 一文帶你深入了解KVM的基本原理
一文帶你深入了解KVM的基本原理
一、 概述
KVM的全稱是Kernel-based Virtual Machine,其是一種基于linux內核的采用硬件輔助虛擬化技術的全虛擬化解決方案。它最初由以色列的初創公司Qumranet開發,并在linux-2.6.20中開始被納入在linux內核,成為內核源碼的一部分。KVM自誕生之初就定位于基于硬件輔助的虛擬化來提供全虛擬化的支持,其以內核模塊的形式被加載。加載KVM模塊的linux內核相當于變成了一個Hypervisor,同時依賴linux內核提供的各種功能來實現硬件管理,擁有極高的兼容性及可擴展性。
上面提到KVM是作為一個內核模塊出現的,所以它還得借助用戶空間的程序來和用戶進行交互,這就不得不提到大名鼎鼎的QEMU了。QEMU是一套由法布里斯·貝拉(Fabrice Bellard)所編寫的以GPL許可證分發源碼的模擬處理器,在GNU/Linux平臺上使用廣泛。
其本身是一個純軟件的支持CPU虛擬化、內存虛擬化及I/O虛擬化等功能的用戶空間程序。其借助KVM提供的虛擬化支持可以將CPU、內存等虛擬化工作交由KVM處理,自己則處理大多數I/O虛擬化的功能,可以實現極高的虛擬化效率。KVM及QEMU配合使用的整體接口如圖1所示。
QEMU盡管非常的強大,但也正是應為它的強大導致其對初學者非常的不友好。這里推薦大家剛開始學習KVM時可以先學習kvm tool,這是一個基于C語言開發的KVM虛擬化工具,其代碼非常精簡易懂,同時也可以支持完整的linux虛擬化,非常適合初學者入門使用。其項目地址為https://github.com/kvmtool/kvmtool。
二、 ARM64虛擬化支持
arm最早在armv7-a引入硬件虛擬化支持。到了armv8中,arm拋棄了armv7時代的特權級,引入了全新的Exception Level(EL),其如圖2所示(armv8.4-A引入了對安全世界虛擬化的支持)。

圖2
其中4個異常等級中的EL2留給Hypervisor用于各種虛擬化功能的訪問及配置,如:stage 2轉換、EL1/EL0指令和寄存器訪問、注入虛擬異常等。
三、 CPU虛擬化
CPU被稱為計算機的大腦,是計算機系統中最核心的模塊。在沒有CPU硬件虛擬化技術之前都是使用二進制指令動態翻譯技術來實現對客戶機操作系統中執行的執行(例如qemu的軟件虛擬化),其不僅實現復雜而且效率非常低下。因此硬件虛擬化技術應運而生,為KVM的誕生創造了必要的條件。
有時Hypervisor需要模擬一些操作,例如VM里運行的軟件試圖配置處理器的一些屬性,如電源管理或是緩存一致性時。通常你不會允許VM直接配置這些屬性,因為這會打破隔離性,從而影響其他VMs。這就需要通過以陷入的方式產生異常,在異常處理程序中做相應的模擬。armv8包含一些陷入控制來幫助實現陷入(trapping) – 模擬(emulating)。如果對相應操作配置了陷入,則這種操作發生時會陷入到更高的異常級別。
例如,正常我們在執行WFI指令時會使CPU進入一個低功耗的狀態,但是對于HOST OS來說,如果讓CPU真正進入低功耗狀態,顯然會影響其他VM的運行。如果我們配置了HCR_EL2.TWI==1時,那么Guest OS在執行WFI時就會觸發EL2的異常,然后陷入Hypervisor,那么此時Hypervisor就可以將對應VCPU所處的線程調出出去,將CPU讓給其他的VCPU線程使用。
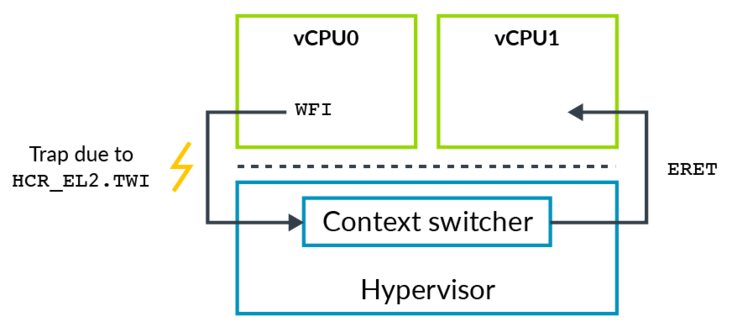
圖3
四、 內存虛擬化
內存虛擬化的目的是給虛擬客戶機操作系統提供一個從0開始的連續的地址空間,同時在多個客戶機之間實現隔離與調度。
arm主要通過Stage 2轉換來提供對內存虛擬化的支持,其允許Hypervisor控制虛擬機的內存視圖,而在這之前則是使用及其復雜的影子頁表技術來實現。Stage 2轉換可以控制虛擬機是否可以訪問特定的某一塊物理內存,以及該內存塊出現在虛擬機內存空間的位置。這種能力對于虛擬機的隔離和沙箱功能來說至關重要。
這使得虛擬機只能看到分配給它自己的物理內存。為了支持Stage 2 轉換, 需要增加一個頁表,我們稱之為Stage 2頁表。操作系統控制的頁表轉換稱之為stage 1轉換,負責將虛擬機視角的虛擬地址轉換為虛擬機視角的物理地址。而stage 2頁表由Hypervisor控制,負責將虛擬機視角的物理地址轉換為真實的物理地址。虛擬機視角的物理地址在Armv8中有特定的詞描述,叫中間物理地址(intermediate Physical Address, IPA)。
stage 2轉換表的格式和stage 1的類似,但也有些屬性的處理不太一樣,例如,判斷內存類型 是normal 還是 device的信息被直接編碼進了表里,而不是通過查詢MAIR_ELx寄存器。
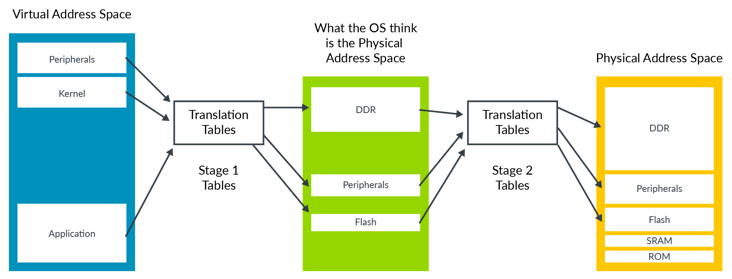
圖4
五、 I/O虛擬化
I/O設備作為一種外部設備,其虛擬化的實現相較于前面的CPU虛擬化及內存虛擬化有些不同,其目前主要有以下四種虛擬化方案。
1、 設備模擬:
在虛擬機監控器中模擬具體的I/O設備的特性,例如qemu。在KVM和qemu的組合中通過Hypervisor捕獲Guest OS的I/O請求交給用戶空間的qemu進行模擬,然后將結果再通過Hypervisor傳遞給Guest OS。這種方式能夠提供非常好的兼容性但是性能太差,同時模擬設備的功能特性支持不夠多。
2、 前后端驅動接口
在Hypervisor和Guest OS之間定義一種權限的適用于虛擬機的交互接口,比如virtio技術。這個方案相較于設備模擬在性能上有所提高,但是兼容性較差,而且在高I/O負載場景,后端驅動的CPU占用較高。
3、 設備直接分配
將一個物理設備直接分配給Guest OS使用。此方式的性能顯而易見,要比上面兩種好很多,但是需要硬件設備支持,且無法共享和動態遷移。
4、 設備共享分配
此方式是設備直接分配的一個擴展,其主要就是讓一個物理設備可以支持多個虛擬機功能接口,將不同的接口地址獨立分配給不同的Guest OS使用。如SR-IOV協議。
參考文獻:
1、《KVM實戰:原理、進階與性能調優》
2、https://segmentfault.com/a/1190000022797518
3、https://www.cnblogs.com/LoyenWang/
編輯:jq
-
ARM
+關注
關注
134文章
9087瀏覽量
367398 -
cpu
+關注
關注
68文章
10855瀏覽量
211594 -
KVM
+關注
關注
0文章
188瀏覽量
12947 -
驅動接口
+關注
關注
0文章
10瀏覽量
2617
原文標題:KVM原理簡介
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
RNN的基本原理與實現
神經網絡的基本原理
電壓比較器的基本原理和應用領域
數字源表的基本原理與結構組成
倍頻器的基本原理、分類及應用領域
5.8G WiFi和2.4G WiFi如何選擇?一文帶你深度了解

拆解FPGA芯片,帶你深入了解其原理
工業以太網的基本原理及優勢
晶振電路中電容電阻的一些基本原理和作用解析






 工商網監
工商網監
評論