 什么是HBM3 為什么HBM很重要
什么是HBM3 為什么HBM很重要
點擊藍字關注我們
從高性能計算到人工智能訓練、游戲和汽車應用,對帶寬的需求正在推動下一代高帶寬內存的發展。
HBM3將帶來2X的帶寬和容量,除此之外還有其他一些好處。雖然它曾經被認為是一種“慢而寬”的內存技術,用于減少芯片外內存中的信號傳輸延遲,但現在HBM3正變得越來越快,越來越寬。在某些情況下,甚至被用于L4緩存。
Arm首席研究工程師Alejandro Rico表示:“這些新功能將使每傳輸位的焦耳效率達到更高水平,而且更多設計可以使用HBM3-only內存解決方案,不需要額外的片外存儲。AI/ML、HPC和數據分析等應用可以利用大帶寬來保持可擴展性。合理利用HBM3帶寬需要一個具有高帶寬片上網絡和處理元素的處理器設計,通過提高內存級并行性來使數據速率最大化。”
人工智能訓練芯片通常需要處理萬億字節的原始數據,而HBM3可以達到這個水平。Rambus的產品營銷高級總監Frank Ferro指出:“用戶在開發ASIC電路來更好地解決人工智能問題的同時,需要更多的帶寬。
每個用戶都試圖想用一個更高效的處理器來實現他們特定的神經網絡,并在實現時達到更好的內存利用率和CPU利用率。對于人工智能訓練來說,HBM一直是最佳選擇,因為它提供了更多帶寬和更低功耗。雖然價格上有點貴,但對于這些應用程序來說(尤其是進入云計算的應用程序)還是負擔得起的。HBM3實際上只是一種自然遷移。”

雖然JEDEC尚未公布未獲批準的HBM3規范細節,但Rambus報告稱其HBM3子系統帶寬將增加到8.4 Gbps(HBM2e為3.6Gbps)。采用HBM3的產品預計將在2023年初發貨。
“當芯片的關鍵性能指標是每瓦特內存帶寬,或者HBM3是實現所需帶寬的唯一途徑時,采用HBM3是有益的,”Cadence的IP組總監Marc Greenberg表示:“與基于PCB的方法(如DDR5、LPDDR5/5X或GDDR6)相比,這種帶寬和效率的代價是在系統中增加額外的硅,并可能增加制造/組裝/庫存成本。額外的硅通常是一個插入器,以及每個HBM3 DRAM堆棧下面的一個基模。”
為什么HBM很重要
自HBM首次宣布以來的十年里,已有2.5代標準進入市場。在此期間,創建、捕獲、復制和消耗的數據量從2010年的2 ZB增加到2020年的64.2 ZB,據Statista預測,這一數字將在2025年增長近三倍,達到181 ZB。
Synopsys的高級產品營銷經理Anika Malhotra表示:“2016年,HBM2將信令速率提高了一倍,達到2 Gbps,帶寬達到256 GB/s。兩年后,HBM2E出現了,實現了3.6 Gbps和460 GB/s的數據速率。性能需求在增加,高級工作負載對帶寬的需求也在增加,因為更高的內存帶寬是實現計算性能的關鍵因素。”
“除此之外,為了更快地處理所有這些數據,芯片設計也變得越來越復雜,通常需要專門的加速器、片內或封裝內存儲器及接口。HBM被視為將異構分布式處理推到一個完全不同水平的一種方式。”
“最初,高帶寬內存只是被圖形公司視為進化方向上的一步;但是后來網絡和數據中心意識到HBM可以為內存結構帶來更多的帶寬。所有推動數據中心采用HBM的動力在于更低延遲、更快訪問和更低功耗。”Malhotra說。“通常情況下,CPU為內存容量進行優化,而加速器和GPU為內存帶寬進行優化。但是隨著模型尺寸的指數增長,系統對容量和帶寬的需求同時在增長(即不會因為增加容量后,對帶寬需求降低)。我們看到更多的內存分層,包括支持對軟件可見的HBM + DDR,以及使用HBM作為DDR的軟件透明緩存。除了CPU和GPU, HBM也很受數據中心FPGA的歡迎。”
HBM最初的目的是替代GDDR等其他內存,由一些領先的半導體公司(特別是英偉達和AMD)推動。這些公司仍然在JEDEC工作組中大力推動其發展,英偉達是該工作組的主席,AMD是主要貢獻者之一。
Synopsys產品營銷經理Brett Murdock表示:“GPU目前有兩種選擇。一種是繼續使用GDDR,這種在SoC周圍會有大量的外設;另一種是使用HBM,可以讓用戶獲得更多的帶寬和更少的物理接口,但是整體成本相對更高。還有一點需要強調的是物理接口越少,功耗越低。所以使用GDDR非常耗電,而HBM非常節能。所以說到底,客戶真正想問的是花錢的首要任務是什么?對于HBM3,已經開始讓答案朝‘可能應該把錢花在HBM上’傾斜。”
盡管在最初推出時,HBM 2/2e僅面向AMD和Nvidia這兩家公司,但現在它已經擁有了龐大的用戶基礎。當HBM3最終被JEDEC批準時,這種增長有望大幅擴大。
關鍵權衡
芯片制造商已經明確表示,當系統中有插入器時HBM3會更有意義,例如基于chiplet的設計已經使用了硅插入器。Greenberg表示:“在許多系統中還沒有插入器的情況下,像GDDR6、LPDDR5/5X或DDR5這樣的PCB內存解決方案可能比添加插入器來實現HBM3更具成本優勢。”
然而,隨著規模經濟發揮作用,這些權衡可能不再是一個問題。Synopsys的Murdock表示,對于使用HBM3的用戶來說,最大的考慮是管理PPA,因為與GDDR相比,在相同的帶寬下,HBM設備的硅面積更小、功耗更低,需要處理的物理接口也更少。
“此外,與DDR、GDDR或LPDDR接口相比,IP端的HBM設備在SoC上的物理實現方法相當野蠻粗暴。對于一般物理接口,我們有很多方法去實現它:可以在模具的側面放一個完整的線性PHY,可以繞過拐角,也可以把它折疊起來。但是對于HBM,當要放下一個HBM立體時,JEDEC已經準確地定義了這個立體上的bump map是什么樣子的。用戶將把它放在插入器上,它將緊挨著SoC,所以如何在SoC上構建bump map只有一個可行的選擇。”
這些決策會影響可靠性。雖然在bump方面減少了靈活性,但增加的可預測性意味著更高的可靠性。
特別是在2.5D和3D帶來的復雜性下,可以消除的變量越多越好。
Malhotra表示,在HBM3被廣泛采用的AI/ML應用中,電源管理是最重要的考慮因素。“對于數據中心和邊緣設備來說都是如此。權衡圍繞著功耗、性能、面積和帶寬。對于邊緣計算,隨著第四個變量(帶寬)加入到傳統的PPA方程中,復雜性正在不斷增加。在AI/ML的處理器設計或加速器設計中,功耗、性能、面積、帶寬的權衡很大程度上取決于工作負載的性質。”
如何確保正常工作?
雖然HBM3實現看起來足夠簡單,但由于這些內存通常用于關鍵任務應用程序,必須確保它們能夠按預期工作。Rambus的產品營銷工程師Joe Rodriguez表示,應該使用多個供應商提供的芯片調試和硬件啟動工具,以確保整個內存子系統正常運行。
用戶通常利用供應商提供的測試平臺和模擬環境,這樣他們就可以使用控制器開始運行模擬,看看系統在HBM 2e/3系統上的表現如何。
Rambus公司的Ferro表示:“在考慮整體系統效率時,HBM實現一直是一個挑戰,因為面積太小。面積小是件好事,但現在系統有了CPU或GPU,可能有4個或更多HBM DRAM。這意味著熱量、功耗、信號完整性、制造可靠性都是物理實現時必須解決的問題。”
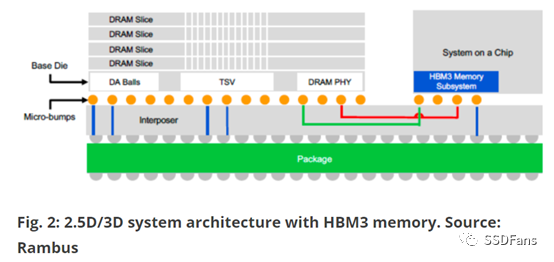
為了從插入器和封裝設計中獲得最優性能,即使在HBM2e,許多公司都努力通過插入器獲得良好的信號完整性。更復雜的是,每個代工廠對于這些插入器都有不同的設計規則,有些規則比其他的更具挑戰性。
結論
在可預見的未來,我們將繼續實現更高內存帶寬,即將到來的HBM3有望開啟系統設計的一個新階段,將系統性能提升到一個新的水平。
為了實現這一點,行業參與者必須繼續解決數據密集型SoC的設計和驗證需求,以及最先進協議(如HBM3)的驗證解決方案。作為一個整體,這些解決方案應該結合在一起,以允許對協議和時序檢查進行規范性驗證,保證設計可以得到充分驗證。
原文鏈接:
https://semiengineering.com/hbm3s-impact-on-chip-design/
編輯:jq
-
芯片
+關注
關注
455文章
50714瀏覽量
423142 -
soc
+關注
關注
38文章
4161瀏覽量
218164 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238254 -
HBM
+關注
關注
0文章
379瀏覽量
14744 -
HBM3
+關注
關注
0文章
74瀏覽量
154
原文標題:HBM3來了!
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
HBM3E量產后,第六代HBM4要來了!

HBM格局生變!傳三星HBM3量產供貨英偉達,國內廠商積極布局
中國AI芯片和HBM市場的未來
三星HBM芯片遇阻英偉達測試
韓美半導體新款TC鍵合機助力HBM市場擴張
HBM3E起飛,沖鋒戰鼓已然擂響

NVIDIA預定購三星獨家供應的大量12層HBM3E內存
英偉達CEO贊譽三星HBM內存,計劃采購
SK海力士HBM3E正式量產,鞏固AI存儲領域的領先地位
三星強化HBM工作團隊為永久辦公室,欲搶占HBM3E領域龍頭地位?
HBM、HBM2、HBM3和HBM3e技術對比






 工商網監
工商網監
評論