") 如何向大規(guī)模預(yù)訓(xùn)練語言模型中融入知識?
如何向大規(guī)模預(yù)訓(xùn)練語言模型中融入知識?
本文介紹了復(fù)旦大學(xué)數(shù)據(jù)智能與社會計(jì)算實(shí)驗(yàn)室 (Fudan DISC)在ACL 2021上錄用的一篇Findings長文: K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters
文章摘要
本文關(guān)注于向大規(guī)模預(yù)訓(xùn)練語言模型(如RoBERTa、BERT等)中融入知識。提出了一種靈活、簡便的知識融入框架K-Adapter,通過外掛知識插件的方式來增強(qiáng)原模型,緩解了知識遺忘的問題、且支持連續(xù)知識學(xué)習(xí)。本文提出的模型在三種知識驅(qū)動的任務(wù),包括了命名實(shí)體識別、關(guān)系分類、問答等任務(wù)上取得了顯著的效果。
研究背景
預(yù)訓(xùn)練語言模型,如BERT、GPT、XLNet、RoBERTa,可以通過無監(jiān)督訓(xùn)練目標(biāo)(如MLM)來從大規(guī)模文本語料中學(xué)習(xí)通用表示,并且在各種各樣的下游任務(wù)上取得了SOTA的表現(xiàn)。盡管這些模型取得了巨大的進(jìn)步,但是最近的一些工作表明這些通過無監(jiān)督方式訓(xùn)練的模型很難學(xué)習(xí)到豐富的知識,如邏輯知識、事實(shí)類知識、語言學(xué)知識、特定領(lǐng)域的知識等等。因此這啟發(fā)了本文來研究如何向預(yù)訓(xùn)練模型中融入知識。
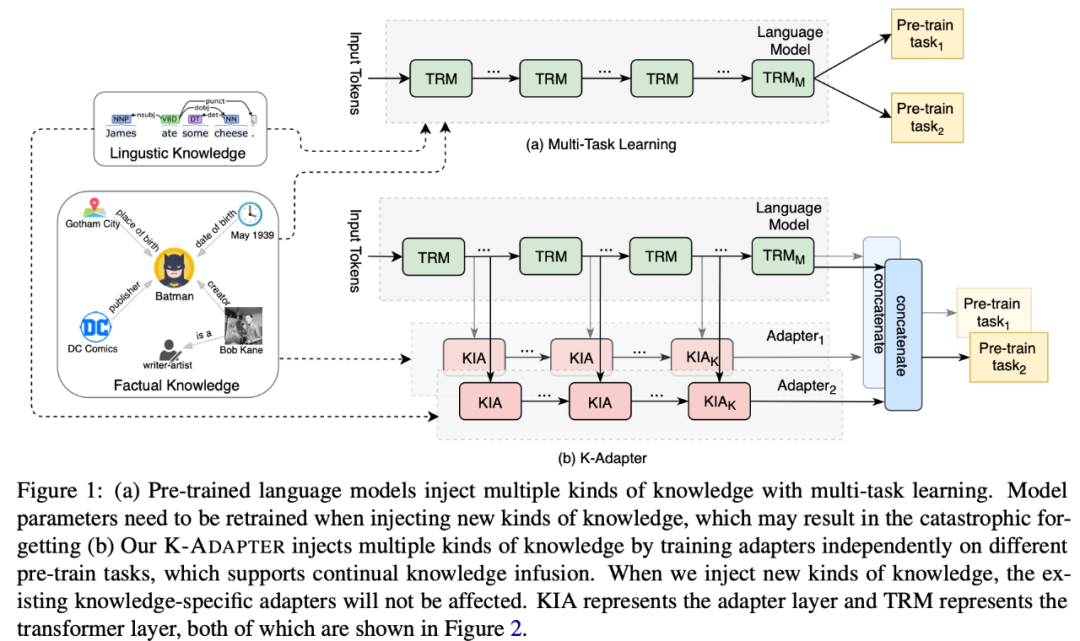
最近出現(xiàn)了一些向預(yù)訓(xùn)練模型中融入知識的工作,如ERNIE、WKLM、KnowBERT等。下表中展示了本文工作和先前融入知識工作的對比。先前的工作通過多任務(wù)(multi-task)學(xué)習(xí)的方式訓(xùn)練模型,也就是在原有的MLM訓(xùn)練目標(biāo)的基礎(chǔ)上,額外增加了用于融入知識的訓(xùn)練目標(biāo),例如ERINE通過增加Entity Linking的訓(xùn)練目標(biāo)學(xué)習(xí)相關(guān)知識。由于這些方法在預(yù)訓(xùn)練融入知識的階段BERT不是固定的,需要更新模型的全部參數(shù),會使得模型融入知識的代價(jià)較大。而且他們不支持連續(xù)學(xué)習(xí),模型的參數(shù)在引入新知識的時(shí)候需要重新訓(xùn)練;對于已經(jīng)學(xué)到的知識來說,會造成災(zāi)難性遺忘(catastrophic forgetting)的問題。為了更好地解決上述問題,本文提出了 K-Adapter,一種靈活、簡便地向預(yù)訓(xùn)練模型中注入知識的方法。
方法描述
本文提出的方法如下圖所示。圖a是基于多任務(wù)學(xué)習(xí)融入知識的方法,圖b是本文模型K-Adapter,通過外掛在原始模型外的adapter,融入不同種類的知識。
1. Adapter結(jié)構(gòu)
Adapter模型可以看做是知識特定模型,可以看做為插件,掛載在預(yù)訓(xùn)練模型外部。具體而言,每個(gè)Adapter模型由K個(gè)Adapter層(如下圖所示,KIA)組成,其中每個(gè)Adapter層包含了N個(gè)Transformer層和兩個(gè)映射層(Projection Layer)。對于Adapter模型,本文將Adapter層插入到預(yù)訓(xùn)練模型的不同Transformer層之間,將預(yù)訓(xùn)練模型的中間層輸出的特征和前一個(gè)Adapter層的輸出特征拼接作為Adapter層的輸入。本文將預(yù)訓(xùn)練模型和Adapter的最后一個(gè)隱藏特征拼接作為最終的輸出特征。
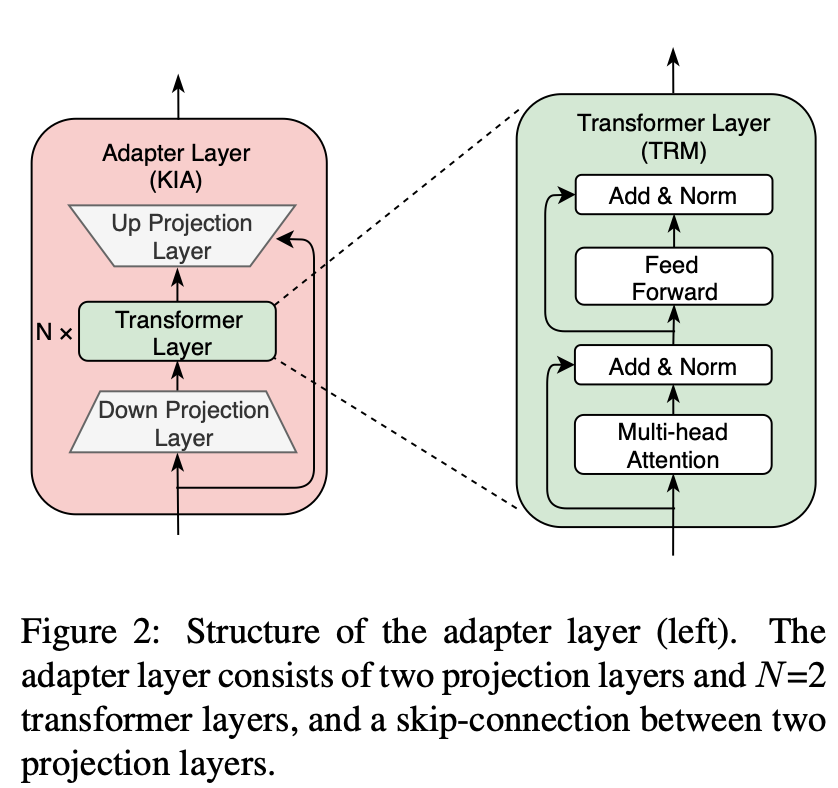
本文采用RoBERTa作為backbone。需要注意的是,RoBERTa在融入知識的預(yù)訓(xùn)練過程中是固定的,但Adapter的參數(shù)是可訓(xùn)練的。這樣的模型和訓(xùn)練設(shè)定,緩解了融入知識時(shí)災(zāi)難性遺忘的問題,不同知識的學(xué)習(xí)不受影響,融入知識效率更高;而且不同的Adapter間沒有信息流、可以利用分布式的方式同時(shí)、獨(dú)立地訓(xùn)練。
本文通過設(shè)置不同的預(yù)訓(xùn)練任務(wù)向Adapter中融入不同的知識。接下來介紹如何將不同種類的知識融入到特定的Adapter中。
2. 知識融入
下圖展示了向知識特定Adapter中融入知識的框圖。
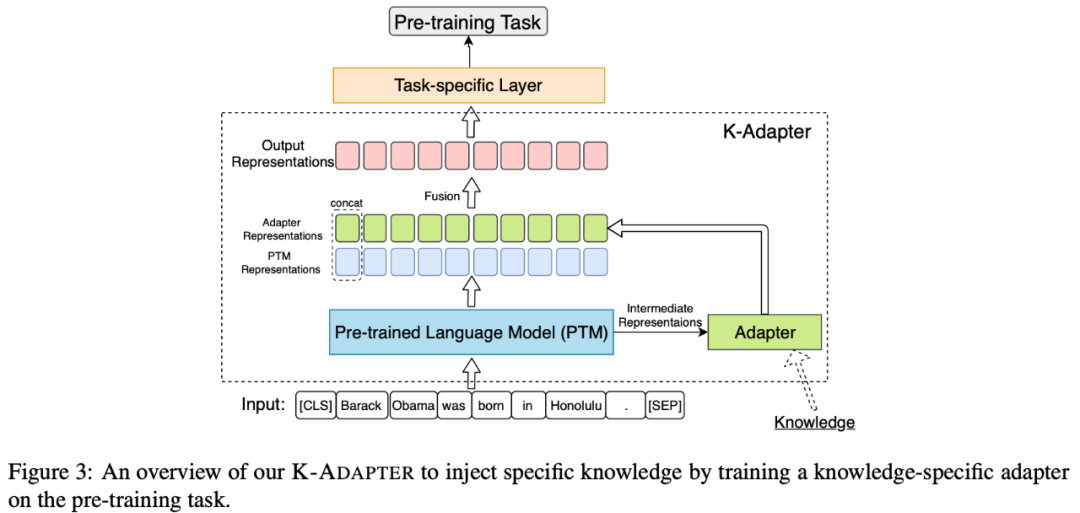
本文主要融入了2種知識——事實(shí)類知識和語言類知識,分別融入到了2種知識特定的adapter中:
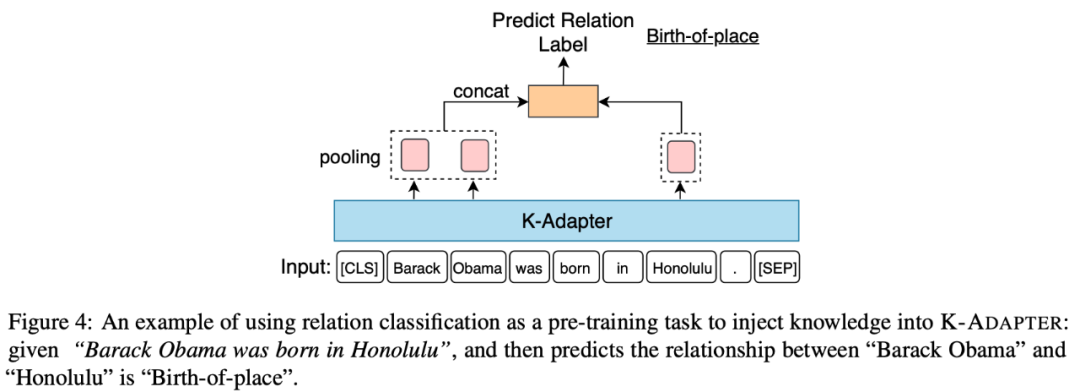
(1)Factual Adapter:Factual Adapter融入了事實(shí)類知識。此處的事實(shí)類知識指文本中實(shí)體之間的關(guān)系,來源于Wikipedia和Wikidata之間自動對齊的文本-三元組對。本文在關(guān)系分類任務(wù)上進(jìn)行預(yù)訓(xùn)練來融入知識,該任務(wù)要求給定1個(gè)句子和句子中的2個(gè)實(shí)體,然后要求模型預(yù)測出這兩個(gè)實(shí)體的關(guān)系。如下圖展示了融入事實(shí)類知識的示意圖。
(2)Linguistic Adapter:Linguistic Adapter融入了語言類知識。語言類的知識是自然語言中最基本的一類知識,比如說語義和語法信息。本文中的語言類知識指文本中詞之間的依存關(guān)系。本文在依存關(guān)系預(yù)測任務(wù)上進(jìn)行預(yù)訓(xùn)練來融入知識。這個(gè)任務(wù)要求模型預(yù)測出給定句子中,每個(gè)詞的father的index。
下圖展示了如何將Adapter應(yīng)用在下游任務(wù)中。此處關(guān)鍵的點(diǎn)是預(yù)訓(xùn)練模型特征+知識特征,即一方面利用預(yù)訓(xùn)練模型的通用信息,一方面利用Adapter中的特定知識。
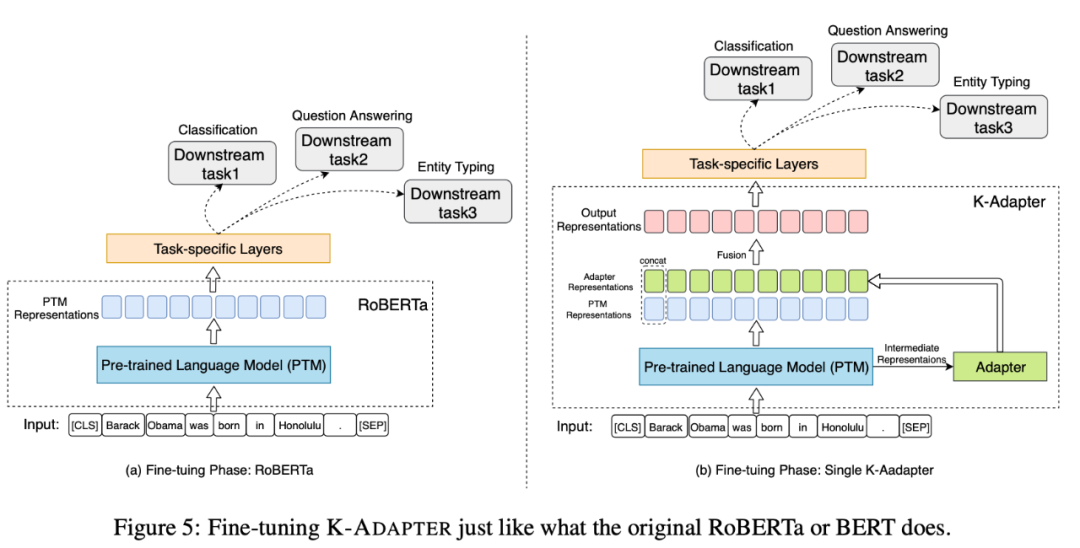
實(shí)驗(yàn)
本文在3種知識驅(qū)動的下游任務(wù)上進(jìn)行實(shí)驗(yàn),包含命名實(shí)體識別,問答和關(guān)系分類。此外,還通過案例分析和探究性實(shí)驗(yàn)對模型學(xué)習(xí)事實(shí)類知識的有效性進(jìn)行了分析。K-ADAPTER (F+L) 代表同時(shí)外掛事實(shí)類(factual) adapter和語言類(linguistic) adapter;K-ADAPTER (F) 代表外掛事實(shí)類(factual) adapter,K-ADAPTER (L) 代表外掛語言(linguistic) adapter。實(shí)驗(yàn)中RoBERTa均指RoBERTa-Large。
1. 命名實(shí)體識別(Entity Typing)
命名實(shí)體識別任務(wù)是給定一個(gè)文本和指定的實(shí)體,讓模型預(yù)測出指定實(shí)體的類別。在OpenEntity和FIGER數(shù)據(jù)集上的結(jié)果如下表所示。在OpenEntity數(shù)據(jù)集上,本文模型K-ADAPTER(F+L)相比于RoBERTa進(jìn)一步提高了1.38%的Mi-F1。在FIGER數(shù)據(jù)集上,與WKLM相比,K-ADAPTER (F+L)提高了2.88%的Ma-F1,提高了2.54%的Mi-F1。
2. 問答(Question Answering)
問答任務(wù)的目的是給定一個(gè)問題和一個(gè)文本,來讓模型做出回答,有時(shí)還會提供問題的上下文信息。在問答任務(wù)上的實(shí)驗(yàn)結(jié)果如下表所示。在CosmosQA上,與BERT-FTRACE+SWAG相比,本文的RoBERTa在準(zhǔn)確率上顯著提高了11.89%。與RoBERTa相比,K-ADAPTER(F+L)進(jìn)一步提高了1.24%的準(zhǔn)確率,這表明K-ADAPTER可以獲得更好的常識推理能力。在開放域的QA數(shù)據(jù)集(SearchQA和Quasar-T)上,與其他baseline相比,K-ADAPTER取得了更好的結(jié)果。這表明K-ADAPTER可以充分利用融入的知識,有利于根據(jù)檢索到的段落來回答問題。具體來說,在SearchQA上,K-ADAPTER(F+L)WKLM相比,顯著提高了4.01%的F1,甚至比WKLM+Ranking略高。值得注意的是,K-ADAPTER沒有建模檢索到的段落的置信度,而WKLM+Ranking額外利用了另一個(gè)基于BERT的ranker為檢索到的段落進(jìn)行打分、排序。
3. 關(guān)系分類(Relation Classification)
關(guān)系分類任務(wù)是指給定一個(gè)文本和文本中的兩個(gè)實(shí)體,要求模型預(yù)測出這兩個(gè)實(shí)體之間的關(guān)系。在關(guān)系分類任務(wù)上的實(shí)驗(yàn)結(jié)果如下表所示。結(jié)果表明,K-ADAPTER明顯優(yōu)于所有baseline。特別地,(1)K-ADAPTER模型優(yōu)于RoBERTa,證明了利用Adapter進(jìn)行知識融入的有效性;(2)與RoBERTa+multitask相比,K-ADAPTER取得了更大的提升,這直接說明了K-ADAPTER相比于多任務(wù)學(xué)習(xí)方式融入知識的效果更好,有助于模型充分利用知識。
4. 案例分析(Case Study)
下表中展示了在TACRED數(shù)據(jù)集上,K-ADAPTER和RoBERTa的定性比較。結(jié)果表明,K-ADAPTER中的事實(shí)知識可以幫助模型從預(yù)測“no_relation”轉(zhuǎn)換到預(yù)測正確的類別標(biāo)簽。
為了檢驗(yàn)?zāi)P蛯W(xué)習(xí)事實(shí)類知識的能力,本文在LAMA數(shù)據(jù)集上進(jìn)行了探究(Probing)實(shí)驗(yàn)。具體來說,該實(shí)驗(yàn)是在zero-shot的設(shè)定下進(jìn)行的,要求模型不在微調(diào)的情況下完成關(guān)于事實(shí)知識的完型填空,例如將“The native language of Mammootty is [MASK] ”作為輸入,讓模型預(yù)測出 [MASK]是什么。
總結(jié)
提出了一種靈活而簡單的方法K-Adapter,支持將知識注入到大規(guī)模預(yù)訓(xùn)練語言模型中。
K-Adapter保持原有預(yù)訓(xùn)練模型參數(shù)不變,使用不同的知識特定"插件"學(xué)習(xí)不同類別的知識,支持連續(xù)知識學(xué)習(xí),從而緩解“知識遺忘”問題,即融入新的知識不會影響原有的知識;且由于不同adapter間沒有信息流,所以adapter可以用分布式的方式進(jìn)行高效地訓(xùn)練。
在三種知識驅(qū)動的任務(wù)上取得了顯著的效果,包括了命名實(shí)體識別、關(guān)系分類、問答。詳細(xì)的分析進(jìn)一步證明K-Adapter可以學(xué)習(xí)到更為豐富的事實(shí)類知識,為如何有效地進(jìn)行知識融入提供了一些見解。
責(zé)任編輯:lq6
-
語言
+關(guān)注
關(guān)注
1文章
97瀏覽量
24388 -
模型
+關(guān)注
關(guān)注
1文章
3456瀏覽量
49755
原文標(biāo)題:通過外掛"插件"向預(yù)訓(xùn)練語言模型中融入知識
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
用PaddleNLP為GPT-2模型制作FineWeb二進(jìn)制預(yù)訓(xùn)練數(shù)據(jù)集

用PaddleNLP在4060單卡上實(shí)踐大模型預(yù)訓(xùn)練技術(shù)

【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗(yàn)】+大模型微調(diào)技術(shù)解讀
什么是大模型、大模型是怎么訓(xùn)練出來的及大模型作用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論