 采用硬件加速實現的基本思維有哪些
采用硬件加速實現的基本思維有哪些
很多圖像算法不涉及對顏色的識別,僅需要識別灰度目標的變化即可,因此很多時候需要將彩色圖像轉換為灰度圖像,在進行進一步的處理。彩色轉灰度計算公式如下:Y=0.299*R + 0.587*G + 0.144*B,作者以05年的嵌入式系統計算,采用640*480的圖像進行試驗,一系列的圖像優化如下(只是類比,不要太在意數據):
1)一維數組索引比三維快,因此先將RGB三維數組轉成一維數組,再直接用上述公式進行計算,嵌入式系統計算時間為120秒;
2)由于Windows位圖是ARGB8888的精度,因此計算結果僅需要8bit整形,可忽略小數,假定左右擴大1000倍去轉定點計算,則新的公式如下:Y=(299R + 587*G + 144*B)/1000,此時嵌入式系統計算時間加快到45秒;
3)除法計算太慢,擴大2N次方可轉移位操作,假定擴大4096倍轉定點,則新的公式如下:Y=(R*1224+G*2404+B*467)>>12,計算進一步加快到30秒;
4)由于RGB的取值是固定的[0,255],因此公式中每一步運算其實都可以提前計算好,然后直接索引——查找表,這樣將執行計算轉換成了執行索引,此時再測試計算速度驚人的提升到了2秒;
5)接著作者再馬力全開,采用2個ALU并行計算,并且將查找表從int型改成unsigned short型,以及函數聲明為inline,減少CPU的調用開銷,最后在嵌入式系統上將計算速度提升到了0.5秒。
以上為conquer 05年《讓你的軟件飛起來》中的相關數據,通過軟件優化的提升,從最初的120S提升到了0.5S,將近240倍,足以見得一個優秀的軟件工程師的重要性,也許IOS和Windows的性能差距那么大,也由此方面原因吧。
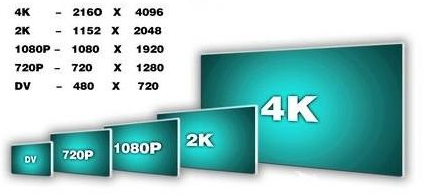
目前多媒體視頻普遍到了2K/4K的分辨率,以4K視頻為例,其運算量是640*480的30.7倍((4096*2304)/(640*480)≈30.7),那么0.5*30.7=15.35秒怎么做到實時視頻處理/顯示呢(60FPS下單幀16.667ms),差92000倍呢。PC采用GPU加速處理完成圖形運算,但如果是終端產品,如果沒有昂貴的CPU,也沒有其他加速引擎,那簡直天方夜譚。那么,此時主角該上場了——硬件加速器,讓我們開始他的表演。
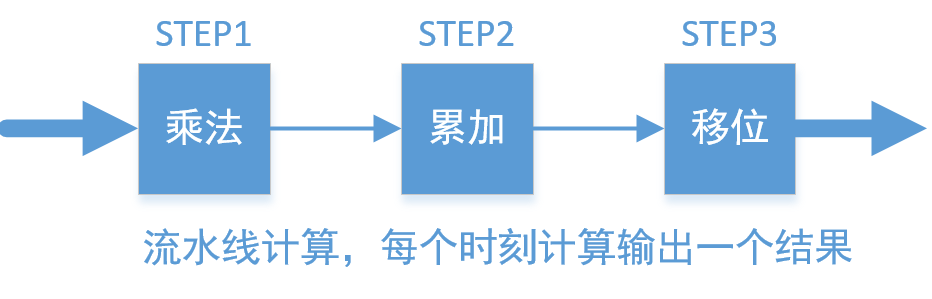
以4096*2304的4K60視頻RGB轉YUV為例,進行硬件思維的加速計算解說。不管是FPGA還是ASIC,以門級電路并行加速運算,時序邏輯每個時鐘翻轉完成一次計算。前面《讓你的軟件飛起來》中(2)已經完成了定點化,然后(3)采用乘法+移位的方式實現,(4)采用查找表再累加的方式實現。單從效率上考慮,兩者計算一個像素的灰度均耗用3個CLK(乘法、累加、移位,或給RAM地址、讀RAM數據,累加);但從資源上對比,前者占用3個乘法器和2個加法器,乘法器數量不多,但是綜合速率受器件的限制,后者則需要3個19bit*256深度的RAM,占用了更多的面積,綜合速率上也受到RAM的限制。兩者都用了專用單元庫,但采用硬件乘法器面積更小,且靈活性更強,工作量也更小(不用專門去生成),因此用硬件加速首選采用優化方式(3),具體實現流水線如下:
STEP1:采用三個乘法器,并行計算當前輸入像素的RGB通道乘法,即R*1224,G*2404, B*467;
STEP2:將上述三個結果直接進行累加;同時計算下一個像素的STEP1操作;
STEP3:將累加后的結果向右移動12bit,取低8bit得到最后的結果;同時計算下一個像素的STEP1,STEP2。
以流水線式循環操作完一副完整的圖像,如果是輸入到下一級算法處理,則整體的延時僅為3個CLK,因為三個時鐘后得到灰度圖像的1個像素,立馬可以進行下一級運算;如果圖像寫回緩存,我們再來精算一下:以主頻250MHz為例(事實上28nm ASIC跑500MHz甚至1GHz都不是問題,FPGA 45nm的250MHz也沒有問題),則需要(4096*2304+2)*4ns=37.75ms>16.667ms。
直接流水線實現,貌似這還不夠滿足我們實時的需求,畢竟很多運算需要從內存中來,回到內存中去,還得給別的算法預留時間,彩色轉灰度這只是算法的第一步而已,復雜的還沒來呢。那我們繼續想辦法突變限制,充分利用硬件加速,挑戰不可能。既然采用門級電路,那不存在線程的約束,然而我們已經采用了流水線并行計算灰度值,那進一步想是否可以同時計算n個像素的灰度值呢?答案是肯定的,如下圖所示:
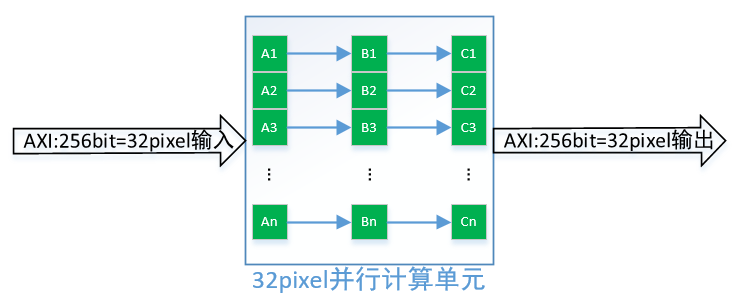
假設DDR控制器位寬是256bit,則一次性可以讀取32個pixel的數據,32個像素同時計算需要96個乘法器,64個加法器,這些資源的需求甚至對低端的FPGA都不是問題,對于ASIC來說沒有太大的面積影響。因此還是在主頻250MHz,DDR控制器帶寬256bit條件下,我們處理一副4096*2304彩轉灰圖像的時間為:37.35/32≈1.17ms<16.667ms,采用并行運算提升32倍效率后,4K圖像僅需要1.17ms,完全能夠滿足實時性,甚至還給后續算法預留了90%以上的時間,可以滿足系統的需求。
綜上,采用硬件加速實現的幾種基本思維,總結如下:
1)浮點轉定點,硬件乘法+移位實現加速;
2)資源夠的前提下,充分利用并行計算,在單位時間提升計算量;
3)充分利用流水線特性,算法采用Pipeline的方式進行計算,能不回內存就不回內存,能用localbuffer就用localbuffer;
4)盡量少用CPU參與計算,硬件自動完成狀態跳轉,除非最終結果浮點等復雜的運算;
文章出處:【微信公眾號:FPGA自習室】
責任編輯:gt
-
FPGA
+關注
關注
1629文章
21748瀏覽量
603863 -
控制器
+關注
關注
112文章
16382瀏覽量
178311 -
分辨率
+關注
關注
2文章
1067瀏覽量
41949
原文標題:圖像處理硬件加速引擎——不斷突破限制(下)
文章出處:【微信號:FPGA_Study,微信公眾號:FPGA自習室】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

基于Xilinx XCKU115的半高PCIe x8 硬件加速卡

FPGA加速深度學習模型的案例
適用于數據中心應用中的硬件加速器的直流/直流轉換器解決方案

PSoC 6 MCUBoot和mbedTLS是否支持加密硬件加速?
新思科技硬件加速解決方案技術日在成都和西安站成功舉辦
Elektrobit利用其首創的硬件加速軟件優化汽車通信網絡的性能

330-基于FMC接口的Kintex-7 XC7K325T PCIeX4 3U PXIe接口卡 圖形圖像硬件加速器
【國產FPGA+OMAPL138開發板體驗】(原創)7.硬件加速Sora文生視頻源代碼
音視頻解碼器硬件加速:實現更流暢的播放效果

KubeCASH:基于軟硬件融合的容器管理平臺





 工商網監
工商網監
評論