") Kria K26 SOM性能解決方案的對(duì)比分析
Kria K26 SOM性能解決方案的對(duì)比分析
賽靈思的研究結(jié)果表明,K26 SOM 提供了比英偉達(dá) Jetson Nano 高出大約 3 倍的性能。此外,它的單位功耗性能較之英偉達(dá) Jetson TX2 提升了 2 倍。對(duì)于 SSD MobileNet-v1 這樣的網(wǎng)絡(luò),K26 SOM 的低時(shí)延、高性能深度學(xué)習(xí)處理單元 (DPU)提供了比 Nano 高出 4 倍甚至更高的性能。
01
與未來兼容的 Kria K26 SOM
智能應(yīng)用除了要求亞微秒級(jí)的時(shí)延,還需要具備私密性、低功耗、安全性和低成本。以 Zynq MPSoC 架構(gòu)為基礎(chǔ),Kria K26 SOM 提供了業(yè)界一流的單位功耗性能和更低的總體擁有成本,使之成為邊緣設(shè)備的理想選擇。
原始計(jì)算能力
就在邊緣設(shè)備上部署解決方案而言,硬件必須擁有充足的算力,才能處理先進(jìn) ML 算法工作負(fù)載。我們可以使用各種深度學(xué)習(xí)處理單元 (DPU) 配置對(duì) Kria K26 SOM 進(jìn)行配置,還能根據(jù)性能要求,將最適用的配置集成到設(shè)計(jì)內(nèi)。
支持更低精度的數(shù)據(jù)類型
深度學(xué)習(xí)算法正在以極快的速度演進(jìn)發(fā)展,各種更低精度的數(shù)據(jù)類型和定制數(shù)據(jù)正在進(jìn)入使用。傳統(tǒng)的 GPU 廠商已無法滿足當(dāng)前的市場(chǎng)需求,而 Kria K26 SOM 能夠支持全系列數(shù)據(jù)類型精度,如 PF32、INT8、二進(jìn)制和其他定制數(shù)據(jù)類型。
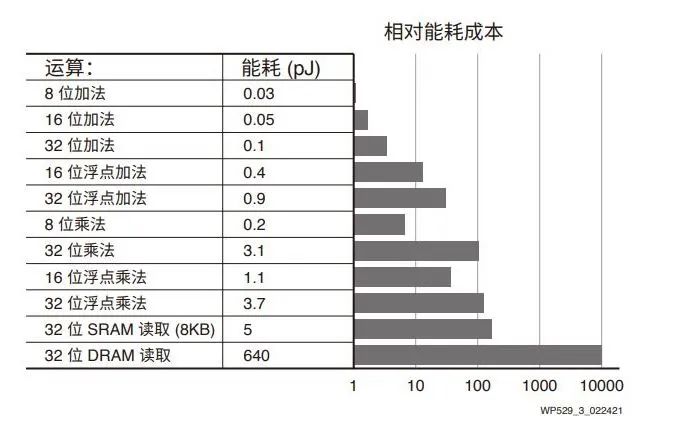
運(yùn)算的能耗成本
低時(shí)延與低功耗
為了改善軟件可編程能力,GPU 架構(gòu)需要頻繁訪問外部 DDR。這種做法非常低效,有時(shí)候會(huì)對(duì)高帶寬設(shè)計(jì)要求構(gòu)成瓶頸。相反,Zynq MPSoC 架構(gòu)具有高能效,它的可重配置能
力便于開發(fā)者設(shè)計(jì)的應(yīng)用減少或不必訪問外部存儲(chǔ)器。這不僅有助于減少應(yīng)用的總功耗,也通過降低端到端時(shí)延改善了響應(yīng)能力。
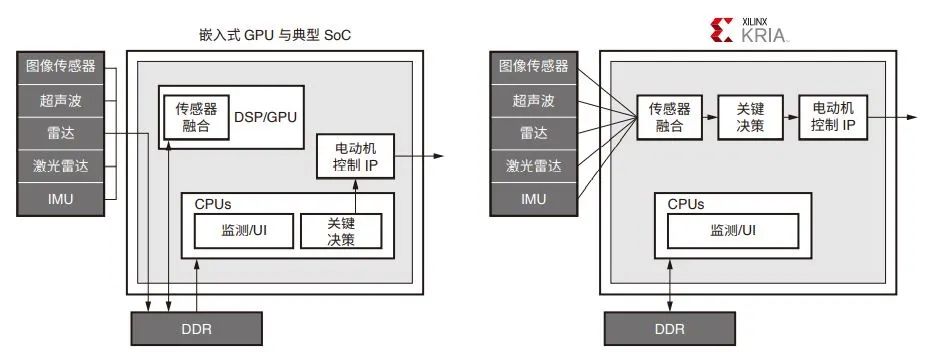
典型 GPU 與 Zynq MPSoC 架構(gòu)
靈活性
與數(shù)據(jù)流固定的 GPU 不同,賽靈思硬件提供了靈活性用來專門地重新配置數(shù)據(jù)路徑,從而實(shí)現(xiàn)最大吞吐量并降低時(shí)延。此外,可編程的數(shù)據(jù)路徑也降低了對(duì)批處理的需求,而批處理是 GPU 的一個(gè)重大不足,需要在降低時(shí)延或提高吞吐量之間做出權(quán)衡取舍。Kria SOM 靈活的架構(gòu)已在稀疏網(wǎng)絡(luò)中展示出巨大潛力。
02
與英偉達(dá) Jetson 性能比較
深度學(xué)習(xí)模型性能比較
根據(jù)測(cè)試數(shù)據(jù),所有模型在 K26 SOM 上的性能數(shù)值均優(yōu)于英偉達(dá) Jetson Nano。而且對(duì)于 SSD Mobilenet-V1 等部分模型,吞吐量則為 Jetson Nano 的四倍以上,為 Jetson Tx2 的兩倍左右,從下表可以很容易地看到顯著的吞吐量提升。
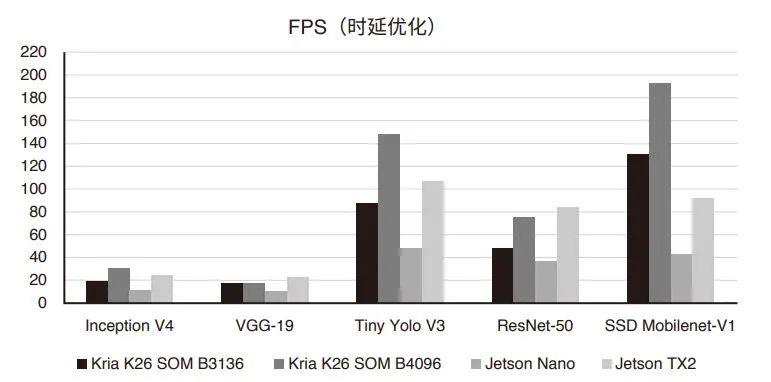
FPS(時(shí)延優(yōu)化)
功耗測(cè)量
邊緣設(shè)備提供最佳性能這點(diǎn)非常重要,但同時(shí)必須降低能耗。賽靈思測(cè)量了英偉達(dá)和賽靈思 SOM 模塊在執(zhí)行具體模型時(shí)發(fā)生的峰值功率,結(jié)果很明顯,K26 SOM 優(yōu)于 Jetson Nano
3.5 倍,優(yōu)于 Jetson TX2 2.4 倍。
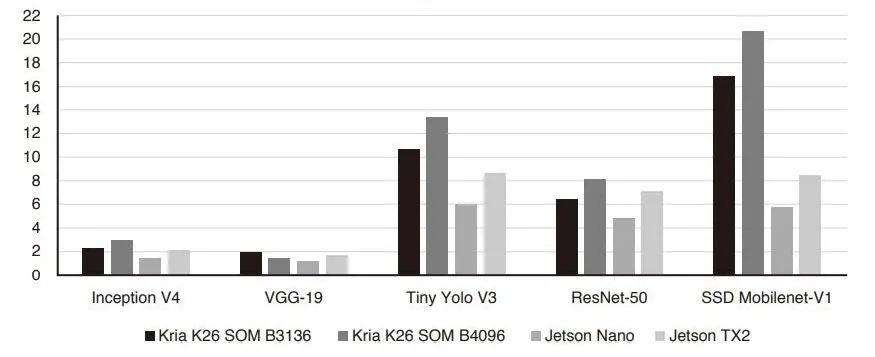
FPS/瓦
實(shí)際應(yīng)用性能比較
為了分析實(shí)際用例,我們選擇了一種準(zhǔn)確檢測(cè)和識(shí)別車輛牌照的基于機(jī)器學(xué)習(xí)的應(yīng)用。將 Uncanny Vision 行業(yè)領(lǐng)先的 ANPR 算法部署在 Kria SOM 上后,與英偉達(dá)用 Deepstream-SDK 完成的“車牌識(shí)別”的公開數(shù)據(jù)進(jìn)行比較,結(jié)果說明,Uncanny Vision 的 ANPR 流水線在針對(duì) KV260 入門套件進(jìn)行優(yōu)化后,實(shí)現(xiàn)了超過 33fps 的吞吐量,顯著優(yōu)于英偉達(dá)基準(zhǔn)測(cè)試中 Jetson Nano 的 8pfs 和 Jetson Tx2 的 23fps。這種前所未有的性能水平為 ANPR 集成商和 OEM 廠商提供了優(yōu)于競(jìng)爭(zhēng)對(duì)手的開發(fā)靈活性。
實(shí)際應(yīng)用測(cè)試顯示,K26 SOM 不僅在標(biāo)準(zhǔn)性能比較中表現(xiàn)極其優(yōu)異,并且在為開發(fā)者提供加速整體 AI 和視覺流水線所需的原始性能時(shí),效率也更高。通過對(duì)比,在標(biāo)準(zhǔn)的基準(zhǔn)測(cè)試領(lǐng)域之外,競(jìng)爭(zhēng)解決方案傾向于提供較低效率水平,而且功耗較高。
文章出處:【微信公眾號(hào):FPGA開發(fā)圈】
責(zé)任編輯:gt
-
賽靈思
+關(guān)注
關(guān)注
32文章
1794瀏覽量
131246 -
gpu
+關(guān)注
關(guān)注
28文章
4729瀏覽量
128890 -
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3770瀏覽量
90989
原文標(biāo)題:白皮書 | Kria K26:邊緣端視覺 AI 理想平臺(tái)
文章出處:【微信號(hào):FPGA-EETrend,微信公眾號(hào):FPGA開發(fā)圈】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
TNC連接器對(duì)比分析:與其他射頻連接器的性能對(duì)決

廣和通率先推出5G融合Wi-Fi 7智能解決方案
RoCE與IB對(duì)比分析(二):功能應(yīng)用篇
億佰特污水監(jiān)控系統(tǒng)智能解決方案,精確感知、精細(xì)管理!

常用音頻線接口對(duì)比分析
對(duì)比分析點(diǎn)焊機(jī)與傳統(tǒng)焊接方法
網(wǎng)關(guān)和路由器的對(duì)比分析
激光錫焊與回流焊接對(duì)焊點(diǎn)影響的對(duì)比分析
交流伺服電機(jī)與直流伺服電機(jī)的對(duì)比分析
貿(mào)澤開售適用于工業(yè)、醫(yī)療和機(jī)器人應(yīng)用的AMD/Xilinx Kria K24 SOM

SD卡、MicroSD卡和SD NAND的性能與應(yīng)用對(duì)比
控制繼電器與PLC的對(duì)比分析
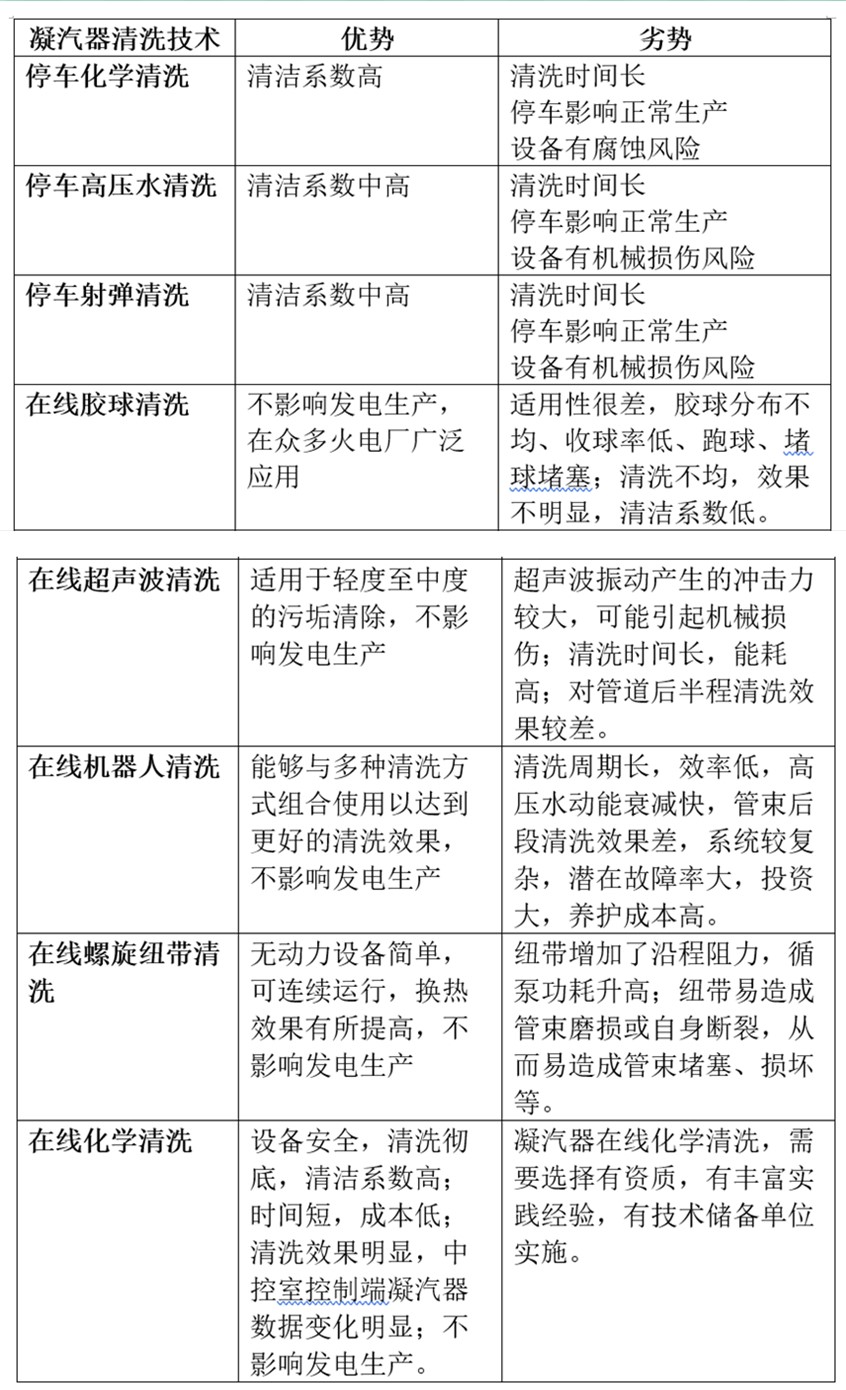
火電廠凝汽器不停車在線清洗與凝汽器停車清洗八種技術(shù)對(duì)比分析
DC電源模塊與AC電源模塊的對(duì)比分析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論