
前段時間我在準備暑期實習嘛,這是當時面攜程的時候二面的一道問題,我一臉懵逼,趕緊道歉,不好意思不知道沒了解過,面試官又解釋說 redo log,我尋思著 redo log 我知道啊,WAL 是啥?
給面試官整無語了(滑稽),為我當時的無知道歉。后來回去百度了一下才知道,最近又在丁奇大佬的《MySQL 實戰 45 講》 中看到了 WAL,遂來寫篇文章總結下。
InnoDB 體系架構在說 WAL 之前,有必要簡單介紹下 InnoDB 存儲引擎的體系架構,方便我們理解下文,并且 redo log 也是 InnoDB 存儲引擎所特有的。
如下圖,InnoDB 存儲引擎由內存池和一些后臺線程組成:
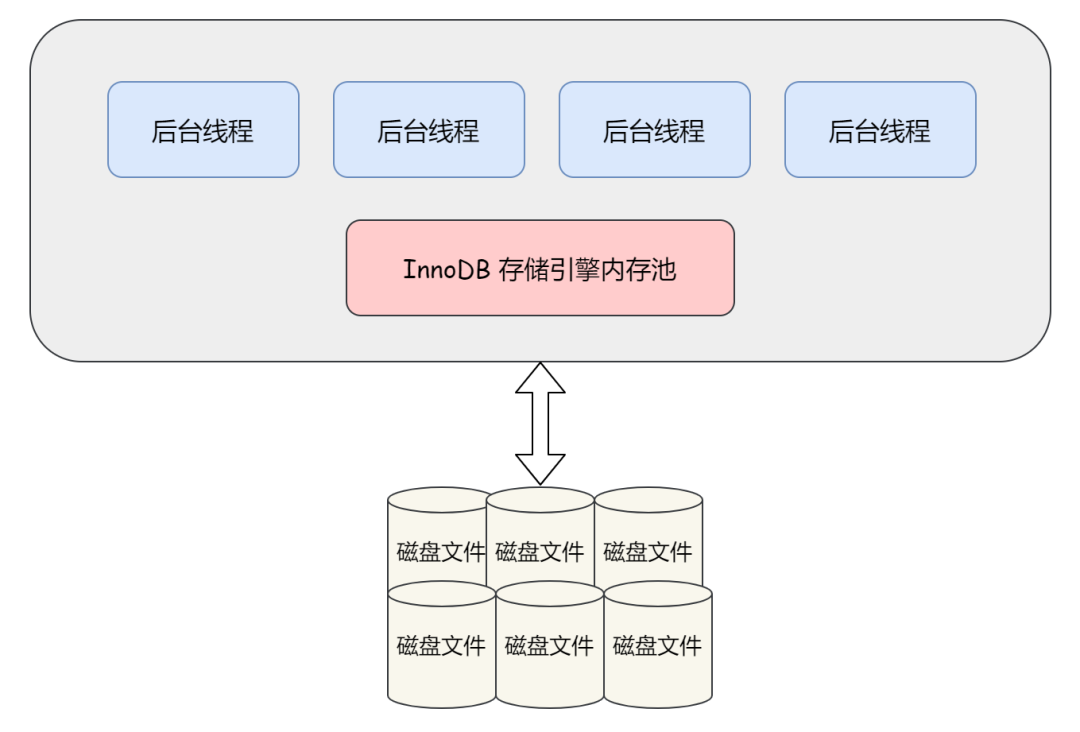
內存池
先來解釋下內存池。
首先,我們需要知道,InnoDB 存儲引擎是基于磁盤存儲的,并將其中的記錄按照頁的方式進行管理。因此可將其視為基于磁盤的數據庫系統(Disk-base Database),在這樣的系統中,眾所周知,由于 CPU 速度與磁盤速度之間的不匹配,通常會使用緩沖池技術來提高數據庫的整體性能。
所以這里的內存池也被稱為緩沖池(簡單理解為緩存就好了)。
具體來說,緩沖池其實就是一塊內存區域,在 CPU 與磁盤之間加入內存訪問,通過內存的速度來彌補磁盤速度較慢對數據庫性能的影響。
擁有了緩沖池后,“讀取頁” 操作的具體步驟就是這樣的:
首先將從磁盤讀到的頁存放在緩沖池中
下一次再讀相同的頁時,首先判斷該頁是否在緩沖池中。若在緩沖池中,稱該頁在緩沖池中被命中,直接讀取該頁。否則,讀取磁盤上的頁。
“修改頁” 操作的具體步驟就是這樣的:
首先修改在緩沖池中的頁;然后再以一定的頻率刷新到磁盤上。
所謂 ”臟頁“ 就發生在修改這個操作中,如果緩沖池中的頁已經被修改了,但是還沒有刷新到磁盤上,那么我們就稱緩沖池中的這頁是 ”臟頁“,即緩沖池中的頁的版本要比磁盤的新。
至此,綜上所述,我們可以得出這樣的結論:緩沖池的大小直接影響著數據庫的整體性能。
后臺線程
后臺線程其實最大的作用就是用來完成 “將從磁盤讀到的頁存放在緩沖池中” 以及 “將緩沖池中的數據以一定的頻率刷新到磁盤上” 這倆個操作的,當然了,還有其他的作用。以下是《MySQL 技術內幕:InnoDB 存儲引擎 - 第 2 版》對于后臺線程的描述:
后臺線程的主要作用就是刷新內存池中的數據,保證內存池中緩存的是最近的數據;此外將已修改的數據文件刷新到磁盤文件,同時保證在數據庫發生異常的情況下 InnoDB 能恢復到正常運行狀態。
另外,InnoDB 存儲引擎是多線程的模型,也就是說它擁有多個不同的后臺線程,負責處理不同的任務。這里簡單列舉下幾種不同的后臺線程:
Master Thread:主要負責將緩沖池中的數據異步刷新到磁盤,保證數據的一致性
IO Thread:在 InnoDB 存儲引擎中大量使用了 AIO(Async IO)來處理寫 IO 請求,這樣可以極大提高數據庫的性能。IO Thread 的工作主要是負責這些 IO 請求的回調(call back)處理
Purge Thread:回收已經使用并分配的 undo 頁
Page Cleaner Thread:將之前版本中臟頁的刷新操作都放入到單獨的線程中來完成。其目的是為了減輕原 Master Thread 的工作及對于用戶查詢線程的阻塞,進一步提高 InnoDB 存儲引擎的性能
redo log 與 WAL 策略上文我們提到,當緩沖池中的某頁數據被修改后,該頁就被標記為 ”臟頁“,臟頁的數據會被定期刷新到磁盤上。
倘若每次一個頁發生變化,就將新頁的版本刷新到磁盤,那么這個開銷是非常大的。并且,如果熱點數據都集中在某幾個頁中,那么數據庫的性能將變得非常差。另外,如果在從緩沖池將頁的新版本刷新到磁盤時發生了宕機,那么這個數據就不能恢復了。
所以,為了避免發生數據丟失的問題,當前事務數據庫系統(并非 MySQL 所獨有)普遍都采用了 WAL(Write Ahead Log,預寫日志)策略:即當事務提交時,先寫重做日志(redo log),再修改頁(先修改緩沖池,再刷新到磁盤);當由于發生宕機而導致數據丟失時,通過 redo log 來完成數據的恢復。這也是事務 ACID 中 D(Durability 持久性)的要求。
有了 redo log,InnoDB 就可以保證即使數據庫發生異常重啟,之前提交的記錄都不會丟失,這個能力稱為 crash-safe。
舉個簡單的例子,假設你非常熱心且 rich 的,借出去了很多錢,但是你非常 old school,不會使用電子設備并且記性不太好,所以你用一個小本本記下了所有欠你錢的人的名字和具體金額。這樣,別人還你錢的時候,你就翻出你的小本本,一頁頁地找到他的名字然后把這次還的錢扣除掉。
但是呢,其實你平常是非常忙碌的,沒辦法隨時隨地翻小本本做記錄,因此你就想出了一個主意:每當有人還你錢的時候,你就在一張白紙上記下來,然后挑個時間對照小本本把白紙上的賬目都給清了。
這就是 WAL。白紙就是 redo log,小本本就是磁盤。
當然了,redo log 可不是白紙這么簡單,一張用完了換一張就行了,這里有必要詳細解釋下。
每個 InnoDB 存儲引擎至少有 1 個重做日志文件組( redo log group),每個文件組下至少有 2 個重做日志文件(redo log file),默認的話是一個 redo log group,其中包含 2 個 redo log file:ib_logfile0 和 ib_logfile1 。
一般來說,為了得到更高的可靠性,用戶可以設置多個鏡像日志組(mirrored log groups),將不同的文件組放在不同的磁盤上,以此提高 redo log 的高可用性。在日志組中每個 redo log file 的大小一致,并以循環寫入的方式運行。
所謂循環寫入,也就是為啥我們說 redo log 不像白紙那樣用完一張換一張就行,舉個例子,如下圖,一個 redo log group,包含 3 個 redo log file:
InnoDB 存儲引擎會先寫 redo log file 0,當 file 0 被寫滿的時候,會切換至 redo log file 1,當 file 1 也被寫滿時,會切換到 redo log file 2 中,而當 file 2 也被寫滿時,會再切換到 file 0 中。
可以看出,redo log file 的大小設置對于 InnoDB 存儲引擎的性能有著非常大的影響:
redo log file 不能設置得太大,如果設置得很大,在恢復時可能需要很長的時間
redo log file 又不能設置得太小了,否則可能導致一個事務的日志需要多次切換重做日志文件
CheckPoint 技術有了 redo log 就可以高枕無憂了嗎?顯然不是這么簡單,我們仍然面臨這樣 3 個問題:
1)緩沖池不是無限大的,也就是說不能沒完沒了的存儲我們的數據等待一起刷新到磁盤
2)redo log 是循環使用而不是無限大的(也許可以,但是成本太高,同時不便于運維),那么當所有的 redo log file 都寫滿了怎么辦?
3)當數據庫運行了幾個月甚至幾年時,這時如果發生宕機,重新應用 redo log 的時間會非常久,此時恢復的代價將會非常大。
因此 Checkpoint 技術的目的就是解決上述問題:
緩沖池不夠用時,將臟頁刷新到磁盤
redo log 不可用時,將臟頁刷新到磁盤
縮短數據庫的恢復時間
所謂 CheckPoint 技術簡單來說其實就是在 redo log file 中找到一個位置,將這個位置前的頁都刷新到磁盤中去,這個位置就稱為 CheckPoint(檢查點)。
針對上面這三點我們依次來解釋下:
1)縮短數據庫的恢復時間:當數據庫發生宕機時,數據庫不需要重做所有的日志,因為 Checkpoint 之前的頁都已經刷新回磁盤。故數據庫只需對 Checkpoint 后的 redo log 進行恢復就行了。這顯然大大縮短了恢復的時間。
2)緩沖池不夠用時,將臟頁刷新到磁盤:所謂緩沖池不夠用的意思就是緩沖池的空間無法存放新讀取到的頁,這個時候 InnoDB 引擎會怎么辦呢?LRU 算法。InnoDB 存儲引擎對傳統的 LRU 算法做了一些優化,用其來管理緩沖池這塊空間。
總的思路還是傳統 LRU 那套,具體的優化細節這里就不再贅述了:即最頻繁使用的頁在 LRU 列表(LRU List)的前端,最少使用的頁在 LRU 列表的尾端;當緩沖池的空間無法存放新讀取到的頁時,將首先釋放 LRU 列表中尾端的頁。這個被釋放出來(溢出)的頁,如果是臟頁,那么就需要強制執行 CheckPoint,將臟頁刷新到磁盤中去。
3)redo log 不可用時,將臟頁刷新到磁盤:
所謂 redo log 不可用就是所有的 redo log file 都寫滿了。但事實上,其實 redo log 中的數據并不是時時刻刻都是有用的,那些已經不再需要的部分就稱為 ”可以被重用的部分“,即當數據庫發生宕機時,數據庫恢復操作不需要這部分的 redo log,因此這部分就可以被覆蓋重用(或者說被擦除)。
舉個例子來具體解釋下:一組 4 個文件,每個文件的大小是 1GB,那么總共就有 4GB 的 redo log file 空間。write pos 是當前 redo log 記錄的位置,隨著不斷地寫入磁盤,write pos 也不斷地往后移,就像我們上文說的,寫到 file 3 末尾后就回到 file 0 開頭。CheckPoint 是當前要擦除的位置(將 Checkpoint 之前的頁刷新回磁盤),也是往后推移并且循環的:
write pos 和 CheckPoint 之間的就是 redo log file 上還空著的部分,可以用來記錄新的操作。如果 write pos 追上 CheckPoint,就表示 redo log file 滿了,這時候不能再執行新的更新,得停下來先覆蓋(擦掉)一些 redo log,把 CheckPoint 推進一下。
綜上所述,Checkpoint 所做的事情無外乎是將緩沖池中的臟頁刷新到磁盤。不同之處在于每次刷新多少頁到磁盤,每次從哪里取臟頁,以及什么時間觸發 Checkpoint。在 InnoDB 存儲引擎內部,有兩種 Checkpoint,分別為:
Sharp Checkpoint:發生在數據庫關閉時將所有的臟頁都刷新回磁盤,這是默認的工作方式,參數 innodb_fast_shutdown=1
Fuzzy Checkpoin:InnoDB 存儲引擎內部使用這種模式,只刷新一部分臟頁,而不是刷新所有的臟頁回磁盤。關于 Fuzzy CheckPoint 具體的情況這里就不再贅述了。
有了 bin log 為什么還需要 redo log?前文我們講過,MySQL 架構可以分成倆層,一層是 Server 層,它主要做的是 MySQL 功能層面的事情;另一層就是存儲引擎,負責存儲與提取相關的具體事宜。
redo log 是 InnoDB 引擎特有的日志,而 Server 層也有自己的日志,包括錯誤日志(error log)、二進制日志(binlog)、慢查詢日志(slow query log)、查詢日志(log)。
其他三個日志顧明思意都挺好理解的,需要解釋的就是 binlog(二進制日志,binary log),它記錄了對 MySQL 數據庫執行更改的所有操作,但是不包括 SELECT 和 SHOW 這類操作,因為這類操作對數據本身并沒有修改。也就是說,binlog 是邏輯日志,記錄的是這個語句的原始邏輯,比如 “給 ID=1 這一行的 a 字段加 1”。
可以看出來,binlog 日志只能用于歸檔,因此 binlog 也被稱為歸檔日志,顯然如果 MySQL 只依靠 binlog 等這四種日志是沒有 crash-safe 能力的,所以為了彌補這種先天的不足,得益于 MySQL 可插拔的存儲引擎架構,InnoDB 開發了另外一套日志系統 — 也就是 redo log 來實現 crash-safe 能力。
這就是為什么有了 bin log 為什么還需要 redo log 的答案。
回顧下 redo log 存儲的東西,可以發現 redo log 是物理日志,記錄的是 “在某個數據頁上做了什么修改”。
另外,還有一點不同的是:binlog 是追加寫入的,就是說 binlog 文件寫到一定大小后會切換到下一個,并不會覆蓋以前的日志;而 redo log 是循環寫入的。
編輯:jq
-
緩沖器
+關注
關注
6文章
2037瀏覽量
46587 -
存儲
+關注
關注
13文章
4502瀏覽量
87063 -
磁盤
+關注
關注
1文章
388瀏覽量
25652 -
AIO
+關注
關注
1文章
62瀏覽量
10172
原文標題:攜程二面:講講 MySQL 中的 WAL 策略和 CheckPoint 技術
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
ARM Mali GPU 深度解讀
Arm 公司面向 PC 市場的 ?Arm Niva? 深度解讀
兆易創新人形機器人方案 深度解讀
英偉達Cosmos-Reason1 模型深度解讀

使用插件將Excel連接到MySQL/MariaDB
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
MySQL數據庫的安裝

MySQL編碼機制原理

解讀MIPI A-PHY與車載Serdes芯片技術與測試
華納云:如何修改MySQL的默認端口






 工商網監
工商網監

評論