") 圖像處理硬件加速引擎是什么 如何提高CPU芯片性能
圖像處理硬件加速引擎是什么 如何提高CPU芯片性能
什么是硬件加速引擎?
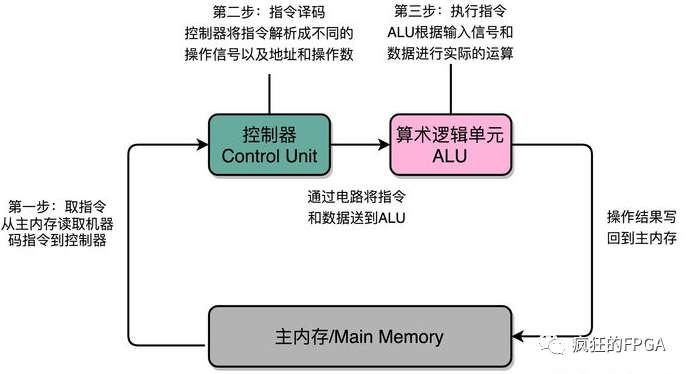
軟件在CPU上執(zhí)行,首先是從控制器從存儲(chǔ)器取指(Fetch),接著控制器進(jìn)行譯碼(Decode),然后由算數(shù)邏輯單元(ALU)執(zhí)行指令(Execute),這就是指令周期,如下圖所示。因此CPU每執(zhí)行一個(gè)運(yùn)算,都是一個(gè)流水線式調(diào)用計(jì)算的過(guò)程。普通計(jì)算機(jī)用指令運(yùn)算速度衡量計(jì)算性能,而超算通常用浮點(diǎn)運(yùn)算速度來(lái)衡量其性能。但不管是指令運(yùn)算還是浮點(diǎn)運(yùn)算,在CPU上都是線程的運(yùn)算,并且要耗費(fèi)n個(gè)指令周期。線程的機(jī)制決定了運(yùn)算只能按部就班,執(zhí)行完當(dāng)前的操作才能進(jìn)行下一個(gè),所以經(jīng)常電腦會(huì)卡住,因?yàn)樾阅懿蛔阋钥焖賵?zhí)行當(dāng)前的運(yùn)算。
想要提高CPU芯片性能,最簡(jiǎn)單粗暴的辦法:要么提升主頻,要么增加核數(shù):
1)提高主頻:當(dāng)前流片的制程限制了主頻,我們一直徘徊在3-5GHz,且進(jìn)一步提高主頻,功耗和散熱也是很大的問(wèn)題。
2)增加核數(shù):無(wú)限制的增加核數(shù)是一種非常笨拙的辦法 ,并且軟件不好優(yōu)化,同時(shí)又受面積、功耗、散熱、成本的制約,芯片良品率也將會(huì)進(jìn)一步降低。
除非是云服務(wù)器類(lèi)芯片等以為追求性能為目標(biāo),對(duì)能耗比不敏感的芯片,否則消費(fèi)類(lèi)芯片核心競(jìng)爭(zhēng)力仍以能耗比和性?xún)r(jià)比為主。這意味著隨著摩爾定律的終結(jié),我們很難再?gòu)耐ㄓ肅PU榨出更多的性能,那么架構(gòu)的演進(jìn)也許才能突破限制——采用硬件加速器引擎(協(xié)處理器),比如采用GPU/DSP/DPU等專(zhuān)用處理單元加速器來(lái)完成特定的功能,提升處理的效率。
典型的在2020.11.11,apple在WWDC上發(fā)布了采用自研SOC的全芯Macbook系列產(chǎn)品,使用的就是最新自研的號(hào)稱(chēng)地表最強(qiáng)的M1芯片。該芯片采用了apple的手機(jī)SOC架構(gòu),由TSMC最新5nm制程工藝代工,集成了8個(gè)CPU,8個(gè)GPU(128個(gè)執(zhí)行單元,可同時(shí)執(zhí)行24576個(gè)線程,運(yùn)算能力高達(dá)2.6TFLOPS),以及16核的神經(jīng)網(wǎng)絡(luò)加速引擎Neural Engine(即上述所謂DPU,每秒可進(jìn)行11萬(wàn)億次操作),硬件編解碼核(硬件完成AVS、264/5等制式視頻的編解碼)。
這款地表最強(qiáng)的SOC,在同等功耗下,號(hào)稱(chēng)達(dá)到了2倍目前最快的CPU性能,再次刷新了數(shù)據(jù)。這里的GPU與Neural Engine,硬件編解碼核等,這就我們所謂的硬件加速器。芯片充分利用硬件加速引擎,有效緩解了CPU線程運(yùn)算的壓力。GPU是專(zhuān)用的圖形處理單元,Neural Engine是專(zhuān)用的卷積神經(jīng)網(wǎng)絡(luò)計(jì)算單元,硬件編解碼是專(zhuān)用的視頻編解碼處理單元,三者異曲同工,無(wú)非就是將原本要用CPU計(jì)算的卷積/浮點(diǎn)運(yùn)算進(jìn)行了硬化,采用門(mén)電路進(jìn)行并行加速運(yùn)算,而非傳統(tǒng)CPU的指令運(yùn)算流程。
文章出處:【微信公眾號(hào):FPGA自習(xí)室】
責(zé)任編輯:gt
-
控制器
+關(guān)注
關(guān)注
112文章
16339瀏覽量
177853 -
cpu
+關(guān)注
關(guān)注
68文章
10855瀏覽量
211606 -
引擎
+關(guān)注
關(guān)注
1文章
361瀏覽量
22548
原文標(biāo)題:圖像處理硬件加速引擎——不斷突破限制(上)
文章出處:【微信號(hào):FPGA_Study,微信公眾號(hào):FPGA自習(xí)室】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于 DSP5509 進(jìn)行數(shù)字圖像處理中 Sobel 算子邊緣檢測(cè)的硬件連接電路圖
TDA4VM上的硬件加速運(yùn)動(dòng)恢復(fù)結(jié)構(gòu)算法

AM62A SoC通過(guò)硬件加速視覺(jué)處理改進(jìn)條形碼讀取器
適用于數(shù)據(jù)中心應(yīng)用中的硬件加速器的直流/直流轉(zhuǎn)換器解決方案
圖形圖像硬件加速器卡設(shè)計(jì)原理圖:270-VC709E 基于FMC接口的Virtex7 XC7VX690T PCIeX8 接口卡
基于FPGA的圖像采集與顯示系統(tǒng)設(shè)計(jì)
工業(yè)級(jí)HMI芯片Model3芯片詳解(二)圖像顯示

PSoC 6 MCUBoot和mbedTLS是否支持加密硬件加速?
基于FPGA的實(shí)時(shí)邊緣檢測(cè)系統(tǒng)設(shè)計(jì),Sobel圖像邊緣檢測(cè),F(xiàn)PGA圖像處理
新思科技硬件加速解決方案技術(shù)日在成都和西安站成功舉辦
Elektrobit利用其首創(chuàng)的硬件加速軟件優(yōu)化汽車(chē)通信網(wǎng)絡(luò)的性能
用DE1-SOC進(jìn)行硬件加速的2D N-Body重力模擬器設(shè)計(jì)

330-基于FMC接口的Kintex-7 XC7K325T PCIeX4 3U PXIe接口卡 圖形圖像硬件加速器
【國(guó)產(chǎn)FPGA+OMAPL138開(kāi)發(fā)板體驗(yàn)】(原創(chuàng))7.硬件加速Sora文生視頻源代碼
音視頻解碼器硬件加速:實(shí)現(xiàn)更流暢的播放效果






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論