 邊緣AI處理器拼的只是算力和功耗嗎
邊緣AI處理器拼的只是算力和功耗嗎
電子發燒友網報道(文/周凱揚)AI應用如同燃起的野火一般,從消費級的手機端,出現在了工業級的超級游輪和航空級的空間站上。然而在邊緣端,這些應用遇上了傳統應用也掙扎了數年的需求:更高的性能、更大的容量和更低的功耗。
更糟糕的是,機器學習模型正在以指數級的速度增長,每3到5個月就會翻一番。要想應用這些模型的話,傳統的計算芯片已經難以利用有限的內存資源和功率提供高性能,連數據中心都在AI工作負載上感到吃力了,更不用說在邊緣側運行的大型模型。為此,邊緣AI處理器成了不少芯片大廠和初創企業的發力方向。然而在處理器的選取上,并不是僅僅看算力、功耗和成本而已。
邊緣AI處理器的選擇
首先,AI芯片公司不僅要有硬件開發實力,也要具備強大的AI軟件棧和工具。比如英特爾或英偉達之類的廠商,其CPU或GPU設計早已為TensorFlow、Caffe或Pytorch等框架提供了支持,但初創企業自研架構的AI處理器往往需要打造自己的編譯器來支持這些框架。
其次,是處理器支持的神經網絡精度。多數邊緣AI處理器精度并不高,這是因為將神經網絡轉換為低精度簡化了硬件設計,同時也極大地降低了功耗。要想保持高精度的話,往往需要重新訓練神經網絡。
Nvidia - Jetson Xavier NX
英偉達于2019年公布了一款名為“Jetson Xavier NX”的AI處理器,專門用于邊緣系統和嵌入式應用。Jetson Xavier NX只有70mm x 45mm的大小,卻可以在15W的功耗下提供21 TOPS(INT8)的AI算力。
Jetson Xavier NX集成了6核CPU、384核GPU、48個Tensor核心、2個NVDLA深度學習加速器和7路VLIW視覺處理器加速器。其中CPU選用了英偉達Carmel Arm核心,GPU則是基于Volta架構。該處理器還配備了8GB 128位的LDDR4x內存,可提供59.7GB/s的帶寬性能。
英偉達已經為用戶提供了開發者套件,可以創建高性能的AI應用,并快速部署深度神經網絡模型和常見的機器學習框架,比如Tensorflow和Pytorch等,除此之外也可以用到cuDNN、TensorRT和DeepStream等一系列軟件庫和加速工具。
Jetson Xavier NX最大的優勢在于其Jetson產品線全部基于同一軟件棧,所以可以直接套用更強大的Jetson AGX Xavier上的AI應用,只不過算力要稍低一截而已。憑借其21TOPS的AI算力,加上加速器提供的視頻處理器性能,可以毫無壓力地完成人體識別、自研語言處理、姿勢檢測和注視檢測等AI應用,適用于自動光學檢測和智能攝像頭等一系列邊緣IoT設備。
Hailo - Hailo-8
Hailo是一家來自于以色列的AI芯片公司,不少核心開發成員來自于以色列國防科技部門,主要負責為邊緣設備開發高性能的AI處理器。早在2019年,Hailo就公布了其自研的邊緣AI處理器Hailo-8,其算力可達26TOPS(INT8),但該處理器的典型功耗僅有2.5W。在完成了多輪融資后,Hailo也在今年開始了Hailo-8的量產。
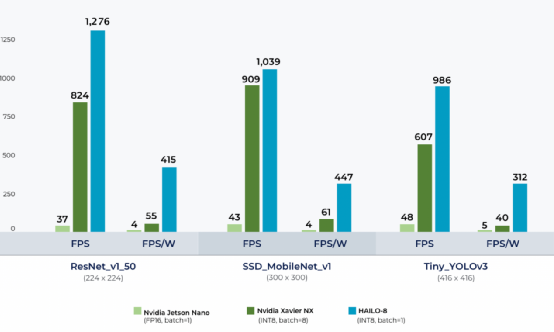
Hailo-8與Jetson產品的對比 / Hailo
與傳統的CPU、GPU、DSP或硬件加速器的架構不同,Hailo在這款處理器上運用了自研的結構定義數據流架構。在ResNet-50的神經網絡測試中,Hailo-8取得了1330FPS@3.2W的成績。Hailo還在官網曬出出了Hailo-8與英偉達Jetson Nano與Xavier NX在ResNet和SSD_MobileNet等模型下的預期表現對比,我們從上圖可以看出,Hailo-8在性能上優勢明顯,能耗比更是讓英偉達的兩款Jetson處理器望塵莫及。
Hailo還準備好了開源的Model Zoo,其中囊括了物體識別、分類、人臉檢測識別等60多種計算機視覺任務的深度學習模型。開發者利用這些預訓練的Tensorflow和ONNX模型,只需用上自己的數據重新訓練,即可在Hailo設備上迅速創建好原型。
Mythic - M1076
美國德州的初創公司Mythic推出了利用存內計算技術的M1076模擬矩陣處理器(AMP)。單個M1076芯片的面積只有360mm2,卻可以在3W至4W的功耗下提供35 TOPS的算力,與常見的SoC或GPU方案相比,功耗低了10倍以上。
但這并不是M1076的最大特色,與傳統數字計算方式不同,Mythic在M1076上運用了模擬計算。模擬計算雖然理論上要要與數字計算,但長久以來收到尺寸的限制,在速度與擴展性上一直提不上去。然而Mythic通過將模擬運算與嵌入式閃存結合,選擇了存內計算的方式。
M1076同時支持INT4、INT8和INT16三種數據類型,非常適合作為TinyML的開發平臺。Mythic也為客戶提供了物體識別/分類、圖像分割和姿勢評估等模型,可用于AR/VR中的智能健身和游戲等應用。
小結
云計算在邊緣端的弱勢使得邊緣AI處理器有了崛起的機會,在工業4.0、自動化系統和智能IoT的潮流下,邊緣AI還需要繼續開拓應用場景,而不僅僅是用于機器視覺任務。邊緣AI處理器廠商也必須繼續提供更多的模型,幫助開發者加速邊緣AI應用的落地。
聲明:本文由電子發燒友原創,轉載請注明以上來源。如需入群交流,請添加微信elecfans999,投稿爆料采訪需求,請發郵箱huangjingjing@elecfans.com。
編輯:jq
-
處理器
+關注
關注
68文章
19348瀏覽量
230262 -
芯片
+關注
關注
456文章
50950瀏覽量
424739 -
AI
+關注
關注
87文章
31133瀏覽量
269460 -
機器學習
+關注
關注
66文章
8425瀏覽量
132770
原文標題:邊緣AI處理器拼的不僅是算力和功耗
文章出處:【微信號:elecfans,微信公眾號:電子發燒友網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
進迭時空 K1 系列 8 核 64 位 RISC - V AI CPU 芯片介紹
未來邊緣GPU算力在車聯網中的創新應用(下)

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
超緊湊模塊提供高達 39 TOPS AI 算力

米爾STM32MP2核心板首發新品上市!高性能+多接口+邊緣算力
基于全志V853處理器的智能輔助駕駛算法介紹

AI算力核心板:Core-1688JD4






 工商網監
工商網監
評論