 介紹一種新穎的三元組對比學習訓練框架
介紹一種新穎的三元組對比學習訓練框架
摘要
在自然語言處理和知識圖譜領域的信息提取中,三元組抽取是必不可少的任務。在本文中,我們將重新審視用于序列生成的端到端三元組抽取任務。由于生成三元組抽取可能難以捕獲長期依賴關系并生成不忠實的三元組,因此我們引入了一種新的模型,即使用生成式Transformer的對比學習三元組抽取框架。
具體來說,我們介紹了一個共享的Transformer模塊,用于基于編碼器-解碼器的生成。為了產生忠實的結果,我們提出了一種新穎的三元組對比學習訓練框架。此外,我們引入了兩種機制來進一步改善模型的性能(即,分批動態注意掩碼和三元組校準)。在三個數據集(NYT,WebNLG和MIE)上的實驗結果表明,我們的方法比基線具有更好的性能。我們的代碼和數據集將在論文出版后發布。
論文動機
編碼器-解碼器模型是功能強大的工具,已在許多NLP任務中獲得成功,但是現有方法仍然存在兩個關鍵問題。首先,由于遞歸神經網絡(RNN)的固有缺陷,它們無法捕獲長期依賴關系,從而導致重要信息的丟失,否則將在句子中反映出來,從而導致模型無法應用更長的文本。第二,缺乏工作致力于生成忠實的三元組,序列到序列的體系結構會產生不忠實的序列,從而產生意義上的矛盾。例如,給定句子“美國總統特朗普在紐約市皇后區長大,并居住在那里直到13歲”,該模型可以生成事實“(特朗普出生于皇后區)”。盡管從邏輯上講是正確的,但我們無法從給定的句子中找到直接的證據來支持它。
為了解決這些問題,我們引入了帶有生成變壓器(CGT)的對比學習三元組提取框架,該框架是一個共享的Transformer模塊,支持編碼器-解碼器的生成式三元組對比學習多任務學習。首先,我們使用分隔符和部分因果掩碼機制將輸入序列與目標序列連接起來,以區分編碼器-解碼器表示形式。除了預先訓練的模型之外,我們的模型不需要任何其他參數。然后,我們介紹了一種新穎的三元組對比學習對象,該對象利用真實的三元組作為正實例,并利用隨機令牌采樣將損壞的三元組構造為負實例。為了共同優化三元組生成對象和對比學習對象,我們引入了分批動態注意掩碼機制,該機制允許我們動態選擇不同的對象并共同優化任務。最后,我們介紹了一種新穎的三元組校準算法,以在推理階段濾除虛假三元組。
這項工作的貢獻如下:
我們將三元組提取作為序列生成任務進行了重新介紹,并引入了一種新穎的CGT模型。考慮到增加的提取功能,CGT除了在預訓練語言模型中發現的參數外,不需要其他參數。
我們引入了兩種機制來進一步提高模型性能(即,批處理動態注意掩碼和三元組校準)。第一個可以聯合優化不同的對象,第二個可以確保忠實的推理。
我們在三個基準數據集上評估了CGT。 我們的模型優于其他強大的基準模型。我們還證明,在捕獲長期依存關系方面,CGT比現有的三元組抽取方法更好,因此,在使用長句子場景下依然可以獲得更好的性能。
模型框架
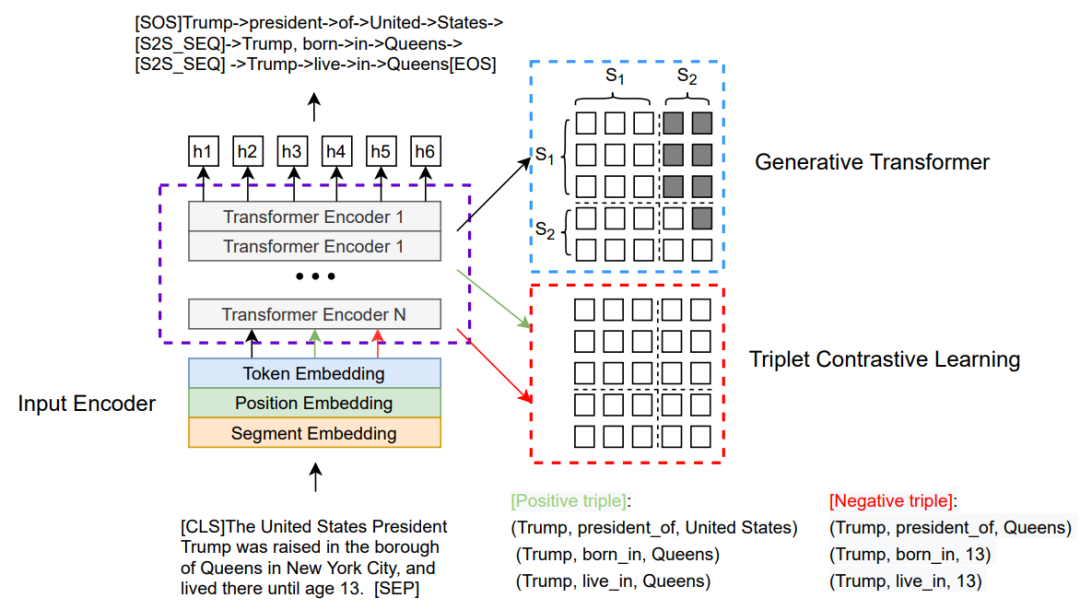
這里我們展示了CGT生成式Transformer的總體架構。右上部分表示Transformer生成模塊,右下部分表示三元組對比學習模塊。這兩個部分訓練時共同優化。生成模塊依靠部分因果掩碼機制建模成序列生成任務,如右圖中的示例所示,對于三元組序列生成,其中右上部分設置為-∞以阻止從源段到目標段的關注;左側部分設置為全0,表示令牌能夠參與第一段。利用交叉熵損失生成來優化三元組生成過程,獲得生成損失。對比學習模塊將輸入文本與正確的三元組實例或者偽造的三元組進行隨機拼接,依靠部分因果掩碼機制建模成文本分類任務,其中mask矩陣的元素全為0,利用經過MLP多層感知機層的特殊token[CLS]表示來計算分類打分函數,鑒別是否為正確實例,從而增強模型對關鍵token的感知能力。我們利用交叉熵優化對比損失。生成損失與對比學習損失通過一個超參數權衡構成了我們最終的總體損失。我們的解碼推理采用的是波束搜索和啟發式約束。
實驗結果
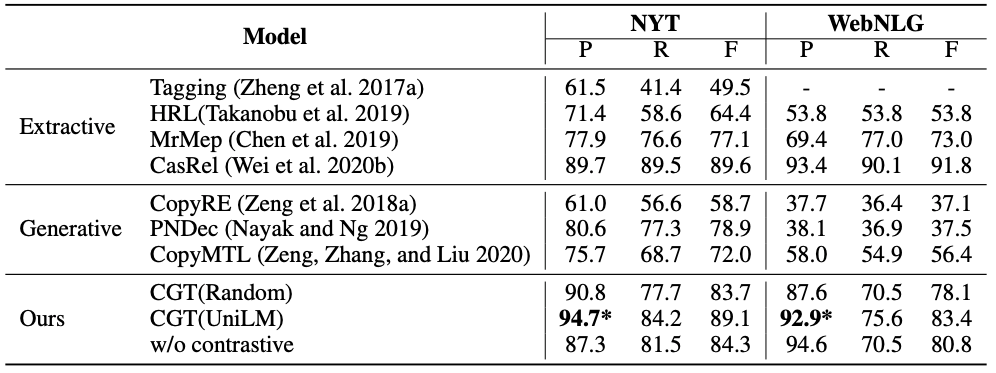
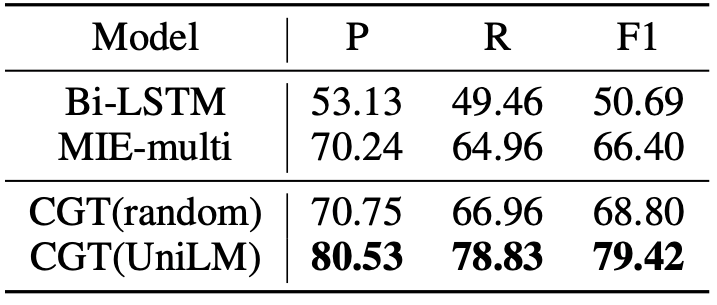
我們對三個基準數據集進行了實驗:紐約時報(NYT),WebNLG和MIE。MIE是醫學領域的大規模中文對話信息提取數據集。圖2中中顯示了這三個數據集的部分實驗統計信息。
責任編輯:lq6
-
編碼器
+關注
關注
45文章
3701瀏覽量
135690 -
自然語言處理
+關注
關注
1文章
623瀏覽量
13710
原文標題:AAAI2021-基于對比學習的三元組生成式抽取方法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于梯度下降算法的三元鋰電池循環壽命預測

三元鋰電生命循環究竟是多長?朗凱威鋰電電池定制 三元鋰電池組DIY
朗凱威三元鋰電池組 6020:高性能能源解決方案







 工商網監
工商網監
評論