") 使用G1 GC時(shí)HBase為什么性能下降了近20%
使用G1 GC時(shí)HBase為什么性能下降了近20%
編者按:筆者在 HBase 業(yè)務(wù)場(chǎng)景中嘗試將 JDK 從 8 升級(jí)到 11,使用 G1 GC 作為垃圾回收器,但是性能下降 20%。到底是什么導(dǎo)致了性能衰退?又該如何定位解決?本文介紹如果通過(guò)使用 JFR、火焰圖等工具確定問(wèn)題,最后通過(guò)版本逐一驗(yàn)證找到了引起性能問(wèn)題的代碼。在畢昇 JDK 中率先修復(fù)問(wèn)題最后將修復(fù)推送到上游社區(qū)中。希望通過(guò)本文的介紹讓讀者了解到如何解決大版本升級(jí)中遇到的性能問(wèn)題;同時(shí)也提醒 Java 開(kāi)發(fā)者要正確地使用參數(shù)(使用前要理解參數(shù)的含義)。
HBase 從 2.3.x 開(kāi)始正式默認(rèn)的支持 JDK 11,HBase 對(duì)于 JDK 11 的支持指的是 HBase 本身可以通過(guò) JDK 11 的編譯、同時(shí)相關(guān)的測(cè)試用例全部通過(guò)。由于 HBase 依賴(lài) Hadoop 和 Zookeeper,而目前最新的 Hadoop 和 Zookeeper 尚未支持 JDK 11,所以 HBase 中仍然有一個(gè) jira 來(lái)關(guān)注 JDK 11 支持的問(wèn)題,具體參考:https://issues.apache.org/jira/browse/HBASE-22972。
G1 GC 從 JDK 9 以后就成為默認(rèn)的 GC,而且 HBase 在新的版本中也采用 G1 GC,對(duì)于 HBase 是否可以在生產(chǎn)環(huán)境中使用 JDK 11?筆者嘗試使用 JDK 11 來(lái)運(yùn)行新的 HBase,驗(yàn)證 JDK 11 是否比 JDK 8 有優(yōu)勢(shì)。
環(huán)境介紹
驗(yàn)證的方式非常簡(jiǎn)單,搭建一個(gè) 3 節(jié)點(diǎn)的 HBase 集群,安裝 HBase,采用的版本為 2.3.2,關(guān)于 HBase 環(huán)境搭建可以參考官網(wǎng)。
另外為了驗(yàn)證,使用一個(gè)額外的客戶(hù)端機(jī)器,通過(guò) HBase 自帶的 PerformanceEvaluation 工具(簡(jiǎn)稱(chēng) PE)來(lái)驗(yàn)證 HBase 讀、寫(xiě)性能。PE 支持隨機(jī)的讀、寫(xiě)、掃描,順序讀、寫(xiě)、掃描等。
例如一個(gè)簡(jiǎn)單的隨機(jī)寫(xiě)命令如下:
hbase org.apache.hadoop.hbase.PerformanceEvaluation --rows=10000 --valueSize=8000 randomWrite 5
該命令的含義是:創(chuàng)建 5 個(gè)客戶(hù)端,并且執(zhí)行持續(xù)的寫(xiě)入測(cè)試。每個(gè)客戶(hù)端每次寫(xiě)入 8000 字節(jié),共寫(xiě)入 10000 行。
PE 使用起來(lái)非常簡(jiǎn)單,是 HBase 壓測(cè)中非常流行的工具,關(guān)于 PE 更多的用法可以參考相關(guān)手冊(cè)。
本次測(cè)試為了驗(yàn)證讀寫(xiě)性能,采用如下配置:
org.apache.hadoop.hbase.PerformanceEvaluation --writeToWAL=true --nomapred --size=256 --table=Test1 --inmemoryCompaction=BASIC --presplit=50 --compress=SNAPPY sequentialWrite 120
JDK 采用 JDK 8u222 和 JDK 11.0.8 分別進(jìn)行測(cè)試,當(dāng)切換 JDK 時(shí),客戶(hù)端和 3 臺(tái) HBase 服務(wù)器統(tǒng)一切換。JDK 的運(yùn)行參數(shù)為:
-XX:+PrintGCDetails -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:-ResizePLAB
注意:這里禁止 ResizePLAB 是業(yè)務(wù)根據(jù) HBase 優(yōu)化資料設(shè)置。
測(cè)試結(jié)果:JDK 11 性能下降
通過(guò) PE 進(jìn)行測(cè)試,運(yùn)行結(jié)束有 TPS 數(shù)據(jù),表示性能。
在相同的硬件環(huán)境、相同的 HBase,僅僅使用不同的 JDK 來(lái)運(yùn)行。同時(shí)為了保證結(jié)果的準(zhǔn)確性,多次運(yùn)行,取平均值。測(cè)試結(jié)果如下:
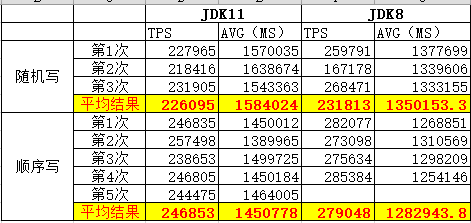
從表中可以快速地計(jì)算得到吞吐量下降,運(yùn)行時(shí)間增加。

結(jié)論:使用 G1 GC,JDK 11 相對(duì)于 JDK 8 來(lái)說(shuō)性能明顯下降。
原因分析
從 JDK 8 到 JDK 11, G1 GC 做了非常多的優(yōu)化用于提高性能。為什么 JDK 11 對(duì)于應(yīng)用者來(lái)說(shuō)更不友好?簡(jiǎn)單的總結(jié)一下從 JDK 8 到 JDK 11 做的一些比較大的設(shè)計(jì)變化,如下表所示:
優(yōu)化點(diǎn)描述
IHOP 啟發(fā)式設(shè)置IHOP 用于控制并發(fā)標(biāo)記的啟動(dòng)時(shí)機(jī),在 JDK 9 中引入該優(yōu)化,根據(jù)應(yīng)用運(yùn)行的情況,計(jì)算 IHOP 的值,確保在內(nèi)存耗盡之前啟動(dòng)并發(fā)標(biāo)記。對(duì)于性能和運(yùn)行時(shí)間理論上都是正優(yōu)化,特殊情況下可能會(huì)導(dǎo)致性能下降
Full GC 的并行話在 JDK10 中將 Full GC 從串行實(shí)現(xiàn)優(yōu)化為并行實(shí)現(xiàn),該優(yōu)化不會(huì)產(chǎn)生負(fù)面影響
動(dòng)態(tài)線程調(diào)整根據(jù) GC 工作線程的負(fù)載情況,引入動(dòng)態(tài)的線程數(shù)來(lái)處理任務(wù)。該優(yōu)化會(huì)帶來(lái)正效果,注意不是 GC 工作線程數(shù)目越多 GC 的效果越好(GC 會(huì)涉及到多線程的任務(wù)竊取和同步機(jī)制,過(guò)多的線程會(huì)導(dǎo)致性能下降)
引用集的重構(gòu)引用集處理優(yōu)化,設(shè)置處理大小、將并行修改為并發(fā)等
統(tǒng)一 JDK 8 和 JDK 11 的參數(shù),驗(yàn)證效果
由于 JDK 11 和 JDK 8 實(shí)現(xiàn)變化很多,部分功能完全不同,但是這些變化的功能一般都有參數(shù)控制,一種有效的嘗試:梳理 JDK 8 和 JDK 11 關(guān)于 G1 的參數(shù),將它們?cè)O(shè)置為相同的值,比如關(guān)閉 IHOP 的自適應(yīng),關(guān)閉線程調(diào)整等。這里簡(jiǎn)單的給出 JDK 8 和 JDK 11 不同參數(shù)的比較,如下圖所示:
將兩者參數(shù)都設(shè)置為和 JDK 8 一樣的值,重新驗(yàn)證測(cè)試,結(jié)果不變,JDK 11 性能仍然下降。
GC 日志分析,確定 JDK 11 性能下降點(diǎn)
對(duì)于 JDK 8 和 JDK 11 同時(shí)配置日志收集功能,重新測(cè)試,獲得 GC 日志。通過(guò) GC 日志分析,我們發(fā)現(xiàn)差異主要在 G1 young gc 的 object copy 階段(耗時(shí)基本在這),JDK 11 的 Young GC 耗時(shí)大概 200ms,JDK 8 的 Young GC 耗時(shí)大概 100ms,兩者設(shè)置的目標(biāo)停頓時(shí)間都是 100ms。
JDK 11 中 GC 日志片段:
JDK 8 中 GC 日志片段:
我們對(duì)整個(gè)日志做了統(tǒng)計(jì),有以下發(fā)現(xiàn):
并發(fā)標(biāo)記時(shí)機(jī)不同,混合回收的時(shí)機(jī)也不同;
單次 GC 中對(duì)象復(fù)制的耗時(shí)不同,JDK 11 明顯更長(zhǎng);
總體 GC 次數(shù) JDK 11 的更多,包括了并發(fā)標(biāo)記的停頓次數(shù);
總體 GC 的耗時(shí) JDK 11 更多。

針對(duì) Young GC 的性能劣化,我們重點(diǎn)關(guān)注測(cè)試了和 Young GC 相關(guān)的參數(shù),例如:調(diào)整 UseDynamicNumberOfGCThreads、G1UseAdaptiveIHOP 、GCTimeRatio 均沒(méi)有效果。
下面我們嘗試使用不同的工具來(lái)進(jìn)一步定位到底哪里出了問(wèn)題。
JFR 分析-確認(rèn)日志分析結(jié)果
畢昇 JDK 11 和畢昇 JDK 8 都引入了 JFR,JFR 作為 JVM 中問(wèn)題定位的新貴,我們也在該案例進(jìn)行了嘗試,關(guān)于 JFR 的原理和使用,參考本系列的技術(shù)文章:Java Flight Recorder - 事件機(jī)制詳解
JDK 11 總體信息
JDK 8 中通過(guò) JFR 收集信息。
JDK 8 總體信息
JFR 的結(jié)論和我們前面分析的結(jié)論一致,JDK 11 中中斷比例明顯高于 JDK 8。
JDK 11 中垃圾回收發(fā)生的情況
JDK 8 中垃圾回收發(fā)生的情況
從圖中可以看到在 JDK 11 中應(yīng)用消耗內(nèi)存的速度更快(曲線速率更為陡峭),根據(jù)垃圾回收的原理,內(nèi)存的消耗和分配相關(guān)。
JDK 11 中 VM 操作
JDK 8 中 VM 操作
通過(guò) JFR 整體的分析,得到的結(jié)論和我們前面的一致,確定了 Young GC 可能存在問(wèn)題,但是沒(méi)有更多的信息。
火焰圖-發(fā)現(xiàn)熱點(diǎn)
為了進(jìn)一步的追蹤 Young GC 里面到底發(fā)生了什么導(dǎo)致對(duì)象賦值更為耗時(shí),我們使用 Async-perf 進(jìn)行了熱點(diǎn)采集。關(guān)于火焰圖的使用參考本系列的技術(shù)文章:使用 perf 解決 JDK8 小版本升級(jí)后性能下降的問(wèn)題[1]
JDK 11 的火焰圖
JDK 11 GC 部分火焰圖
圖片 JDK 8 的火焰圖
JDK 8 GC 部分火焰圖
通過(guò)分析火焰圖,并比較 JDK 8 和 JDK 11 的差異,可以得到:
在 JDK 11 中,耗時(shí)主要在:
G1ParEvacuateFollowersClosure::do_void()
G1RemSet::scan_rem_set
在 JDK 8 中,耗時(shí)主要在:
G1ParEvacuateFollowersClosure::do_void()
更一步,我們對(duì) JDK 11 里面新出現(xiàn)的 scan_rem_set() 進(jìn)行更進(jìn)一步分析,發(fā)現(xiàn)該函數(shù)僅僅和引用集相關(guān),通過(guò)修改 RSet 相關(guān)參數(shù)(修改 G1ConcRefinementGreenZone ),將 RSet的處理盡可能地從Young GC的操作中移除。火焰圖中參數(shù)不再成為熱點(diǎn),但是 JDK 11 仍然性能下降。
比較 JDK 8 和 JDK 11 中 G1ParEvacuateFollowersClosure::do_void() 中的不同,除了數(shù)組處理外其他的基本沒(méi)有變化,我們將 JDK 11 此處的代碼修改和 JDK 8 完全一樣,但是性能仍然下降。
結(jié)論:雖然 G1ParEvacuateFollowersClosure::do_void() 是性能下降的觸發(fā)點(diǎn),但是此處并不是問(wèn)題的根因,應(yīng)該是其他的原因造成了該函數(shù)調(diào)用次數(shù)增加或者耗時(shí)增加。
逐個(gè)版本驗(yàn)證-最終確定問(wèn)題
我們分析了所有可能的情況,仍然無(wú)法快速找到問(wèn)題的根源,只能使用最笨的辦法,逐個(gè)版本來(lái)驗(yàn)證從哪個(gè)版本開(kāi)始性能下降。
在大量的驗(yàn)證中,對(duì)于 JDK 9、JDK 10,以及小版本等都重新做了構(gòu)建(關(guān)于 JDK 的構(gòu)建可以參考官網(wǎng)),我們發(fā)現(xiàn) JDK 9-B74 和 JDK 9-B73 有一個(gè)明顯的區(qū)別。為此我們分析了 JDK 9-B73 合入的代碼。發(fā)現(xiàn)該代碼和 PLAB 的設(shè)置相關(guān),為此梳理了所有 PLAB 相關(guān)的變動(dòng):
B66 版本為了解決 PLAB size 獲取不對(duì)的問(wèn)題(根據(jù) GC 線程數(shù)量動(dòng)態(tài)調(diào)整,但是開(kāi)啟 UseDynamicNumberOfGCThreads 后該值有問(wèn)題,默認(rèn)是關(guān)閉)修復(fù)了 bug。具體見(jiàn) jira:Determining the desired PLAB size adjusts to the the number of threads at the wrong place[2]
B74 發(fā)現(xiàn)有問(wèn)題(desired_plab_sz 可能會(huì)有相除截?cái)鄦?wèn)題和沒(méi)有對(duì)齊的問(wèn)題),重新修改,具體見(jiàn) 8079555: REDO - Determining the desired PLAB size adjusts to the the number of threads at the wrong place[3]
B115 中發(fā)現(xiàn) B74 的修改,動(dòng)態(tài)調(diào)整 PLAB大小后,會(huì)導(dǎo)致很多情況 PLAB過(guò)小(大概就是不走 PLAB,走了直接分配),頻繁的話會(huì)導(dǎo)致性能大幅下降,又做了修復(fù) Net PLAB size is clipped to max PLAB size as a whole, not on a per thread basis[4]
重新修改了代碼,打印 PLAB 的大小。對(duì)比后發(fā)現(xiàn) desired_plab_sz 大小,在性能正常的版本中該值為 1024 或者 4096(分別是 YoungPLAB 和 OLDPLAB),在性能下降的版本中該值為 258。由此確認(rèn) desired_plab_sz 不正確的計(jì)算導(dǎo)致了性能下降。
PALB 為什么會(huì)引起性能下降?
PLAB 是 GC 工作線程在并行復(fù)制內(nèi)存時(shí)使用的緩存,用于減少多個(gè)并行線程在內(nèi)存分配時(shí)的鎖競(jìng)爭(zhēng)。PLAB 的大小直接影響 GC 工作線程的效率。
在 GC 引入動(dòng)態(tài)線程調(diào)整的功能時(shí),將原來(lái) PLABSize 的大小作為多個(gè)線程的總體 PLAB 的大小,將 PLAB 重新計(jì)算,如下面代碼片段:

其中 desired_plab_sz 主要來(lái)自 YoungPLABSize 和 OldPLABSIze 的設(shè)置。所以這樣的代碼修改改變了 YoungPLABSize、OldPLABSize 參數(shù)的語(yǔ)義。
另外,在本例中,通過(guò)參數(shù)顯式地禁止了 ResizePLAB 是觸發(fā)該問(wèn)題的必要條件,當(dāng)打開(kāi) ResizePLAB 后,PLAB 會(huì)根據(jù) GC 工作線程晉升對(duì)象的大小和速率來(lái)逐步調(diào)整 PLAB 的大小。
注意,眾多資料說(shuō)明:禁止 ResziePLAB 是為了防止 GC 工作線程的同步,這個(gè)說(shuō)法是不正確的,PLAB 的調(diào)整耗時(shí)非常的小。PLAB 是 JVM 根據(jù) GC 工作線程使用內(nèi)存的情況,根據(jù)數(shù)學(xué)模型來(lái)調(diào)整大小,由于模型的誤差,可能導(dǎo)致 PLAB 的大小調(diào)整不一定有人工調(diào)參效果好。如果你沒(méi)有對(duì) YoungPLABSize、OldPLABSize 進(jìn)行調(diào)優(yōu),并不建議禁止 ResizePLAB。在 HBase 測(cè)試中,當(dāng)打開(kāi) ResizePLAB 后 JDK 8 和 JDK 11 性能基本相同,也從側(cè)面說(shuō)明了該參數(shù)的使用情況。
解決方法&修復(fù)方法
由于該問(wèn)題是 JDK 9 引入,在 JDK 9, JDK 10, JDK 11, JDK 12, JDK 13, JDK 14, JDK 15, JDK 16 都會(huì)存在性能下降的問(wèn)題。
我們對(duì)該問(wèn)題進(jìn)行了修正,并提交到社區(qū),具體見(jiàn) Jira:https://bugs.openjdk.java.net/browse/JDK-8257145[5];代碼見(jiàn):https://github.com/openjdk/jdk/pull/1474[6];該問(wèn)題在 JDK 17 中被修復(fù)。
同時(shí)該問(wèn)題在畢昇 JDK 所有版本中第一時(shí)間得到解決。
當(dāng)然對(duì)于短時(shí)間內(nèi)無(wú)法切換 JDK 的同學(xué),遇到這個(gè)問(wèn)題,該如何解決?難道要等到 JDK 17?一個(gè)臨時(shí)的方法是顯式地設(shè)置 YoungPLABSize 和 OldPLABSize 的值。YoungPLABSize 設(shè)置為 YoungPLABSize* ParallelGCThreads,其中 ParallelGCThreads 為 GC 并行線程數(shù)。例如 YoungPLABSize 原來(lái)為 1024,ParallelGCThreads 為 8,在 JDK 9~16,將 YoungPLABSize 設(shè)置為 8192 即可。
其中參數(shù) ParallelGCThreads 的計(jì)算方法為:沒(méi)有設(shè)置該參數(shù)時(shí),當(dāng) CPU 個(gè)數(shù)小于等于 8, ParallelGCThreads 等于 CPU 個(gè)數(shù),當(dāng) CPU 個(gè)數(shù)大于 8,ParallelGCThreads 等于 CPU 個(gè)數(shù)的 5/8)。
小結(jié)
本文分享了針對(duì) JDK 升級(jí)后性能下降的解決方法。Java 開(kāi)發(fā)人員如果遇到此類(lèi)問(wèn)題,可以按照下面的步驟嘗試自行解決:
對(duì)齊不同 JDK 版本的參數(shù),確保參數(shù)相同,看是否可以快速重現(xiàn);
分析 GC 日志,確定是否由 GC 引起。如果是,建議將所有的參數(shù)重新驗(yàn)證,包括移除原來(lái)的參數(shù)。本例中一個(gè)最大的失誤是,在分析過(guò)程中沒(méi)有將原來(lái)業(yè)務(wù)提供的參數(shù) ResizePLAB 移除重新測(cè)試,浪費(fèi)了很多時(shí)間。如果執(zhí)行該步驟后,定位問(wèn)題可能可以節(jié)約很多時(shí)間;
使用一些工具,比如 JFR、NMT、火焰圖等。本例中嘗試使用這些工具,雖然無(wú)果,但基本上確認(rèn)了問(wèn)題點(diǎn);
最后的最后,如果還是沒(méi)有解決,請(qǐng)聯(lián)系畢昇 JDK 社區(qū)(點(diǎn)擊原文進(jìn)入社區(qū))。畢昇 JDK 社區(qū)每雙周周二舉行技術(shù)例會(huì),同時(shí)有一個(gè)技術(shù)交流群討論 GCC、LLVM 和 JDK 等相關(guān)編譯技術(shù),感興趣的同學(xué)可以添加如下微信小助手入群。
責(zé)任編輯:haq
-
JDK
+關(guān)注
關(guān)注
0文章
81瀏覽量
16592 -
Hbase
+關(guān)注
關(guān)注
0文章
27瀏覽量
11180
原文標(biāo)題:JDK 從8升級(jí)到11,使用 G1 GC,HBase 性能下降近20%。JDK 到底干了什么?
文章出處:【微信號(hào):wireless-tag,微信公眾號(hào):?jiǎn)⒚髟贫丝萍肌繗g迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
9.9萬(wàn)元行業(yè)最低售價(jià)!宇樹(shù)智能人形機(jī)器人G1發(fā)布:“每天都在升級(jí)進(jìn)化”

ADS1220 PT100采樣電路測(cè)固定電阻時(shí)數(shù)據(jù)隨時(shí)間緩慢下降是什么原因?
在ADS8584S手冊(cè)上(如下),當(dāng)開(kāi)啟OS功能時(shí),為什么這里的吞量反而下降了?
使用TLV320ADC3101設(shè)置coefficient,信號(hào)和噪聲都整體下降了是怎么回事?
用opa690與vca810搭了一個(gè)增益可控的前置運(yùn)放模塊,頻率一高它的增益卻下降了,為什么?
格科微推出高性能GC32E2圖像傳感器
HBase集群數(shù)據(jù)在線遷移方案探索
英飛凌CoolSiC? MOSFET G2,助力下一代高性能電源系統(tǒng)

宇樹(shù)科技發(fā)布Unitree G1新型人形機(jī)器人
廣泛用于4G/5G小基站、4G/5G直放站的GC080X收發(fā)機(jī)芯片
請(qǐng)問(wèn)無(wú)感BLDC的FOC控制中觀測(cè)器G1和G2參數(shù)如何確定?
sr鎖存器不定狀態(tài)怎么理解
全面提升!英飛凌推出新一代碳化硅技術(shù)CoolSiC MOSFET G2
戴爾全年P(guān)C銷(xiāo)量暴跌20%






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論