 基于APP650網絡處理器加速RNC WCDMA用戶平面的解決方案
基于APP650網絡處理器加速RNC WCDMA用戶平面的解決方案
隨著高速分組接入(HSPA)峰值數據速率不斷提高,目前主要依靠各種通用處理器(CPU)進行用戶平面處理工作的無線電網絡控制器(RNC)平臺已無法滿足日益增加的通信有效負載要求。因此,RNC需要通過新的方法來處理PDCP、無線鏈路控制(RLC)、MAC以及FP等用戶平面無線協議。由于對峰值數據速率要求的提高,以及HSPA用戶數量和與WCDMA網絡相關流量的增加,RNC需要更快速的HSPA。
本文將介紹如何通過LSIAPP650 Advanced Payload Plus網絡處理器來加快當前的HSPA用戶平面設計,不管目前的用戶平面運行于何種硬件上。通過讓APP650接管RLC分段/級聯以及重組等用戶平面處理工作,RNC可針對小型RLC服務數據單元(SDU)提供100Mb/s以上的用戶峰值數據速率,并且可使3萬名用戶的總吞吐量達到700Mb/s以上。通過使用APP650分擔部分處理工作的方法以及高度靈活的RLC(3GPP7版本以上),使每用戶的峰值速率吞吐量能達到200Mb/s以上。
蜂窩系統的一個重要要求就是為分組數據業務提供高數據速度。為滿足這一要求,3GPP/WCDMA標準R5版和R6版均提出了HSPA標準。盡管3GPP/WCDMA標準R1版就支持分組數據通信,但HSPA進一步增強了性能,可提供更高階調制、快速的調度以及速率控制等,從而支持更高的每用戶峰值數據速率。隨著HSPA的不斷發展,峰值數據速率也將不斷提高。預計3GPP7版本以上的每用戶峰值數據速率將提升至200Mb/s以上。
在采用HSPA技術的3G網絡中,RNC通常控制數百個基站。RNC負責其控制下各蜂窩系統的呼叫設置和無線電資源管理。WCDMA用戶平面協議層包括PDCP、RLC、MAC以及FP等,都是在下行方向上的RNC中啟動,和在上行方向上的RNC中終止。
RLC協議層是唯一終止于3G網絡用戶設備(移動設備)中的RNC用戶平面層。所有其它層均只位于RNC與基站之間。
現有RNC平臺通常使用多個通用CPU來處理WCDMA用戶平面協議棧。隨著HSPA的發展以及蜂窩數據速率的提高,現有RNC架構已無法滿足WCDMA網絡日益提高的通信有效負載要求。
根據摩爾定律,CPU的性能每18個月應提高1倍。根據幾份市場研究報告顯示,預計對RNC用戶平面處理容量的網絡需求每12個月將提高約3倍,當前的RNC用戶平面處理技術顯然無力應付不斷發展的需求(圖1)。LSI針對這一問題提供了短期和長期解決方案。

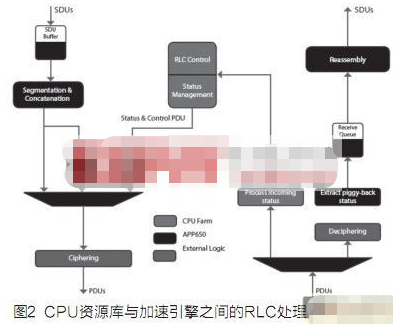
本文建議采用的解決方案是將CPU從RLC分段/級聯工作中釋放出來,從而顯著降低當前CPU的工作負載。此前曾將CPU從分段工作中釋放出來用于其它協議(如TCP)中,以縮短服務器平臺中的CPU周期。本文將介紹類似理念的應用,以加速WCDMA用戶平面處理(尤其是RLC協議)。LSIAPP650處理器將CPU從分段/級聯以及重組工作中釋放出來,支持高達3萬用戶的RLC連接。圖2為幾個CPU采用單一APP650處理器作為加速引擎的情況。
相對于通常受限于單核或單線程性能的非加速方案而言,這種加速方案具有明顯的優勢。以前,提高HSPA峰值數據速率和增加用戶(使用典型的CPU和操作系統模型,用CPU進行用戶平面處理的用戶)數量要求單用戶處理軟件在多個處理器上并行或管道化操作。這種軟件工作方式不僅極其復雜、成本高昂,而且容易出錯。與此不同的是,我們可利用LSIAPP650處理器來負責一些CPU工作強度最高的處理任務,從而節約50%乃至更多的CPU處理資源。而且在采用同一硬件時,高峰值數據速率與總體吞吐量將提高一倍以上。
APP650在用戶平面處理方面的優勢
APP650網絡處理器由幾個處理單元組成,其中包括模式處理器、流量管理和狀態引擎等。
模式處理器主要負責數據包分類,其采用管線化、多線程的多處理器架構。模式處理器的每管線級能在每個時鐘周期的不同上下文/線程下工作,這不同于管線中的所有指令必須屬于單個上下文且只有上下文暫停(高速緩存缺失、存儲器訪問、分支預測錯誤等)時才打開管線中上下文執行的傳統通用架構。在傳統的單線程架構中,讓執行管線保持繁忙比較困難,因為管線中的所有指令都屬于單線程。在APP650架構中,如果上下文執行的函數調用時延較高,那么該函數調用在管線中的位置會被分配給其他上下文。因此,APP650多線程架構能支持零周期上下文切換功能,這在單線程的多核架構中是不能實現的。模式處理引擎可提供144個不同的上下文,能全面利用硬件資源,并避免存儲器出現時延。
與此形成對比的是,CPU的存儲器瓶頸會導致我們難以充分利用資源,而且會浪費CPU的工作周期。APP650網絡處理器會為即將到達的數據包分配一個上下文,這樣許多數據包能同時處理。由于我們能同時處理許多數據包,這樣就能充分利用CPU資源,而且還能實現高達5.9Gb/s的數據速率。
在APP650架構中,機制與策略是彼此獨立的。硬件負責提供機制,而軟件負責提供策略。APP650架構是在硬件中執行存儲器管理與數據移動,因此在牽涉到存儲器的分配與釋放、數據包指針的跟蹤或者數據復制到不同存儲器地址等方面時間,不會出現軟件消耗資源的問題。APP650硬件就每個數據包調用軟件來提供決策,避免了因中斷處理或輪詢而浪費CPU資源。APP650網絡處理器還包括了預排序修改(PQM)引擎,其不僅能在數據包的不同部分中插入或刪除數據,而且還可將數據包分段為許多子數據包。PQM引擎的上述特性可顯著加速RLC分段/排序進程。另外,APP650網絡處理器還有一個重要特性,就是硬件輔助多字段數據包分類。數據包分類可能占用很多CPU資源,但在APP650網絡處理器上數據包分類非常高效。
APP650狀態引擎提供了跟蹤數據包相關狀態的機制。在RLC處理中,我們用該引擎跟蹤RLC連接狀態。舉例來說,與每個RLC連接相關的12位序列號都是狀態引擎所跟蹤的協議狀態的一部分。
在APP650網絡處理器中,硬件將軟件作為子例程調用,就緩沖管理、流量整形/調度和數據包修改提供決策。軟件運行在基于超長指令字(VLIW)架構的三個計算引擎上。緩沖管理計算引擎強制執行數據包丟棄策略并保持排序統計數據。流量整形器引擎確定每個隊列的服務質量(QOS)和服務等級(COS)處理。流編輯器計算引擎執行協議數據單元(PDU)修改。APP650網絡處理器的硬件輔助流量管理支持成千上萬隊列的確定性流量管理行為,同時還提供了一個框架,通過C編程語言子集進行流量管理算法定制。由于流量管理功能由不同引擎執行,因此分類工作負載不會影響流量管理的確定性。
與此形成對比的是,CPU架構要在支持數據包處理應用的同一處理器池上或在一個單獨分配的內核上執行流量管理算法。這兩種情況都會造成硬件資源在確定性方面利用不充分。此外,軟件程序員還要負責流量管理解決方案開發的各方面工作。APP650架構通過硬件框架消除了上述各種復雜問題,軟件程序員只需做出流量決策。
APP650架構的構建使軟件開發人員不用考慮硬件多線程和并行處理的問題。因此,APP650架構所需較少的軟件編程,相對于現有的CPU無線用戶平面解決方案而言能大幅提高吞吐量。
LSI提供了豐富的軟件開發環境,包括確保周期精度的仿真器,可用作功能調試和應用性能分析。此外,仿真器工具還能用來確定不同硬件資源的利用。
將CPU從RLC分段/級聯任務中釋放出來
根據所需可靠性的不同,RLC可分為三種不同的工作模式。我們在本文中只討論RLC確認模式(AM)。RLCAM模式通過自動重復請求(ARQ)協議來提供可靠的通信。
在RNC下行方向上,發送器執行SDU的分段和級聯任務。RLCSDUs可映射至RLCPDUs,發送并置于重傳隊列中。在不同條件下,發送器可生成狀態報告并反饋給對等RLC。狀態報告可作為獨立的RLCPDU發送,如果有足夠的填充碼的話,它也可附帶在數據PDU末端上。
在RNC上行方向上,RLCAM實體從MAC層接收RLCPDUs。解碼后提取RLC報頭,并用于SDUs的重組。所有狀態和控制PDU都經過處理,且相關信息將被發送至RLC發送端。發送端將根據接收到的狀態PDU檢查重傳緩沖器。此外,RLC報頭中的信息也可用于生成狀態PDUs。
在CPU資源庫中,RLC層的SDU與RLCPDU分段/級聯會消耗大部分CPU資源。由于分段/級聯以及重組能以高數據速率在所有RLC通道上執行,因此可將CPU從上述工作中釋放出來,從而顯著節約CPU資源。圖4顯示了RLC發送器的不同組件以及加速引擎和CPU集之間的分區。我們的目標就是將CPU從高帶寬工作中釋放出來。
在該設計方案中,RLC狀態管理和控制仍由CPU資源庫處理。對狀態PDU進行處理,并將一系列命令重傳給減負引擎(offloadengine)。
例如,在RNC發送器中斷言RLCPDUPOLL位將導致RLC對等對狀態PDU進行傳輸。狀態PDU由RNCCPU資源庫處理,隨后加速引擎將接到指令,將RLCPDU從重傳隊列中釋放出來,或向對等RLC重傳PDU。
如圖5所示,RLCSDU緩沖器將被保存在加速引擎中。由于CPU資源庫不接收SDU,因而可通過SDU的減負、分類以及緩沖節約大量CPU資源。
流量控制是RLC協議的另一項功能。該功能使RLC接收器能夠控制傳輸RLCPDU的對等的速率。流量控制邏輯在CPU資源庫中實施,停止或恢復RLC通道的命令由該邏輯提交至加速引擎。
RLC分段/級聯以及重組減負的性能分析
為了演示APP650網絡處理器作為RLC加速引擎的功能并分析其系統性能,我們設計并實施了概念驗證原型。在原型設計中,傳輸進來的RLCSDU可在APP650網絡處理器中實現緩沖。在每一個傳輸時間間隔(TTI),對所有緩沖的SDU都進行分段和級聯,并將RLCPDU傳輸至千兆以太網端口。隨后,將RLCPDU回路返回至APP650網絡處理器,并經過重組進程將SDU傳回至測試設備。圖5顯示了測試配置情況。
最多可創建30,000個RLC連接,并可針對不同的SDU大小測量可持續吞吐量。可在在所有RLC連接上完成分段/級聯以及重組。在所有實驗中,均采用兩個SDU突發長度進行定期突發。突發的時間間隔與TTI一致。在所有實驗中,可將RLCPDU大小均設為100字節。
表1顯示了SDU大小為142至442字節情況下的30,000個RLC通道的RLCSDU總吞吐量。請注意,無論SDU多大,所有30,000個通道的吞吐量均約為700Mb/s。這種決定性是通用處理器架構所無法實現的。對于30,000個連接而言,吞吐量受傳輸RLCPDU的千兆以太網接口帶寬的限制,而與APP650的處理能力無關。預配置的RLC連接的數量不會影響吞吐量,這是因為所有RLC配置數據均保存在分類樹中(查詢延遲取決于模式大小,而非分類樹中項目的數量),并且與RLC連接相關的所有狀態均保存在狀態引擎內部存儲器中。
APP650仿真器可用于提供資源利用信息(表2)。結果顯示了高RLC通道數情況下且總吞吐量達700Mb/s時的APP650上下文利用率。首處理(firstpass)和次處理(secondpass)上下文利用率分別為51%和10%,從而表明即便在此類極高的速率情況下,APP650網絡處理器仍有進一步提高功能的足夠空間。
結論
隨著HSPA峰值數據速率不斷提高,依靠一系列CPU內核來進行WCDMA用戶平面處理的現有RNC平臺已經不能滿足流量工作負載提高的要求了。現有RNC平臺的問題在于,用戶平面處理(大多為數據處理)的性質不適用于通用CPU架構。無線用戶平面處理要求對周期資源占用較高的功能進行優化,如RLC分段/級聯和重組等。
本文介紹了一種可加速現有RNC WCDMA用戶平面協議棧的方案,即讓APP650網絡處理器來完成RLC分段/級聯和重組的工作。本文討論了APP650架構的眾多優勢,如高效處理數據包的確定性等。仿真與原型設計表明,APP650網絡處理器可為30KRLC通道提供高達700Mb/s的總吞吐量。對于高度靈活的RLC而言,我們能實現超過200Mb/s的單RLC通道峰值速率。
簡言之,可將APP650網絡處理器用作用戶平面加速器,以解決當前RNC系統所面臨的用戶平面峰值和總速率等難題。
責任編輯:gt
-
處理器
+關注
關注
68文章
19349瀏覽量
230295 -
接收器
+關注
關注
14文章
2473瀏覽量
72010 -
cpu
+關注
關注
68文章
10882瀏覽量
212229
發布評論請先 登錄
相關推薦
基于Sitara處理器工業以太網應用的快速啟動系統解決方案
工業應用理想選擇多核處理器
RS-485網絡解決方案的穩定性演示
WCDMA基站的測試解決方案介紹
機器學習實戰:GNN加速器的FPGA解決方案
關于基于網絡處理器的核心路由器設計技術研究,不看肯定后悔
GNN(圖神經網絡)硬件加速的FPGA實戰解決方案
一種基于FPGA的圖神經網絡加速器解決方案
華為WCDMA全網解決方案
面向WCDMA網的傳輸網絡建設
基于多核DSP提升RNC的分組處理能力






 工商網監
工商網監
評論