 你們了解Word2vec嗎?讀者一篇就夠了
你們了解Word2vec嗎?讀者一篇就夠了
嵌入(embedding)是機器學習中最迷人的想法之一。如果你曾經使用Siri、Google Assistant、Alexa、Google翻譯,甚至智能手機鍵盤進行下一詞預測,那么你很有可能從這個已經成為自然語言處理模型核心的想法中受益。
在過去的幾十年中,嵌入技術用于神經網絡模型已有相當大的發展。尤其是最近,其發展包括導致BERT和GPT2等尖端模型的語境化嵌入。
BERT:
https://jalammar.github.io/illustrated-bert/
Word2vec是一種有效創建詞嵌入的方法,它自2013年以來就一直存在。但除了作為詞嵌入的方法之外,它的一些概念已經被證明可以有效地創建推薦引擎和理解時序數據。在商業的、非語言的任務中。像Airbnb、阿里巴巴、Spotify這樣的公司都從NLP領域中提取靈感并用于產品中,從而為新型推薦引擎提供支持。
在這篇文章中,我們將討論嵌入的概念,以及使用word2vec生成嵌入的機制。讓我們從一個例子開始,熟悉使用向量來表示事物。你是否知道你的個性可以僅被五個數字的列表(向量)表示?
個性嵌入:你是什么樣的人?
如何用0到100的范圍來表示你是多么內向/外向(其中0是最內向的,100是最外向的)?你有沒有做過像MBTI那樣的人格測試,或者五大人格特質測試?如果你還沒有,這些測試會問你一系列的問題,然后在很多維度給你打分,內向/外向就是其中之一。
五大人格特質測試測試結果示例。它可以真正告訴你很多關于你自己的事情,并且在學術、人格和職業成功方面都具有預測能力。此處可以找到測試結果。
假設我的內向/外向得分為38/100。
讓我們把范圍收縮到-1到1:
當你只知道這一條信息的時候,你覺得你有多了解這個人?了解不多。人很復雜,讓我們添加另一測試的得分作為新維度。
我們可以將兩個維度表示為圖形上的一個點,或者作為從原點到該點的向量。我們擁有很棒的工具來處理即將上場的向量們。
我已經隱藏了我們正在繪制的人格特征,這樣你會漸漸習慣于在不知道每個維度代表什么的情況下,從一個人格的向量表示中獲得價值信息。
我們現在可以說這個向量部分地代表了我的人格。當你想要將另外兩個人與我進行比較時,這種表示法就有用了。假設我被公共汽車撞了,我需要被性格相似的人替換。
處理向量時,計算相似度得分的常用方法是余弦相似度:
1號替身在性格上與我更相似。指向相同方向的向量(長度也起作用)具有更高的余弦相似度。
再一次,兩個維度還不足以捕獲有關不同人群的足夠信息。心理學已經研究出了五個主要人格特征(以及大量的子特征),所以讓我們使用所有五個維度進行比較:
使用五個維度的問題是我們不能在二維平面繪制整齊小箭頭了。這是機器學習中的常見問題,我們經常需要在更高維度的空間中思考。但好在余弦相似度仍然有效,它適用于任意維度:
余弦相似度適用于任意數量的維度。這些得分比上次的得分要更好,因為它們是根據被比較事物的更高維度算出的。
在本節的最后,我希望提出兩個中心思想:
1.我們可以將人和事物表示為代數向量(這對機器來說很棒!)。
2.我們可以很容易地計算出相似的向量之間的相互關系。
詞嵌入
通過上文的理解,我們繼續看看訓練好的詞向量實例(也被稱為詞嵌入)并探索它們的一些有趣屬性。
這是一個單詞“king”的詞嵌入(在維基百科上訓練的GloVe向量):
[ 0.50451 , 0.68607 , -0.59517 , -0.022801, 0.60046 , -0.13498 , -0.08813 , 0.47377 , -0.61798 , -0.31012 , -0.076666, 1.493 , -0.034189, -0.98173 , 0.68229 , 0.81722 , -0.51874 , -0.31503 , -0.55809 , 0.66421 , 0.1961 , -0.13495 , -0.11476 , -0.30344 , 0.41177 , -2.223 , -1.0756 , -1.0783 , -0.34354 , 0.33505 , 1.9927 , -0.04234 , -0.64319 , 0.71125 , 0.49159 , 0.16754 , 0.34344 , -0.25663 , -0.8523 , 0.1661 , 0.40102 , 1.1685 , -1.0137 , -0.21585 , -0.15155 , 0.78321 , -0.91241 , -1.6106 , -0.64426 , -0.51042 ]
這是一個包含50個數字的列表。通過觀察數值我們看不出什么,但是讓我們稍微給它可視化,以便比較其它詞向量。我們把所有這些數字放在一行:
讓我們根據它們的值對單元格進行顏色編碼(如果它們接近2則為紅色,接近0則為白色,接近-2則為藍色):
我們將忽略數字并僅查看顏色以指示單元格的值。現在讓我們將“king”與其它單詞進行比較:
看看“Man”和“Woman”彼此之間是如何比它們任一一個單詞與“King”相比更相似的?這暗示你一些事情。這些向量圖示很好的展現了這些單詞的信息/含義/關聯。
這是另一個示例列表(通過垂直掃描列來查找具有相似顏色的列):
有幾個要點需要指出:
1.所有這些不同的單詞都有一條直的紅色列。它們在這個維度上是相似的(雖然我們不知道每個維度是什么)
2.你可以看到“woman”和“girl”在很多地方是相似的,“man”和“boy”也是一樣
3.“boy”和“girl”也有彼此相似的地方,但這些地方卻與“woman”或“man”不同。這些是否可以總結出一個模糊的“youth”概念?可能吧。
4.除了最后一個單詞,所有單詞都是代表人。我添加了一個對象“water”來顯示類別之間的差異。你可以看到藍色列一直向下并在 “water”的詞嵌入之前停下了。
5.“king”和“queen”彼此之間相似,但它們與其它單詞都不同。這些是否可以總結出一個模糊的“royalty”概念?
類比
展現嵌入奇妙屬性的著名例子是類比。我們可以添加、減去詞嵌入并得到有趣的結果。一個著名例子是公式:“king”-“man”+“woman”:
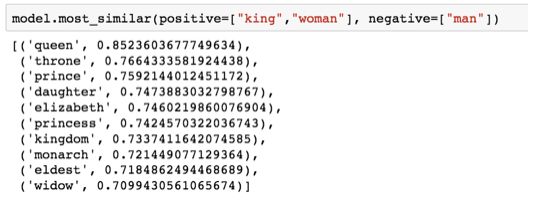
在python中使用Gensim庫,我們可以添加和減去詞向量,它會找到與結果向量最相似的單詞。該圖像顯示了最相似的單詞列表,每個單詞都具有余弦相似性。
我們可以像之前一樣可視化這個類比:
由“king-man + woman”生成的向量并不完全等同于“queen”,但“queen”是我們在此集合中包含的400,000個字嵌入中最接近它的單詞。
現在我們已經看過訓練好的詞嵌入,接下來讓我們更多地了解訓練過程。但在我們開始使用word2vec之前,我們需要看一下詞嵌入的父概念:神經語言模型。
語言模型
如果要舉自然語言處理最典型的例子,那應該就是智能手機輸入法中的下一單詞預測功能。這是個被數十億人每天使用上百次的功能。
下一單詞預測是一個可以通過語言模型實現的任務。語言模型會通過單詞列表(比如說兩個詞)去嘗試預測可能緊隨其后的單詞。
在上面這個手機截屏中,我們可以認為該模型接收到兩個綠色單詞(thou shalt)并推薦了一組單詞(“not” 就是其中最有可能被選用的一個):
我們可以把這個模型想象為這個黑盒:
但事實上,該模型不會只輸出一個單詞。實際上,它對所有它知道的單詞(模型的詞庫,可能有幾千到幾百萬個單詞)的按可能性打分,輸入法程序會選出其中分數最高的推薦給用戶。
自然語言模型的輸出就是模型所知單詞的概率評分,我們通常把概率按百分比表示,但是實際上,40%這樣的分數在輸出向量組是表示為0.4
自然語言模型(請參考Bengio 2003)在完成訓練后,會按如下中所示法人三步完成預測:
第一步與我們最相關,因為我們討論的就是Embedding。模型在經過訓練之后會生成一個映射單詞表所有單詞的矩陣。在進行預測的時候,我們的算法就是在這個映射矩陣中查詢輸入的單詞,然后計算出預測值:
現在讓我們將重點放到模型訓練上,來學習一下如何構建這個映射矩陣。
語言模型訓練
相較于大多數其他機器學習模型,語言模型有一個很大有優勢,那就是我們有豐富的文本來訓練語言模型。所有我們的書籍、文章、維基百科、及各種類型的文本內容都可用。相比之下,許多其他機器學習的模型開發就需要手工設計數據或者專門采集數據。
我們通過找常出現在每個單詞附近的詞,就能獲得它們的映射關系。機制如下:
1.先是獲取大量文本數據(例如所有維基百科內容)
2. 然后我們建立一個可以沿文本滑動的窗(例如一個窗里包含三個單詞)
3. 利用這樣的滑動窗就能為訓練模型生成大量樣本數據。
當這個窗口沿著文本滑動時,我們就能(真實地)生成一套用于模型訓練的數據集。為了明確理解這個過程,我們看下滑動窗是如何處理這個短語的:
在一開始的時候,窗口鎖定在句子的前三個單詞上:
我們把前兩個單詞單做特征,第三個單詞單做標簽:
這時我們就生產了數據集中的第一個樣本,它會被用在我們后續的語言模型訓練中。
接著,我們將窗口滑動到下一個位置并生產第二個樣本:
這時第二個樣本也生成了。
不用多久,我們就能得到一個較大的數據集,從數據集中我們能看到在不同的單詞組后面會出現的單詞:
在實際應用中,模型往往在我們滑動窗口時就被訓練的。但是我覺得將生成數據集和訓練模型分為兩個階段會顯得更清晰易懂一些。除了使用神經網絡建模之外,大家還常用一項名為N-gams的技術進行模型訓練。
如果想了解現實產品從使用N-gams模型到使用神經模型的轉變,可以看一下Swiftkey (我最喜歡的安卓輸入法)在2015年的發表一篇博客,文中介紹了他們的自然語言模型及該模型與早期N-gams模型的對比。我很喜這個例子,因為這個它能告訴你如何在營銷宣講中把Embedding的算法屬性解釋清楚。
顧及兩頭
根據前面的信息進行填空:
在空白前面,我提供的背景是五個單詞(如果事先提及到‘bus’),可以肯定,大多數人都會把bus填入空白中。但是如果我再給你一條信息——比如空白后的一個單詞,那答案會有變嗎?
這下空白處改填的內容完全變了。這時’red’這個詞最有可能適合這個位置。從這個例子中我們能學到,一個單詞的前后詞語都帶信息價值。事實證明,我們需要考慮兩個方向的單詞(目標單詞的左側單詞與右側單詞)。那我們該如何調整訓練方式以滿足這個要求呢,繼續往下看。
Skipgram模型
我們不僅要考慮目標單詞的前兩個單詞,還要考慮其后兩個單詞。
如果這么做,我們實際上構建并訓練的模型就如下所示:
上述的這種架構被稱為連續詞袋(CBOW),在一篇關于word2vec的論文中有闡述。
還有另一種架構,它不根據前后文(前后單詞)來猜測目標單詞,而是推測當前單詞可能的前后單詞。我們設想一下滑動窗在訓練數據時如下圖所示:
這里粉框顏色深度呈現不同,是因為滑動窗給訓練集產生了4個獨立的樣本:
這種方式稱為Skipgram架構。我們可以像下圖這樣將展示滑動窗的內容。
這樣就為數據集提供了4個樣本:
然后我們移動滑動窗到下一個位置:
這樣我們又產生了接下來4個樣本:
在移動幾組位置之后,我們就能得到一批樣本:
重新審視訓練過程
現在我們已經從現有的文本中獲得了Skipgram模型的訓練數據集,接下來讓我們看看如何使用它來訓練一個能預測相鄰詞匯的自然語言模型。
從數據集中的第一個樣本開始。我們將特征輸入到未經訓練的模型,讓它預測一個可能的相鄰單詞。
該模型會執行三個步驟并輸入預測向量(對應于單詞表中每個單詞的概率)。因為模型未經訓練,該階段的預測肯定是錯誤的。但是沒關系,我們知道應該猜出的是哪個單詞——這個詞就是我訓練集數據中的輸出標簽:
目標單詞概率為1,其他所有單詞概率為0,這樣數值組成的向量就是“目標向量”。
模型的偏差有多少?將兩個向量相減,就能得到偏差向量:
現在這一誤差向量可以被用于更新模型了,所以在下一輪預測中,如果用not作為輸入,我們更有可能得到thou作為輸出了。
這其實就是訓練的第一步了。我們接下來繼續對數據集內下一份樣本進行同樣的操作,直到我們遍歷所有的樣本。這就是一輪(epoch)了。我們再多做幾輪(epoch),得到訓練過的模型,于是就可以從中提取嵌入矩陣來用于其他應用了。
以上確實有助于我們理解整個流程,但這依然不是word2vec真正訓練的方法。我們錯過了一些關鍵的想法。
負例采樣
回想一下這個神經語言模型計算預測值的三個步驟:
從計算的角度來看,第三步非常昂貴 - 尤其是當我們將需要在數據集中為每個訓練樣本都做一遍(很容易就多達數千萬次)。我們需要尋找一些提高表現的方法。
一種方法是將目標分為兩個步驟:
1.生成高質量的詞嵌入(不要擔心下一個單詞預測)。
2.使用這些高質量的嵌入來訓練語言模型(進行下一個單詞預測)。
在本文中我們將專注于第1步(因為這篇文章專注于嵌入)。要使用高性能模型生成高質量嵌入,我們可以改變一下預測相鄰單詞這一任務:
將其切換到一個提取輸入與輸出單詞的模型,并輸出一個表明它們是否是鄰居的分數(0表示“不是鄰居”,1表示“鄰居”)。
這個簡單的變換將我們需要的模型從神經網絡改為邏輯回歸模型——因此它變得更簡單,計算速度更快。
這個開關要求我們切換數據集的結構——標簽值現在是一個值為0或1的新列。它們將全部為1,因為我們添加的所有單詞都是鄰居。
現在的計算速度可謂是神速啦——在幾分鐘內就能處理數百萬個例子。但是我們還需要解決一個漏洞。如果所有的例子都是鄰居(目標:1),我們這個”天才模型“可能會被訓練得永遠返回1——準確性是百分百了,但它什么東西都學不到,只會產生垃圾嵌入結果。
為了解決這個問題,我們需要在數據集中引入負樣本 - 不是鄰居的單詞樣本。我們的模型需要為這些樣本返回0。模型必須努力解決這個挑戰——而且依然必須保持高速。
但是我們作為輸出詞填寫什么呢?我們從詞匯表中隨機抽取單詞
這個想法的靈感來自噪聲對比估計。我們將實際信號(相鄰單詞的正例)與噪聲(隨機選擇的不是鄰居的單詞)進行對比。這導致了計算和統計效率的巨大折衷。
噪聲對比估計
http://proceedings.mlr.press/v9/gutmann10a/gutmann10a.pdf
基于負例采樣的Skipgram(SGNS)
我們現在已經介紹了word2vec中的兩個(一對)核心思想:負例采樣,以及skipgram。
Word2vec訓練流程
現在我們已經了解了skipgram和負例采樣的兩個中心思想,可以繼續仔細研究實際的word2vec訓練過程了。
在訓練過程開始之前,我們預先處理我們正在訓練模型的文本。在這一步中,我們確定一下詞典的大小(我們稱之為vocab_size,比如說10,000)以及哪些詞被它包含在內。
在訓練階段的開始,我們創建兩個矩陣——Embedding矩陣和Context矩陣。這兩個矩陣在我們的詞匯表中嵌入了每個單詞(所以vocab_size是他們的維度之一)。第二個維度是我們希望每次嵌入的長度(embedding_size——300是一個常見值,但我們在前文也看過50的例子)。
在訓練過程開始時,我們用隨機值初始化這些矩陣。然后我們開始訓練過程。在每個訓練步驟中,我們采取一個相鄰的例子及其相關的非相鄰例子。我們來看看我們的第一組:
現在我們有四個單詞:輸入單詞not和輸出/上下文單詞: thou(實際鄰居詞),aaron和taco(負面例子)。我們繼續查找它們的嵌入——對于輸入詞,我們查看Embedding矩陣。對于上下文單詞,我們查看Context矩陣(即使兩個矩陣都在我們的詞匯表中嵌入了每個單詞)。
然后,我們計算輸入嵌入與每個上下文嵌入的點積。在每種情況下,結果都將是表示輸入和上下文嵌入的相似性的數字。
現在我們需要一種方法將這些分數轉化為看起來像概率的東西——我們需要它們都是正值,并且 處于0到1之間。sigmoid這一邏輯函數轉換正適合用來做這樣的事情啦。
現在我們可以將sigmoid操作的輸出視為這些示例的模型輸出。您可以看到taco得分最高,aaron最低,無論是sigmoid操作之前還是之后。
既然未經訓練的模型已做出預測,而且我們確實擁有真實目標標簽來作對比,那么讓我們計算模型預測中的誤差吧。為此我們只需從目標標簽中減去sigmoid分數。
這是“機器學習”的“學習”部分。現在,我們可以利用這個錯誤分數來調整not、thou、aaron和taco的嵌入,使我們下一次做出這一計算時,結果會更接近目標分數。
訓練步驟到此結束。我們從中得到了這一步所使用詞語更好一些的嵌入(not,thou,aaron和taco)。我們現在進行下一步(下一個相鄰樣本及其相關的非相鄰樣本),并再次執行相同的過程。
當我們循環遍歷整個數據集多次時,嵌入會繼續得到改進。然后我們就可以停止訓練過程,丟棄Context矩陣,并使用Embeddings矩陣作為下一項任務的已被訓練好的嵌入。
窗口大小和負樣本數量
word2vec訓練過程中的兩個關鍵超參數是窗口大小和負樣本的數量。
不同的任務適合不同的窗口大小。一種啟發式方法是,使用較小的窗口大小(2-15)會得到這樣的嵌入:兩個嵌入之間的高相似性得分表明這些單詞是可互換的(注意,如果我們只查看附近距離很近的單詞,反義詞通常可以互換——例如,好的和壞的經常出現在類似的語境中)。使用較大的窗口大小(15-50,甚至更多)會得到相似性更能指示單詞相關性的嵌入。在實際操作中,你通常需要對嵌入過程提供指導以幫助讀者得到相似的”語感“。Gensim默認窗口大小為5(除了輸入字本身以外還包括輸入字之前與之后的兩個字)。
負樣本的數量是訓練訓練過程的另一個因素。原始論文認為5-20個負樣本是比較理想的數量。它還指出,當你擁有足夠大的數據集時,2-5個似乎就已經足夠了。Gensim默認為5個負樣本。
結論
我希望您現在對詞嵌入和word2vec算法有所了解。我也希望現在當你讀到一篇提到“帶有負例采樣的skipgram”(SGNS)的論文(如頂部的推薦系統論文)時,你已經對這些概念有了更好的認識。
編輯:jq
-
機器學習
+關注
關注
66文章
8414瀏覽量
132606 -
數據集
+關注
關注
4文章
1208瀏覽量
24695
原文標題:圖解Word2vec,讀這一篇就夠了!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
UVLED光固化機常用術語和單位簡介,一篇文章帶你全面了解!

《DNESP32S3使用指南-IDF版_V1.6》第一章 本書學習方法

在WORD里面插入波形圖中遇到的問題麻煩大佬幫忙看一下
《DNK210使用指南 -CanMV版 V1.0》第一章本書學習方法
一文了解電商大促系統的高可用保障思路-獻給技術伙伴們

一篇文章帶你了解Chenlink UV光固膠的主要應用領域
【《大語言模型應用指南》閱讀體驗】+ 基礎篇
【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
名單公布!【書籍評測活動NO.38】OpenHarmony開發與實踐 | 基于紅莓RK2206開發板
nlp自然語言處理模型有哪些
iPad版微軟Word新增頁面邊框功能,提升文檔美觀度
網頁版Word添加復選框功能,實現任務跟蹤與習慣養成
利用電氣化和自動化構建更高效、更可持續的電網 - 第 1 篇(共 2 篇)





 工商網監
工商網監
評論