") 如何解決像亂序執(zhí)行又像內(nèi)存屏障的BUG
如何解決像亂序執(zhí)行又像內(nèi)存屏障的BUG
后發(fā)先至:另外一位讀者則給出了一個(gè)更奇怪的現(xiàn)象,兩個(gè)變量中后執(zhí)行的代碼看起來卻先被調(diào)用了。
加個(gè)if問題竟然解了:最后一個(gè)反饋留言最令人崩潰,在代碼中隨便加上個(gè)判斷語(yǔ)句,不但解決了y=0的問題,性能還非常好。
1難道這就是傳說中的亂序執(zhí)行?
先來看以下讀者回復(fù)的代碼:
package main import (“fmt”“sync/atomic”“time”) func main() {var x int32var y int32 go func() {for { x = atomic.AddInt32(&x, 1) y = atomic.AddInt32(&y, 1) } }() time.Sleep(time.Second) fmt.Println(“x=”, x) fmt.Println(“y=”, y)}
在這部分內(nèi)容中,兩個(gè)變量x和y都是由原子操作Automic.Add來保證并發(fā)安全的,但是結(jié)果輸出出來我們可以發(fā)現(xiàn)y竟然比x還大?而且每次運(yùn)行的情況基本都是y更大,只是大多少有所區(qū)別。
x= 49418397y= 49425282成功: 進(jìn)程退出代碼 0.
看到這個(gè)輸出結(jié)果,我第一反應(yīng)感覺這是亂序執(zhí)行的衍生現(xiàn)象,因?yàn)閤和y的加1操作彼此是獨(dú)立的,雖然編譯器不會(huì)優(yōu)化執(zhí)行順序,但是在CPU的執(zhí)行層面有可能會(huì)對(duì)于前后無依賴的操作打亂順序執(zhí)行。這樣一來就的確有可能出現(xiàn)后面的操作先執(zhí)行的情況。
但是仔細(xì)一想這樣的說法應(yīng)該并不合理,如果是亂序執(zhí)行的原因,那么上面這段代碼的執(zhí)行結(jié)果肯定不會(huì)每次結(jié)果都是y更大一些,每次執(zhí)行都是y比x更大只能說明代碼是按照一定順序執(zhí)行的,而且目前的CPU指令流水線的預(yù)測(cè)功能肯定還沒有牛到能夠完全知曉x與y的值不按照順序提交是沒有作何影響的地步。
2仔細(xì)一看還是多并發(fā)競(jìng)爭(zhēng)問題
再來看以下代碼,
package main import (“fmt”“sync/atomic”“time”) func main() {var x int32var y int32 go func() {for { x = atomic.AddInt32(&x, 1) y = atomic.AddInt32(&y, 1) } }() time.Sleep(time.Second) x1 := x y1 := y fmt.Println(“x=”, x1) fmt.Println(“y=”, y1)}
只要把fmt.println之前先把x和y的值拷貝出來到x1與y1,再打印x1與y1的值就基本沒有這個(gè)誤差了。
x= 51061072y= 51061071成功: 進(jìn)程退出代碼 0.
這也就是說,fmt.println在執(zhí)行中間,go func中的子gorouine又被調(diào)度了。所以y比x的值大,本質(zhì)又是一個(gè)多并發(fā)的競(jìng)爭(zhēng)問題。而不是亂序執(zhí)行的原因,只是這個(gè)問題在Go的開發(fā)模式下也是非常隱蔽。
3崩潰了,單核怎么也是0
再說第二個(gè)令人崩潰的讀者反饋,他在單核的云ECS嘗試運(yùn)行以下代碼,
package main import (“fmt”//“sync/atomic”“time”) func main() {var x int32var y int32 go func() {for { x++ y++ } }() time.Sleep(time.Second) fmt.Println(“x=”, x) fmt.Println(“y=”, y)}
結(jié)果也是0。剛開始我覺得這個(gè)讀者反饋有誤,因此我也立刻在阿里云的X86集群與華為云的鯤鵬集群分別申請(qǐng)了一臺(tái)單核ECS,不過結(jié)果令人崩潰,無論是ARM還是X86單核平臺(tái)運(yùn)行上述代表的結(jié)果也還是0,不過這還沒完。
4更崩潰了,隨隨便便加個(gè)if竟然殺瘋了…。
接下來是最令人崩潰的時(shí)刻,我們來看以下代碼:
package main import (“fmt”//“sync/atomic”“time”) func main() {var x int32var y int32 z := 0 go func() {for { x++//一些無需關(guān)注并發(fā)安全的計(jì)算問題 y++if z 》 0 { fmt.Println(“z is”, z)//這一行代碼不會(huì)執(zhí)行到 } } }() time.Sleep(time.Second)//定時(shí)執(zhí)行,超過1秒鐘就停止了,無需關(guān)注并發(fā)安全 fmt.Println(“x=”, x) fmt.Println(“y=”, y)}
這段代碼在沒有作何鎖或者互斥體的基礎(chǔ)上竟然解決了y=0的問題,而且令人崩潰的是,這段代碼的執(zhí)行效率竟然還非常驚人,比之前Automic的方式至少快一個(gè)數(shù)量級(jí),
如果是這樣的話那么這種代碼方案就非常適合于不需要并發(fā)控制,并且定時(shí)需要結(jié)束的計(jì)算場(chǎng)景,假如我一個(gè)計(jì)算任務(wù)只能給1秒鐘,能算得出來就算,算不出來就解下一題了,那么if的方案就非常適合了。
x= 407698730y= 407745938成功: 進(jìn)程退出代碼 0.
在解釋if分支這個(gè)非主流的方案之前,我們?cè)賮砜匆幌禄コ怏w這種主流并發(fā)同步方案。
互斥體實(shí)現(xiàn)如下:
package main import (“fmt”“sync” //“sync/atomic”“time”) func main() {var x int32var y int32var mutex sync.Mutex go func() {for { mutex.Lock() x++ y++ mutex.Unlock() } }() time.Sleep(time.Second) x1 := x y1 := y fmt.Println(“x=”, x1) fmt.Println(“y=”, y1)}
運(yùn)行結(jié)果如下:
x= 50889322y= 50889322成功: 進(jìn)程退出代碼 0.
我們可以看到互斥、原子操作等方法最終運(yùn)行結(jié)果基本都在一個(gè)數(shù)量級(jí)以內(nèi)上下浮動(dòng),幅度不超過10%,對(duì)比之下if的方案實(shí)在是殺瘋了,直接比上述這種安全的寫法性能好出一個(gè)數(shù)量級(jí)!隨便加入個(gè)if分支,竟然也能解決y=0,而且還是高效解決這到底是為什么?
5關(guān)鍵時(shí)刻匯編令人心安,大神一語(yǔ)道破
在我的知識(shí)儲(chǔ)備實(shí)在無法解釋以上現(xiàn)象的時(shí)候,我只能將希望訴諸objdump,將gobuild生成的可執(zhí)行文件來進(jìn)行反編譯,通過查看匯編語(yǔ)言代碼來尋找問題解釋的蛛絲馬跡。不看不知道一看還真是有驚喜,加了if語(yǔ)句和加鎖等方式一樣全部會(huì)加上內(nèi)存寫屏障writeBarrier。具體如下:
未加if的匯編結(jié)果
0000000000499400 《main.main.func1》:499400: eb 00 jmp 499402 《main.main.func1+0x2》499402: eb 00 jmp 499404 《main.main.func1+0x4》499404: eb 00 jmp 499406
《main.main.func1+0x6》499406: eb fa jmp 499402 《main.main.func1+0x2》499408: cc int3499409: cc int349940a: cc int3 49940b: cc int349940c: cc int349940d: cc int3.。。省略0000000000499420 《type..eq.[2]interface {}》:499420: 64 48 8b 0c 25 f8 ff mov %fs:0xfffffffffffffff8,%rcx499427: ff ff499429: 48 3b 61 10 cmp 0x10(%rcx),%rsp 49942d: 0f 86 cf 00 00 00 jbe 499502 《type..eq.[2]interface {}+0xe2》499433: 48 83 ec 50 sub $0x50,%rsp
加了if或者鎖的匯編結(jié)果
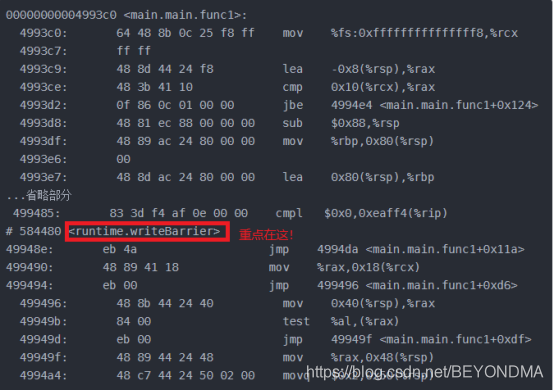
wirteBarrier有點(diǎn)類似于文件操作中flush的作用,會(huì)強(qiáng)制把數(shù)據(jù)由緩存同步到內(nèi)存當(dāng)中去,因此我前文中所說兩個(gè)變量其中一個(gè)加鎖,另一個(gè)結(jié)果也能不為0是因?yàn)樗麄冊(cè)谕痪彺嫘性蚪忉屢膊粚?duì),x和y并不是因?yàn)樵谕粋€(gè)緩存行所以才被一起同步回內(nèi)存的,而是由于wirteBarrier這個(gè)屏障所引入的。我們來看下面的代碼。
package main import (“fmt”//“sync/atomic”“time”) func main() {var x int32var y int32 slice := make([]int, 10, 10) z := 0 go func() {for { x++ y++for index, value := range slice { slice[index] = value + 1 }if z 》 0 { fmt.Println(“z is”, z) } } }() time.Sleep(time.Second) fmt.Println(“x=”, x) fmt.Println(“y=”, y) fmt.Println(“slice=”, slice)}
他的運(yùn)行結(jié)果是:
x= 86961625y= 86972610slice= [86978588 86979075 86979101 86979417 86979435 86979452 86979464 86979771 86979793 86979807]成功: 進(jìn)程退出代碼 0.
我造出來長(zhǎng)度為10整形切片,緩存行一般只有64BYTE,那么這個(gè)切片上面的數(shù)據(jù)是不可能在同一緩存行上的,通過這段代碼的執(zhí)行結(jié)果可以看到所有切換的值全部被更新了,因此我們可以了解writeBarrier這個(gè)內(nèi)存寫屏障的功能是將之前所有的數(shù)據(jù)全部強(qiáng)制回寫到內(nèi)存當(dāng)中。
我對(duì)于單核ECS中運(yùn)行的結(jié)果也是y=0的結(jié)果有了一定的認(rèn)識(shí),由于ECS虛擬機(jī)運(yùn)行的主體也是物理機(jī),而物理機(jī)肯定不是單核的,因此不執(zhí)行writeBarrier這個(gè)寫屏障語(yǔ)句,數(shù)據(jù)也無法刷回內(nèi)存,雖然程序運(yùn)行在單核虛擬機(jī)上,而虛擬機(jī)并不會(huì)把匯編指令再做包裝,這也就造成實(shí)際的執(zhí)行與多核環(huán)境沒有什么差別。
6if為什么會(huì)被如此安排
實(shí)在中If不但實(shí)際達(dá)到了內(nèi)存同步的效果,而且還效率更高,看起來非常適合這種沒有強(qiáng)制同步需要的使用場(chǎng)景。不過我們不禁要問為什么編譯器要在出現(xiàn)if語(yǔ)句時(shí)顯式調(diào)用內(nèi)存屏障。個(gè)人猜測(cè)原因有兩個(gè),
if判斷使用真實(shí)值是隱含的前提:首先在進(jìn)行判斷時(shí),使用緩存中的數(shù)據(jù)可能會(huì)帶來顯而易見的問題:因?yàn)樵谧雠袛鄷r(shí)程序員一般是要求用目前變量的實(shí)際值而不是緩存值來進(jìn)行的,這是一個(gè)隱含的前提,可能編譯器在優(yōu)化時(shí)考慮到了這一點(diǎn)。
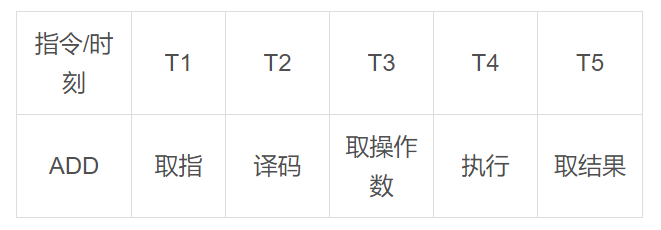
指令流水線的原因:我們知道CPU的每個(gè)動(dòng)作都需要用晶體震蕩而觸發(fā),以加法ADD指令為例,想完成這個(gè)執(zhí)行指令需要取指、譯碼、取操作數(shù)、執(zhí)行以及取操作結(jié)果等若干步驟,而每個(gè)步驟都需要一次晶體震蕩才能推進(jìn),因此在流水線技術(shù)出現(xiàn)之前執(zhí)行一條指令至少需要5到6次晶體震蕩周期才能完成。如下圖:
為了縮短指令執(zhí)行的晶體震蕩周期,芯片設(shè)計(jì)人員參考了工廠流水線機(jī)制的提出了指令流水線的想法,由于取指、譯碼這些模塊其實(shí)在芯片內(nèi)部都是獨(dú)立的,完成可以在同一時(shí)刻并發(fā)執(zhí)行,那么只要將多條指令的不同步驟放在同一時(shí)刻執(zhí)行,比如指令1取指,指令2譯碼,指令3取操作數(shù)等等,就可以大幅提高CPU執(zhí)行效率:
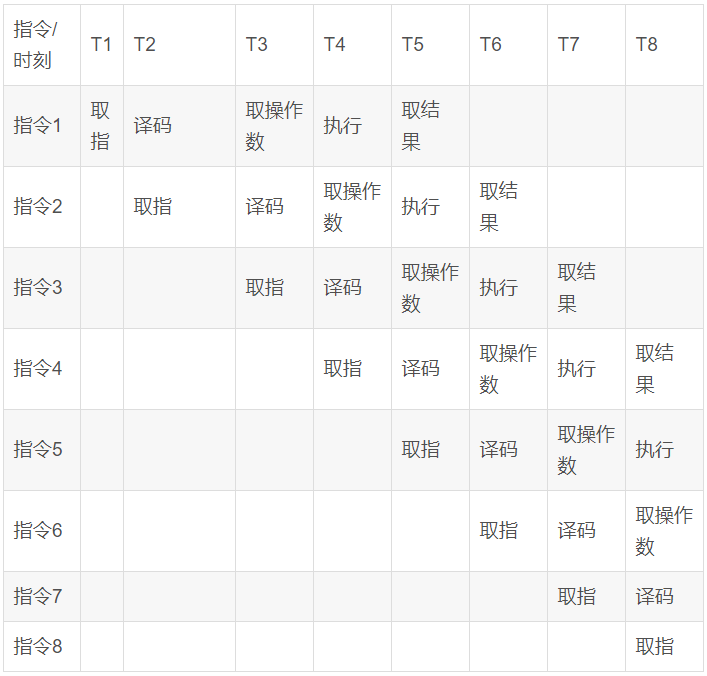
以上圖流水線為例 ,在T5時(shí)刻之前指令流水線以每周期一條的速度不斷建立,在T5時(shí)代以后每個(gè)震蕩周期,都可以有一條指令取結(jié)果,平均每條指令就只需要一個(gè)震蕩周期就可以完成。這種流水線設(shè)計(jì)也就大幅提升了CPU的運(yùn)算速度。
但是if分支會(huì)造成流水線的停頓,也就是說指令流水線系統(tǒng)無法確定在指令1執(zhí)行時(shí)確定指令7的具體情況。那么在if時(shí)加上writeBarrier這種耗時(shí)操作其實(shí)也就可以理解了,反正if也造拖慢執(zhí)行速度,那編譯器也就不在乎在此時(shí)加上另外的耗時(shí)操作了。
7Rust為什么令人羨慕
不過在看了一段時(shí)間的Rust后,我感覺Rust的優(yōu)勢(shì)是可以避免程序員犯很多錯(cuò)誤,而這其中所謂的錯(cuò)誤雖然看起來低級(jí),但是如果他們被隱藏在千萬(wàn)行代碼之中,那么排查起來真是相當(dāng)費(fèi)時(shí)費(fèi)力,由于已經(jīng)是所有權(quán)轉(zhuǎn)移了,因此變量的使用不太會(huì)出現(xiàn)像Go一樣的錯(cuò)誤情況,這點(diǎn)我們?cè)谏弦黄恼轮幸呀?jīng)有所論述了,而且我們來看以下代碼:
use std::thread;use std::mpsc;use std::Duration; fn main() {let (tx, rx) = mpsc::channel();let tx1 = mpsc::clone(&tx); //增加一個(gè)發(fā)送者tx1,需要clonelet tx2 =
mpsc::clone(&tx); //增加一個(gè)發(fā)送者tx2,需要clone thread::spawn(move || {let vals = vec![String::from(“I‘m”),String::from(“from”),String::from(“the”),String::from(“tx it self”), ]; for val in vals { tx.send(val).unwrap(); }}); thread::spawn(move || {let vals = vec!
[String::from(“I’m”),String::from(“from”),String::from(“the”),String::from(“tx1”), ]; for val in vals { tx1.send(val).unwrap(); }}); thread::spawn(move || {let vals = vec![String::from(“I‘m”),String::from(“from”),String::from(“the”),String::from(“tx2”), ]; for val in vals { tx2.send(val).unwrap(); }}); for received in rx { //一個(gè)通道一個(gè)接收者,接收若干個(gè)發(fā)送者的信息 println!(“Got: {}”, received);} }
可見Rust中連管道的多路并發(fā)的管理使用都要通過clone的方式來安全傳遞信息,個(gè)人根本想不到用Rust編程怎么能出現(xiàn)像上面例子中Go造成的Bug,因此Rust的學(xué)習(xí)曲線雖然陡峭,但是感覺Rust程序包往往只掌握原生的框架就可以做得很好了,而不像Python、Java除了原生語(yǔ)言知識(shí)以外,還需要學(xué)習(xí)熟練運(yùn)用各種第三方的包。
馬超,CSDN博客專家,阿里云MVP、華為云MVP,華為2020年技術(shù)社區(qū)開發(fā)者之星。
編輯:jq
-
BUG
+關(guān)注
關(guān)注
0文章
155瀏覽量
15665
原文標(biāo)題:遠(yuǎn)看像亂序執(zhí)行,近看是內(nèi)存屏障的 BUG 是如何解決的?
文章出處:【微信號(hào):coder_life,微信公眾號(hào):程序人生】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
MQ消息亂序問題解析與實(shí)戰(zhàn)解決方案
虛擬內(nèi)存不足如何解決 虛擬內(nèi)存和物理內(nèi)存的區(qū)別
DDR內(nèi)存頻率對(duì)性能的影響
微處理器執(zhí)行指令的基本過程
堆棧和內(nèi)存的基本知識(shí)
ESP32C3藍(lán)牙m(xù)eshprovisioner出現(xiàn)內(nèi)存溢出問題如何解決?
讀取0x1000003e處內(nèi)存失敗如何解決?
【BUG收集】為昕原理圖設(shè)計(jì)EDA軟件(Jupiter)免費(fèi)評(píng)測(cè)活動(dòng)常見問題及BUG收集
Andes晶心科技正式推出AndesCore? AX65全新RISC-V亂序執(zhí)行、超純量、多核處理器
ug內(nèi)部錯(cuò)誤,內(nèi)存訪問違例怎么解決
深入理解Linux RCU:從硬件說起之內(nèi)存屏障





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論