 亞馬遜云科技提出“智能湖倉”方案,有力解決數據移動困難問題
亞馬遜云科技提出“智能湖倉”方案,有力解決數據移動困難問題
什么是數據湖?智能湖倉又是什么?亞馬遜云科技中國峰會北京站一一為你解答!
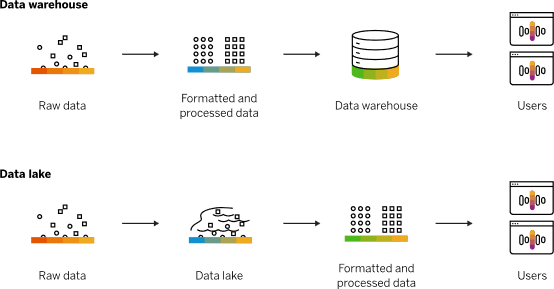
通過將不同結構、不同類型、不同來源的相關數據匯總起來并加以分析,用戶能夠得出更深刻、更豐富的洞察見解。為此,用戶需要從不同孤島中獲取所有數據、將其聚合至統一位置(也就是人們常說的「數據湖」),再以此為基礎執行分析與機器學習。
但在其他用例中,用戶也會將數據放置在其他專用存儲體系之內,例如存儲在數據倉庫內以針對結構化數據執行復雜查詢并快速獲得結果;或者存儲在搜索服務中以快速搜索/分析日志數據,進而監控生產系統的運行狀況。無論如何,要想從這些數據中獲取最佳洞見,用戶必須有能力輕松在數據湖與專用存儲系統之間移動數據。
但隨著系統中數據規模的持續增長,數據移動也變得越來越困難。為了解決這一挑戰、進而從數據中獲取最大收益,亞馬遜云科技提出了Lake House“智能湖倉”方案。
作為一類現代化數據架構,智能湖倉方法不僅強調將數據湖與數據倉庫集成起來,同時也涉及將數據湖、數據倉庫以及所有其他專用服務接入統一且連續的整體。數據湖提供對主體數據的分析環境,而專用分析服務則負責以令人滿意的速度為用戶提供具體用例支持(例如實時儀表板與日志分析功能)。

如圖所示,為真實客戶數據與常見數據遷移需求(包括數據分析服務與數據存儲間的數據遷移、由內向外、由外向內、周邊移動等情況)共同建立的智能湖倉方案。
這樣一套分層與組件化數據分析架構,使用戶可以通過正確的工具完成正確的任務,同時提供以迭代及增量方式構建架構的良好敏捷性。在添加新數據源、發現新的用例/需求以及開發新的分析方法時,亞馬遜云科技可以更靈活地調整智能湖倉中的相應組件,借此滿足當前及未來的各類需求。
對于亞馬遜云科技的這套智能湖倉架構,用戶可以把它組織成一套五層邏輯堆棧,其中各個層對應著負責滿足特定需求的專用組件。
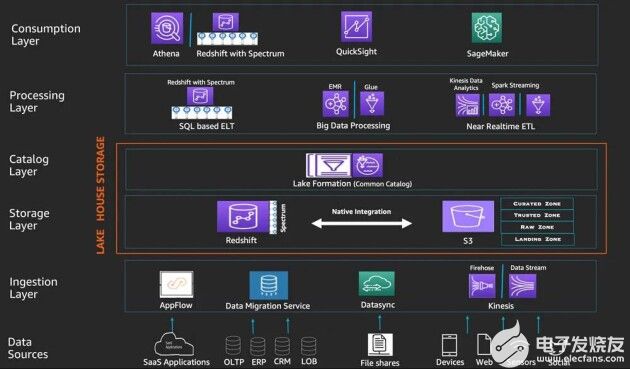
為亞馬遜云科技平臺上的智能湖倉參考架構
亞馬遜云科技的智能湖倉參考架構提供多種專用Amazon服務,能夠讓不同角色類型之間的數據消費方式互連互通,包括支持交互式SQL查詢、商務智能與機器學習等多種分析用例。這些服務使用統一的智能湖倉接口訪問存儲在Amazon S3、Amazon Redshift以及Amazon Lake Formation目錄中的所有數據與元數據。此外,各項服務還可以通過開放文件格式(例如JSON、Avro、Parquet以及ORC)使用Amazon Redshift表中存儲的平面關系數據以及S3對象中存儲的平面或復雜結構化或非結構化數據。
基于專用服務組合建立的智能湖倉架構將幫助用戶從海量數據中快速獲取面向所有用戶的洞察見解,同時充分預留升級空間,供用戶隨后續發展隨時引入新的分析方法與技術成果。
fqj
-
亞馬遜
+關注
關注
8文章
2680瀏覽量
83515
發布評論請先 登錄
相關推薦
HERE攜手亞馬遜云科技創新AI地圖解決方案,加速軟件定義汽車發展
亞馬遜云科技AI Networking解決方案回顧
亞馬遜云科技發布Amazon Bedrock新功能
亞馬遜云科技與Adobe攜手推出AEP解決方案
亞馬遜云科技與SAP推出GROW with SAP解決方案
亞馬遜云科技發布全新數據中心組件
戴爾數據湖倉助力企業數字化轉型
基于亞馬遜云科技的GROW with SAP解決方案 助力企業簡化云端ERP部署
亞馬遜云科技推出Amazon Lambda SnapStart功能
亞馬遜云科技啟動"智能家居與智能產品創新加速計劃"

亞馬遜云科技啟動“智能家居與智能產品創新加速計劃”

浪潮信息攜手天府云數據科技推出了42kW智算風冷算力倉
店匠科技選擇亞馬遜云科技為首選云服務供應商
什么是數據湖?數據湖和數據倉庫有什么區別?
揭秘湖倉一體:大數據演進的未來趨勢與影響






 工商網監
工商網監
評論