 innodb究竟是如何存數據的
innodb究竟是如何存數據的
前言如果你使用過mysql數據庫,對它的存儲引擎:innodb,一定不會感到陌生。
眾所周知,在mysql5以前,默認的存儲引擎是:myslam。但mysql5之后,默認的存儲引擎已經變成了:innodb,它是我們建表的首選存儲引擎。
那么,問題來了:
innodb底層是如何存儲數據的?
表中有哪些隱藏列?
用戶記錄之間是如何關聯起來的?
如果你想知道上面三個問題的答案,那么,請繼續往下面看。
本文主要包含如下內容:
1.磁盤or內存?1.1 磁盤數據對系統來說是非常重要的東西,比如:用戶的身份證、手機號、銀行號、會員過期時間、積分等等。一旦丟失,會對用戶造成很大的影響。
那么問題來了,如何才能保證這些重要的數據不丟呢?
答案:把數據存在磁盤上。
當然有人會說,如果磁盤壞了怎么辦?
那就需要備份,或者做主從了。。。
好了,打住,這不是今天的重點。
言歸正傳。
大家都知道,從磁盤上讀寫數據,至少需要兩次IO請求才能完成。一次是讀IO,另一次是寫IO。
而IO請求是比較耗時的操作,如果頻繁的進行IO請求勢必會影響數據庫的性能。
那么,如何才能解決數據庫的性能問題呢?
1.2 內存把數據存在寄存器?
沒錯,操作系統從寄存器中讀取數據是最快的,因為它離CPU最近。
但是寄存器有個非常致命的問題是:它只能存儲非常少量的數據,設計它的目的主要是用來暫存指令和地址,并非存儲大量用戶數據的。
這樣看來,只能把數據存在內存中了。
因為內存同樣能滿足我們,快速讀取和寫入數據的需求,而且性能是非常可觀的,只是比較寄存器稍稍慢了一丟丟而已。
不過有個讓人討厭的地方是,內存相對于磁盤來說,是更加昂貴的資源。通常情況下,500G或者1T的磁盤,是很常見的。但你有聽說過有500G的內存嗎?別人會以為你瘋了。內存大小討論的數量級一般是16G或32G。
內存可以存儲一些用戶數據,但無法存儲所有的用戶數據,因為如果數據量太大了,它可能還是存不下。
此外,即使用戶數據能剛好存在內存,以后萬一有一天,數據庫服務器或者部署節點掛了,或者重啟了,數據不就丟了?
怎么做,才能不會因為異常情況,而丟數據。同時,又能保證數據的讀寫速度呢?
2.數據頁我們可以把一批數據放在一起。
寫操作時,先將數據寫到內存的某個批次中,然后再將該批次的數據一次性刷到磁盤上。如下圖所示:
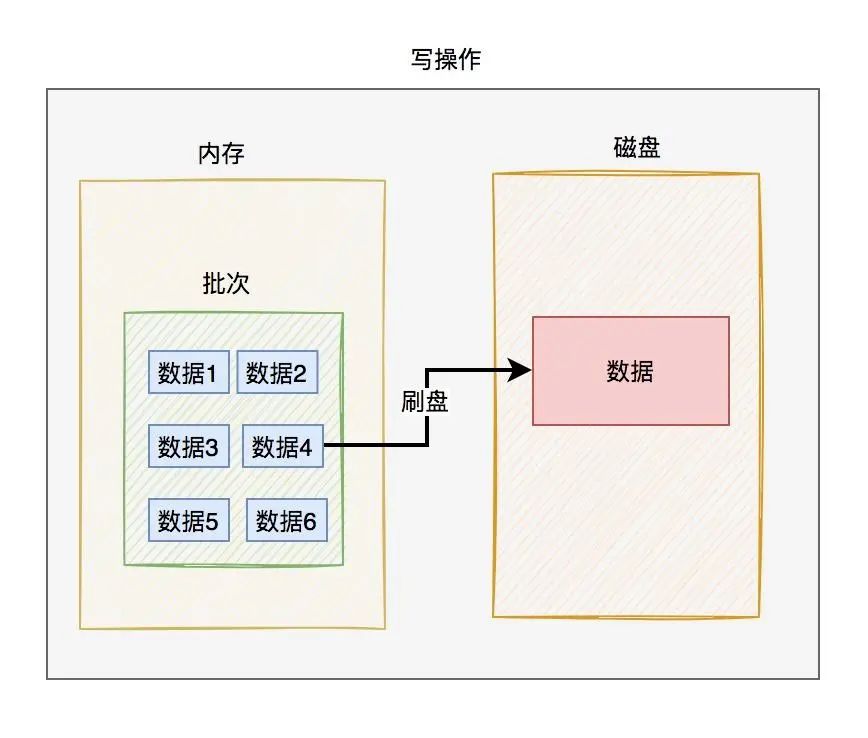
讀操作時,從磁盤上一次讀一批數據,然后加載到內存當中,以后就在內存中操作。
將內存中的數據刷到磁盤,或者將磁盤中的數據加載到內存,都是以批次為單位,這個批次就是我們常說的:數據頁。
當然innodb中存在多種不同類型的頁,數據頁只是其中一種,我們在這里重點介紹一下數據頁。
那么問題來了,什么是數據頁?
數據頁主要是用來存儲表中記錄的,它在磁盤中是用雙向鏈表相連的,方便查找,能夠非常快速得從一個數據頁,定位到另一個數據頁。
很多時候,由于我們表中的數據比較多,在磁盤中可能存放在多個數據頁當中。
有一天,我們要根據某個條件查詢數據時,需要從一個數據頁找到另一個數據頁,這時候的雙向鏈表就派上大用場了。
通常情況下,單個數據頁默認的大小是16kb。當然,我們也可以通過參數:innodb_page_size,來重新設置大小。不過,一般情況下,用它的默認值就夠了。
好吧,數據頁的整體結構已經搞明白了。
那么,單個數據頁包含哪些內容呢?
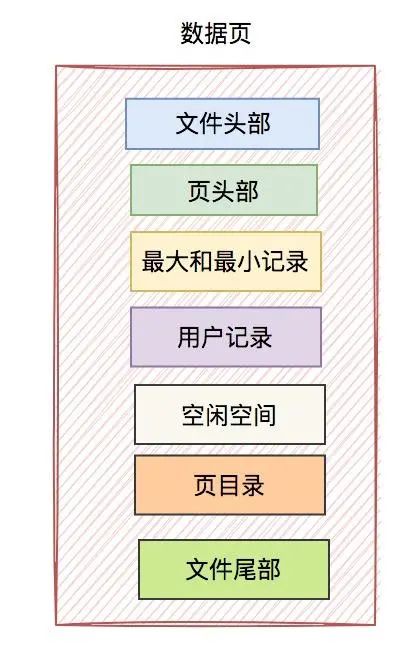
從上圖中可以看出,數據頁主要包含如下幾個部分:
文件頭部
頁頭部
最大和最小記錄
用戶記錄
空閑空間
頁目錄
文件尾部
3.用戶記錄對于新申請的數據頁,用戶記錄是空的。當插入數據時,innodb會將一部分空閑空間分配給用戶記錄。
用戶記錄是innodb的重中之重,我們平時保存到數據庫中的數據,就存儲在它里面。那么,它里面又包含哪些內容呢?你不好奇嗎?
其實在innodb支持的數據行格式有四種:
compact行格式
redundant行格式
dynamic行格式
compressed行格式
我們以compact行格式為例:
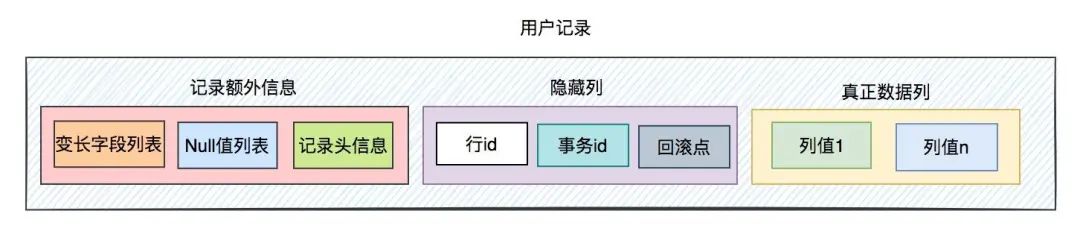
一條用戶記錄主要包含三部分內容:
記錄額外信息,它包含了變長字段、null值列表和記錄頭信息。
隱藏列,它包含了行id、事務id和回滾點。
真正的數據列,包含真正的用戶數據,可以有很多列。
下面讓我們一起了解一下這些內容。
3.1 額外信息額外信息并非真正的用戶數據,它是為了輔助存數據用的。
3.1.1 變長字段列表
有些數據如果直接存會有問題,比如:如果某個字段是varchar或text類型,它的長度不固定,可以根據存入數據的長度不同,而隨之變化。
如果不在一個地方記錄數據真正的長度,innodb很可能不知道要分配多少空間。假如都按某個固定長度分配空間,但實際數據又沒占多少空間,豈不是會浪費?
所以,需要在變長字段中記錄某個變長字段占用的字節數,方便按需分配空間。
3.1.2 null值列表
數據庫中有些字段的值允許為null,如果把每個字段的null值,都保存到用戶記錄中,顯然有些浪費存儲空間。
有沒有辦法只簡單的標記一下,不存儲實際的null值呢?
答案:將為null的字段保存到null值列表。
在列表中用二進制的值1,表示該字段允許為null,用0表示不允許為null。它只占用了1位,就能表示某個字符是否為null,確實可以節省很多存儲空間。
3.1.3 記錄頭信息
記錄頭信息用于描述一些特殊的屬性。
它主要包含:
deleted_flag:即刪除標記,用于標記該記錄是否被刪除了。
min_rec_flag:即最小目錄標記,它是非葉子節點中的最小目錄標記。
n_owned:即擁有的記錄數,記錄該組索引記錄的條數。
heap_no:即堆上的位置,它表示當前記錄在堆上的位置。
record_type:即記錄類型,其中:0表示普通記錄,1表示非葉子節點,2表示Infrimum記錄, 3表示Supremum記錄。
next_record:即下一條記錄的位置。
3.2 隱藏列數據庫在保存一條用戶記錄時,會自動創建一些隱藏列。目前innodb自動創建的隱藏列有三種:
db_row_id,即行id,它是一條記錄的唯一標識。
db_trx_id,即事務id,它是事務的唯一標識。
db_roll_ptr,即回滾點,它用于事務回滾。
如果表中有主鍵,則用主鍵做行id,無需額外創建。如果表中沒有主鍵,假如有不為null的unique唯一鍵,則用它做為行id,同樣無需額外創建。
如果表中既沒有主鍵,又沒有唯一鍵,則數據庫會自動創建行id。
也就是說在innodb中,隱藏列中事務id和回滾點是一定會被創建的,但行id要根據實際情況決定。
3.3 真正數據列真正的數據列中存儲了用戶的真實數據,它可以包含很多列的數據。這個比較簡單,沒有什么好多說的。
3.4 用戶記錄是如何相連的?通過上面介紹的內容,大家對一條用戶記錄是如何存儲的,應該有了一定的認識。
但問題來了,一條用戶記錄和另一條用戶記錄是如何相連的,innodb是怎么知道,某條記錄的下一條記錄是誰?
答案是:用前面提到過的, 記錄額外信息 》 記錄頭信息 》下一條記錄的位置。
多條用戶記錄之間通過下一條記錄的位置,組成了一個單向鏈表。這樣就能從前往后,找到所有的記錄了。
4.最大和最小記錄從上面可以得知,在一個數據頁當中,如果存在多條用戶記錄,它們是通過下一條記錄的位置相連的。
不過有個問題:如果才能快速找到最大的記錄和最小的記錄呢?
這就需要在保存用戶記錄的同時,也保存最大和最小記錄了。
最大記錄保存到Supremum記錄中。
最小記錄保存在Infimum記錄中。
在保存用戶記錄時,數據庫會自動創建兩條額外的記錄:Supremum 和 Infimum。
從圖中可以看出用戶數據是從最小記錄開始,通過下一條記錄的位置,從小到大,一步步查找,最后找到最大記錄為止。
5.頁目錄從上面可以看出,如果我們要查詢某條記錄的話,數據庫會從最小記錄開始,一條條查找所有記錄。如果中途找到了,則直接返回該記錄。如果一直找到最大記錄,還沒有找到想要的記錄,則返回空。
咋一看,沒有問題。
但如果仔細想想。
效率會不會有點低?
這不是要對整頁用戶數據進行掃描嗎?
有沒有更高效的方法?
這就需要使用頁目錄了。
說白了,就是把一頁用戶記錄分為若干組,每一組的最大記錄都保存到一個地方,這個地方就是頁目錄。每一組的最大記錄叫做槽。
由此可見,頁目錄是有多個槽組成的。
假設一頁的數據分為4組,這樣在頁目錄中,就對應了4個槽,每個槽中都保存了該組數據的最大值。
這樣就能通過二分查找,比較槽中的記錄跟需要找到的記錄的大小。如果用戶需要查找的記錄,小于當前槽中的記錄,則向上查找上一個槽。如果用戶需要查找的記錄,大于當前槽中的記錄,則向下查找下一個槽。
如此一來,就能通過二分查找,快速的定位需要查找的記錄了。
so easy
6.文件頭部和尾部6.1 文件頭部通過前面介紹的行記錄中下一條記錄的位置和頁目錄,innodb能非常快速的定位某一條記錄。但有個前提條件,就是用戶記錄必須在同一個數據頁當中。
如果用戶記錄非常多,在第一個數據頁找不到我們想要的數據,需要到另外一頁找該怎么辦呢?
這時就需要使用文件頭部了。
它里面包含了多個信息,但我只列出了其中4個最關鍵的信息:
頁號
上一頁頁號
下一頁頁號
頁類型
顧名思義,innodb是通過頁號、上一頁頁號和下一頁頁號來串聯不同數據頁的。如下圖所示:不同的數據頁之間,通過上一頁頁號和下一頁頁號構成了雙向鏈表。這樣就能從前向后,一頁頁查找所有的數據了。
此外,頁類型也是一個非常重要的字段,它包含了多種類型,其中比較出名的有:數據頁、索引頁(目錄項頁)、溢出頁、undo日志頁等。
6.2 文件尾部我之前提過,數據庫的數據是以數據頁為單位,加載到內存中,如果數據有更新的話,需要刷新到磁盤上。
但如果某一天比較倒霉,程序在刷新到磁盤的過程中,出現了異常,比如:進程被kill掉了,或者服務器被重啟了。
這時候數據可能只刷新了一部分,如何判斷上次刷盤的數據是完整的呢?
這就需要用到文件尾部。
它里面記錄了頁面的校驗和。
在數據刷新到磁盤之前,會先計算一個頁面的校驗和。后面如果數據有更新的話,會計算一個新值。文件頭部中也會記錄這個校驗和,由于文件頭部在前面,會先被刷新到磁盤上。
接下來,刷新用戶記錄到磁盤的時候,假設刷新了一部分,恰好程序出現異常了。這時,文件尾部的校驗和,還是一個舊值。數據庫會去校驗,文件尾部的校驗和,不等于文件頭部的新值,說明該數據頁的數據是不完整的。
7.頁頭部通過上面介紹的內容,數據頁之間能夠輕松訪問了,但剩下還有個比較重要的問題,就是記錄的狀態信息。
比如一頁數據到底保存了多條記錄,或者頁目錄到底使用了多個槽等。這些信息是實時統計,還是事先統計好了,保存到某個地方?
為了性能考慮,上面的這些統計數據,當然是先統計好,保存到一個地方。后面需要用到該數據時,再讀取出來會更好。這個保存統計數據的地方,就是頁頭部。
當然頁頭部不僅僅只保存:槽的數量、記錄條數等信息。
它還記錄了:
已刪除記錄所占的字節數
最后插入記錄的位置
最大事務id
索引id
索引層級
其實還有很多,在這里就不一一列舉了,有興趣的朋友可以找我私聊。
總結多個數據頁之間通過頁號構成了雙向鏈表。而每一個數據頁的行數據之間,又通過下一條記錄的位置構成了單項鏈表。
參考:《mysql是怎樣運行的》
編輯:jq
-
磁盤
+關注
關注
1文章
375瀏覽量
25201 -
數據庫
+關注
關注
7文章
3794瀏覽量
64362 -
MySQL
+關注
關注
1文章
804瀏覽量
26531
原文標題:innodb 是如何存數據的?
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
LoRa數據究竟是如何傳輸的?

嵌入式和人工智能究竟是什么關系?
PCM1861 INT腳究竟是輸出還是輸入?
超高頻讀寫器究竟是什么,能做什么?一文讀懂!

運放輸入偏置電流的方向是流入運放芯片還是流出運放芯片?這個怎么確定的?
請問cH340G的TX引腳電平究竟是3v還是5v?
MPLS究竟是什么?
工業物聯網究竟是什么呢?它又有哪些作用呢?
STM32擦除后數據究竟是0x00還是0xff ?
MOSFET的柵源振蕩究竟是怎么來的?柵源振蕩的危害什么?如何抑制
吸塵器究竟是如何替你“吃灰”的【其利天下技術】






 工商網監
工商網監
評論