

在先前文章中,我們談到現代GPU發展出SIMT(Single Instruction Multiple Thread)的執行結構,硬件線程池的線程們有相對獨立的運行上下文,以Warp為單位分發到一組處理單元按SIMD的模式運行。
這些Warp內的線程共享同樣的PC,以鎖步的方式執行指令,但是每個線程又可以有自己的執行分支。很自然衍生的一個問題就是現代GPU如何有效的處理Branch Divergence(分支分歧)?
一方面為適應復雜圖形渲染以及通用計算的要求,GPU編程語言像其它高級語言一樣需要支持各種各樣的流控制(Flow Control)指令,比如ifswitchdoforwhile等等,這些指令都會導致分支分歧。
另一方面GPU并行計算的特點要求所有處理單元整齊劃一地執行相同指令,才能夠取得性能最大化。如何較好地解決這兩種不同要求導致的沖突,一直是GPU研究中的熱點難點問題。在這里筆者沒有能力深入探討,只是淺嘗輒止做一般介紹,主要求這個系列內容完整,不足甚至謬誤之處,請各位看官不吝指正。
一,分支分歧對性能的影響
這一節我們首先來討論下分支分歧對GPU性能的影響。以如下ifelse代碼為例,我們看下GPU一般是如何來處理分支分歧的?
if (cond) {。。。} else {。。。}
假設一個Warp中有16個線程判斷條件為真,另外16個線程條件為假,所以一半線程會執行if中的語句,另一半線程執行else中的語句。這看起來像個悖論,我們知道Warp中的線程同一時刻只能執行相同的指令。
實際上遇到分支分歧時GPU會順序執行每個分支路徑,而禁用不在此路徑上的線程,直到所有有線程使能的分支路徑都走完,線程再重新匯合到同一執行路徑。每個分支都有些線程不干活或者干無用功,Warp實際上需要執行的指令數目大增。
假設每個分支任務量大致相同,分支分歧造成的性能損失少則原先的一半,最壞的情況如果每個線程執行分支都不一致,性能下降為最高時候的1/32。
所以無論在設計算法還是分配處理數據的時候,我們都要小心盡量避免同一個Warp內線程出現分支分歧的狀況,在遇到流控制指令的時候,最好能夠選擇同樣的路徑。
二,如何實現Reconvergence
上一節我們講了Warp的線程產生了分支分歧之后,為求性能最佳,不可能讓它們一直放任自流,最終還是要盡可能在合適時機把它們重新匯合(Reconverge)起來。但這一切是如何實現的呢?
按照參考1的說法,“The SM uses a branch synchronization stack to manage independent threads that diverge and converge” 。下面根據可接觸到的文獻我們看看大概是如何實現的,不一定跟GPU產商的實際做法一致。
我們稱這個Warp運行時棧為SIMT Stack,每個Warp擁有一個SIMT棧用于處理SIMT執行模式中的分支分歧。
首先我們需要先確定分支分歧的最近重匯合點(Reconvergence Point),一般可以選用造成分支分歧節點的直接后序支配節點(Immediate post-dominator,若控制流圖的節點n 到終結節點的每一條路徑均要經過節點d,則稱節點d后序支配節點n,如d與n之間沒有任何其他節點后序支配n,則稱節點d直接后序支配節點n)。
這可以通過編譯時的控制流分析得到。左邊是我們假想的一段GPU偽代碼,右邊是對應的控制流圖,我們假設SIMD通道的數目是4,每個節點邊上的掩碼數字代表通道上線程在該節點基本塊有沒有使能。
SIMT棧結構每個條目由執行指令PC、分支重匯合PC(RPC)和使能線程掩碼三部分組成。執行流從節點B分支分歧到節點E重新匯合時SIMT棧的更新過程。執行的時候,遇到流控制指令,我們將各個分支依次入棧,棧頂條目的PC會被送到取指單元開始相應分支路徑的處理。
只有條目掩碼中使能的線程會處于活躍狀態,當下一條PC等于棧頂條目RPC的時候,說明該分支已經到了匯合點,棧頂條目會被彈出,開始下一分支的處理以至所有執行線程匯合并共同執行接下來的指令。值得注意的是真實環境下GPU都設計有一些特殊指令來維護SIMT棧。
下圖表示上面代碼在時間軸上的執行過程,實心箭頭表示對應線程在該執行節點處于活躍狀態,反之空心箭頭代表不活躍狀態。
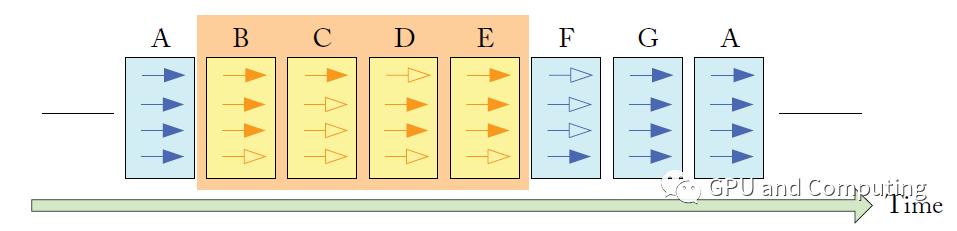
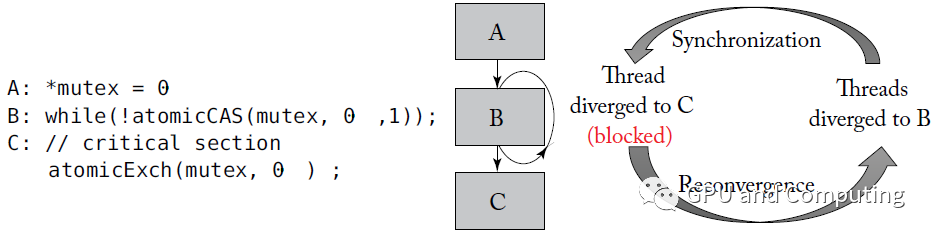
基于SIMT棧的Reconvergence方案并不完美,其中一個很大的問題是Warp內線程細粒度同步的時候很容易引發死鎖。按照Nvidia的說法,“algorithms requiring fine-grainedsharing of data guarded by locks or mutexes can easily lead to deadlock,depending on which warp the contending threads come from.”。
以下面代碼為例,某幸運線程拿到鎖之后,在最近重匯合點C等著與大部隊接頭,不幸的是它無法執行下面的Exch指令以釋放鎖,導致其它線程只能在B處空轉,形成死鎖。
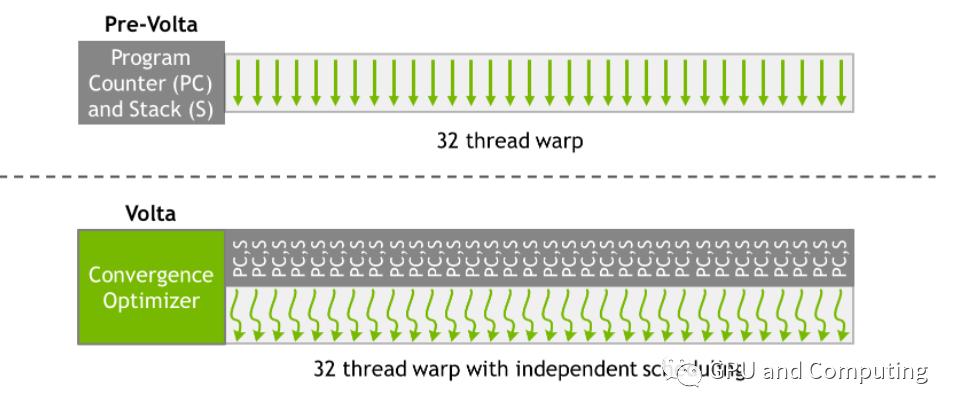
從更高的層次上理解,分支分歧導致的順序執行只發生在Warp內的線程,Warp之間卻相互不受干擾,這種不一致的處理方式對算法移植的適應性還是可預測性都會帶來影響。Nvidia從Volta GPU開始做出了改進。
提出了“Independent Thread Scheduling”的方法,使得所有線程無關所在Warp可以具有同樣并發執行能力,為此相比之前的GPU其Warp內所有線程共享PC以及運行棧,Volta GPU的線程都分別有各自的PC和運行棧,如下圖所示。
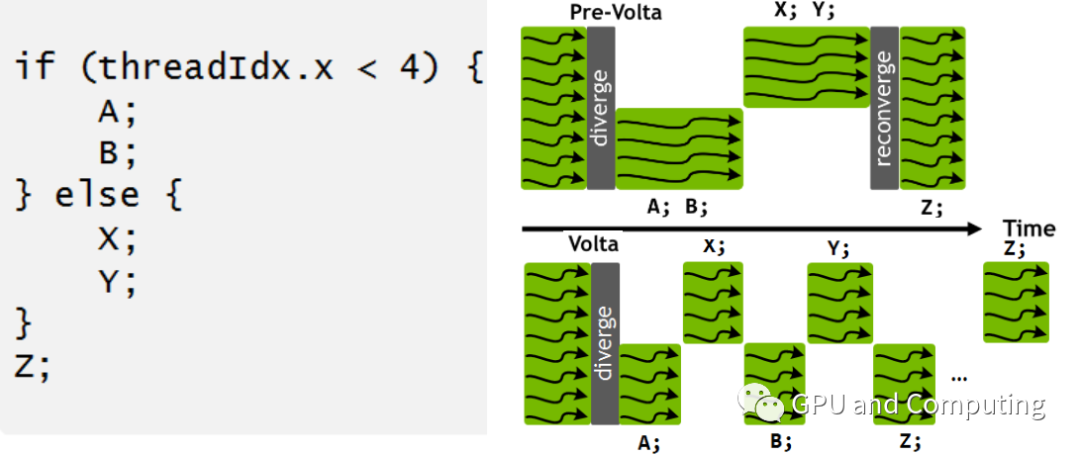
如此針對同樣的GPU程序以及分支分歧,Volta與之前的GPU相比有截然不同的調度行為。我們注意到在Volta中所有的Warp線程并沒有一起強制匯合執行Z基本塊,主要考慮到Z可能作為生產者需要提供其它執行分支依賴的的數據。
回到我們先前死鎖的例子,在Volta中這個死鎖便可迎刃而解。如果我們明顯了解相關分支不存在同步行為,為優化性能計,CUDA提供了 __syncwarp() 函數以便強制匯合。
主要參考資料:
NVIDIA Tesla: A Unified Graphics and Computing Architecture
Dynamic Warp Formation and Scheduling for Efficient GPU Control Flow
https://developer.nvidia.com/blog/inside-volta/
General-Purpose Graphics Processor Architectures
編輯:jq
-
gpu
+關注
關注
28文章
4955瀏覽量
131398 -
PC
+關注
關注
9文章
2152瀏覽量
156652 -
編程
+關注
關注
88文章
3689瀏覽量
95329
原文標題:近距離看GPU計算(3)
文章出處:【微信號:gh_6fde77c41971,微信公眾號:FPGA干貨】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】+NVlink技術從應用到原理
?為什么GPU性能效率比峰值性能更關鍵

GPU 性能原理拆解

BNC接頭技術原理與工程應用剖析:從結構到性能優化

《CST Studio Suite 2024 GPU加速計算指南》
NPU與GPU的性能對比
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片GPU
常見GPU問題及解決方法
如何提高GPU性能
如何選擇適合的GPU
GPU高性能服務器配置
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析

深入剖析石英 CMOS 振蕩器 PC3225 系列(1 to 200 MHz)的卓越性能






 工商網監
工商網監

評論