") 如何制作一個(gè)簡(jiǎn)單的16位CPU 快來(lái)這里看教程
如何制作一個(gè)簡(jiǎn)單的16位CPU 快來(lái)這里看教程
如何制作一個(gè)簡(jiǎn)單的16位CPU,首先我們要明確CPU是做什么的,想必各位都比我清楚,百度的資料也很全。。。。。
如果想要制作一個(gè)CPU,首先得明白下計(jì)算機(jī)的組成結(jié)構(gòu)(或者計(jì)算機(jī)的替代品,因?yàn)椴⒉皇侵挥杏?jì)算機(jī)有CPU,現(xiàn)在的電子產(chǎn)品都很先進(jìn),很多設(shè)備例如手機(jī)、洗衣機(jī)甚至電 視和你家的汽車上面都得裝一個(gè)CPU),數(shù)字電路基礎(chǔ),還最好有點(diǎn)編程的基礎(chǔ)(當(dāng)然,沒(méi)有也沒(méi)關(guān)系,這些知識(shí)都很容易獲得,各種書(shū)上面都會(huì)提到,并且在接下來(lái)的過(guò)程中我會(huì)提到這些知識(shí))
我們要實(shí)現(xiàn)的是一個(gè)RISC指令集的CPU,并且我們最后要自己為這個(gè)CPU設(shè)計(jì)指令并且編碼。
首先我們來(lái)聽(tīng)個(gè)故事,關(guān)于CPU的誕生的故事:
日本客戶希望英特爾幫助他們?cè)O(shè)計(jì)和生產(chǎn)八種專用集成電路芯片,用于實(shí)現(xiàn)桌面計(jì)算器。英特爾的工程師發(fā)現(xiàn)這樣做有兩個(gè)很大的問(wèn)題。第一,英特爾已經(jīng)在全力開(kāi)發(fā) 三種內(nèi)存芯片了,沒(méi)有人力再設(shè)計(jì)八種新的芯片。第二,用八種芯片實(shí)現(xiàn)計(jì)算器,將大大超出預(yù)算成本。
英特爾的一個(gè)名叫特德?霍夫(Ted Hoff)的工程師仔細(xì)分析了日本同行的設(shè)計(jì),他發(fā)現(xiàn)了一個(gè)現(xiàn)象。這八塊芯片各實(shí)現(xiàn)一種特定的功能。當(dāng)用戶使用計(jì)算器時(shí),這些功能并不是同時(shí)都需要的。比 如,如果用戶需要計(jì)算100個(gè)數(shù)的和,他會(huì)重復(fù)地輸入一個(gè)數(shù),再做一次加法,一共做100次,最后再打印出來(lái)。負(fù)責(zé)輸入、加法和打印的電路并不同時(shí)工作。這樣,當(dāng)一塊芯片在工作時(shí),其他芯片可能是空閑的。
霍夫有了一個(gè)想法:為什么不能用一塊通用的芯片加上程序來(lái)實(shí)現(xiàn)幾塊芯片的功能呢?當(dāng)需要某種功能時(shí),只需要把實(shí)現(xiàn)該功能的一段程序代碼(稱為子程序)加載到通用芯片上,其功能與專用芯片會(huì)完全一樣。
經(jīng)過(guò)幾天的思考后,霍夫畫(huà)出了計(jì)算器的新的體系結(jié)構(gòu)圖,其中包含4塊芯片:一塊通用處理器芯片,實(shí)現(xiàn)所有的計(jì)算和控制功能;一塊可讀寫(xiě)內(nèi)存(RAM)芯片, 用來(lái)存放數(shù)據(jù);一塊只讀內(nèi)存(ROM)芯片,用來(lái)存放程序;一塊輸入輸出芯片,實(shí)現(xiàn)鍵入數(shù)據(jù)和操作命令、打印結(jié)果等等功能。
看完這個(gè)故事后,可以總結(jié):CPU是一種用來(lái)代替專用集成電路的器件(這只是我的理解,不同人有不同理解,這個(gè)就智者見(jiàn)智了,我在接下來(lái)的例子中也會(huì)說(shuō)明我的想法)。
然后考慮如下這個(gè)例子:
例1-1:
mov eax,0
repeat:inc eax
jmp repeat
例1-2:
int main()
{
unsigned int i = 0;
while(1)
i++;
}
例1-3:
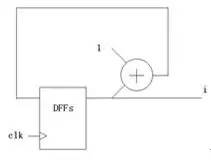
可以看到,以上三個(gè)例子都產(chǎn)生了一個(gè)從0不斷增加的序列,而且前兩個(gè)例子會(huì)一直加到溢出又從0開(kāi)始(這個(gè)取決于計(jì)算機(jī)的字長(zhǎng)也就是多少位的CPU,eax是 32位寄存器所以必然是加到4294967295然后回0,而后面那個(gè)c程序則看不同編譯器和不同平臺(tái)不一樣),后面那個(gè)例子則看你用的是什么樣的加法器和多少個(gè)D觸發(fā)器
那問(wèn)題就來(lái)了,我假設(shè)要一個(gè)遞減的序列怎么辦呢?前兩個(gè)例子很好解釋,我直接改代碼不就得了:
例2-1:
mov eax,0
repeat:dec eax
jmp repeat
例2-2:
int main()
{
unsigned int i = 0;
while(1)
i--;
}
你只需要輕輕敲擊鍵盤(pán),修改了代碼之后,它就會(huì)如你所愿的執(zhí)行。
但是后面那個(gè)例子怎么辦呢?可能你已經(jīng)想到辦法了:如例2-3所示。
例2-3:
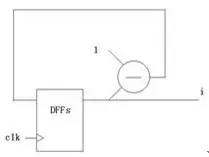
問(wèn)題就來(lái)了,你在鍵盤(pán)上敲兩下可不能改變實(shí)際電路!上面(例1-3)中是個(gè)加法器,但是跑到這里卻變成了減法器(例2-3)!
這樣的話,你就得再做一個(gè)電路,一個(gè)用來(lái)算加法,一個(gè)用來(lái)算減法,可是兩個(gè)電路代表你得用更多的電路和芯片,你花的錢就得更多,要是你不能同時(shí)使用這兩個(gè)電路你就花了兩份錢卻只干了一件事!
這個(gè)問(wèn)題能被解決嗎?答案是能!
請(qǐng)看例3:
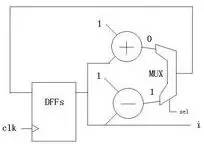
這個(gè)例子中使用了一個(gè)加法器一個(gè)減法器,沒(méi)比上面的電路省(顯然。。。。難道你想用減法器做加法器的功能?不可能吧!當(dāng)然,加上一個(gè)負(fù)數(shù)的補(bǔ)碼確實(shí)就是減去 一個(gè)數(shù),但是這里先不考慮這種問(wèn)題),多了一組多路器,少了一組D觸發(fā)器。總的來(lái)說(shuō),優(yōu)勢(shì)還是明顯的(兩塊電路板和一塊電路板的差別)。
而sel信號(hào)就是用來(lái)選擇的(0是遞增,1是遞減)。
如果我們把sel信號(hào)看做“程序”的話,這個(gè)電路就像一個(gè)“CPU”能根據(jù)“程序”執(zhí)行不同的“操作”,這樣的話,通過(guò)“程序”(sel信號(hào)),這個(gè)電路就能夠?qū)崿F(xiàn)復(fù)用。
根據(jù)上面的結(jié)論,我認(rèn)為(僅僅是個(gè)人認(rèn)為啊~):程序就是硬件電路的延伸!
而CPU的基本思想,我認(rèn)為就是這樣的。
接下來(lái)我們就分析CPU的結(jié)構(gòu)和各個(gè)部件,然后實(shí)現(xiàn)這個(gè)CPU。
什么是單周期CPU,什么是多周期CPU,什么是RISC,什么是CISC
首先大家得有時(shí)鐘的概念:這個(gè)問(wèn)題不好解釋 啊。。。。。。可以理解為家里面的機(jī)械鐘,上上電池之后就會(huì)滴答滴答走,而它“滴答滴答”的速度就是頻率,滴答一下用的時(shí)間就是周期,而人的工作,下班, 吃飯和學(xué)習(xí)娛樂(lè)都是按照時(shí)鐘的指示來(lái)進(jìn)行的(熬夜的網(wǎng)癮少年不算),一般來(lái)說(shuō),時(shí)鐘信號(hào)都是由晶體振蕩器產(chǎn)生的,0101交替的信號(hào)(低電平和高電平)。
數(shù)字電路都需要一個(gè)“時(shí)鐘”來(lái)驅(qū)動(dòng),就像演奏交響樂(lè)的時(shí)候需要一個(gè)指揮家在前面指揮一樣,所有的人都會(huì)跟著指揮的拍子來(lái)演奏,就像數(shù)字電路中所有的部件都會(huì)跟著時(shí)鐘節(jié)拍工作一樣。
如下是一個(gè)理想的時(shí)鐘信號(hào):(注意是理想的)。
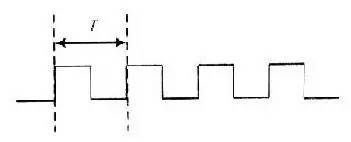
當(dāng)然,實(shí)際的時(shí)鐘信號(hào)可能遠(yuǎn)沒(méi)有這么理想,可能上升沿是斜的,而且占空比也可能不是50%,有抖動(dòng),有偏移(相對(duì)于兩個(gè)器件),可能因?yàn)閷?dǎo)線的寄生電容效應(yīng)變得走形。
上面那段如果沒(méi)聽(tīng)懂也沒(méi)關(guān)系~~~反正就是告訴你,實(shí)際的時(shí)鐘信號(hào)測(cè)出來(lái)肯定沒(méi)這么標(biāo)準(zhǔn)。
而 cpu的工作頻率,是外頻與倍頻的積(cpu究竟怎么算頻率,其實(shí)這個(gè)我也不太清楚呵呵),因?yàn)閏pu是通過(guò)外部的晶振產(chǎn)生一個(gè)時(shí)鐘信號(hào),然后再通過(guò)內(nèi)部 的電路(鎖相環(huán)),倍頻至需要的頻率。當(dāng)然,有人問(wèn),為什么要這么麻煩呢?直接在電路外邊做個(gè)時(shí)鐘晶振能產(chǎn)生那么高的時(shí)鐘信號(hào)就可以了嘛,這個(gè)是可以的, 在某些簡(jiǎn)單的系統(tǒng)上(例如51單片姬)就是這樣的,但是計(jì)算姬的cpu比較復(fù)雜,因?yàn)橐恍┰蛩员仨氁龅絚pu內(nèi)。
下面簡(jiǎn)單說(shuō)一下CPU的兩種指令集:CISC和RISC。
說(shuō)下我的看法(個(gè)人看法,如有錯(cuò)誤還請(qǐng)高手指正):
RISC是Reduced Instruction Set Computer,精簡(jiǎn)指令集計(jì)算機(jī),典型例子是MIPS處理器。
CISC 是Complex Instruction Set Compute,復(fù)雜指令集計(jì)算機(jī),典型例子是x86系列處理器(當(dāng)然現(xiàn)在的x86指令還是當(dāng)初cisc的指令,但是實(shí)際處理器的結(jié)構(gòu)都已經(jīng)變成了 risc結(jié)構(gòu)了,risc的結(jié)構(gòu)實(shí)現(xiàn)流水線等特性比較容易,在計(jì)算機(jī)前的你如果用的是intel某系列的處理器,則它使用的指令集看上去還是像cisc的 指令,但是實(shí)際上你的cpu的結(jié)構(gòu)已經(jīng)是risc的了)。
一般CISC的處理器需要用微指令配合運(yùn)行,而RISC全部是通過(guò)硬連線實(shí)現(xiàn)的, 也就是說(shuō),當(dāng)cisc的處理器在執(zhí)行你的程序前,還得先從另外一個(gè)rom里面讀出一些數(shù)據(jù)來(lái)“指導(dǎo)”處理器怎么處理你的命令,所以cisc效率比較低,而 risc是完全通過(guò)部件和部件之間的連接實(shí)現(xiàn)某種功能,極大的提高了工作效率,而且為流水線結(jié)構(gòu)的出現(xiàn)提供了基礎(chǔ)。cisc的寄存器數(shù)量較少,指令能夠?qū)?現(xiàn)一些比較特殊的功能,例如8086的一些寄存器:
ax,bx,cx,dx,si,di等;段寄存器有:cs,ds,es,ss等。相對(duì)的指令功能比較特殊,例如xlat將bx中的值作為基地址,al中的值作為偏移,在內(nèi)存中尋址到的數(shù)據(jù)送到al當(dāng)中(以ds為段寄存器)
而risc的處理器則通用寄存器比較多,而指令的功能可以稍微弱一點(diǎn),例如:
以nios嵌入式處理器來(lái)說(shuō)明,nios處理器有32個(gè)通用寄存器(r0~r31),而指令功能相對(duì)x86的弱一些,而且x86進(jìn)行內(nèi)存訪問(wèn)是直接使用mov指令,nios處理器讀內(nèi)存用的是load,寫(xiě)內(nèi)存用的是store,
二者響應(yīng)中斷的方式也不一樣,舉一個(gè)典型的例子,x86的處理器將中斷向量表放在了內(nèi)存的最低地址(0-1023,每個(gè)中斷向量占四個(gè)字節(jié)),能容納256 個(gè)中斷(以實(shí)模式的8086舉例)響應(yīng)中斷時(shí),將中斷號(hào)對(duì)應(yīng)的地址上的cs和ip的值裝入到cs和ip寄存器而將原來(lái)的地址保存,并且保存狀態(tài)寄存器然后 進(jìn)入中斷處理,而risc則擁有一個(gè)共同的中斷響應(yīng)函數(shù),這個(gè)函數(shù)會(huì)根據(jù)中斷號(hào)找到程序向系統(tǒng)注冊(cè)的函數(shù)的地址,并且調(diào)用這個(gè)函數(shù)。一般來(lái)說(shuō)而是用的 cisc指令的長(zhǎng)度是不定的,例如x86的xor ax,bx對(duì)應(yīng)機(jī)器碼是0x31d8、而push ax是0x50、pop cx是0x59。而risc的指令確是定長(zhǎng)的,例如32位。
如果還有不清楚的。。。。。自行百度,要理解這些概念需要一點(diǎn)時(shí)間
一個(gè)CPU的基本結(jié)構(gòu)以及必要組件
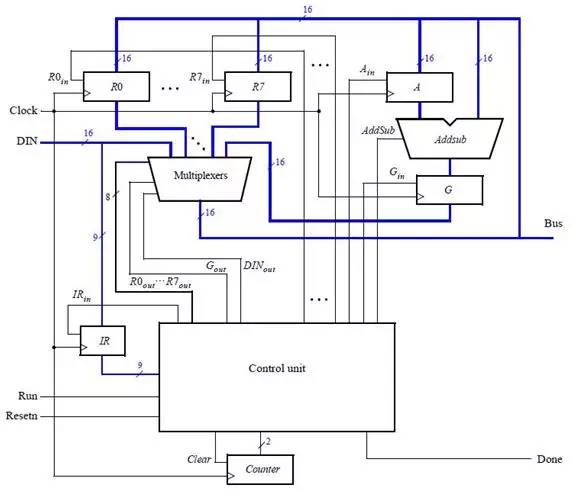
這個(gè)例子引用自DE2開(kāi)發(fā)板套件帶的光盤(pán)上的Lab Exercise 9,我們從圖中可以看到,一個(gè)CPU包含了通用寄存器組R0~R7,一個(gè)ALU(算術(shù)邏輯單元),指令寄存器IR,控制器(一般這部分是一個(gè)有限狀態(tài)機(jī)或 者是用微指令實(shí)現(xiàn)),還有就是數(shù)據(jù)通路(圖中的連線)。
當(dāng)然真正的CPU不可能只包含這么一點(diǎn)點(diǎn)組件,這是一個(gè)模型CPU,也就是說(shuō)只是說(shuō)明CPU的原 理,真正復(fù)雜的CPU要涉及到很多復(fù)雜的結(jié)構(gòu)和時(shí)序,例如虛擬模式需要使用一些特殊的寄存器、為了支持分頁(yè)需要使用頁(yè)表寄存器等,為了加速內(nèi)存的訪問(wèn)需要 使用TLB,加速數(shù)據(jù)和指令的訪問(wèn)而使用data cache和instruction cache等等。。。。。當(dāng)然,那都是后面該考慮的,所以我們先從這個(gè)簡(jiǎn)單的部分開(kāi)始講起。
例子中能實(shí)現(xiàn)如下指令:

mv指令將Ry的數(shù)據(jù)轉(zhuǎn)移到Rx中,mvi將立即數(shù)D轉(zhuǎn)移到Rx當(dāng)中,add將Rx和Ry的和放到Rx中,sub同上,不過(guò)執(zhí)行的是減法。
首先來(lái)說(shuō)明mv指令是如何執(zhí)行的:mv指令將Ry的值移入Rx寄存器當(dāng)中,這兩個(gè)寄存器都是由一組D觸發(fā)器構(gòu)成,而D觸發(fā)器的個(gè)數(shù)取決于寄存器的寬度,就像 32位機(jī)、64位機(jī)這樣,那他們的寄存器使用的D觸發(fā)器的個(gè)數(shù)就是不一樣的。
當(dāng)執(zhí)行mv rx,ry時(shí),中間的多路器(圖中最大的那個(gè)multiplexer)選通Ry,讓Ry寄存器驅(qū)動(dòng)總線,這個(gè)時(shí)候Bus上的信號(hào)就是Ry的值;然后再看到 R0~R7上分別有R0in~R7in信號(hào),這個(gè)信號(hào)是使能信號(hào),當(dāng)這個(gè)信號(hào)有效時(shí),在上升沿此觸發(fā)器會(huì)將din的數(shù)據(jù)輸入,所以說(shuō)到這里大家一定想到 了,這個(gè)時(shí)候Rx觸發(fā)器上的Din信號(hào)就會(huì)變?yōu)橛行В@樣過(guò)了一個(gè)時(shí)鐘周期后Ry的值就被送到了Rx當(dāng)中。
與mv指令類似,mvi指令也將一個(gè)數(shù)據(jù)送入Rx當(dāng)中,只不過(guò)這次的數(shù)據(jù)存在指令當(dāng)中,是立即數(shù),所以Rx的Din信號(hào)會(huì)變?yōu)橛行В嗦菲鲿?huì)選擇IR中的數(shù)據(jù),因?yàn)閙vi指令的立即數(shù)存在指令當(dāng)中。并且進(jìn)行一定處理,例如擴(kuò)展等。
add 指令會(huì)讓多路器先選擇Rx,然后Ain信號(hào)有效,這樣一個(gè)時(shí)鐘周期后,Rx數(shù)據(jù)被送入Alu的A寄存器當(dāng)中,這時(shí)多路器選擇Ry,addsub信號(hào)為 add以指示ALU進(jìn)行加法操作,Gin有效讓G寄存器存放運(yùn)算結(jié)果,然后再過(guò)一個(gè)時(shí)鐘周期G當(dāng)中的數(shù)據(jù)就是Rx與Ry的和,這時(shí)多路器再選擇 Gin,Rx的Din有效,過(guò)了一個(gè)時(shí)鐘周期后數(shù)據(jù)就被存放到Rx當(dāng)中了。
sub的過(guò)程與add差不多,不過(guò)addsub信號(hào)是sub指示ALU進(jìn)行減法。
我做的CPU模型
下面我就將我做的CPU模型的RTL網(wǎng)表發(fā)出來(lái),代碼我會(huì)上傳的,但是這個(gè)還只能進(jìn)行仿真,因?yàn)樵O(shè)計(jì) 的時(shí)候理念有問(wèn)題,出現(xiàn)了異步設(shè)計(jì),而且出現(xiàn)了將狀態(tài)機(jī)的輸出作為另一個(gè)器件的時(shí)鐘端的錯(cuò)誤,所以這個(gè)模型只能用于仿真。我用的synplify pro綜合出的RTL,而狀態(tài)轉(zhuǎn)移圖是用的Quartus的FSM Viewer截下來(lái)的。
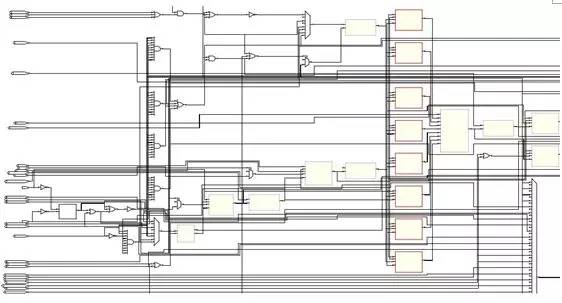
首先是整個(gè)系統(tǒng)的概覽:
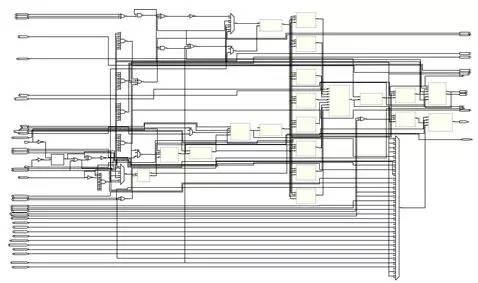
這個(gè)比上面的那個(gè)簡(jiǎn)單模型復(fù)雜多了吧!但是別擔(dān)心,其實(shí)這個(gè)只是上面的那個(gè)CPU變得稍微復(fù)雜了一點(diǎn),這個(gè)和上面那個(gè)不同的地方還有:這個(gè)CPU是一個(gè)多周期CPU而上面的Lab Exercise是一個(gè)單周期的CPU
下圖是程序計(jì)數(shù)器(PC),也就是常見(jiàn)x86處理器里面的ip(instruction poiniter):
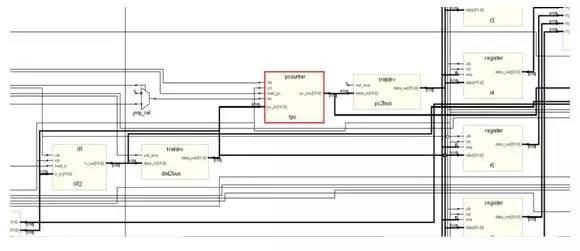
紅色部分就是pc了,后面是一個(gè)三態(tài)橋,連接到了總線上面,這里的數(shù)據(jù)有時(shí)候是要送到地址總線,用于尋內(nèi)存中的數(shù)據(jù),以便完成Instruction Fetch過(guò)程。有時(shí)候又要送到通用寄存器的數(shù)據(jù)端,用于將pc的值送到其他寄存器。
下面這個(gè)是IR(Instruction Register),這個(gè)是多周期處理器的典型特征,因?yàn)樘幚砥髟诘谝粋€(gè)周期里面將機(jī)器碼從內(nèi)存取出,然后存放到這個(gè)寄存器里面,后面的幾個(gè)狀態(tài)都是通過(guò)這個(gè)寄存器里面的數(shù)據(jù)作為指示執(zhí)行操作的。
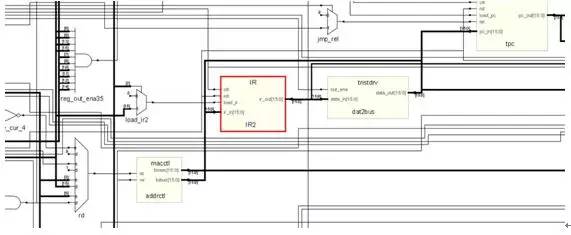
下面介紹一下ALU,ALU是Arithmetic Logic Unit,即算術(shù)邏輯單元,這個(gè)裝置的作用是進(jìn)行算術(shù)操作和邏輯操作。典型的算術(shù)操作例
如:1+1=2,11x23=253,而典型的邏輯操作例如:1 and 1=1,0 or 0 = 0,1《《3=8這種屬于邏輯操作。
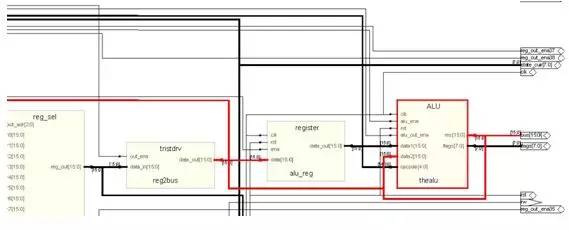
而從圖中大家也看得到,ALU的輸出用一根很長(zhǎng)的線連接到了后面,參考整個(gè)CPU的圖的話,會(huì)發(fā)現(xiàn)這些線連到了通用寄存器上面,這是為了讓運(yùn)算的結(jié)果存放回 去,例如你用add eax,1的時(shí)候,eax的值被加上1然后放回eax,所以ALU的運(yùn)算結(jié)果要用反饋送回到通用寄存器,而ALU的輸入也應(yīng)該有通用寄存器的輸出。
下面再介紹ADDRMUX:
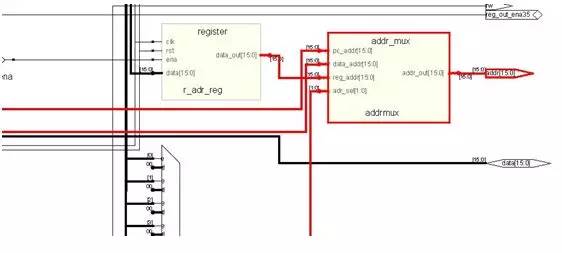
這個(gè)部件是用來(lái)選擇地址的,右邊的輸出是CPU的地址總線,而CPU的地址總線就已經(jīng)送出CPU了(也就是你能夠在芯片的外表上看到引腳了),CPU的地址總線是送到存儲(chǔ)器的地址端的。
而現(xiàn)代的計(jì)算機(jī)系統(tǒng)實(shí)際上是相當(dāng)復(fù)雜的,所以其實(shí)你家的計(jì)算機(jī)上CPU是通過(guò)北橋芯片訪問(wèn)內(nèi)存的(當(dāng)然也有將內(nèi)存控制器做到 CPU里面的)左邊是地址的來(lái)源,地址的來(lái)源即有通用寄存器,也有程序計(jì)數(shù)器,還有一個(gè)是直接從IR里面送出,這是因?yàn)橛械牧⒓磾?shù)里面也包含內(nèi)存地址信息。
最后介紹通用寄存器:
通用寄存器的作用就是用來(lái)保存中間值或者用于運(yùn)算,例如
add eax,2
相當(dāng)于eax+2然后送回eax。
最后介紹一下?tīng)顟B(tài)機(jī),這個(gè)部分就是CPU的“靈魂”,如果說(shuō)有了上面那些部件CPU有了一副“軀體”的話,這一部分就是CPU的“靈魂”了:
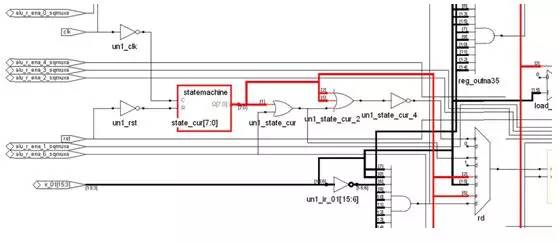
狀態(tài)機(jī)基本上與系統(tǒng)所有的組件都連接到一起了,因?yàn)樯厦嫠f(shuō)的所有動(dòng)作的執(zhí)行,都需要狀態(tài)機(jī)的控制,狀態(tài)機(jī)其實(shí)就是由一部分觸發(fā)器構(gòu)成的記憶電路和另外一部 分組合邏輯構(gòu)成的次態(tài)譯碼電路構(gòu)成,還有根據(jù)當(dāng)前狀態(tài)和輸入進(jìn)行譯碼的部分用于控制各個(gè)部件,下面是教科書(shū)上的典型FSM結(jié)構(gòu):
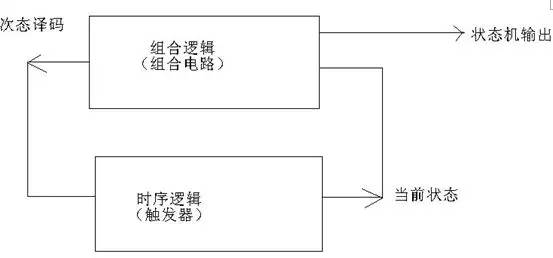
而我們用的狀態(tài)機(jī)狀態(tài)轉(zhuǎn)移圖如下:
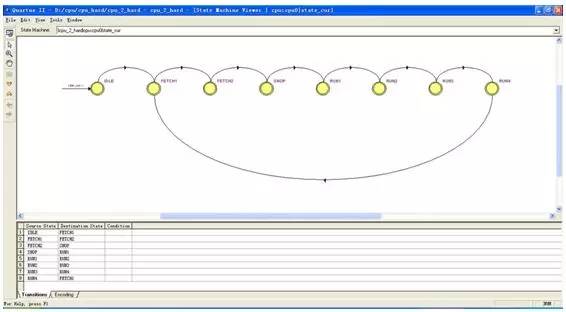
因?yàn)檫@個(gè)處理器設(shè)計(jì)的很簡(jiǎn)單,所以沒(méi)有出現(xiàn)很多狀態(tài),當(dāng)處理器經(jīng)歷完以上的狀態(tài)之后,處理器就執(zhí)行完了一條指令。
有的CISC的處理器用微指令進(jìn)行控制,作用和狀態(tài)機(jī)相近,這種結(jié)構(gòu)出現(xiàn)在一些比較古老的處理器上,因?yàn)槟莻€(gè)時(shí)候的設(shè)計(jì)工具和方法沒(méi)有現(xiàn)在的先進(jìn),所以往往 改動(dòng)硬件是困難的和高成本的,所以用微指令的話,做好了硬件的結(jié)構(gòu),要是需要改動(dòng)只要修改微指令就好了,而現(xiàn)在的電子技術(shù)很發(fā)達(dá),設(shè)計(jì)工具也很完備,所以 就有很多直接通過(guò)硬連線實(shí)現(xiàn)的處理器。
好馬配好鞍,有了處理器,我們就得給它配上一個(gè)好的程序,下面我們就用自己設(shè)計(jì)的處理器進(jìn)行求和,從1加到100,因?yàn)槲覀儧](méi)有設(shè)計(jì)編譯器,也沒(méi)有設(shè)計(jì)匯編器,所以程序只能用機(jī)器碼寫(xiě)出,示例程序如下:
我們不妨先寫(xiě)出程序的匯編代碼:
mov [ADDR],r0;r0 = 0
mov r1,100
lop:add r2,r1
sub r1,1
cmp r1,0
jz ext
mov r4,4
jmp r4(lop)
ext:mov [ADDR],r2
jmp $
先將內(nèi)存中存放數(shù)據(jù)的地址清零,這樣才能存放等下送來(lái)的結(jié)果,然后將r1寄存器存入循環(huán)次數(shù)(也就是求和的上限)。然后再將r1的值加到r2中來(lái),r2其實(shí)就是放求和的寄存器,最后我們會(huì)將r2中的值送到內(nèi)存中的某個(gè)地址存放的。
然 后將r1減去1,看看是否為0?如果為0則說(shuō)明求和結(jié)束了,如果不是0則說(shuō)明還要繼續(xù),結(jié)束后程序就跳到ext部分將結(jié)果存放到內(nèi)存中某個(gè)地址(例子中給 的是49152也就是二進(jìn)制的1100000000000000b),最后jmp $是為了讓程序停在這一行,防止程序跑飛(跑飛的程序危害很大!有可能吧數(shù)據(jù)當(dāng)代碼或者把代碼當(dāng)數(shù)據(jù)!)
轉(zhuǎn)換成VerilogHDL語(yǔ)言如下:
module memory
(
input [15:0] addr,
inout [15:0] data,
input rw
);
reg [15:0] data_ram[0:16‘b1111_1111_1111_1111];
integer i;
initial begin
for (i = 0; i 《= 16’b1111_1111_1111_1111; i = i + 1)
data_ram[i] = $random();
data_ram[0] = 16‘b1000000100000000; //mov [ADDR],r0;r0 = 0
data_ram[1] = 16’b1100000000000000; //ADDR
data_ram[2] = 16‘b1000000010001000; //mov r1,100
data_ram[3] = 100; //100
//data_ram[2] = 16’b1110011001000000;
data_ram[4] = 16‘b0010000100010001; //lop:add r2,r1
data_ram[5] = 16’b1110000011001000; //sub r1,1
data_ram[6] = 16‘b0000000000000001; //1
data_ram[7] = 16’b1110000000001000; //cmp r1,0
data_ram[8] = 16‘b0000000000000000; //0
data_ram[9] = 16’b1110011010000000; //jz ext
data_ram[10] = 16‘b0000000000000011; //+3 offset(ext)
data_ram[11] = 16’b1000000010100000;//mov r4,4
data_ram[12] = 16‘b0000000000000100;
data_ram[13] = 16’b0110011001100000;//jmp r4(lop)
data_ram[14] = 16‘b1000000100000010;//ext:mov [ADDR],r2
data_ram[15] = 16’b1100000000000000;//ADDR
data_ram[16] = 16‘b1110011001000000;//jmp $
data_ram[17] = 16’b1111111111111110;//-2 offset($)
/*data_ram[0] = 16‘b1000000010000000; //mov r0,imm
data_ram[1] = 16’b0011111111111111; //imm
data_ram[2] = 16‘b0000000001111000; //mov r7,r0
data_ram[3] = 16’b1000000010011000; //mov r3,0
data_ram[4] = 16‘b0000000000000000;
data_ram[5] = 16’b1000000010100000; //mov r4,code of jmp r5
data_ram[6] = 16‘b0110011001101000; //jmp r5
data_ram[7] = 16’b0000000101011100; //mov [r3],r4
data_ram[8] = 16‘b1000000011110000; //mov r6,[0]
data_ram[9] = 16’b0000000000000000; //[0]
data_ram[10]= 16‘b1000000100000110; //mov [255],r6
data_ram[11]= 16’b0000000011111111;
data_ram[12]= 16‘b0110011001011000; //jmp r3
*/
end
always @ (addr or rw or data)
if (rw)
data_ram[addr] = data;
assign data = rw ? 16’hzzzz : data_ram[addr];
endmodule
設(shè)計(jì)中CPU外圍還需要一個(gè)內(nèi)存設(shè)備(Memory),我用HDL對(duì)其建模,初始化的時(shí)候每個(gè)內(nèi)存地址上對(duì)應(yīng)的數(shù)據(jù)都初始化為隨機(jī)的,然后只有從0開(kāi)始的一系列地址被初始化為我寫(xiě)的代碼,機(jī)器碼對(duì)應(yīng)的匯編指令在注釋中已經(jīng)給出。
然后是結(jié)果,結(jié)果應(yīng)該是r2從0變化到5050(1+2+3+.。。.。.+100=5050)
而r1則從100變化到0,變化到0后程序?qū)⑦M(jìn)入死循環(huán),停止在jmp $那一條。這是仿真開(kāi)始的時(shí)候:
大家可以看到初始化后,d0~d7都變成了0,這是r0~r7寄存器的Q端,而state_current和state_next則是狀態(tài)機(jī)的現(xiàn)態(tài)和狀態(tài)機(jī) 的次態(tài),cpu的各個(gè)部件都通過(guò)這個(gè)狀態(tài)機(jī)受到控制。狀態(tài)名出現(xiàn)的順序和上面的FSM Viewer的連線順序是一樣的。
而且大家可以看到,d2從0變化到了0x64也就是十進(jìn)制100,說(shuō)明已經(jīng)執(zhí)行了第一次加法了。
再來(lái)看看仿真結(jié)束:
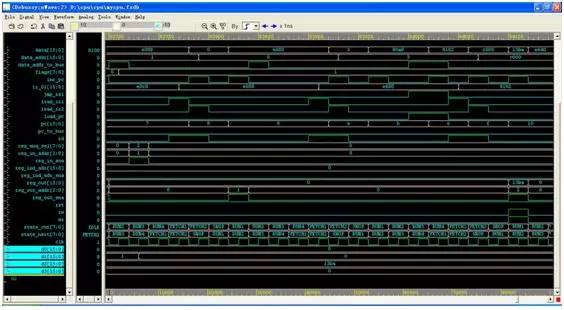
這時(shí)候d1變化到了0而d2變化到了0x13ba(十進(jìn)制的5050),說(shuō)明程序已經(jīng)在我們?cè)O(shè)計(jì)的處理器里面運(yùn)行并且成功的得出了結(jié)果!
最后給出一些我用到的指令(跟x86的很像):
add dst,src 將src和dst相加并且送到dst寄存器中
mov [addr],src 將src的值送到以addr位地址的內(nèi)存單元
sub dst,src 將dst減去src并且送到dst中去
cmp dst,src 將dst減去src 然后不送到dst中 只改變標(biāo)志位
jz dst 當(dāng)zf=1時(shí)(即上次的算術(shù)操作結(jié)果為0)則跳轉(zhuǎn)到dst中去
最后再提一下:
我是用synplify綜合的電路,然后用debussy+modelsim仿真的,
相關(guān)資料請(qǐng)參考:
CPU邏輯設(shè)計(jì),朱子玉,李亞民著
Lab Exercise 9出自DE2的開(kāi)發(fā)光盤(pán)
作者:大法師千尋
版權(quán)聲明:文章轉(zhuǎn)自網(wǎng)絡(luò)。版權(quán)歸原作者所有,如有侵權(quán),請(qǐng)聯(lián)系我們刪除!
編輯:jq
-
cpu
+關(guān)注
關(guān)注
68文章
10856瀏覽量
211622 -
CISC
+關(guān)注
關(guān)注
1文章
31瀏覽量
19509 -
編譯器
+關(guān)注
關(guān)注
1文章
1624瀏覽量
49113 -
計(jì)算器
+關(guān)注
關(guān)注
16文章
437瀏覽量
37331
原文標(biāo)題:大神教你制作一個(gè)簡(jiǎn)單的16位CPU
文章出處:【微信號(hào):mcu168,微信公眾號(hào):硬件攻城獅】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
將軟件從8位(字節(jié))可尋址CPU遷移至C28x CPU

一個(gè)簡(jiǎn)單的分頻器電路分享
一個(gè)簡(jiǎn)單的拍手操作開(kāi)關(guān)電路分享
CPU的各種知識(shí)

IAR的unsigned long為什么只有16位數(shù)?
英特爾五款優(yōu)秀的CPU介紹
關(guān)于PSSI_DMA 16位到32位的問(wèn)題求解
一個(gè)簡(jiǎn)單溫度報(bào)警電路分析
XC2234l-20F如何使用16位tasking編譯器定義一個(gè)段?
用Excel構(gòu)建了一個(gè)16位的CPU,如何做到的?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論