候,就可以得到最優的模型結果。
事實上,在實驗中我們會發現,自注意力機制和卷積層是很類似的,尤其是在網絡的前若干層中自注意力機制學習到的歸納偏差和卷積層學習到的特征圖十分類似。
視覺Transformers
現有的計算機視覺工作中,除了那些將自注意力機制加入卷積流程中的工作之外,其他的方法的計算都僅僅依賴于自注意力層,并且只使用了最原始的Transformer的編碼-解碼器結構。
當我們的模型參數量能夠設置得很大,并且數據量充足的時候,這些模型在圖像分類任務/目標檢測等任務中所表現出來的效果能夠達到SOTA的程度,甚至有時候更好。
同時這些模型的結構會更加簡單,訓練速度還會更快。最原始的Transorfer的編碼-解碼器結構:https://arxiv.org/pdf/1706.03762.pdf
接下來我們簡要的介紹三篇重要的相關論文,它們都在自己的網絡中使用了Transformer結構。
1、Image Transormer這篇論文提出了一種在ImageNet數據集上的全新SOTA圖像生成器,并且在超高分辨率任務上取得了很好的效果。
論文地址:https://arxiv.org/pdf/1802.05751.pdf
在這篇論文中,他們將圖像生成任務視作一個自回歸問題,圖片中的每個新像素僅基于圖像中先前已知的像素值生成。在每一個特征生成過程中,自注意力機制將m個展開后的特征圖作為上下文,從而生成未知的像素值。為了讓這些像素能夠匹配自注意力層的輸入,論文使用1D卷積將每個RGB值轉換為d維張量,并將局部的上下文特征圖的m維特征展平到一維。下圖就是這個模型的示意圖:
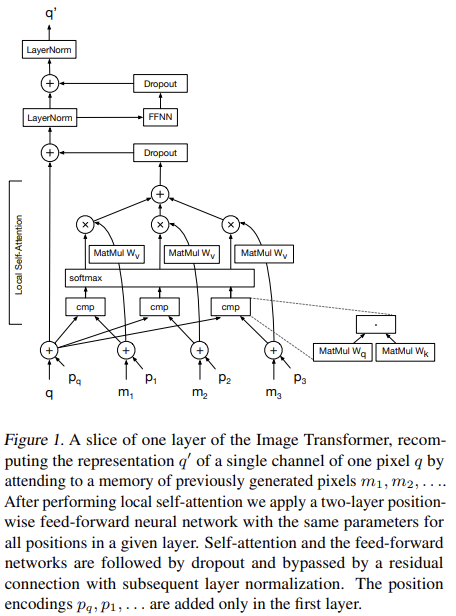
原文中3.2節圖1的自注意力結構
在圖中,q表示要更新的像素embedding,它與內存中的像素m的所有其他嵌入相乘,使用查詢和鍵矩陣(Wq和Wk)生成一個得分,然后對該得分進行softmax操作,并將其作為矩陣Wv的權重。
算法最終將該Embedding加到原始的q Embedding中,從而得到最終的結果。在圖中,p表示添加到每個輸入嵌入中的位置編碼。這種編碼是從每個像素的坐標生成的。
需要注意的是,通過使用自注意力機制,算法可以并行地預測多個像素值,因為算法已經知道輸入圖像的原始像素值,并且用于計算自我注意的Patch機制,可以處理比卷積層更高的感受野。但是在評估的操作過程中,由于圖像的生成依賴于每個像素的鄰居的值,因此只能單步執行。
2、DETRDETR是DEtection TRansformer的縮寫,它是一種結構較為簡單的模型,在目標檢測領域中達到了SOTA的高度。論文地址:https://arxiv.org/pdf/2005.12872.pdf模型的結構如下圖所示:
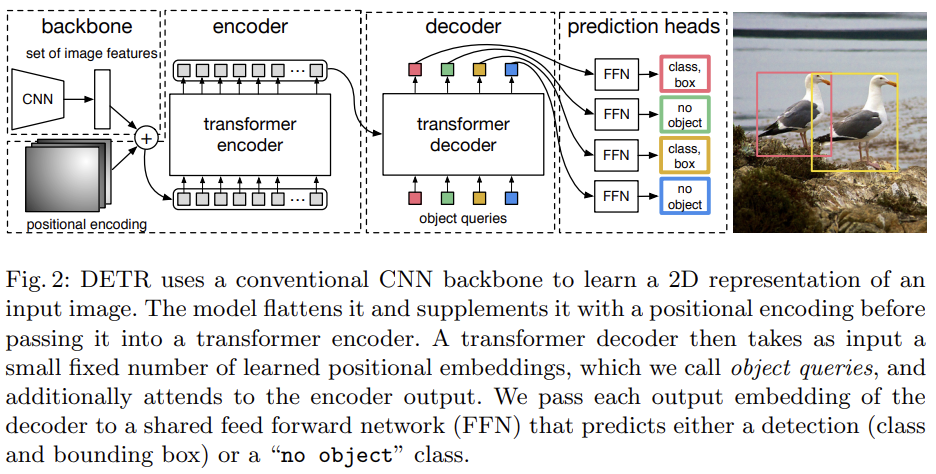
原文中3.2節圖2的DETR結構圖
它搭配著使用了自注意力機制,以及從卷積神經網絡提取的視覺特征。在CNN的主干模塊中,算法計算的特征圖會首先被展平,也就是說,如果特征地圖具有形狀(h x w x d),則展平結果將具有形狀(hw x d)。每一個維度中都添加了一個可學習的位置編碼,而編碼器也會將結果序列作為輸入。
編碼器使用多個自注意力塊來組合不同Embedding之間的特征。處理后的Embedding被傳遞到一個解碼器模塊。這個解碼器模塊使用可學習的Embedding作為對象查詢來處理所有視覺特征,從而生成一個嵌入。在該嵌入中,執行目標檢測所需的所有信息都被編碼。
每個輸出被輸入到一個全連接層中,該網絡模塊將輸出一個包含元素c和b的五維張量,其中c表示該元素的預測類個數,b表示邊界框的坐標(分別是一維和四維)。
c的值分配給一個“no object”標記,它表示沒有找到任何有意義的檢測的目標查詢,所以說模型將不考慮它的坐標。
這個模型能夠并行計算單個圖像的多個檢測。但是,它可以檢測到的目標個數受制于所使用的目標查詢次數。
論文的作者在文中表示,該模型在大尺寸目標識別的圖像處理方面優于SOTA模型。他們認為這都歸功于自注意力機制為模型提供了更高的感受野。
3、Vision Transformer(ViT)這個模型是圖像識別領域的代表性SOTA工作,它僅僅使用了自注意力機制,而且達到了目前的SOTA識別率。論文地址:https://arxiv.org/pdf/2010.11929.pdf下面是論文模型的一個例子:
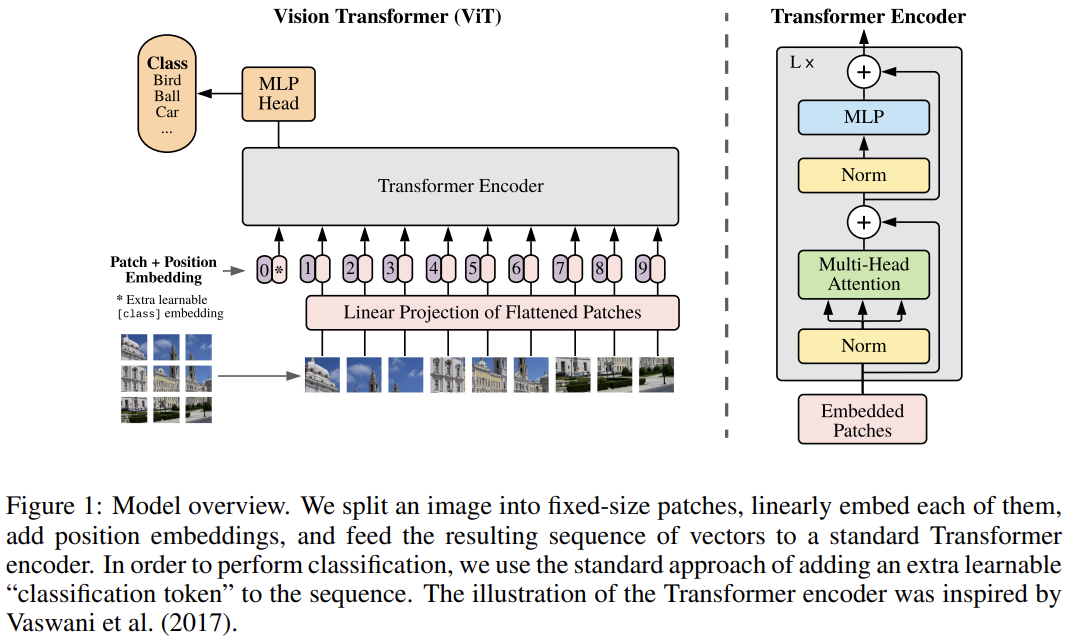
原文3.1節圖1中的ViT結構
該模型的輸入是從像素大小為PxP的塊中提取的平坦像素向量。每個輸入像素被送入一個線性投影層,這個層將產生文中所謂的“補丁嵌入(Patch embeddings)”。
注意,在序列的開頭處,模型附加了一個額外可學習的嵌入。這種嵌入處于自我注意更新之后,用于預測輸入圖像的類別。
每個Embedding中也添加了一個可學習的位置Embedding。分類只需將一個 MLP 頭放在Transformer結構的頂部,具體的插入位置就是在我們添加到序列中的額外可學習的Embedding位置。
此外,本文還給出了一種混合的模型結構。它使用ResNet早期的特征映射作為Transformer的輸入,而沒有選擇輸入投影的圖像塊。
通過對 Transformer 模型和 CNN 骨干網絡端到端的訓練,模型能夠達到最好的圖像分類結果。
5
位置編碼
由于Transformers需要學習一個具體的任務,也就是需要學習該任務的歸納偏差,所以只要進行模型訓練,就都會對該網絡產生一定的收益。
換句話說,任何可以包含在模型輸入中的歸納偏差都將有助于模型的學習,并能夠用于改善結果。當使用Transformers的更新功能時,輸入序列的順序信息會被丟失。
對于Transformer模型來說,這個順序信息是很難被學習到的,或者說有的時候根本不可能被學習到。
所以它所做的就是將一個位置表示聚合到模型的輸入嵌入中。這種位置編碼可以通過學習獲得,也可以從一個固定的函數中取樣得到。
雖然聚合操作通常只在輸入到模型的嵌入處完成,但是我們其實是可以改變這個聚合操作的位置。在計算機視覺中,這些嵌入既可以表示特征在一維平坦序列中的位置,也可以表示特征的二維位置。在該領域中,大家普遍認為位置編碼是很有效的一種信息。
它們由可學習的若干個嵌入組成。
這些嵌入特征不用編碼全局的位置,轉而去學習各個編碼特征之間的相對距離從而達到更好的效果。
6
結論
Transformers結構解決了一個自然語言處理和計算機視覺領域都困擾已久的問題——長期依賴。
Transformer模型是一種很簡單但是很靈活的方法,如果將其抽象為一系列嵌入,那么它可以應用于任何類型的數據。卷積具有平移不變性、局部敏感性,也缺少對圖像的整體感知和宏觀理解。
Transformers可用于卷積網絡中,從而讓網絡學習處對圖像的全局理解。
Transformers能夠用于計算機視覺領域,就算我們把原來卷積網絡中的卷積層都拋棄,只使用Transformers層的時候,模型也能得到SOTA的結果。
責任編輯:lq
-
計算機視覺
+關注
關注
8文章
1700瀏覽量
46059 -
機器學習
+關注
關注
66文章
8435瀏覽量
132887 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13605
原文標題:Transformer在CV界火的原因是?
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論