


本文轉(zhuǎn)載于極術(shù)社區(qū)
極術(shù)專欄:ARM攢機指南
作者:djygrdzh
CCI400是怎么做到硬件一致性的呢?簡單來說,就是處理器組C1,發(fā)一個包含地址信息的特殊讀寫的命令到總線,然后總線把這個命令轉(zhuǎn)給另一個處理器組C2。C2收到請求后,根據(jù)地址逐步查找二級和一級緩存,如果發(fā)現(xiàn)自己也有,那么就返回數(shù)據(jù)或者做相應(yīng)的緩存一致性操作,這個過程稱作snooping(監(jiān)聽)。
具體的操作我不展開,ARM使用MOESI一致性協(xié)議,里面都有定義。在這個過程中,被請求的C2中的處理器核心并不參與這個過程,所有的工作由緩存和總線接口單元BIU等部件來做。
為了符合從設(shè)備不主動發(fā)起請求的定義,需要兩組主從設(shè)備,每個處理器組占一個主和一個從。這樣就可以使得兩組處理器互相保持一致性。而有些設(shè)備如DMA控制器,它本身不包含緩存,也不需要被別人監(jiān)聽,所以它只包含從設(shè)備,如上圖桔黃色的部分。在ARM的定義中,具有雙向功能的接口被稱作ACE,只能監(jiān)聽別人的稱作ACE-Lite。它們除了具有AXI的讀寫通道外,還多了個監(jiān)聽通道。
多出來的監(jiān)聽通道,同樣也有地址(從到主),回應(yīng)(主到從)和數(shù)據(jù)(主到從)。每組信號內(nèi)都包含和AXI一樣的標(biāo)志符,用來支持多OT。如果在主設(shè)備找到數(shù)據(jù)(稱為命中),那么數(shù)據(jù)通道會被使用,如果沒有,那告知從設(shè)備未命中就可以了,不需要傳數(shù)據(jù)。由此,對于上文的DMA控制器,它永遠(yuǎn)不可能傳數(shù)據(jù)給別人,所以不需要數(shù)據(jù)組,這也就是ACE和ACE-Lite的主要區(qū)別。
我們還可以看到,在讀通道上有個額外的線RACK,它的用途是,當(dāng)從設(shè)備發(fā)送讀操作中的數(shù)據(jù)給主,它并不知道何時主能收到這個數(shù)據(jù),因為我們說過插入寄存器會導(dǎo)致總線延遲變長。萬一這個時候,對同樣的地址A,它需要發(fā)送新的監(jiān)聽請求給主,就會產(chǎn)生一個問題:主是不是已經(jīng)收到前面發(fā)出的地址A的數(shù)據(jù)了呢?如果沒收到,那它可能會告知監(jiān)聽未命中。但實際上地址A的數(shù)據(jù)已經(jīng)發(fā)給主了,它該返回命中。加了這個RACK后,從設(shè)備在收到主給的確認(rèn)RACK之前,不會發(fā)送新的監(jiān)聽請求給主,從而避免了上述問題。寫通道上的WACK同樣如此。
我們之前計算過NIC400上的延遲,有了CCI400的硬件同步,是不是訪問更快了呢?首先,硬件一致性的設(shè)計目的不是為了更快,而是軟件更簡單。而實際上,它也未必就快。因為給定一個地址,我們并不知道它是不是在另一組處理器的緩存內(nèi),所以無論如何都需要額外的監(jiān)聽動作。當(dāng)未命中的時候,這個監(jiān)聽動作就是多余的,因為我們還是得從內(nèi)存去抓數(shù)據(jù)。這個多余的動作就意味著額外的延遲,10加10一共20個總線周期,增長了100%。當(dāng)然,如果命中,雖然總線總共上也同樣需要10周期,可是從緩存拿數(shù)據(jù)比從內(nèi)存拿快些,所以此時是有好處的。綜合起來看,當(dāng)命中大于一定比例,總體還是受益的。
可從實際的應(yīng)用程序情況來看,除了特殊設(shè)計的程序,通常命中不會大于10%。所以我們必須想一些辦法來提高性能。一個辦法就是,無論結(jié)果是命中還是未命中,都讓總線先去內(nèi)存抓數(shù)據(jù)。等到數(shù)據(jù)抓回來,我們也已經(jīng)知道監(jiān)聽的結(jié)果,再決定把哪邊的數(shù)據(jù)送回去。這個辦法的缺點,功耗增大,因為無論如何都要去讀內(nèi)存。第二,在內(nèi)存訪問本身就很頻繁的時候,這么做會降低總體性能。
另外一個方法就是,如果預(yù)先知道數(shù)據(jù)不在別的處理器組緩存,那就可以讓發(fā)出讀寫請求的主設(shè)備,特別注明不需要監(jiān)聽,總線就不會去做這個動作。這個方法的缺點就是需要軟件干預(yù),雖然代價并不大,分配操作系統(tǒng)頁面的時候設(shè)下寄存器就可以,可是對程序員的要求就高了,必須充分理解目標(biāo)系統(tǒng)。
CCI總線還使用了一個新的方法來提高性能,那就是在總線里加入一個監(jiān)聽過濾器(SnoopFilter)。這其實也是一塊緩存(TAG RAM),把它所有處理器組內(nèi)部一級二級緩存的狀態(tài)信息都放在里面。數(shù)據(jù)緩存(DATA RAM)是不需要的,因為它只負(fù)責(zé)查看命中與否。這樣做的好處就是,監(jiān)聽請求不必發(fā)到各組處理器,在總線內(nèi)部就可以完成,省了將近10個總線周期,功耗也優(yōu)于訪問內(nèi)存。它的代價是增加了一點緩存(一二級緩存10%左右的容量)。并且,如果監(jiān)聽過濾器里的某行緩存被替換(比如寫監(jiān)聽命中,需要無效化(Invalidate)緩存行,MOESI協(xié)議定義),同樣的操作必須在對應(yīng)處理器組的一二級緩存也做一遍,以保持一致性。這個過程被稱作反向無效化,它添加了額外的負(fù)擔(dān),因為在更新一二級緩存的時候,監(jiān)聽過濾器本身也需要追蹤更新的狀態(tài),否則就無法保證一致性。幸好,在實際測試中發(fā)現(xiàn),這樣的操作并不頻繁,一般不超過5%的可能性。當(dāng)然,有些測試代碼會頻繁的觸發(fā)這個操作,此時監(jiān)聽過濾器的缺點就顯出來了。
以上的想法在CCI500中實現(xiàn),示意圖如下:
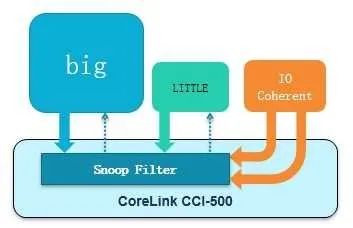
在經(jīng)過實際性能測試后,CCI設(shè)計人員發(fā)現(xiàn)總線瓶頸移到了訪問這個監(jiān)聽過濾器的窗口,這個瓶頸其實掩蓋了上文的反向無效化問題,它總是先于反向無效化被發(fā)現(xiàn)。把這個窗口加大后,又在做測試時發(fā)現(xiàn),如果每個主從接口都拼命灌數(shù)據(jù)(主從設(shè)備都是OT無限大,并且一主多從有前后交叉),在主從設(shè)備接口處經(jīng)常出現(xiàn)等待的情況,也就是說,明明數(shù)據(jù)已經(jīng)準(zhǔn)備好了,設(shè)備卻來不及接收。于是,又增加了一些緩沖來存放這些數(shù)據(jù)。其代價是稍大的面積和功耗。請注意,這個緩沖和存放OT的狀態(tài)緩沖并不重復(fù)。
根據(jù)實測數(shù)據(jù),在做完所有改進后,新的總線帶寬性能同頻增加50%以上。而頻率可以從500Mhz提高到1GMhz。當(dāng)然這個結(jié)果只是一個模糊的統(tǒng)計,如果我們考慮處理器和內(nèi)存控制器OT數(shù)量有限,被監(jiān)聽數(shù)據(jù)的百分比有不同,命中率有變化,監(jiān)聽過濾器大小有變化,那肯定會得到不同的結(jié)果。
作為一個手機芯片領(lǐng)域的總線,需要支持傳輸?shù)亩鄡?yōu)先級也就是QoS。因為顯示控制器等設(shè)備對實時性要求高,而處理器組的請求也很重要。支持QoS本身沒什么困難,只需要把各類請求放在一個緩沖,根據(jù)優(yōu)先級傳送即可。但是在實際測試中,發(fā)現(xiàn)如果各個設(shè)備的請求太多太頻繁,緩沖很快就被填滿,從而阻塞了新的高優(yōu)先級請求。為了解決這個問題,又把緩沖按優(yōu)先級分組,每一組只接受同等或更高優(yōu)先級的請求,這樣就避免了阻塞。
此外,為了支持多時鐘和電源域,使得每一組處理器都可以動態(tài)調(diào)節(jié)電壓和時鐘頻率,CCI系列總線還可以搭配異步橋ADB(Asynchronous Domain Bridge)。它對于性能有一定的影響,在倍頻是2的時候,信號穿過它需要一個額外的總線時鐘周期。如果是3,那更大些。在對于訪問延遲有嚴(yán)格要求的系統(tǒng)里面,這個時間不可忽略。如果不需要額外的電源域,我們可以不用它,省一點延遲。NIC/CCI/CCN/NoC總線天然就支持異步傳輸。
和一致性相關(guān)的是訪存次序和鎖,有些程序員把它們搞混了。假設(shè)我們有兩個核C0和C1。當(dāng)C0和C1分別訪問同一地址A0,無論何時,都要保證看到的數(shù)據(jù)一致,這是一致性。然后在C0里面,它需要保證先后訪問地址A0和A1,這稱作訪問次序,此時不需要鎖,只需要壁壘指令。如果C0和C1上同時運行兩個線程,當(dāng)C0和C1分別訪問同一地址A0,并且需要保證C0和C1按照先后次序訪問A0,這就需要鎖。所以,單單壁壘指令只能保證單核單線程的次序,多核多線程的次序需要鎖。而一致性保證了在做鎖操作時,同一變量在緩存或者內(nèi)存的不同拷貝,都是一致的。
ARM的壁壘指令分為強壁壘DSB和弱壁壘DMB。我們知道讀寫指令會被分成請求和完成兩部分,強壁壘要求上一條讀寫指令完成后才能開始下一個請求,弱壁壘則只要求上一條讀寫指令發(fā)出請求后就可以繼續(xù)下一條讀寫指令的請求,且只能保證,它之后的讀寫指令完成時,它之前的讀寫指令肯定已經(jīng)完成了。顯然,后一種情況性能更高,OT》1。但測試表明,多個處理器組的情況下,壁壘指令如果傳輸?shù)娇偩€,只能另整體系統(tǒng)性能降低,因此在新的ARM總線中是不支持壁壘的,必須在芯片設(shè)計階段,通過配置選項告訴處理器自己處理壁壘指令,不要送到總線。但這并不影響程序中的壁壘指令,處理器會在總線之前把它過濾掉。
具體到CCI總線上,壁壘機制是怎么實現(xiàn)的呢?首先,壁壘和讀寫一樣,也是使用讀寫通道的,只不過它地址總是0,且沒有數(shù)據(jù)。標(biāo)志符也是有的,此外還有額外的2根線BAR0/1,表明本次傳輸是不是壁壘,是哪種壁壘。他是怎么傳輸?shù)哪兀肯瓤慈醣趬荆缦聢D:
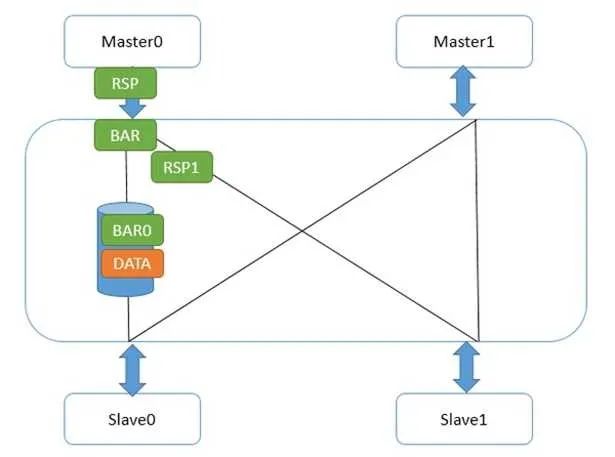
Master0寫了一個數(shù)據(jù)data,然后又發(fā)了弱壁壘請求。CCI和主設(shè)備接口的地方,一旦收到壁壘請求,立刻做兩件事,第一,給Master0發(fā)送壁壘響應(yīng);第二,把壁壘請求發(fā)到和從設(shè)備Slave0/1的接口。Slave1接口很快給了壁壘響應(yīng),因為它那里沒有任何未完成傳輸。而Slave0接口不能給壁壘響應(yīng),因為data還沒發(fā)到從設(shè)備,在這條路徑上的壁壘請求必須等待,并且不能和data的寫請求交換次序。這并不能阻撓Master0發(fā)出第二個數(shù)據(jù),因為它已經(jīng)收到它的所有下級(Master0接口)的壁壘回應(yīng),所以它又寫出了flag。如下圖:
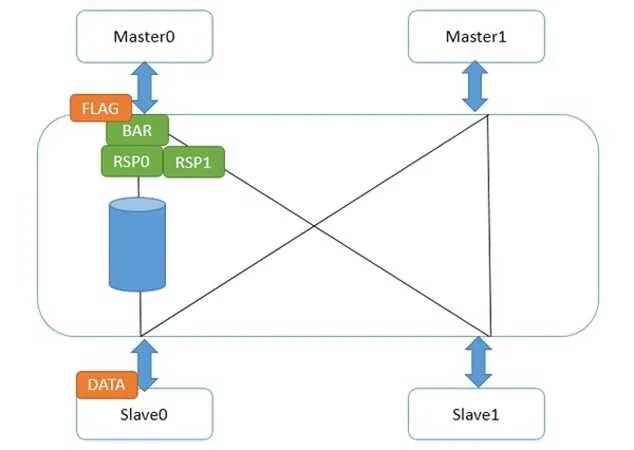
此時,flag在Master0接口中等待它的所有下一級接口的壁壘響應(yīng)。而data達(dá)到了Slave0后,壁壘響應(yīng)走到了Master0接口,flag繼續(xù)往下走。此時,我們不必?fù)?dān)心data沒有到slave0,因為那之前,來自Slave0接口的壁壘響應(yīng)不會被送到Master0接口。這樣,就做到了弱壁壘的次序保證,并且在壁壘指令完成前,flag的請求就可以被送出來。
對于強壁壘指令來說,僅僅有一個區(qū)別,就是Master0接口在收到所有下一級接口的壁壘響應(yīng)前,它不會發(fā)送自身的壁壘響應(yīng)給Master0。這就造成flag發(fā)不出來,直到壁壘指令完成。如下圖:
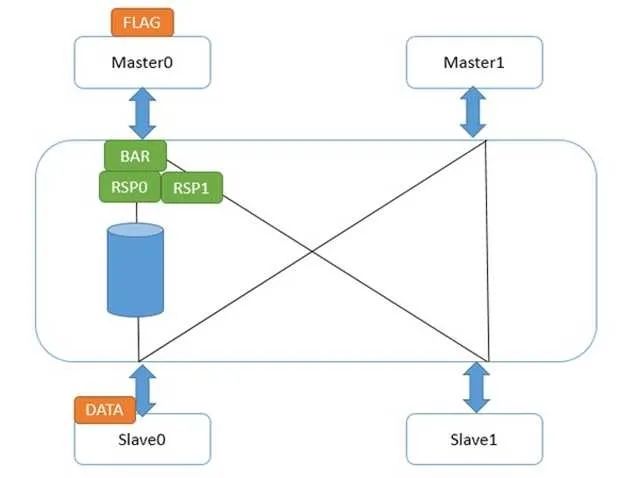
這樣,就保證了強壁壘完成后,下一條讀寫指令才能發(fā)出請求。此時,強壁壘前的讀寫指令肯定是完成了的。
另外需要特別注意的是,ARM的弱壁壘只是針對顯式數(shù)據(jù)訪問的次序。什么叫顯式數(shù)據(jù)訪問?讀寫指令,緩存,TLB操作都算。相對的,什么是隱式數(shù)據(jù)訪問?在處理器那一節(jié),我們提到,處理器會有推測執(zhí)行,預(yù)先執(zhí)行讀寫指令;緩存也有硬件預(yù)取機制,根據(jù)之前數(shù)據(jù)訪問的規(guī)律,自動抓取可能用到的緩存行。這些都不包含在當(dāng)前指令中,弱壁壘對他們無能為力。因此,切記,弱壁壘只能保證你給出的指令次序,并不能保證在它們之間沒有別的模塊去訪問內(nèi)存,哪怕這個模塊來自于同一個核。
簡單來說,如果只需要保證讀寫次序,用弱壁壘;如果需要某個讀寫指令完成才能做別的事情,用強壁壘。以上都是針對普通內(nèi)存類型。當(dāng)我們把類型設(shè)成設(shè)備時,自動保證強壁壘。
我們提到,壁壘只是針對單核。在多核多線程時,哪怕使用了壁壘指令,也沒法保證讀寫的原子性。解決辦法有兩個,一個是軟件鎖,一個是原子操作。AXI/ACE協(xié)議不支持原子操作。所以手機通常需要用到軟件鎖。
軟件鎖中有個自旋鎖,能用一個ARM硬件機制exclusive access來實現(xiàn)。當(dāng)使用特殊指令對一個地址寫入值,相應(yīng)緩存行上會做一個特殊標(biāo)記,表示還沒有別的核去寫這行緩存。然后下條指令讀這個行,如果標(biāo)記沒變,說明寫和讀之間沒有人打擾,那么就拿到鎖了。如果變了,那么回到寫的過程重新獲取鎖。由于緩存一致性,這個鎖變量可以被多個核與線程使用。當(dāng)然,過程中還是需要壁壘指令來保證次序。
在支持ARMv8.2和AMBA 5.0 CHI接口的系統(tǒng)中,原子操作被重新引入。在硬件層面,其實原子操作非常容易理解,如果某個數(shù)據(jù)存在于自己的緩存,那就直接修改;如果存在于別人的緩存,那對所有其他緩存執(zhí)行Eviction操作,踢出后,放到自己的緩存繼續(xù)操作。這個過程其實和exclusive access非常類似。
對于普通內(nèi)存,還會產(chǎn)生一個問題,就是讀寫操作可能會經(jīng)過緩存,你不知道數(shù)據(jù)是否最終寫到了內(nèi)存中。通常我們使用clean操作來刷緩存。但是刷緩存本身是個模糊的概念,緩存存在多級,有些在處理器內(nèi),有些在總線之后,到底刷到哪里算是終結(jié)呢?還有,為了保證一致性,刷的時候是不是需要通知別的處理器和緩存?為了把這些問題規(guī)范化,ARM引入了Point of Unification/Coherency,Inner/Outer Cacheable和System/Inner/Outer/Non Shareable的概念。
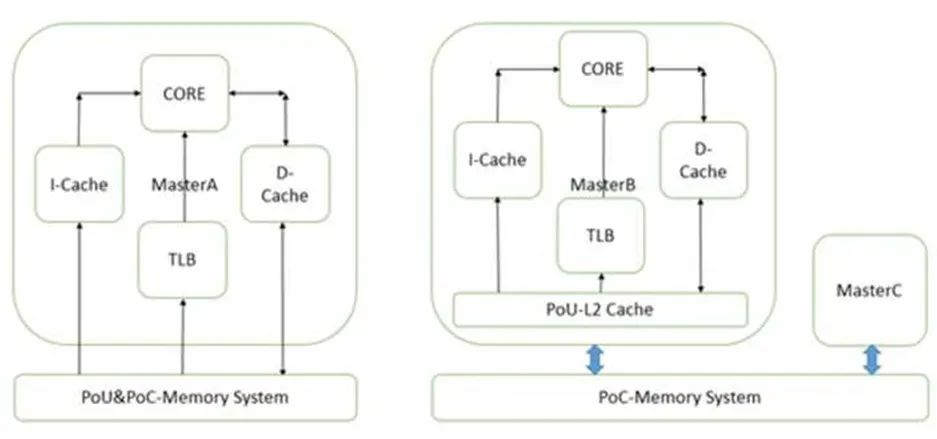
PoU是指,對于某一個核Master,附屬于它的指令,數(shù)據(jù)緩存和TLB,如果在某一點上,它們能看到一致的內(nèi)容,那么這個點就是PoU。如上圖右側(cè),MasterB包含了指令,數(shù)據(jù)緩存和TLB,還有二級緩存。指令,數(shù)據(jù)緩存和TLB的數(shù)據(jù)交換都建立在二級緩存,此時二級緩存就成了PoU。而對于上圖左側(cè)的MasterA,由于沒有二級緩存,指令,數(shù)據(jù)緩存和TLB的數(shù)據(jù)交換都建立在內(nèi)存上,所以內(nèi)存成了PoU。還有一種情況,就是指令緩存可以去監(jiān)聽數(shù)據(jù)緩存,此時,不需要二級緩存也能保持?jǐn)?shù)據(jù)一致,那一級數(shù)據(jù)緩存就變成了PoU。
PoC是指,對于系統(tǒng)中所有Master(注意是所有的,而不是某個核),如果存在某個點,它們的指令,數(shù)據(jù)緩存和TLB能看到同一個源,那么這個點就是PoC。如上圖右側(cè),二級緩存此時不能作為PoC,因為MasterB在它的范圍之外,直接訪問內(nèi)存。所以此時內(nèi)存是PoC。在左圖,由于只有一個Master,所以內(nèi)存是PoC。
再進一步,如果我們把右圖的內(nèi)存換成三級緩存,把內(nèi)存接在三級緩存后面,那PoC就變成了三級緩存。
有了這兩個定義,我們就可以指定TLB和緩存操作指令到底發(fā)到哪個范圍。比如在下圖的系統(tǒng)上,有兩組A15,每組四個核,組內(nèi)含二級緩存。系統(tǒng)的PoC在內(nèi)存,而A15的PoU分別在它們自己組內(nèi)的二級緩存上。在某個A15上執(zhí)行Clean清指令緩存,范圍指定PoU。顯然,所有四個A15的一級指令緩存都會被清掉。那么其他的各個Master是不是受影響?那就要用到Inner/Outer/Non Shareable。
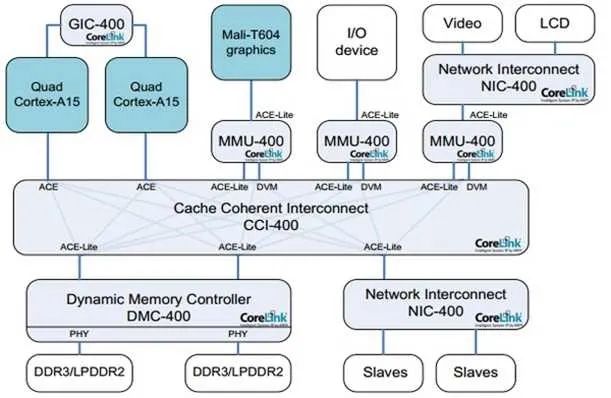
Shareable的很容易理解,就是某個地址的可能被別人使用。我們在定義某個頁屬性的時候會給出。Non-Shareable就是只有自己使用。當(dāng)然,定義成Non-Shareable不表示別人不可以用。某個地址A如果在核1上映射成Shareable,核2映射成Non-Shareable,并且兩個核通過CCI400相連。那么核1在訪問A的時候,總線會去監(jiān)聽核2,而核2訪問A的時候,總線直接訪問內(nèi)存,不監(jiān)聽核1。顯然這種做法是錯誤的。
對于Inner和Outer Shareable,有個簡單的的理解,就是認(rèn)為他們都是一個東西。在最近的ARM A系列處理器上上,配置處理器RTL的時候,會選擇是不是把inner的傳輸送到ACE口上。當(dāng)存在多個處理器簇或者需要雙向一致性的GPU時,就需要設(shè)成送到ACE端口。這樣,內(nèi)部的操作,無論inner shareable還是outer shareable,都會經(jīng)由CCI廣播到別的ACE口上。
說了這么多概念,你可能會想這有什么用處?回到上文的Clean指令,PoU使得四個A7的指令緩存中對應(yīng)的行都被清掉。由于是指令緩存操作,Inner Shareable屬性使得這個操作被擴散到總線。而CCI400總線會把這個操作廣播到所有可能接受的口上。ACE口首當(dāng)其沖,所以四個A15也會清它們對應(yīng)的指令緩存行。對于Mali和DMA控制器,他們是ACE-Lite,本不必清。但是請注意它們還連了DVM接口,專門負(fù)責(zé)收發(fā)緩存維護指令,所以它們的對應(yīng)指令緩存行也會被清。不過事實上,它們沒有對應(yīng)的指令緩存,所以只是接受請求,并沒有任何動作。
要這么復(fù)雜的定義有什么用?用處是,精確定義TLB/緩存維護和讀寫指令的范圍。如果我們改變一下,總線不支持Inner/Outer Shareable的廣播,那么就只有A7處理器組會清緩存行。顯然這么做在邏輯上不對,因為A7/A15可能運行同一行代碼。并且,我們之前提到過,如果把讀寫屬性設(shè)成Non-Shareable,那么總線就不會去監(jiān)聽其他主,減少訪問延遲,這樣可以非常靈活的提高性能。
再回到前面的問題,刷某行緩存的時候,怎么知道數(shù)據(jù)是否最終寫到了內(nèi)存中?對不起,非常抱歉,還是沒法知道。你只能做到把范圍設(shè)成PoC。如果PoC是三級緩存,那么最終刷到三級緩存,如果是內(nèi)存,那就刷到內(nèi)存。不過這在邏輯上沒有錯,按照定義,所有Master如果都在三級緩存統(tǒng)一數(shù)據(jù)的話,那就不必刷到內(nèi)存了。
簡而言之,PoU/PoC定義了指令和命令的所能抵達(dá)的緩存或內(nèi)存,在到達(dá)了指定地點后,Inner/Outer Shareable定義了它們被廣播的范圍。
再來看看Inner/Outer Cacheable,這個就簡單了,僅僅是一個緩存的前后界定。一級緩存一定是Inner Cacheable的,而最外層的緩存,比如三級,可能是Outer Cacheable,也可能是Inner Cacheable。他們的用處在于,在定義內(nèi)存頁屬性的時候,可以在不同層的緩存上有不同的處理策略。
在ARM的處理器和總線手冊中,還會出現(xiàn)幾個PoS(Point of Serialization)。它的意思是,在總線中,所有主設(shè)備來的各類請求,都必須由控制器檢查地址和類型,如果存在競爭,那就會進行串行化。這個概念和其他幾個沒什么關(guān)系。
縱觀整個總線的變化,還有一個核心問題并沒有被提及,那就是動態(tài)規(guī)劃re-scheduling與合并Merging。處理器和內(nèi)存控制器中都有同樣的模塊,專門負(fù)責(zé)把所有的傳輸進行分類,合并,調(diào)整次序,甚至預(yù)測未來可能接收到的讀寫請求地址,以實現(xiàn)最大效率的傳輸。這個問題在分析性能時會重新提到。但是在總線這層,軟件能起的影響很小。清楚了總線延遲和OT最大的好處是可以和性能計數(shù)器的統(tǒng)計結(jié)果精確匹配,看看是不是達(dá)到預(yù)期了。
現(xiàn)在手機和平板上最常見的用法,CCI連接CPU和GPU,作為子網(wǎng),網(wǎng)內(nèi)有硬件一致性。NoC連接子網(wǎng),同時連接其余的設(shè)備,包括多個內(nèi)存控制器和視頻,顯示控制器,不需要一致性。優(yōu)點是兼顧一致性,大帶寬和靈活性,缺點是CPU/GPU到內(nèi)存控制器要跨過兩個網(wǎng),延遲有點大。
訪存路徑的最后一步是內(nèi)存。有的程序員認(rèn)為內(nèi)存是一個所有地址訪問時間相等的設(shè)備,是這樣的么?這要看情況。
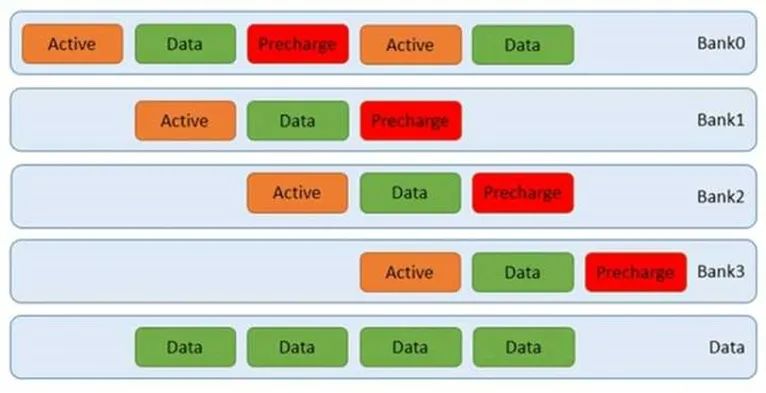
DDR地址有三個部分組成,行,bank,列。一旦這三個部分定了,那么就可以選中確定的一個物理頁,通常有2-8KB大小。我們買內(nèi)存的時候,有3個性能參數(shù),比如10-10-10。這個表示訪問一個地址所需要的三個操作時間,行有效(包括選bank),列選通(命令/數(shù)據(jù)訪問),還有預(yù)充電。前兩個好理解,第三個的意思是,某個內(nèi)存物理頁暫時用不著,必須關(guān)閉,保持電容電壓,否則再次使用這頁數(shù)據(jù)就丟失了。如果連續(xù)的內(nèi)存訪問都是在同行同bank,那么第一和第三個10都可以省略,每一次訪問只需要10單位時間;同行不同bank,表示需要打開一個新的頁,只有第三個10可以省略,共20單位時間;不同行同bank,那么需要關(guān)閉老頁面,打開一個新頁面,預(yù)充電沒法省,共30單位時間。
我們得到什么結(jié)論?如果控制好物理地址,就能使某段時間內(nèi)的訪存都集中在一個頁內(nèi),從而節(jié)省大量的時間。根據(jù)經(jīng)驗,在突發(fā)訪問時,最多可以省50%。那怎么做到這一點?去查查芯片手冊中物理內(nèi)存地址到內(nèi)存管腳的映射,就可以得到需要的物理地址。然后調(diào)用系統(tǒng)函數(shù),為這個物理地址分配虛擬地址,就可以使得程序只訪問某個固定的物理內(nèi)存頁。
在訪問有些數(shù)據(jù)結(jié)構(gòu)時,特定的大小和偏移有可能會不小心觸發(fā)不同行同bank這個條件。這樣可能每次訪問都是最差情況。為了避免這種最差情況的產(chǎn)生,有些內(nèi)存控制器可以自動讓最終地址哈希化,打亂原有的不同行同bank條件,從而在一定程度上減少延遲。我們也可以通過計算和調(diào)整軟件物理地址來避免上述情況的發(fā)生。
在實際的訪問中,通常無法保證訪問只在一個頁中。DDR內(nèi)存支持同時打開多個頁,比如4個。而通過交替訪問,我們可以同時利用這4個頁,不必等到上一次完成就開始下一個頁的訪問。這樣就可以減少平均延遲。如下圖:
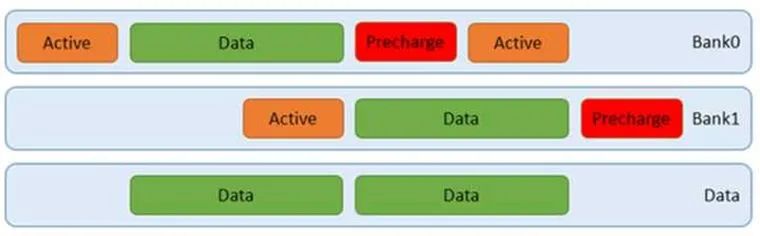
我們可以通過突發(fā)訪問,讓上圖中的綠色數(shù)據(jù)塊更長,那么相應(yīng)的利用率就越高。此時甚至不需要用到四個bank,如下圖:
如果做的更好些,我們可以通過軟件控制地址,讓上圖中的預(yù)充電,甚至行有效盡量減少,那么就可以達(dá)到更高的效率。還有,使用更好的內(nèi)存顆粒,調(diào)整配置參數(shù),減少行有效,列選通,還有預(yù)充電的時間,提高DDR傳輸頻率,也是好辦法,這點PC機超頻玩家應(yīng)該有體會。此外,在DDR板級布線的時候,控制每組時鐘,控制線,數(shù)據(jù)線之間的長度差,調(diào)整好走線阻抗,做好自校準(zhǔn),設(shè)置合理的內(nèi)存控制器參數(shù),調(diào)好眼圖,都有助于提高信號質(zhì)量,從而可以使用更短的時序參數(shù)。
如果列出所有數(shù)據(jù)突發(fā)長度情況,我們就得到了下圖:
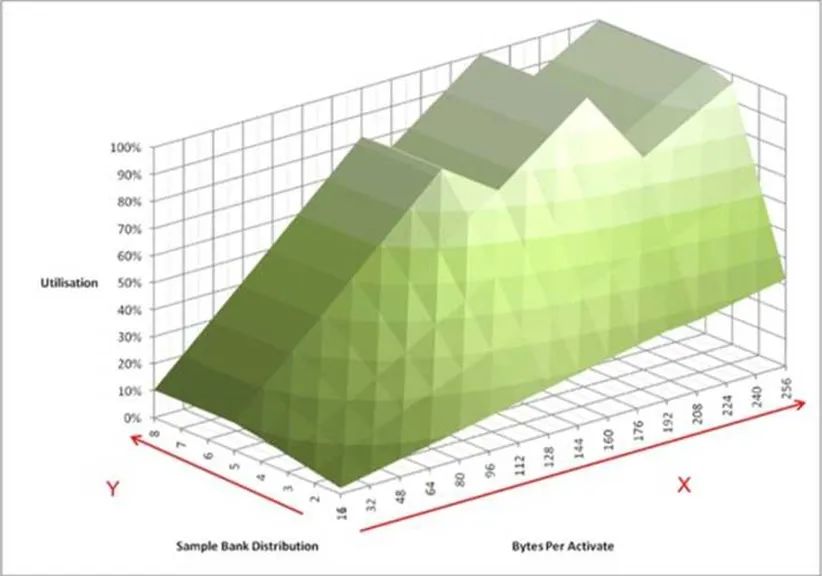
上面這個圖包含了更直觀的信息。它模擬內(nèi)存控制器連續(xù)不斷的向內(nèi)存顆粒發(fā)起訪問。X軸表示在訪問某個內(nèi)存物理頁的時候,連續(xù)地址的大小。這里有個默認(rèn)的前提,這塊地址是和內(nèi)存物理頁對齊的。Y軸表示同時打開了多少個頁。Z軸表示內(nèi)存控制器訪問內(nèi)存顆粒時帶寬的利用率。我們可以看到,有三個波峰,其中一個在128字節(jié),利用率80%。而100%的情況下,訪問長度分別為192字節(jié)和256字節(jié)。這個大小恰恰是64字節(jié)緩存行的整數(shù)倍,意味著我們可以利用三個或者四個8拍的突發(fā)訪問完成。此時,我們需要至少4個頁被打開。
還有一個重要的信息,就是X軸和Z軸的斜率。它對應(yīng)了DDR時序參數(shù)中的tFAW,限定單位時間內(nèi)同時進行的頁訪問數(shù)量。這個數(shù)字越小,性能可能越低,但是同樣的功耗就越低。
對于不同的DDR,上面的模型會不斷變化。而設(shè)計DDR控制器的目的,就是讓利用率盡量保持在100%。要做到這點,需要不斷的把收到的讀寫請求分類,合并,調(diào)整次序。而從軟件角度,產(chǎn)生更多的緩存行對齊的讀寫,保持地址連續(xù),盡量命中已打開頁,減少行地址和bank地址切換,都是減少內(nèi)存訪問延遲的方法。
交替訪問也能提高訪存性能。上文已經(jīng)提到了物理頁的交替,還可以有片選信號的交替訪問。當(dāng)有兩個內(nèi)存控制器的時候,控制器之間還可以交替。無論哪種交替訪問,都是在前一個訪問完成前,同時開始下一個傳輸。當(dāng)然,前提必須是他們使用的硬件不沖突。物理頁,片選,控制器符合這一個要求。交替訪問之后,原本連續(xù)分布在一個控制器的地址被分散到幾個不同的控制器。最終期望的效果如下圖:
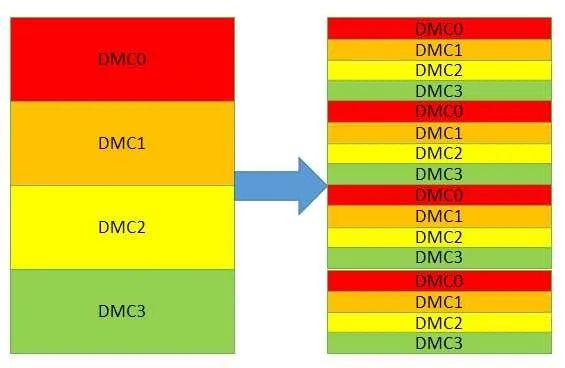
這種方法對連續(xù)的地址訪問效果最好。但是實際的訪存并沒有上圖那么理想,因為哪怕是連續(xù)的讀,由于緩存中存在替換eviction和硬件預(yù)取,最終送出的連續(xù)地址序列也會插入擾動,而如果取消緩存直接訪存,可能又沒法利用到硬件的預(yù)取機制和額外的OT資源。
實測下來,可能會提升30%左右。此外,由于多個主設(shè)備的存在,每一個主都產(chǎn)生不同的連續(xù)地址,使得效果進一步降低。因此,只有采用交織訪問才能真正的實現(xiàn)均勻訪問多個內(nèi)存控制器。
當(dāng)然,此時的突發(fā)長度和粒度要匹配,不然粒度太大也沒法均勻,就算均勻了也未必是最優(yōu)的。對于某個內(nèi)存控制來說,最好的期望是總收到同一個物理頁內(nèi)的請求。
還有一點需要提及。如果使用了帶ecc的內(nèi)存,那么最好所有的訪問都是ddr帶寬對齊(一般64位)。因為使能ecc后,所有內(nèi)存訪問都是帶寬對齊的,不然ecc沒法算。如果你寫入小于帶寬的數(shù)據(jù),內(nèi)存控制器需要知道原來的數(shù)據(jù)是多少,于是就去讀,然后改動其中一部分,再計算新的ecc值,再寫入。這樣就多了一個讀的過程。根據(jù)經(jīng)驗,如果訪存很多,關(guān)閉ecc會快8%。
編輯:jq
-
處理器
+關(guān)注
關(guān)注
68文章
19920瀏覽量
235665 -
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7259瀏覽量
92038 -
總線
+關(guān)注
關(guān)注
10文章
2961瀏覽量
89835
原文標(biāo)題:技術(shù)分享 | ARM攢機指南 - 基礎(chǔ)篇
文章出處:【微信號:Ithingedu,微信公眾號:安芯教育科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
RK3568驅(qū)動指南|第十二篇 GPIO子系統(tǒng)-第130章 GPIO的調(diào)試方法

RK3568驅(qū)動指南|第十二篇 GPIO子系統(tǒng)-第135章 GPIO子系統(tǒng)與pinctrl子系統(tǒng)相結(jié)合實驗

RK3568驅(qū)動指南|驅(qū)動基礎(chǔ)進階篇-進階7 向系統(tǒng)中添加一個系統(tǒng)調(diào)用
國產(chǎn)ARM主板:自主創(chuàng)新的崛起與未來挑戰(zhàn)

STM32開發(fā)板教程之STM32開發(fā)指南免費下載
華為PCB的EMC設(shè)計指南【可下載】
RK3568驅(qū)動指南|第三篇-并發(fā)與競爭-第19章 并發(fā)與競爭實驗

Arm預(yù)測2025年芯片設(shè)計發(fā)展趨勢
華為PCB的EMC設(shè)計指南

迅為iTOP-RK3568開發(fā)板驅(qū)動開發(fā)指南-第十八篇 PWM
【北京迅為】i.mx8mm嵌入式linux開發(fā)指南第四篇 嵌入式Linux系統(tǒng)移植篇第六十九章uboot移植

從STM32到基于Arm的MSPM0的遷移指南

從遷移到基于Arm STM32的MSPMO指南
從Renesas RL78到基于Arm的MSPM0的遷移指南
安森美光伏逆變器系統(tǒng)設(shè)計指南





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論