 基于有效樣本的類別不平衡損失
基于有效樣本的類別不平衡損失
導讀
使用每個類的有效樣本數量來重新為每個類的Loss分配權重,效果優于RetinaNet中的Focal Loss。
本文綜述了康奈爾大學、康奈爾科技、谷歌Brain和Alphabet公司的基于有效樣本數的類平衡損失(CB損失)。在本文中,設計了一種重新加權的方案,利用每個類的有效樣本數來重新平衡損失,稱為類別平衡損失。
1. 類別平衡問題
假設有像上面那樣的不平衡的類。head:對于索引小的類,這些類有較多的樣本。Tail:對于大索引的類,這些類的樣本數量較少。黑色實線:直接在這些樣本上訓練的模型偏向于優勢類。紅色虛線:通過反向類頻率來重新加權損失可能會在具有高類不平衡的真實數據上產生較差的性能。藍虛線:設計了一個類平衡項,通過反向有效樣本數來重新加權損失。
2. 有效樣本數量
2.1. 定義

數據間信息重疊,左:特征空間S,中:1個樣本數據的單位體積,右:數據間信息重疊
直覺上,數據越多越好。但是,由于數據之間存在信息重疊,隨著樣本數量的增加,模型從數據中提取的邊際效益會減少
左:給定一個類,將該類的特征空間中所有可能數據的集合表示為S。假設S的體積為N且N≥1。中:S子集中的每個樣本的單位體積為1,可能與其他樣本重疊。Right:從S中隨機抽取每個子集,覆蓋整個S集合。采樣的數據越多,S的覆蓋率就越好。期望的采樣數據總量隨著樣本數量的增加而增加,以N為界。
因此,將有效樣本數定義為樣本的期望體積。
這個想法是通過使用一個類的更多數據點來捕捉邊際效益的遞減。由于現實世界數據之間的內在相似性,隨著樣本數量的增加,新添加的樣本極有可能是現有樣本的近重復。另外,cnn是用大量的數據增廣來訓練的,所有的增廣實例也被認為與原始實例相同。對于一個類,N可以看作是唯一原型的數量。
2.2. 數學公式
En表示樣本的有效數量(期望體積)。為了簡化問題,不考慮部分重疊的情況。也就是說,一個新采樣的數據點只能以兩種方式與之前的采樣數據交互:完全在之前的采樣數據集中,概率為p,或完全在原來的數據集之外,的概率為1- p。
有效數字:En = (1?β^n)/(1?β),其中,β = (N? 1)/N,這個命題可以用數學歸納法證明。當E1 = 1時,不存在重疊,E1 =(1?β^1)/(1?β) = 1成立。假設已經有n?1個樣本,并且即將對第n個樣本進行采樣,現在先前采樣數據的期望體積為En ?1,而新采樣的數據點與先前采樣點重疊的概率為 p = E(n?1)/N。因此,第n個實例采樣后的期望體積為:
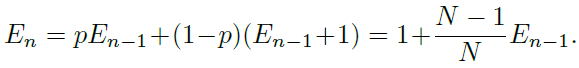
此時:
我們有:
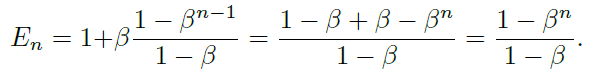
上述命題表明有效樣本數是n的指數函數。超參數β∈[0,1)控制En隨著n的增長有多快。
3. 類別平衡 Loss (CB Loss)
類別平衡(CB)loss可以寫成:
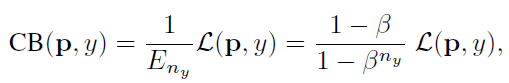
其中,ny是類別y的ground-truth的數量。β = 0對應沒有重新加權, β → 1對應于用反向頻率進行加權。
提出的有效樣本數的新概念使我們能夠使用一個超參數β來平滑地調整無重權和反向類頻率重權之間的類平衡項。
所提出的類平衡項是模型不可知的和損失不可知的,因為它獨立于損失函數L和預測類概率p的選擇。
3.1. 類別平衡的 Softmax 交叉熵損失
給定一個標號為y的樣本,該樣本的softmax交叉熵(CE)損失記為:
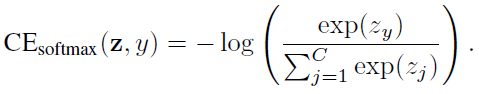
假設類y有ny個訓練樣本,類平衡(CB)softmax交叉熵損失為:
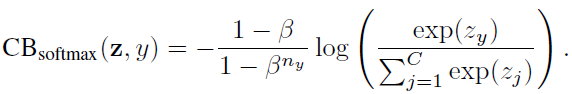
3.2. 類別平衡的 Sigmoid 交叉熵損失
當對多類問題使用sigmoid函數時,網絡的每個輸出都執行一個one-vs-all分類,以預測目標類在其他類中的概率。在這種情況下,Sigmoid不假定類之間的互斥性。由于每個類都被認為是獨立的,并且有自己的預測器,所以sigmoid將單標簽分類和多標簽預測統一起來。這是一個很好的屬性,因為現實世界的數據通常有多個語義標簽。sigmoid交叉熵(CE)損失可以寫成:
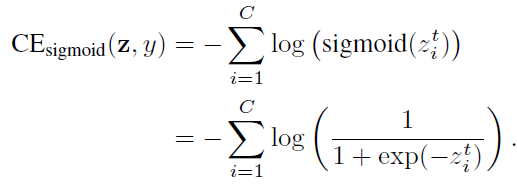
類平衡(CB) sigmoid交叉熵損失為:
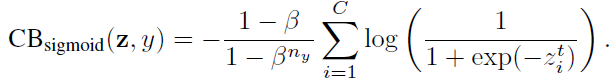
3.3. 類別平衡 Focal Loss
Focal loss (FL)是在RetinaNet中提出的,可以減少分類很好的樣本的損失,聚焦于困難的樣本。
類別平衡的 (CB) Focal Loss為:
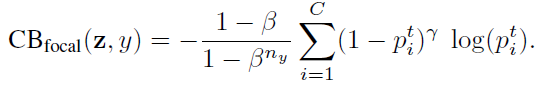
4. 實驗結果
4.1. 數據集
試驗了CIFAR-10和CIFAR-100的5個不平衡系數分別為10、20、50、100和200的長尾版本。iNaturalist 和ILSVRC是天然的類別不平衡數據集。
上面顯示了每個類具有不同不平衡因素的圖像數量。
4.2. CIFAR 數據集
loss類型的超參數搜索空間為{softmax, sigmoid, focal}, [focal loss]的超參數搜索空間為β∈{0.9,0.99,0.999,0.9999},γ∈{0.5,1.0,2.0}。在CIFAR-10上,最佳的β一致為0.9999。但在CIFAR-100上,不同不平衡因子的數據集往往有不同且較小的最優β。
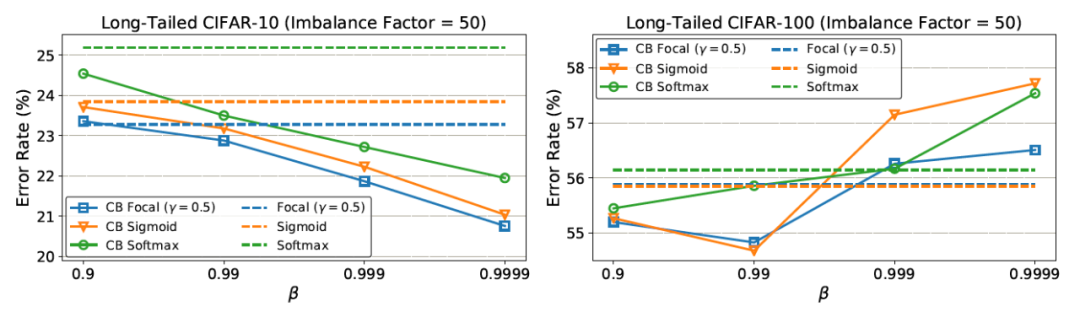
有和沒有類平衡項時的分類錯誤率
在CIFAR-10上,根據β = 0.9999重新加權后,有效樣本數與樣本數接近。這意味著CIFAR-10的最佳重權策略與逆類頻率重權類似。在CIFAR-100上,使用較大的β的性能較差,這表明用逆類頻率重新加權不是一個明智的選擇,需要一個更小的β,具有更平滑的跨類權重。例如,一個特定鳥類物種的獨特原型數量應該小于一個一般鳥類類的獨特原型數量。由于CIFAR-100中的類比CIFAR-10更細粒度,因此CIFAR-100的N比CIFAR-10小。
4.3. 大規模數據集
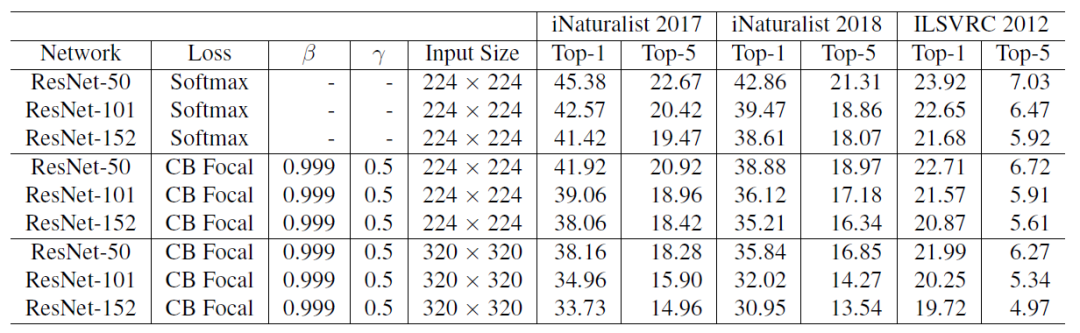
在所有數據集驗證集上,使用不同損失函數訓練的大規模數據集上的Top-1和Top-5分類錯誤率
使用了類平衡的Focal Loss,因為它具有更大的靈活性,并且發現β = 0.999和γ = 0.5在所有數據集上都獲得了合理的良好的性能。值得注意的是,使用了類別平衡的Focal Loss來代替Softmax交叉熵,ResNet-50能夠達到和ResNet-152相應的性能。
以上數字顯示類平衡的Focal Loss損失經過60個epochs的訓練后,開始顯示其優勢。
英文原文:https://medium.com/nerd-for-tech/review-cb-loss-class-balanced-loss-based-on-effective-number-of-samples-image-classification-3056a1a1a001
作者:Sik-Ho Tsang
編譯:ronghuaiyang(AI公園)
編輯:jq
-
谷歌
+關注
關注
27文章
6172瀏覽量
105625 -
數據集
+關注
關注
4文章
1208瀏覽量
24737 -
cnn
+關注
關注
3文章
353瀏覽量
22246
原文標題:CB Loss:基于有效樣本的類別不平衡損失
文章出處:【微信號:NLP_lover,微信公眾號:自然語言處理愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
電容器不平衡保護動作原因分析
LCR測試儀如何測量不平衡度?

電容電壓分配不平衡的影響

三相電流不平衡對電壓影響大嗎
三相負載不平衡會引起零序電流嗎
不平衡電流和零序電流的區別是什么
三相電流不平衡會產生零序電流嗎
軟啟動三相不平衡的解決辦法有哪些
軟啟動報三相電流不平衡怎么處理
電弧爐三相電流不平衡對補償設備的損害






 工商網監
工商網監
評論