


快速排序是由東尼·霍爾所發展的一種排序算法。在平均狀況下,排序 n 個項目要Ο(n log n)次比較。在最壞狀況下則需要Ο(n2)次比較,但這種狀況并不常見。事實上,快速排序通常明顯比其他Ο(n log n) 算法更快,因為它的內部循環(inner loop)可以在大部分的架構上很有效率地被實現出來。
算法步驟:
1 從數列中挑出一個元素,稱為 “基準”(pivot)。
2 重新排序數列,所有元素比基準值小的擺放在基準前面,所有元素比基準值大的擺在基準的后面(相同的數可以到任一邊)。在這個分區退出之后,該基準就處于數列的中間位置。這個稱為分區(partition)操作。
3 遞歸(recursive)的把小于基準值元素的子數列和大于基準值元素的子數列排序。
遞歸的最底部情形,是數列的大小是零或一,也就是永遠都已經被排序好了。雖然一直遞歸下去,但是這個算法總會退出,因為在每次的迭代(iteration)中,它至少會把一個元素擺到它最后的位置去。
C代碼的實現如下:

下面開始單步分析,這里用一個數組的數據來分析

首先將0作為比較的基準,由于右邊所有的數據都比0大,所以數據不做 移動。接下來將8作為比較基準,從最右邊開始和8比較。此時6比8小,將6移動到8前面,其他數據依次后移。

接著在將2和8比較,2比8小,繼續將2移動到8前面,其他的數據依次后移。

這樣將8小的數據移動到8的前面,比8大的數據在8后面保持不變。移動完成后如下:

接下來比較的基準變為數字6,將比6小的數據移動到6前面。從最右邊開始查找,找到1比6小,將1移動到6前面。

然后繼續依次尋找比6小的數字,移動到6的前面,移動完成后如下:

然后比較的基準變為數字5,從最右邊開始尋找比5小的數移動到5前面。查找到的數據為2。

依次查找其他比5小的數據,移動完成后如下:
到這里可以看到數據排序已經完成了。整體運行流程如下:
下面測試一下最壞情況下的排序情況
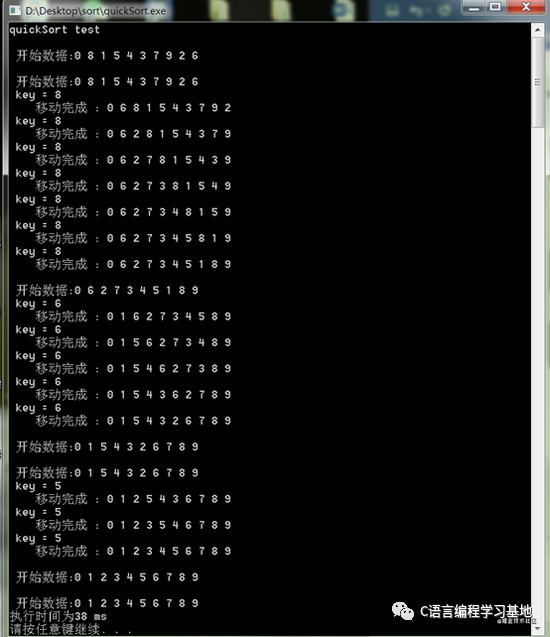
可以看到最壞情況下排序的次數并沒有增多,反而感覺還減少了。在看一下最好情況下的排序情況:
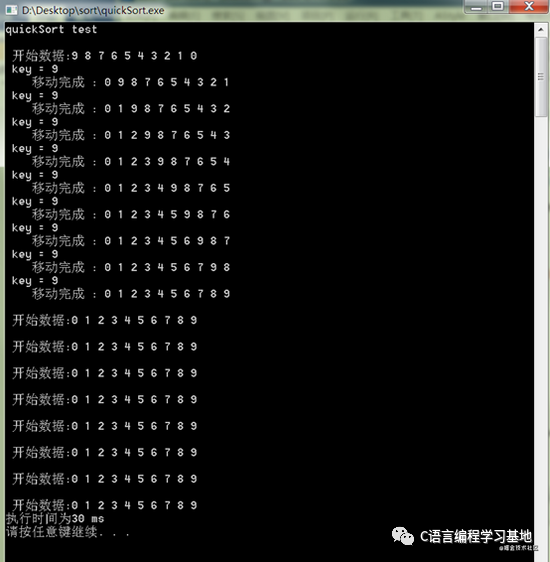
最好情況下數據也要進行比較9次。
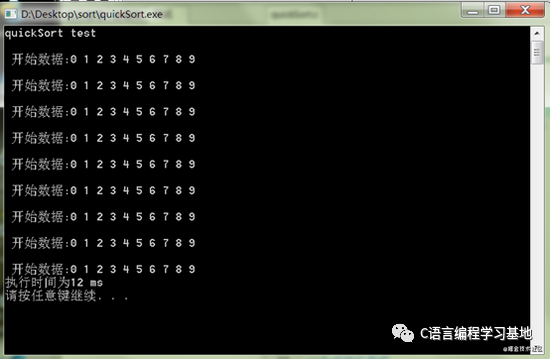
下來隨機生成一個包含10000個數字的數組,測試下執行時間。
可以看到對10000個數字排序需要的時間為120ms。

另外,對現在我們的大多數朋友來說還是學編程技術最重要!栽一棵樹最好的時間是十年前,其次是現在。對于準備學習編程的小伙伴,如果你想更好的提升你的編程核心能力(內功)不妨從現在開始!
編輯:jq
-
C語言
+關注
關注
180文章
7632瀏覽量
141941
原文標題:【數據結構】C語言排序方法——快速排序詳解!
文章出處:【微信號:cyuyanxuexi,微信公眾號:C語言編程學習基地】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
國際首創新突破!中國團隊以存算一體排序架構攻克智能硬件加速難題

Analog Devices Inc. MAX16895 監控電路特性/應用/功能圖
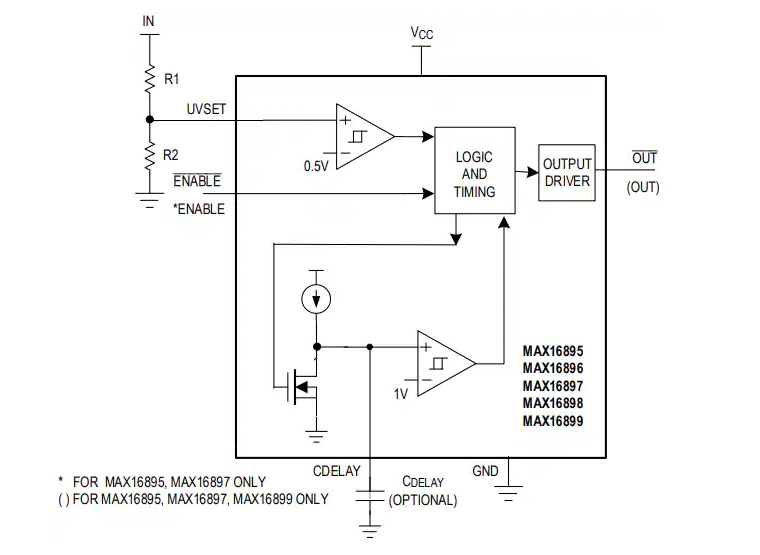
低成本電源排序器解決方案
深入理解C語言:C語言循環控制

詳解Linux sort命令之掌握排序技巧與實用案例
TimSort:一個在標準函數庫中廣泛使用的排序算法
C語言與Java語言的對比
C語言與其他編程語言的比較
時間復雜度為 O(n^2) 的排序算法

TMS320LF240x DSP的C語言和匯編代碼快速入門






 工商網監
工商網監

評論