 分享一種情感分析的解決方案
分享一種情感分析的解決方案
情感分析是比較復雜和高階的AI應用,在AI和人的交互過程中,能夠準確地把握人的情感狀態,從而極大地提升AI產品體驗,對質檢、對話交互、風控、輿論監督等都有著重要意義。本次技術分享要點
1、情感分析基礎知識與應用場景
2、情感分析落地應用中三個挑戰,如何利用多模態信息提升效果、如何利用領域遷移技術減少標注量以及如何利用細粒度情感分析為用戶提供更加實用的情感分析結果
3、追一科技情感分析解決方案
情感分析技術介紹
什么是情感分析
情感是人對客觀事物所持的態度。最簡單的情感可以分為積極(正向)、消極(負向)、中性,又稱為情緒。除了中性外,更多樣化的情感又可細分為:喜、怒、憂、悲、恐、驚等。這些情感不僅構成了人與人之間溝通交流的多樣性,也包含了豐富的信息,幫助我們了解目標對象在特定場景下的狀態以及對相關事務的態度。通過算法模型,結合具體場景和數據分析目標對象的情感狀態,這就是情感分析。 在人工智能(AI)產品和人的交互過程中,能夠準確地把握人的情感狀態可以極大地提升AI產品的體驗。這在質檢,對話交互,風控,輿論監督等方面都有著重要的意義。例如,在服務行業中,對客戶的服務滿意度分析可以幫助企業提高服務質量;而對于電商領域,分析用戶對某商品及其競品的喜好有助于商家找到提升產品競爭力的門道;在人機交互中掌握會話方的情感狀態可以幫助機器人適時地采用恰當話術表達安撫和諒解,提升交互體驗。在現實應用中有非常多的場景需要分析情感或者態度的信息,情感分析算法提供了提煉這些關鍵信息的途徑。 從不同的角度可以把情感分析方法做不同的歸納。按照對情感的劃分方式,可以分為:情感極性分析、情感類別分析和情感程度分析。按照對象粒度分,又有會話級情感分析、句子級情感分析,以及實體級情感分析等。具體分類因所處理的場景和問題而不同。
什么是多模態
我們平時接觸到的信息可以來源于文字、聲音、圖像、味覺、觸覺等。我們把每一個信息的來源域稱為一個模態。 之所以劃分出不同的模態,首先是因為不同場景下可以接觸到的信息不同,其次是不同模態提供的信息往往不同,而最重要的是對不同模態的信息需要采用的處理和建模方式也不同。簡單情況下,我們可以僅通過單一的模態就可以得到一個對情感態度的判斷,例如一段評價文字,一通對話錄音,一段評論視頻等。自然地,我們也可以結合多個模態的數據并將其統一建模,這就是多模態方法。 簡單來講,多模態方法的核心驅動就是:更多的信息來源可以幫助我們做出更優的決策。
多模態情感分析
對于情感分析來說,情感表達可以來源于文字、音頻、圖像,結合兩種及以上模態建模情感分析,就是多模態情感分析方法。由于不同模態的信息在數據形式和處理方式上有很大差別,在統一模型中多增加一種模態信息雖然可以帶來潛在的建模效果提升,但同時也增加了建模的復雜度和難度。例如,通過一句話的文字和對應的錄音建模時,需要先將字符串和音頻分別用兩種截然不同的處理方式量化為模型可接受的表征。 多模態模型策略在情感分析任務中是十分必要的。首先,很多時候僅通過文本或者語音很難準確判斷出情感狀態。一個極端例子是反諷。反諷往往結合中性或者積極的文本內容和與內容不匹配的音頻來完成消極(負向)的情感表達。而這僅靠單模態模型就很難判斷出真實的情感意圖。其次,單模態模型容易受噪聲影響而導致效果問題,例如上游語音識別(ASR)出現的識別錯誤往往會對下游分類任務產生較大影響。因此,要想在實際應用中有一個穩定強大的模型,多模態的建模方法就是必行之道。
情感分析的方法
情感本身是一種復雜的信息體現,在情感建模中使用不同的模態信息有著不同的處理方法及對應的挑戰,下面簡單介紹一下目前通用的一些建模方法及它們所存在的問題。
單模態方法簡介
單模態模型指的是通過單一信號進行情感分析的模型,例如僅基于文本內容或音頻信號來進行情感分析。
文本模型
得益于豐富的文本數據來源,文本模型是最常用的情感分析處理方法,通常的任務是對一句話的文本進行情感分類。從原理上大致可以分基于情感詞典的方法、以及基于深度學習的方法。基于感情詞典的方法此方法是基于跟情感分類相關的關鍵詞,結合目標場景預先建立一個情感關鍵詞的詞典,由關鍵詞的情感匯總判斷出句子的情感,是一種自下而上的方法。
實際應用中,基于情感詞典的方法往往和規則結合使用,從而實現更準確的判斷。但是維護情感詞典和規則本身是一項耗時耗力的工作,對詞典的調優也有著很大的困難。 而基于深度學習的方法則是當前較為流行的方法,它的好處在于它可以端到端地進行情感分析任務,而不需要像基于情感關鍵詞典的方法那樣建立詞典并使用規則。隨著深度學習技術在NLP應用中的不斷發展,許多不同的深度學習模型都能用來進行情感分析,例如CNN/RNN模型等。同時隨著大型預訓練模型的興起,預訓練+遷移學習的方式也被用于情感分析。關于預訓練模型,我們在系列文章的第一篇進行了詳細的介紹,這里就不再展開。
音頻模型
相對于離散的文本,音頻信號輸入為近似連續的數值,通常需要做預處理將音頻文件轉化為頻譜。具體步驟大致為:分幀-加窗-STFT-轉化梅爾頻譜,得到一個維度的特征,其中跟時間長度有關,為特征長度。音頻輸入由于其序列化的特點,通常也有基于CNN/RNN的方法,以及基于CRNN或CNN+Attention的方法。
多模態方法簡介
單模態情感分析方法主要的不足在于沒有利用完整的信息來進行情感分析。例如,如果僅僅基于文本來判斷情感,則丟失掉了說話人語氣與語調等與感情息息相關的信息。因此多模態方法的核心任務是最大化發揮模態融合的優勢完成建模。例如通過構建“語音+文本”的雙模態模型,以此得到一個效果優于同量級單模態模型的雙模態模型,達到1 + 1 》 2的效果,這其中的關鍵在于如何將不同模態融合到一起。 模態融合可以按照其發生的不同階段或者融合的具體方式進行大致的歸類。模態融合發生的不同階段可以直觀地理解為,“模態融合”這一步發生在模型中的哪個位置,它通常可以劃分為:
提前融合(Early Fusion):將不同模態的輸入在模型淺層完成融合,相當于將不同單模態的特征統一到同一個模型輸入參數空間,融合后的特征再輸入到單個模型中完成特征提取和預測。但是由于不同模態本身參數空間的差異性,在輸入層統一多個不同參數空間的方法并不能達到預期效果,實際往往很少被使用。
推遲融合(Late Fusion):推遲融合方法嘗試通過模型來解決參數空間不統一的問題。首先對不同模態的輸入數據分別用不同的網絡結構進行建模和特征提取,最終在分類層前將不同模態提取到的特征進行融合,并依賴梯度反向傳播將不同模態的特征統一到同一特征空間,最后在這個新的空間上做簡單的分類預測。推遲融合由于其簡單的實現方式和不錯的效果往往應用較普遍。
多階段融合(Muilti-Stage Fusion):推遲融合雖然通過網絡本身在分類層前將不同模態特征映射到同一參數空間 ,但僅僅是在高級特征層對不同的模態特征進行融合,也因此失去了在特征提取階段不同特征之間的相互關聯信息。多階段融合為了解決以上問題,在多個階段對特征進行融合操作。通常先通過簡單的的網絡結構將不同模態參數空間統一化,融合后的特征再繼續經過后續深度特征提取網絡進行進一步模態相關的深層特征提取并融合,不同模型結構分支提取到的特征在分類層之前做最終的融合后進行分類預測。多階段融合既保留了使用不同模型結構處理不同模態分支的能力,又自然地達到了不同模態信息融合的目的,對提取到強大特征更有優勢。這種方法的缺點是模型結構相對復雜,往往會設置多個損失函數,有時需要進行分階段調優。
除了按照模態融合的階段進行劃分,多模態方法還可以根據模態融合的具體方法進行劃分為:
基于拼接的特征融合:這種方式假設不同模態特征已經被統一在了同一參數空間上,并簡單地將不同模態的特征進行拼接來完成融合過程。該方法雖然簡單,但它并沒有考慮特征之間的相互作用增益,依賴下游分類網絡來融合模態信息。
基于注意力的特征融合:這種方法將不同模態的特征通過注意力模塊進行打分后融合,以達到充分利用模態間信息增益的目的。
情感分析實際應用挑戰
我們在前面簡單介紹了單/多模態情感分析中最常用的基本方法,而情感分析技術在落地使用中,也面臨著一些實際的挑戰。
首先面臨的是訓練速度、推理速度、模型大小等與模型性能相關的問題。前面的介紹中指出,采用多模態方法理論上可以更好地進行情感分析。但在實際落地使用中,如果采用多模態模型,則代表著模型需要對多個模態進行建模,因此模型的體量通常都比單模態模型要大,而性能也隨之變差。
其次是標注數據需求量的問題,這是深度學習方法普遍存在的問題。而情感分析也與多數的基于深度學習的NLP技術一樣,存在著跨領域的數據標注問題。具體來說,在某一特定場景(如保險客服)下訓練的模型往往不能直接用在其它場景(如運營商客服)。這是由于情感表達本身依賴于場景,在一個場景下的表達可能在另外一個場景下蘊含著不同的情感態度。同時,不同場景對情感態度判讀的界定也會有差別。除此以外,如果采用的是多模態方法,還需要對不同模態的數據都進行標注,并且需要在標注過程中綜合考慮各模態表達的信息。這類數據獲取的難度和標注成本也對多模態情感模型的實際應用有著影響。
最后是情感分析應用場景的問題。在一些場景中,用戶需要的不僅僅是“正向”、“負向”這種簡單的感情標簽,更希望知道感情投射的對象。例如針對句子“雖然服務態度還不錯,但我的問題還是沒有解決”,對客戶來說更加有價值的是給出不同對象的情感分析結果,例如“服務態度-正向;問題沒解決-負向”。
追一科技情感分析解決方案
我們將在這一部分介紹追一科技在解決上述問題的方法。
輕量級雙模態情感分析模型
為了解決模型的性能問題,我們在2020年提出了新的輕量級雙模態模型,該模型在IEMOCAP情感分類數據集上取得了【音頻+文本】雙模態模型的當前最優效果(SOTA),同時發表論文Efficient Speech Emotion Recognition Using Multi-Scale CNN and Attention, icassp 2021,并被世界人工智能語音領域頂會ICASSP(2021)錄用,這標志著追一科技多模態情感分析算法能力處于業內領先水平。
具體來說,我們提出基于多尺度卷積和統計池化相結合的方法來進行不同模態的特征抽取以及模態融合。
相對于其它雙模態情感模型,我們提出的模型沒有使用性能較低的RNN網絡及深層卷積網絡,也沒有利用大型的預訓練模型,而是用了簡單的單層多尺度卷積提取局部多樣性淺層特征,借助平均、最大、標準差池化得到綜合的全局統計特征,最終結合特征拼接和Attention機制融合語音和文本特征并作分類。此外,我們還引入了音頻說話人識別中常用的xvector特征做為輔助全局音頻特征。模型不僅在效果上趕超已有的最優模型,同時由于淺層CNN結構及高度并行化的模型設計,訓練/推理速度也更優。
在模態融合層面,為了保證模型的輕量性同時獲得好的模型效果,我們用了基于Attention的Late-Fusion方法,并結合圖像領域中常用的多尺度特征:
具體來說,音頻信號(MFCC)與文本信號(Word Embedding)分別經過各自的多尺度卷積(MSCNN)與統計池化(SPU)后,再利用Attention機制進行融合,最后輔以xvector進行感情類別的預測。值得指出的是,該方法相比與基于BERT等大型預訓練的方法在預測準確率上,有相當大的性能優勢。在我們的實際應用場景測試中,該方法比基于BERT的方法分別快5倍(CPU)/2倍(GPU)。
無監督域適應(Unsupervised Domain Adaption)
第二個需要解決的是標注數據量的問題。前文已經分析過,現有模型存在跨域困難的問題,同時由于標注成本高,在實際應用落地中難度較大。我們嘗試找到了一個將已訓練模型通過無監督域適應方法遷移到新領域上的方法,使得在新的業務領域上,已有的其它領域模型也能獲得不錯的初始表現。 域適應的核心思想是:在特征空間上某一度量準則下, 如果能夠使得源域與目標域特征分布盡可能接近,那么源域上已經訓練好的預測模塊可更好地直接用于目標域,從而達到模型跨域遷移的目的。
更進一步地,這個過程我們希望盡量地節約成本,最好是在不需要對新的目標領域數據進行標注的前提下完成。為了完成以上域適應和無監督的目的,我們需要解決以下兩個問題:
如何度量源域和目標域特征的相似程度
如何無監督地優化并構建目標域上的模型
針對第一個問題,簡單的解決方案是人為設定好度量的metric,例如我們可以用consine距離,L1、L2距離等。但這些畢竟是人為規定的,我們也無法確定哪一種度量最合適。換一種思路,利用神經網絡的學習能力,完全可以構建一個網絡并讓它去學習一個最合適的度量,而我們只需要站在高處對這個度量效果做出簡單的指點。這即是基于對抗學習的對抗遷移思想。而站在高處的指點,完全可以依據判段特征是來自源域還是目標域來實現。數學上相當于是實現了用Jensen-Shannon散度(用交叉熵損失)或者Wasserstein距離(用Wasserstein距離損失,又叫推土機距離)做為度量metric。
第二個問題,目標域上的模型構建和優化需要分階段進行,但是仍然統一在一個模型框架下,簡要的步驟為:
1.有監督訓練: 源數據 → 源模型 [Gs+ Fs] 2.對抗訓練(無監督): a)復制特征提取網絡, 構建判別器 [Gs → Gt, D] b)循環至穩定: i.訓練m輪D ii.訓練n輪Gs 3.得到目標模型: [Gt + Fs]為了測試這種無監督域適應的模型遷移效果,我們在多個領域數據上做了測試:
可以看到,在有標注數據的服務商領域上,我們的雙模態情感模型二分類效果可達94%的準確率。在三個其它場景中,不做無監督遷移的模型測試結果非常糟糕(遷移前),基本上接近于盲猜。而做了無監督遷移的模型(遷移后)效果較之前有了大幅度提升,這種提升完全是建立在不需標注數據的條件下實現的,在實際應用中有重要意義。
細粒度情感分析
單純的分類模型只能夠給出情感的判斷結果而不能給出情感的指向目標,例如:“這個電飯煲非常好用“,得到結果為積極(正向)。而細粒度情感分析則可以在更加精細的維度上給出情感分析的結果,如下圖所示:
從上面的例子可以看出,同一句話,在更細的粒度上的情感傾向是可能存在不同的,因此有時候直接給出一句話的整體情感分析結果并不能滿足實際使用的需要。為了使模型能夠輸出細粒度的情感分析結果,我們將此問題看作是一個序列標注問題,這也是細粒度情感分析任務的通常做法。
通常來說,在大型預訓練模型的輸出上額外增加序列標注的輸出模塊即可以完成序列標注任務。序列標注的輸出模塊形式較為靈活,例如采用線性層、RNN、Self Attention或者是CRF等,在這里不再對這些常規的方法做一一介紹。 值得一提的是,這個任務可以用我們提出的Global Pointer方法來解決,因此這里主要介紹如何用Global Pointer來進行序列標注。首先,序列標注的任務是需要識別出文本中的片段位置,并給出該片段的標簽。因此對于輸入長度為的文本,首尾組合一共有個候選的可能組合。如果該序列中有個需要定位的實體,那么該問題則變成了從個類別中選取個目標類的多標簽分類問題,可以按照常規的多標簽分類方式來解決。而Global Pointer則正是采用了這一簡單直觀的思路來解決序列標注的問題,這種方式的優勢在于在預測過程中,所有實體是一次給出的,并且可以識別出嵌套實體的情況,非常簡便快捷。而如果目標實體有種標簽,那么只需要進行次分類,即每種實體標簽用一個多標簽分類來建模。
依照上面的思路,對于長度為的序列,通過編碼器得到每個位置上的表征,令代表序列中第個位置到第個位置的片段的實體類型為的分數,則: 其中,。我們采用自研的多標簽分類損失作為最后的優化目標:
其中是該樣本的所有類型為的實體的首尾集合,是該樣本的所有非實體或者類型非的實體的首尾集合,注意我們只需要考慮的組合,即
另外需要指出的是,在進行分數計算的時候,由于需要考慮到q與k的位置關系,因此我們在這一步中加入了自研的旋轉位置編碼。旋轉位置編碼的加入可以大大提升Global Pointer的最終效果。 我們在不同的領域對細粒度情感分析方法進行了測試,效果如下:
可以看出細粒度情感分析可以明確給出客戶反饋中,針對不同對象的感情效果。
責任編輯:lq
-
AI
+關注
關注
87文章
30738瀏覽量
268896 -
情感分析
+關注
關注
0文章
14瀏覽量
5236
原文標題:讓AI捕捉“七情”,多模態情感分析的應用和挑戰
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種使用LDO簡單電源電路解決方案
SMT貼片故障分析與解決方案
基于LSTM神經網絡的情感分析方法
本文介紹了一種基于英飛凌碳化硅溝槽柵(CoolSiC?)的系統解決方案
自然語言處理是什么技術的一種應用
一文讀懂音頻解決方案專家

介紹一種嵌入式Linux中的錄音降噪方案
工業物聯網解決方案有什么用
瑞薩宣布推出一種全新超低25fs-rms時鐘解決方案—FemtoClock? 3
一種用于化學和生物材料識別的便攜式拉曼光譜解決方案
海思推出了一種面向音視頻行業的鴻鵠媒體解決方案
邊緣計算網關:一種高效安全的工業物聯網解決方案

介紹一種OpenAtom OpenHarmony輕量系統適配方案

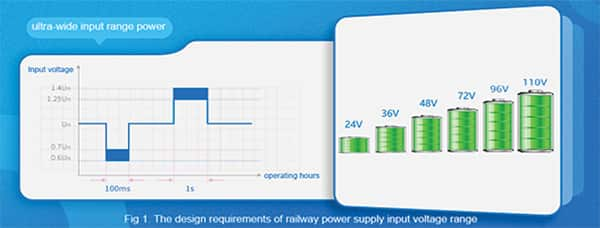
超寬輸入范圍鐵路電源解決方案之分析與比較
求一種FPC、CCS測試完整解決方案





 工商網監
工商網監
評論