 缺失值處理你確定你真的會了嗎
缺失值處理你確定你真的會了嗎
缺失值處理是一個數據分析工作者永遠避不開的話題,如何認識與理解缺失值,運用合適的方式處理缺失值,對模型的結果有很大的影響。本期Python數據分析實戰學習中,我們將詳細討論數據缺失值分析與處理等相關的一系列問題。
作為數據清洗的一個重要環節,一般從缺失值分析和缺失值處理兩個角度展開:-
缺失值分析
- 缺失值處理
Part 1
缺失值分析數據的缺失主要包括記錄的缺失和記錄中某個字段信息的缺失,兩者都會造成分析結果的不準確,以下從缺失值類型、產生的原因及影響等方面展開分析。- 缺失值類型
2、完全隨機丟失(MCAR,Missing Completely at Random)
數據的缺失是完全隨機的,不依賴于任何不完全變量或完全變量,不影響樣本的無偏性。3、非隨機丟失(MNAR,Missing not at Random)
數據的缺失與不完全變量自身的取值有關。正確的理解和判斷缺失值的類型,對工作中對缺失值分析和處理帶來很大對便利,但因沒有一套成熟但缺失值類型判斷方法,大多考經驗處理,這里不作過多闡述。- 缺失值成因
1、信息暫時無法獲取、獲取信息代價太大;
2、信息因人為因素沒有被記錄、遺漏或丟失;3、部分對象或某些屬性不可用或不存在;4、信息采集設備故障、存儲介質、傳輸媒體或其他物理原因造成的數據丟失。- 缺失值影響
1、使系統丟失大量的有用信息;
2、使系統中所表現出的不確定性更加顯著,系統中蘊涵的確定性成分更難把握;3、包含空值的數據會使數據挖掘過程陷入混亂,導致不可靠的輸出。- 缺失值分析
data.info(); data.describe()來查看數據的基本情況。代碼:
>>>data.info()
輸出結果:
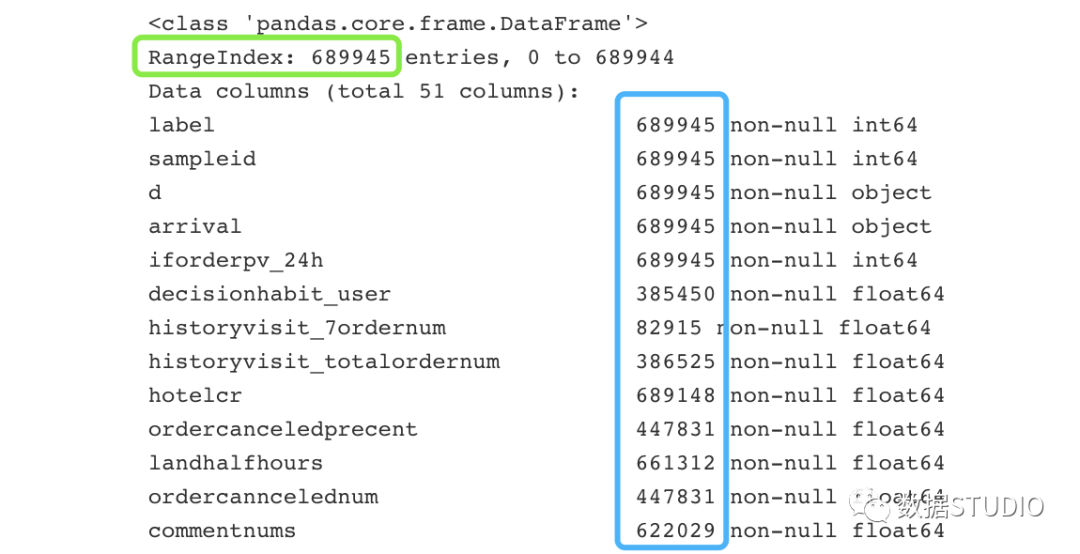
結果圖中綠色框是數據總索引數,藍色框為每個變量的總記錄數,它們的差值為每個變量的缺失值總數。代碼:
>>>data.describe()
輸出結果:
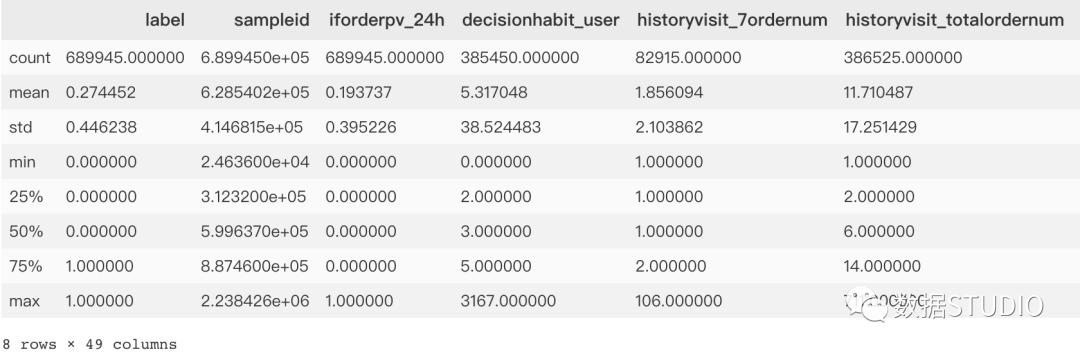
結果圖中count為每個變量的非空計數,其與總索引數的差值,即為缺失值總數。
以上方法在查看數據的總體概況下表現較佳,但用于數據缺失值分析顯得力不從心。下面介紹幾個更加便于缺失值分析的方法。
-
統計缺失值
>>>importpandasaspd
>>>missing=data.isnull().sum().reset_index().rename(columns={0:'missNum'})
>>>missing.head(10)
輸出結果:
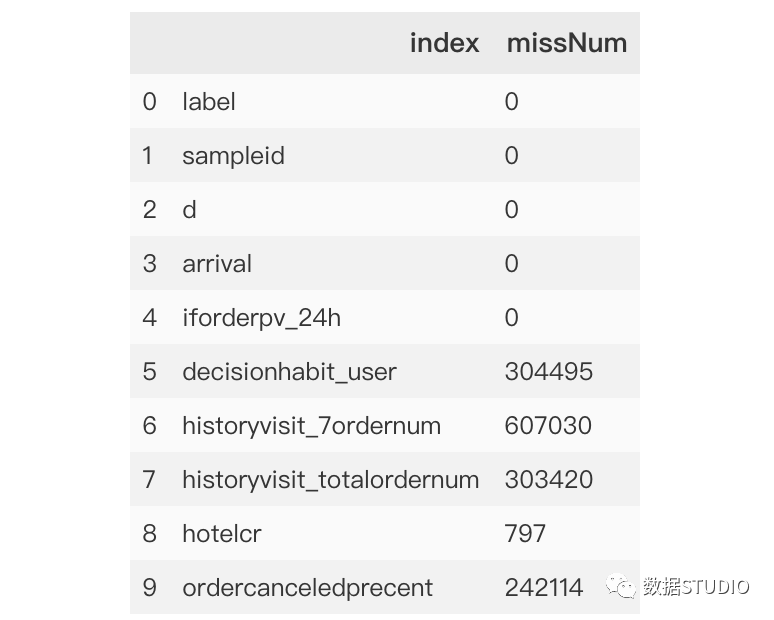
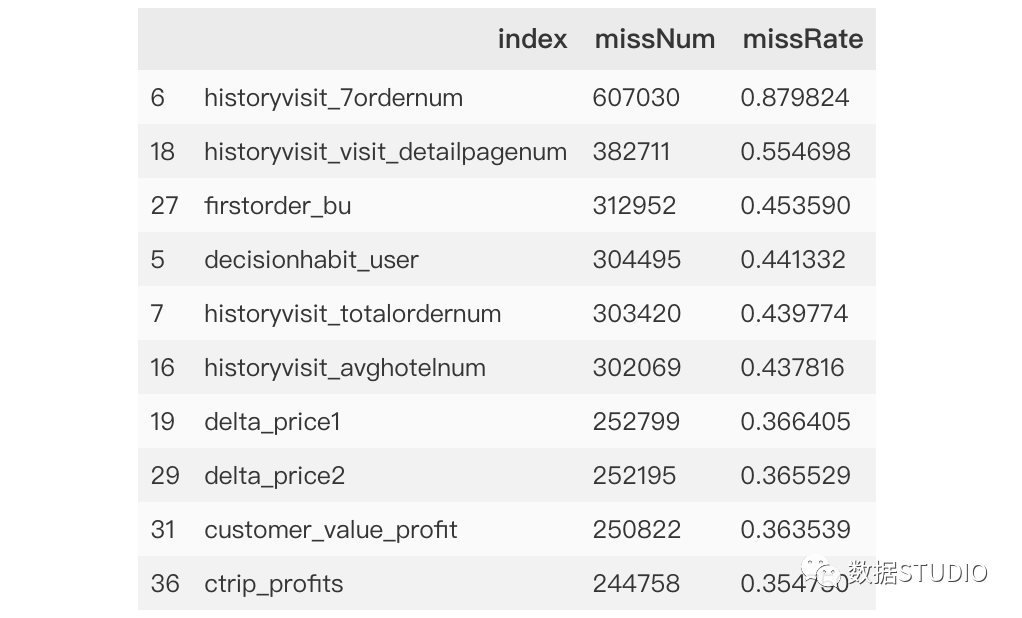
為方便展示,本例中只顯示前10個特征。從上面數據描述查看信息data.info()可以看出,本數據總計為689945條,從missNum中可以清洗看出每條特征變量的缺失情況:索引0-4為無缺失特征,索引8為缺失最少,而索引6則缺失超60萬條。
-
計算缺失值比例
>>>missing['missRate']=missing['missNum']/data.shape[0]
>>>missing.head(10)
輸出結果:data.shape[0] 得到數據記錄總數。
missing.head(10) 只顯示前10條記錄。
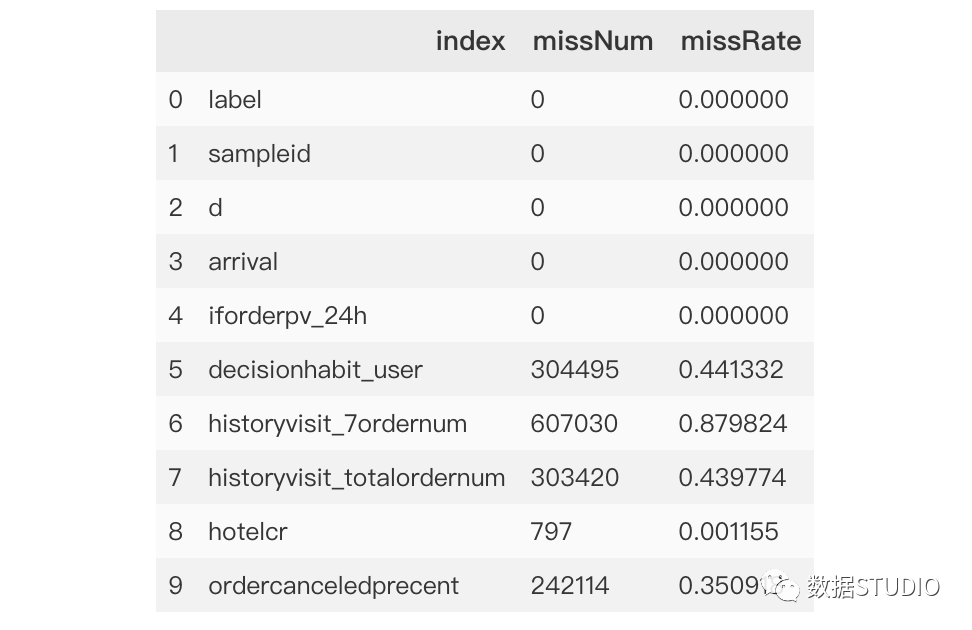
missNum 比數據總量data.shape[0] 得到缺失比值missRate,這樣更加直觀地看出缺失值相對數量,便于后續選擇合適的缺失值處理。-
按照缺失率排序顯示
代碼:
>>>miss_analy=missing[missing.missRate>0].sort_values(by='missRate',ascending=False)
>>>miss_analy.head(10)
輸出結果:miss_analy 存儲的是每個變量缺失情況的數據框。
-
缺失值可視化
matplotlib庫--條形圖
利用常規matplotlib.pyplot庫可視化出每個變量的缺失值比例,以及總體排名情況,一目了然。代碼:
>>>importmatplotlib.pyplotasplt
>>>importpylabaspl
>>>colors=['DeepSkyBlue','DeepPink','Yellow','LawnGreen','Aqua','DarkSlateGray']
>>>fig=plt.figure(figsize=(20,6))
>>>plt.bar(np.arange(miss_analy.shape[0]),list(miss_analy.missRate.values),align='center',color=colors)
>>>font={'family':'TimesNewRoman','weight':'normal','size':23,}
>>>plt.title('Histogramofmissingvalueofvariables',fontsize=20)
>>>plt.xlabel('variablesnames',font)
>>>plt.ylabel('missingrate',font)
#添加x軸標簽,并旋轉90度
>>>plt.xticks(np.arange(miss_analy.shape[0]),list(miss_analy['index']))
>>>pl.xticks(rotation=90)
#添加數值顯示
>>>forx,yinenumerate(list(miss_analy.missRate.values)):
plt.text(x,y+0.08,'{:.2%}'.format(y),ha='center',rotation=90)
>>>plt.ylim([0,1.2])
#保存圖片
>>>fig.savefig('missing.png')
>>>plt.show()
條形圖繪制參數詳解:bar(left, height, width=0.8, bottom=None, color=None, edgecolor=None, linewidth=None, tick_label=None, xerr=None, yerr=None, label = None, ecolor=None, align, log=False, **kwargs)x:sequence of scalars 傳遞數值序列,指定條形圖中x軸上的刻度值。
height:scalar or sequence of scalars傳遞標量或標量序列,指定條形圖y軸上的高度。
width:scalar or array-like, optional,default: 0.8 指定條形圖的寬度,默認為0.8.
bottom:scalar or array-like, optional, default: 0條形基的y坐標, 用于繪制堆疊條形圖。
align:{'center', 'edge'}, optional, default: 'center'
*"center": 在 x 位置上居中。*"edge": 用 x 位置對齊條的左邊。要對齊右邊緣上的條,請通過一個負的 width 和 "align='edge' "。color:scalar or array-like, optional 指定條形圖的填充色。
edgecolor:scalar or array-like, optional 指定條形圖的邊框色。
linewidth:scalar or array-like, optional 指定條形圖邊框的寬度,如果指定為0,表示不繪制邊框。
tick_label:string or array-like,optional 指定條形圖的刻度標簽。
xerr,yerr:scalar or array-like of shape(N,) or shape(2,N), optional,defaultNone
如果 not None,表示在條形圖的基礎上添加誤差棒;值是相對于數據 +/- 誤差棒大小;*標量: 對稱的+/- 誤差棒值為所有條;*shape(N,): 每個bar對稱+/- 誤差棒值;*shape(2,n): 為每個bar分別設置-和+ 誤差棒值。第一行包含較低的錯誤,第二行包含上的錯誤。* None:沒有錯誤。(默認)label:string or array-like, optional 指定條形圖的標簽,一般用以添加圖例。
ecolor:scalar or array-like, optional, default: 'black'ecolor 指定條形圖誤差棒的顏色。*align:指定x軸刻度標簽的對齊方式,默認為'center',表示刻度標簽居中對齊,如果設置為'edge',則表示在每個條形的左下角呈現刻度標簽。
log:bool, optional, default: False 是否對坐標軸進行log變換。
**kwargs 關鍵字參數,用于對條形圖進行其他設置,如透明度等。
missingno庫--矩陣圖、條形圖、熱圖、樹狀圖
mssingno
- 矩陣圖
代碼:
>>>importmissingnoasmsno
>>>msno.matrix(data,labels=True)
矩陣圖繪制參數詳解:msno.matrix(df,filter=None, n=0, p=0, sort=None, figsize=(25, 10), width_ratios=(15, 1), color=(0.25, 0.25, 0.25), fontsize=16, labels=None, sparkline=True, inline=False, freq=None, ax=None)df:DataFrame, default None 被映射的
"DataFrame"。filter: str, default None 用于熱圖的濾鏡。可以是
"top","bottom",或"None"(默認)之一。n:int, default 0過濾后的數據格式中包含的最大列數。
P:int, default 0過濾后的數據框中列的最大填充百分比。
sort:str, default None 要應用的行排序順序。可以是
"ascending"、"descending",或"None"(默認)。figsize:tuple, default (25, 10) 顯示的圖形的大小。
fontsize:int, default 16圖形的字體大小。
labels:list, default None是否顯示列名。如果有的話,當數據列數為50列或更少默認為基礎數據標簽,超過50列時不使用標簽。
sparkline:bool default True 是否顯示
sparkline。width_ratios:tuple default (15,1)矩陣的寬度與
sparkline的寬度之比。如果"sparkline=False",則不執行任何操作。color:default (0.25,0.25,0.25) 填充欄的顏色。
實際使用中,直接使用默認值即能滿足大部分情況下的需求。如常用的參數labels能夠根據數據標簽的數量自動選擇參數值。
-
條形圖
---- 是針對標簽列缺失值的簡單可視化
代碼:
>>>msno.bar(data.iloc[:,0:18])#使用默認參數即可
矩陣圖繪制參數簡介:
msno.bar(df, figsize=(24, 10), fontsize=16, labels=None, log=False, color='dimgray', inline=False, filter=None, n=0, p=0, sort=None, ax=None,)從參數列表中可以看出,條形圖與矩陣圖參數類似,其中參數
inline將在后面的版本中刪除,可以忽略。"The 'inline' argument has been deprecated, and will be removed in a future version"
missingno的條形圖與matplotlib條形圖有異曲同工之秒:封裝的庫,使用更加方便,既能看出缺失值數量,又能看出缺失值對百分比。可通過參數對特征變量按照缺失值缺失情況排序顯示。代碼:
>>>msno.bar(data.iloc[:,0:18],sort='descending')
細心的讀者不難看出,此圖與上圖(未排序)的主題風格并不相同,可利用matplotlib.pyplot來設置主題:
>>>importmatplotlib.pyplotasplt
>>>plt.style.use('seaborn')
>>>%matplotlibinline
- 熱圖
----相關性熱圖措施無效的相關性:一個變量的存在或不存在如何強烈影響的另一個的存在。
代碼:
>>>msno.heatmap(data.iloc[:,0:13])#使用默認參數即可
輸出結果:
兩個變量的無效相關范圍從-1(如果一個變量出現,另一個肯定沒有)到0(出現或不出現的變量對彼此沒有影響)到1(如果一個變量出現,另一個肯定也是)。
數據全缺失或全空對相關性是沒有意義的,所以就在圖中就沒有了,比如date列就沒有出現在圖中。
大于-1和小于1表示有強烈的正相關和負相關,但是由于極少數的臟數據所以并不絕對,這些例外的少數情況需要在數據加工時候予以注意。
熱圖方便觀察兩個變量間的相關性,但是當數據集變大,這種結論的解釋性會變差。
-
樹狀圖
代碼:
>>>msno.dendrogram(data.iloc[:,0:18])
輸出結果:樹狀圖采用由scipy提供的層次聚類算法通過它們之間的無效相關性(根據二進制距離測量)將變量彼此相加。在樹的每個步驟中,基于哪個組合最小化剩余簇的距離來分割變量。變量集越單調,它們的總距離越接近0,并且它們的平均距離越接近零。
在0距離處的變量間能彼此預測對方,當一個變量填充時另一個總是空的或者總是填充的,或者都是空的。
樹葉的高度顯示預測錯誤的頻率。
和矩陣Matrix一樣,只能處理50個變量,但是通過簡單的轉置操作即可處理更多更大的數據集。
這樣的統計計算以及可視化基本已經看出哪些變量缺失,以及缺失比例情況,對數據即有個缺失概況。
Part 2缺失值處理
缺失值處理思路
先通過一定的方法找到缺失值,接著分析缺失值在整體樣本中的分布占比,以及缺失值是否具有顯著的無規律分布特征,即第一部分介紹到缺失值分析。然后考慮使用的模型中是否滿足缺失值的自動處理,最后決定采用那種缺失值處理方法,即接下來介紹到缺失值處理。缺失值處理?法的選擇,主要依據是業務邏輯和缺失值占比,在對預測結果的影響盡可能小的情況下,對缺失值進行處理以滿足算法需求,所以要理解每個缺失值處理方法帶來的影響,下?的缺失值處理?法沒有特殊說明均是對特征(列,變量)的處理。
- 丟棄
-
占?較多,如80%以上時,刪除缺失值所在的列如果某些行缺失值占比較多,或者缺失值所在字段是苛刻的必須有值的,刪除行。
#刪除‘col’列
>>>data.drop('col',axis=1,inplace=True)
#刪除數據表中含有空值的行
>>>data.dropna()
#丟棄某幾列有缺失值的行
>>>data.dropna(axis=0,subset=['a','b'],inplace=True)
#去掉缺失比例大于80%以上的變量
>>>data.dropna(thresh=len(data)*0.2,axis=1)
參數詳解:
data.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)inplace : bool, default False 如果為真,執行就地操作并返回None。
subset : array-like, optional 要考慮沿著其他軸的標簽,例如,如果您要刪除行,這些將是要包含的列的列表。
thresh : int, optional, default 'any' 只保留至少有thresh個非na值的行。
how : {'any', 'all'},default 'any' 確定是否從DataFrame中刪除了行或列至少有一個NA或全部NA。* 'any':如果有任何NA值,刪除行或列。* 'all':如果所有的值都是NA,刪除行或列。
axis : {0 or 'index', 1 or 'columns'}, default 0 確定包含缺失值的行或列是否為移除。* 0,或“索引”:刪除包含缺失值的行。* 1,或“columns”:刪除包含缺失值的列。
- 補全
-
占比一般,30%-80%時,將缺失值作為單獨的?個分類如果特征是連續的,則其他已有值分箱如果特征是分類的,考慮其他分類是否需要重分箱
-
- 等深分箱法(統一權重法): 將數據集按記錄(行數)分箱,每箱具有相同的記錄數(元素個數)。每箱記錄數稱為箱子深度(權重)。
- 等寬分箱法(統一區間法): 使數據集在整個屬性值的區間上平均分布,即每個箱的區間范圍(箱子寬度)是一個常量。
- 用戶自定義區間:當用戶明確希望觀察某些區間范圍內的數據時,可根據需要自定義區間。
-
占?比少,10%-30%時,一般使用模型法,基于已有的其他字段,將缺失字段作為目標變量進行預測,從而得到最為可能的不全值。連續型變量用回歸模型補全;分類變量用分類模型補全。如進行多重插補、KNN算法填充、隨機森林填補法,我們認為若干特征之間有相關性的,可以相互預測缺失值。
# interpolate()插值法,缺失值前后數值的均值,但是若缺失值前后也存在缺失,則不進行計算插補。
>>>data['a']=data['a'].interpolate()
#用前面的值替換,當第一行有缺失值時,該行利用向前替換無值可取,仍缺失
>>>data.fillna(method='pad')
#用后面的值替換,當最后一行有缺失值時,該行利用向后替換無值可取,仍缺失
>>>data.fillna(method='backfill')#用后面的值替換
B. 多重插補法
常見插值函數:牛頓插值法、分段插值法、樣條插值法、Hermite插值法、埃爾米特插值法和拉格朗日插值法,以下詳細介紹拉格朗日插值法的原理和使用。
>>>fromscipy.interpolateimportlagrange
>>>x=[1,2,3,4,7]
>>>y=[5,7,10,3,9]
>>>f=lagrange(x,y)
'numpy.lib.polynomial.poly1d'>4
#這一行是輸出a的類型,以及最高次冪。
>>>print(f)
432
0.5472x-7.306x+30.65x-47.03x+28.13
#第一行和第二行就是插值的結果,顯示出的函數。第二行的數字是對應下午的x的冪,
>>>print(f(1),f(2),f(3))
5.0000000000000077.00000000000001410.00000000000005
#此行是代入的x值,得到的結果。即用小括號f(x)的這種形式,可以直接得到計算結果。
>>>print(f[0],f[2],f[3])
28.1333333333333430.65277777777778-7.3055555555555545
#此行是提取出的系數。即可以用f[a]這種形式,來提取出來對應冪的系數。
C. KNN填充利用KNN算法填充,將目標列當做目標標簽,利用非缺失的數據進行KNN算法擬合,最后對目標標簽缺失值進行預測。(對于連續特征一般是用加權平均法,對于離散特征一般是用加權投票法)拉格朗日插值法
from scipy.interpolate import lanrange對于空間上已知的n個點(無兩點在一條直線上)可以找到一個 n-1 次多項式 ,使得多項式曲線過這個點。需滿?的假設:MAR:Missing At Random,數據缺失的概率僅和已觀測的數據相關,即缺失的概率與未知的數據無關,即與變量的具體數值無關。迭代(循環)次數可能的話超過40,選擇所有的變量甚至額外的輔助變量。
>>>fromsklearn.neighborsimportKNeighborsClassifier,KNeighborsRegressor
>>>defKNN_filled_func(X_train,y_train,X_test,k=3,dispersed=True):
..."""
...X_train為目標列中不含缺失值的數據(不包括目標列)
...y_train為不含缺失值的目標標簽
...X_test為目標列中為缺失值的數據(不包括目標列)
..."""
...ifdispersed:
...KNN=KNeighborsClassifier(n_neighbors=k,weights="distance")
...else:
...KNN=KNeighborsRegressor(n_neighbors=k,weights="distance")
...KNN.fit(X_train,y_train)
...returnX_test.index,KNN.predict(X_test)
D. 隨機森林填補法
其思想與KNN填補法類似。
>>>fromsklearn.ensembleimportRandomForestRegressor,RandomForestClassifier
>>>defRF_filled_func(X_train,y_train,X_test,k=3,dispersed=True):
..."""
...X_train為目標列中不含缺失值的數據(不包括目標列)
...y_train為不含缺失值的目標標簽
...X_test為目標列中為缺失值的數據(不包括目標列)
..."""
...ifdispersed:
...rf=RandomForestRegressor()
...else:
...rf=RandomForestClassifier()
...rf.fit(X_train,y_train)
...returnX_test.index,rf.predict(X_test)
- 占?較少,10%以下,一般使用統計法(連續型變量用均值、中位數、加權均值;分類型變量用眾數)。
-
平均值適用于近似正態分布數據,觀測值較為均勻散布均值周圍;
-
中位數適用于偏態分布或者有離群點數據,中位數是更好地代表數據中心趨勢;
-
眾數一般用于類別變量,無大小、先后順序之分。
pandas 內 df.fillna() 處理缺失值
#均值填充
>>>data['col']=data['col'].fillna(data['col'].means())
#中位數填充
>>>data['col']=data['col'].fillna(data['col'].median())
#眾數填充
>>>data['col']=data['col'].fillna(stats.mode(data['col'])[0][0])
-
sklearn.preprocessing.Imputer()處理缺失值
>>>fromsklearn.preprocessingimportImputer
>>>imr=Imputer(missing_values='NaN',strategy='mean',axis=0)
>>>imputed_data=pd.DataFrame(imr.fit_transform(df.values),columns=df.columns)
>>>imputed_data
此外還有結合實際,運用專家補全。
-
真值轉化法
認為缺失值本身以一種數據分布規律存在。將變量的實際值和缺失值都作為輸入維度參與后續數據處理和模型計算中。 -
不處理
對于一些模型對缺失值有容忍度或靈活處理方法,可不處理缺失值。如KNN、決策樹、隨機森林、神經網絡、樸素貝葉斯、DBSCAN等。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100720 -
數據
+關注
關注
8文章
7006瀏覽量
88945 -
eda
+關注
關注
71文章
2755瀏覽量
173212 -
信息采集
+關注
關注
0文章
81瀏覽量
21195 -
樸素貝葉斯
+關注
關注
0文章
12瀏覽量
3375
原文標題:缺失值處理,你真的會了嗎?
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
嘗試仿真figure68的信號調理電路如圖所示,結果顯示增益達不到計算值,為什么?
如何訓練ai大模型
干貨篇:Air780E之RS485通信篇,你學會了嗎?

spwm載波頻率和幅值怎么確定
劃重點!面試常考的ADC你真的會了嗎?

車路云協同,這次它真的來了嗎?

降價潮背后:大模型落地門檻真的降了嗎?

你真的了解駐波比嗎?到底什么是電壓駐波比?
藍牙信標室內定位算法如何確定 A,n 值

STM32H743ADC數據轉換輸出值缺失的原因?
**模電和數電的區別和聯系,你真的懂嗎?**
PLC故障排除流程圖,看完你學會了嗎?





 工商網監
工商網監
評論