 SparkSQL編程基本概念和基本用法
SparkSQL編程基本概念和基本用法
本節將介紹SparkSQL編程基本概念和基本用法。
不同于RDD編程的命令式編程范式,SparkSQL編程是一種聲明式編程范式,我們可以通過SQL語句或者調用DataFrame的相關API描述我們想要實現的操作。
然后Spark會將我們的描述進行語法解析,找到相應的執行計劃并對其進行流程優化,然后調用相應基礎命令進行執行。
我們使用pyspark進行RDD編程時,在Excutor上跑的很多時候就是Python代碼,當然,少數時候也會跑java字節碼。
但我們使用pyspark進行SparkSQL編程時,在Excutor上跑的全部是java字節碼,pyspark在Driver端就將相應的Python代碼轉換成了java任務然后放到Excutor上執行。
因此,使用SparkSQL的編程范式進行編程,我們能夠取得幾乎和直接使用scala/java進行編程相當的效率(忽略語法解析時間差異)。此外SparkSQL提供了非常方便的數據讀寫API,我們可以用它和Hive表,HDFS,mysql表,Cassandra,Hbase等各種存儲媒介進行數據交換。
美中不足的是,SparkSQL的靈活性會稍差一些,其默認支持的數據類型通常只有 Int,Long,Float,Double,String,Boolean 等這些標準SQL數據類型, 類型擴展相對繁瑣。對于一些較為SQL中不直接支持的功能,通常可以借助于用戶自定義函數(UDF)來實現,如果功能更加復雜,則可以轉成RDD來進行實現。
本節我們將主要介紹以下主要內容:
-
RDD和DataFrame的對比
-
創建DataFrame
-
DataFrame保存成文件
-
DataFrame的API交互
-
DataFrame的SQL交互
importfindspark
#指定spark_home為剛才的解壓路徑,指定python路徑
spark_home="/Users/liangyun/ProgramFiles/spark-3.0.1-bin-hadoop3.2"
python_path="/Users/liangyun/anaconda3/bin/python"
findspark.init(spark_home,python_path)
importpyspark
frompyspark.sqlimportSparkSession
#SparkSQL的許多功能封裝在SparkSession的方法接口中
spark=SparkSession.builder
.appName("test")
.config("master","local[4]")
.enableHiveSupport()
.getOrCreate()
sc=spark.sparkContext
一,RDD,DataFrame和DataSet對比
DataFrame參照了Pandas的思想,在RDD基礎上增加了schma,能夠獲取列名信息。
DataSet在DataFrame基礎上進一步增加了數據類型信息,可以在編譯時發現類型錯誤。
DataFrame可以看成DataSet[Row],兩者的API接口完全相同。
DataFrame和DataSet都支持SQL交互式查詢,可以和 Hive無縫銜接。
DataSet只有Scala語言和Java語言接口中才支持,在Python和R語言接口只支持DataFrame。
DataFrame數據結構本質上是通過RDD來實現的,但是RDD是一種行存儲的數據結構,而DataFrame是一種列存儲的數據結構。
二,創建DataFrame
1,通過toDF方法轉換成DataFrame
可以將RDD用toDF方法轉換成DataFrame
#將RDD轉換成DataFrame
rdd=sc.parallelize([("LiLei",15,88),("HanMeiMei",16,90),("DaChui",17,60)])
df=rdd.toDF(["name","age","score"])
df.show()
df.printSchema()
+---------+---+-----+
|name|age|score|
+---------+---+-----+
|LiLei|15|88|
|HanMeiMei|16|90|
|DaChui|17|60|
+---------+---+-----+
root
|--name:string(nullable=true)
|--age:long(nullable=true)
|--score:long(nullable=true)
2, 通過createDataFrame方法將Pandas.DataFrame轉換成pyspark中的DataFrame
importpandasaspd
pdf=pd.DataFrame([("LiLei",18),("HanMeiMei",17)],columns=["name","age"])
df=spark.createDataFrame(pdf)
df.show()
+---------+---+
|name|age|
+---------+---+
|LiLei|18|
|HanMeiMei|17|
+---------+---+
#也可以對列表直接轉換
values=[("LiLei",18),("HanMeiMei",17)]
df=spark.createDataFrame(values,["name","age"])
df.show()
+---------+---+
|name|age|
+---------+---+
|LiLei|18|
|HanMeiMei|17|
+---------+---+
4, 通過createDataFrame方法指定schema動態創建DataFrame
可以通過createDataFrame的方法指定rdd和schema創建DataFrame。
這種方法比較繁瑣,但是可以在預先不知道schema和數據類型的情況下在代碼中動態創建DataFrame.
frompyspark.sql.typesimport*
frompyspark.sqlimportRow
fromdatetimeimportdatetime
schema=StructType([StructField("name",StringType(),nullable=False),
StructField("score",IntegerType(),nullable=True),
StructField("birthday",DateType(),nullable=True)])
rdd=sc.parallelize([Row("LiLei",87,datetime(2010,1,5)),
Row("HanMeiMei",90,datetime(2009,3,1)),
Row("DaChui",None,datetime(2008,7,2))])
dfstudent=spark.createDataFrame(rdd,schema)
dfstudent.show()
+---------+-----+----------+
|name|score|birthday|
+---------+-----+----------+
|LiLei|87|2010-01-05|
|HanMeiMei|90|2009-03-01|
|DaChui|null|2008-07-02|
+---------+-----+----------+
4,通過讀取文件創建
可以讀取json文件,csv文件,hive數據表或者mysql數據表得到DataFrame。
#讀取json文件生成DataFrame
df=spark.read.json("data/people.json")
df.show()
+----+-------+
|age|name|
+----+-------+
|null|Michael|
|30|Andy|
|19|Justin|
+----+-------+
#讀取csv文件
df=spark.read.option("header","true")
.option("inferSchema","true")
.option("delimiter",",")
.csv("data/iris.csv")
df.show(5)
df.printSchema()
+-----------+----------+-----------+----------+-----+
|sepallength|sepalwidth|petallength|petalwidth|label|
+-----------+----------+-----------+----------+-----+
|5.1|3.5|1.4|0.2|0|
|4.9|3.0|1.4|0.2|0|
|4.7|3.2|1.3|0.2|0|
|4.6|3.1|1.5|0.2|0|
|5.0|3.6|1.4|0.2|0|
+-----------+----------+-----------+----------+-----+
onlyshowingtop5rows
root
|--sepallength:double(nullable=true)
|--sepalwidth:double(nullable=true)
|--petallength:double(nullable=true)
|--petalwidth:double(nullable=true)
|--label:integer(nullable=true)
#讀取csv文件
df=spark.read.format("com.databricks.spark.csv")
.option("header","true")
.option("inferSchema","true")
.option("delimiter",",")
.load("data/iris.csv")
df.show(5)
df.printSchema()
+-----------+----------+-----------+----------+-----+
|sepallength|sepalwidth|petallength|petalwidth|label|
+-----------+----------+-----------+----------+-----+
|5.1|3.5|1.4|0.2|0|
|4.9|3.0|1.4|0.2|0|
|4.7|3.2|1.3|0.2|0|
|4.6|3.1|1.5|0.2|0|
|5.0|3.6|1.4|0.2|0|
+-----------+----------+-----------+----------+-----+
onlyshowingtop5rows
root
|--sepallength:double(nullable=true)
|--sepalwidth:double(nullable=true)
|--petallength:double(nullable=true)
|--petalwidth:double(nullable=true)
|--label:integer(nullable=true)
#讀取parquet文件
df=spark.read.parquet("data/users.parquet")
df.show()
+------+--------------+----------------+
|name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa|null|[3,9,15,20]|
|Ben|red|[]|
+------+--------------+----------------+
#讀取hive數據表生成DataFrame
spark.sql("CREATETABLEIFNOTEXISTSsrc(keyINT,valueSTRING)USINGhive")
spark.sql("LOADDATALOCALINPATH'data/kv1.txt'INTOTABLEsrc")
df=spark.sql("SELECTkey,valueFROMsrcWHEREkey)
df.show(5)
+---+-----+
|key|value|
+---+-----+
|0|val_0|
|0|val_0|
|0|val_0|
|0|val_0|
|0|val_0|
+---+-----+
onlyshowingtop5rows
#讀取mysql數據表生成DataFrame
"""
url="jdbc//localhost:3306/test"
df=spark.read.format("jdbc")
.option("url",url)
.option("dbtable","runoob_tbl")
.option("user","root")
.option("password","0845")
.load()
df.show()
"""
三,DataFrame保存成文件
可以保存成csv文件,json文件,parquet文件或者保存成hive數據表
#保存成csv文件
df=spark.read.format("json").load("data/people.json")
df.write.format("csv").option("header","true").save("data/people_write.csv")
#先轉換成rdd再保存成txt文件
df.rdd.saveAsTextFile("data/people_rdd.txt")
#保存成json文件
df.write.json("data/people_write.json")
#保存成parquet文件,壓縮格式,占用存儲小,且是spark內存中存儲格式,加載最快
df.write.partitionBy("age").format("parquet").save("data/namesAndAges.parquet")
df.write.parquet("data/people_write.parquet")
#保存成hive數據表
df.write.bucketBy(42,"name").sortBy("age").saveAsTable("people_bucketed")
四,DataFrame的API交互
frompyspark.sqlimportRow
frompyspark.sql.functionsimport*
df=spark.createDataFrame(
[("LiLei",15,"male"),
("HanMeiMei",16,"female"),
("DaChui",17,"male")]).toDF("name","age","gender")
df.show()
df.printSchema()
+---------+---+------+
|name|age|gender|
+---------+---+------+
|LiLei|15|male|
|HanMeiMei|16|female|
|DaChui|17|male|
+---------+---+------+
root
|--name:string(nullable=true)
|--age:long(nullable=true)
|--gender:string(nullable=true)
1,Action操作
DataFrame的Action操作包括show,count,collect,,describe,take,head,first等操作。
#show
df.show()
+---------+---+------+
|name|age|gender|
+---------+---+------+
|LiLei|15|male|
|HanMeiMei|16|female|
|DaChui|17|male|
+---------+---+------+
#show(numRows:Int,truncate:Boolean)
#第二個參數設置是否當輸出字段長度超過20時進行截取
df.show(2,False)
+---------+---+------+
|name|age|gender|
+---------+---+------+
|LiLei|15|male|
|HanMeiMei|16|female|
+---------+---+------+
onlyshowingtop2rows
#count
df.count()
3
#collect
df.collect()
[Row(name='LiLei',age=15,gender='male'),
Row(name='HanMeiMei',age=16,gender='female'),
Row(name='DaChui',age=17,gender='male')]
#first
df.first()
Row(name='LiLei',age=15,gender='male')
#take
df.take(2)
[Row(name='LiLei',age=15,gender='male'),
Row(name='HanMeiMei',age=16,gender='female')]
#head
df.head(2)
[Row(name='LiLei',age=15,gender='male'),
Row(name='HanMeiMei',age=16,gender='female')]
2,類RDD操作
DataFrame支持RDD中一些諸如distinct,cache,sample,foreach,intersect,except等操作。
可以把DataFrame當做數據類型為Row的RDD來進行操作,必要時可以將其轉換成RDD來操作。
df=spark.createDataFrame([("HelloWorld",),("HelloChina",),("HelloSpark",)]).toDF("value")
df.show()
+-----------+
|value|
+-----------+
|HelloWorld|
|HelloChina|
|HelloSpark|
+-----------+
#map操作,需要先轉換成rdd
rdd=df.rdd.map(lambdax:Row(x[0].upper()))
dfmap=rdd.toDF(["value"]).show()
+-----------+
|value|
+-----------+
|HELLOWORLD|
|HELLOCHINA|
|HELLOSPARK|
+-----------+
#flatMap,需要先轉換成rdd
df_flat=df.rdd.flatMap(lambdax:x[0].split("")).map(lambdax:Row(x)).toDF(["value"])
df_flat.show()
+-----+
|value|
+-----+
|Hello|
|World|
|Hello|
|China|
|Hello|
|Spark|
+-----+
#filter過濾
df_filter=df.rdd.filter(lambdas:s[0].endswith("Spark")).toDF(["value"])
df_filter.show()
+-----------+
|value|
+-----------+
|HelloSpark|
+-----------+
#filter和broadcast混合使用
broads=sc.broadcast(["Hello","World"])
df_filter_broad=df_flat.filter(~col("value").isin(broads.value))
df_filter_broad.show()
+-----+
|value|
+-----+
|China|
|Spark|
+-----+
#distinct
df_distinct=df_flat.distinct()
df_distinct.show()
+-----+
|value|
+-----+
|World|
|China|
|Hello|
|Spark|
+-----+
#cache緩存
df.cache()
df.unpersist()
#sample抽樣
dfsample=df.sample(False,0.6,0)
dfsample.show()
+-----------+
|value|
+-----------+
|HelloChina|
|HelloSpark|
+-----------+
df2=spark.createDataFrame([["HelloWorld"],["HelloScala"],["HelloSpark"]]).toDF("value")
df2.show()
+-----------+
|value|
+-----------+
|HelloWorld|
|HelloScala|
|HelloSpark|
+-----------+
#intersect交集
dfintersect=df.intersect(df2)
dfintersect.show()
+-----------+
|value|
+-----------+
|HelloSpark|
|HelloWorld|
+-----------+
#exceptAll補集
dfexcept=df.exceptAll(df2)
dfexcept.show()
+-----------+
|value|
+-----------+
|HelloChina|
+-----------+
3,類Excel操作
可以對DataFrame進行增加列,刪除列,重命名列,排序等操作,去除重復行,去除空行,就跟操作Excel表格一樣。
df=spark.createDataFrame([
("LiLei",15,"male"),
("HanMeiMei",16,"female"),
("DaChui",17,"male"),
("RuHua",16,None)
]).toDF("name","age","gender")
df.show()
df.printSchema()
+---------+---+------+
|name|age|gender|
+---------+---+------+
|LiLei|15|male|
|HanMeiMei|16|female|
|DaChui|17|male|
|RuHua|16|null|
+---------+---+------+
root
|--name:string(nullable=true)
|--age:long(nullable=true)
|--gender:string(nullable=true)
#增加列
dfnew=df.withColumn("birthyear",-df["age"]+2020)
dfnew.show()
+---------+---+------+---------+
|name|age|gender|birthyear|
+---------+---+------+---------+
|LiLei|15|male|2005|
|HanMeiMei|16|female|2004|
|DaChui|17|male|2003|
|RuHua|16|null|2004|
+---------+---+------+---------+
#置換列的順序
dfupdate=dfnew.select("name","age","birthyear","gender")
dfupdate.show()
#刪除列
dfdrop=df.drop("gender")
dfdrop.show()
+---------+---+
|name|age|
+---------+---+
|LiLei|15|
|HanMeiMei|16|
|DaChui|17|
|RuHua|16|
+---------+---+
#重命名列
dfrename=df.withColumnRenamed("gender","sex")
dfrename.show()
+---------+---+------+
|name|age|sex|
+---------+---+------+
|LiLei|15|male|
|HanMeiMei|16|female|
|DaChui|17|male|
|RuHua|16|null|
+---------+---+------+
#排序sort,可以指定升序降序
dfsorted=df.sort(df["age"].desc())
dfsorted.show()
+---------+---+------+
|name|age|gender|
+---------+---+------+
|DaChui|17|male|
|RuHua|16|null|
|HanMeiMei|16|female|
|LiLei|15|male|
+---------+---+------+
#排序orderby,默認為升序,可以根據多個字段
dfordered=df.orderBy(df["age"].desc(),df["gender"].desc())
dfordered.show()
+---------+---+------+
|name|age|gender|
+---------+---+------+
|DaChui|17|male|
|HanMeiMei|16|female|
|RuHua|16|null|
|LiLei|15|male|
+---------+---+------+
#去除nan值行
dfnotnan=df.na.drop()
dfnotnan.show()
+---------+---+------+
|name|age|gender|
+---------+---+------+
|LiLei|15|male|
|HanMeiMei|16|female|
|DaChui|17|male|
+---------+---+------+
#填充nan值
df_fill=df.na.fill("female")
df_fill.show()
+---------+---+------+
|name|age|gender|
+---------+---+------+
|LiLei|15|male|
|HanMeiMei|16|female|
|DaChui|17|male|
|RuHua|16|female|
+---------+---+------+
#替換某些值
df_replace=df.na.replace({"":"female","RuHua":"SiYu"})
df_replace.show()
+---------+---+------+
|name|age|gender|
+---------+---+------+
|LiLei|15|male|
|HanMeiMei|16|female|
|DaChui|17|male|
|SiYu|16|null|
+---------+---+------+
#去重,默認根據全部字段
df2=df.unionAll(df)
df2.show()
dfunique=df2.dropDuplicates()
dfunique.show()
+---------+---+------+
|name|age|gender|
+---------+---+------+
|LiLei|15|male|
|HanMeiMei|16|female|
|DaChui|17|male|
|RuHua|16|null|
|LiLei|15|male|
|HanMeiMei|16|female|
|DaChui|17|male|
|RuHua|16|null|
+---------+---+------+
+---------+---+------+
|name|age|gender|
+---------+---+------+
|RuHua|16|null|
|DaChui|17|male|
|HanMeiMei|16|female|
|LiLei|15|male|
+---------+---+------+
#去重,根據部分字段
dfunique_part=df.dropDuplicates(["age"])
dfunique_part.show()
+---------+---+------+
|name|age|gender|
+---------+---+------+
|DaChui|17|male|
|LiLei|15|male|
|HanMeiMei|16|female|
+---------+---+------+
#簡單聚合操作
dfagg=df.agg({"name":"count","age":"max"})
dfagg.show()
+-----------+--------+
|count(name)|max(age)|
+-----------+--------+
|4|17|
+-----------+--------+
#匯總信息
df_desc=df.describe()
df_desc.show()
+-------+------+-----------------+------+
|summary|name|age|gender|
+-------+------+-----------------+------+
|count|4|4|3|
|mean|null|16.0|null|
|stddev|null|0.816496580927726|null|
|min|DaChui|15|female|
|max|RuHua|17|male|
+-------+------+-----------------+------+
#頻率超過0.5的年齡和性別
df_freq=df.stat.freqItems(("age","gender"),0.5)
df_freq.show()
+-------------+----------------+
|age_freqItems|gender_freqItems|
+-------------+----------------+
|[16]|[male]|
+-------------+----------------+
4,類SQL表操作
類SQL表操作主要包括表查詢(select,selectExpr,where),表連接(join,union,unionAll),表分組(groupby,agg,pivot)等操作。
df=spark.createDataFrame([
("LiLei",15,"male"),
("HanMeiMei",16,"female"),
("DaChui",17,"male"),
("RuHua",16,None)]).toDF("name","age","gender")
df.show()
+---------+---+------+
|name|age|gender|
+---------+---+------+
|LiLei|15|male|
|HanMeiMei|16|female|
|DaChui|17|male|
|RuHua|16|null|
+---------+---+------+
#表查詢select
dftest=df.select("name").limit(2)
dftest.show()
+---------+
|name|
+---------+
|LiLei|
|HanMeiMei|
+---------+
dftest=df.select("name",df["age"]+1)
dftest.show()
+---------+---------+
|name|(age+1)|
+---------+---------+
|LiLei|16|
|HanMeiMei|17|
|DaChui|18|
|RuHua|17|
+---------+---------+
#表查詢select
dftest=df.select("name",-df["age"]+2020).toDF("name","birth_year")
dftest.show()
+---------+----------+
|name|birth_year|
+---------+----------+
|LiLei|2005|
|HanMeiMei|2004|
|DaChui|2003|
|RuHua|2004|
+---------+----------+
#表查詢selectExpr,可以使用UDF函數,指定別名等
importdatetime
spark.udf.register("getBirthYear",lambdaage:datetime.datetime.now().year-age)
dftest=df.selectExpr("name","getBirthYear(age)asbirth_year","UPPER(gender)asgender")
dftest.show()
+---------+----------+------+
|name|birth_year|gender|
+---------+----------+------+
|LiLei|2005|MALE|
|HanMeiMei|2004|FEMALE|
|DaChui|2003|MALE|
|RuHua|2004|null|
+---------+----------+------+
#表查詢where,指定SQL中的where字句表達式
dftest=df.where("gender='male'andage>15")
dftest.show()
+------+---+------+
|name|age|gender|
+------+---+------+
|DaChui|17|male|
+------+---+------+
#表查詢filter
dftest=df.filter(df["age"]>16)
dftest.show()
+------+---+------+
|name|age|gender|
+------+---+------+
|DaChui|17|male|
+------+---+------+
#表查詢filter
dftest=df.filter("gender='male'")
dftest.show()
+------+---+------+
|name|age|gender|
+------+---+------+
|LiLei|15|male|
|DaChui|17|male|
+------+---+------+
#表連接join
dfscore=spark.createDataFrame([("LiLei","male",88),("HanMeiMei","female",90),("DaChui","male",50)])
.toDF("name","gender","score")
dfscore.show()
+---------+------+-----+
|name|gender|score|
+---------+------+-----+
|LiLei|male|88|
|HanMeiMei|female|90|
|DaChui|male|50|
+---------+------+-----+
#表連接join,根據單個字段
dfjoin=df.join(dfscore.select("name","score"),"name")
dfjoin.show()
+---------+---+------+-----+
|name|age|gender|score|
+---------+---+------+-----+
|LiLei|15|male|88|
|HanMeiMei|16|female|90|
|DaChui|17|male|50|
+---------+---+------+-----+
#表連接join,根據多個字段
dfjoin=df.join(dfscore,["name","gender"])
dfjoin.show()
+---------+------+---+-----+
|name|gender|age|score|
+---------+------+---+-----+
|HanMeiMei|female|16|90|
|DaChui|male|17|50|
|LiLei|male|15|88|
+---------+------+---+-----+
#表連接join,根據多個字段
#可以指定連接方式為"inner","left","right","outer","semi","full","leftanti","anti"等多種方式
dfjoin=df.join(dfscore,["name","gender"],"right")
dfjoin.show()
+---------+------+---+-----+
|name|gender|age|score|
+---------+------+---+-----+
|HanMeiMei|female|16|90|
|DaChui|male|17|50|
|LiLei|male|15|88|
+---------+------+---+-----+
dfjoin=df.join(dfscore,["name","gender"],"outer")
dfjoin.show()
+---------+------+---+-----+
|name|gender|age|score|
+---------+------+---+-----+
|HanMeiMei|female|16|90|
|DaChui|male|17|50|
|LiLei|male|15|88|
|RuHua|null|16|null|
+---------+------+---+-----+
#表連接,靈活指定連接關系
dfmark=dfscore.withColumnRenamed("gender","sex")
dfmark.show()
+---------+------+-----+
|name|sex|score|
+---------+------+-----+
|LiLei|male|88|
|HanMeiMei|female|90|
|DaChui|male|50|
+---------+------+-----+
dfjoin=df.join(dfmark,(df["name"]==dfmark["name"])&(df["gender"]==dfmark["sex"]),
"inner")
dfjoin.show()
+---------+---+------+---------+------+-----+
|name|age|gender|name|sex|score|
+---------+---+------+---------+------+-----+
|HanMeiMei|16|female|HanMeiMei|female|90|
|DaChui|17|male|DaChui|male|50|
|LiLei|15|male|LiLei|male|88|
+---------+---+------+---------+------+-----+
#表合并union
dfstudent=spark.createDataFrame([("Jim",18,"male"),("Lily",16,"female")]).toDF("name","age","gender")
dfstudent.show()
+----+---+------+
|name|age|gender|
+----+---+------+
|Jim|18|male|
|Lily|16|female|
+----+---+------+
dfunion=df.union(dfstudent)
dfunion.show()
+---------+---+------+
|name|age|gender|
+---------+---+------+
|LiLei|15|male|
|HanMeiMei|16|female|
|DaChui|17|male|
|RuHua|16|null|
|Jim|18|male|
|Lily|16|female|
+---------+---+------+
#表分組groupBy
frompyspark.sqlimportfunctionsasF
dfgroup=df.groupBy("gender").max("age")
dfgroup.show()
+------+--------+
|gender|max(age)|
+------+--------+
|null|16|
|female|16|
|male|17|
+------+--------+
#表分組后聚合,groupBy,agg
dfagg=df.groupBy("gender").agg(F.mean("age").alias("mean_age"),
F.collect_list("name").alias("names"))
dfagg.show()
+------+--------+---------------+
|gender|mean_age|names|
+------+--------+---------------+
|null|16.0|[RuHua]|
|female|16.0|[HanMeiMei]|
|male|16.0|[LiLei,DaChui]|
+------+--------+---------------+
#表分組聚合,groupBy,agg
dfagg=df.groupBy("gender").agg(F.expr("avg(age)"),F.expr("collect_list(name)"))
dfagg.show()
+------+--------+------------------+
|gender|avg(age)|collect_list(name)|
+------+--------+------------------+
|null|16.0|[RuHua]|
|female|16.0|[HanMeiMei]|
|male|16.0|[LiLei,DaChui]|
+------+--------+------------------+
#表分組聚合,groupBy,agg
df.groupBy("gender","age").agg(F.collect_list(col("name"))).show()
+------+---+------------------+
|gender|age|collect_list(name)|
+------+---+------------------+
|male|15|[LiLei]|
|male|17|[DaChui]|
|female|16|[HanMeiMei]|
|null|16|[RuHua]|
+------+---+------------------+
#表分組后透視,groupBy,pivot
dfstudent=spark.createDataFrame([("LiLei",18,"male",1),("HanMeiMei",16,"female",1),
("Jim",17,"male",2),("DaChui",20,"male",2)]).toDF("name","age","gender","class")
dfstudent.show()
dfstudent.groupBy("class").pivot("gender").max("age").show()
+---------+---+------+-----+
|name|age|gender|class|
+---------+---+------+-----+
|LiLei|18|male|1|
|HanMeiMei|16|female|1|
|Jim|17|male|2|
|DaChui|20|male|2|
+---------+---+------+-----+
+-----+------+----+
|class|female|male|
+-----+------+----+
|1|16|18|
|2|null|20|
+-----+------+----+
#窗口函數
df=spark.createDataFrame([("LiLei",78,"class1"),("HanMeiMei",87,"class1"),
("DaChui",65,"class2"),("RuHua",55,"class2")])
.toDF("name","score","class")
df.show()
dforder=df.selectExpr("name","score","class",
"row_number()over(partitionbyclassorderbyscoredesc)asorder")
dforder.show()
+---------+-----+------+
|name|score|class|
+---------+-----+------+
|LiLei|78|class1|
|HanMeiMei|87|class1|
|DaChui|65|class2|
|RuHua|55|class2|
+---------+-----+------+
+---------+-----+------+-----+
|name|score|class|order|
+---------+-----+------+-----+
|DaChui|65|class2|1|
|RuHua|55|class2|2|
|HanMeiMei|87|class1|1|
|LiLei|78|class1|2|
+---------+-----+------+-----+
六,DataFrame的SQL交互
將DataFrame注冊為臨時表視圖或者全局表視圖后,可以使用sql語句對DataFrame進行交互。
不僅如此,還可以通過SparkSQL對Hive表直接進行增刪改查等操作。
1,注冊視圖后進行SQL交互
#注冊為臨時表視圖,其生命周期和SparkSession相關聯
df=spark.createDataFrame([("LiLei",18,"male"),("HanMeiMei",17,"female"),("Jim",16,"male")],
("name","age","gender"))
df.show()
df.createOrReplaceTempView("student")
dfmale=spark.sql("select*fromstudentwheregender='male'")
dfmale.show()
+---------+---+------+
|name|age|gender|
+---------+---+------+
|LiLei|18|male|
|HanMeiMei|17|female|
|Jim|16|male|
+---------+---+------+
+-----+---+------+
|name|age|gender|
+-----+---+------+
|LiLei|18|male|
|Jim|16|male|
+-----+---+------+
#注冊為全局臨時表視圖,其生命周期和整個Spark應用程序關聯
df.createOrReplaceGlobalTempView("student")
query="""
selectt.gender
,collect_list(t.name)asnames
fromglobal_temp.studentt
groupbyt.gender
""".strip("
")
spark.sql(query).show()
#可以在新的Session中訪問
spark.newSession().sql("select*fromglobal_temp.student").show()
+------+------------+
|gender|names|
+------+------------+
|female|[HanMeiMei]|
|male|[LiLei,Jim]|
+------+------------+
+---------+---+------+
|name|age|gender|
+---------+---+------+
|LiLei|18|male|
|HanMeiMei|17|female|
|Jim|16|male|
+---------+---+------+
2,對Hive表進行增刪改查操作
#刪除hive表
query="DROPTABLEIFEXISTSstudents"
spark.sql(query)
#建立hive分區表
#(注:不可以使用中文字段作為分區字段)
query="""CREATETABLEIFNOTEXISTS`students`
(`name`STRINGCOMMENT'姓名',
`age`INTCOMMENT'年齡'
)
PARTITIONEDBY(`class`STRINGCOMMENT'班級',`gender`STRINGCOMMENT'性別')
""".replace("
","")
spark.sql(query)
##動態寫入數據到hive分區表
spark.conf.set("hive.exec.dynamic.partition.mode","nonstrict")#注意此處有一個設置操作
dfstudents=spark.createDataFrame([("LiLei",18,"class1","male"),
("HanMeimei",17,"class2","female"),
("DaChui",19,"class2","male"),
("Lily",17,"class1","female")]).toDF("name","age","class","gender")
dfstudents.show()
#動態寫入分區
dfstudents.write.mode("overwrite").format("hive")
.partitionBy("class","gender").saveAsTable("students")
#寫入到靜態分區
dfstudents=spark.createDataFrame([("Jim",18,"class3","male"),
("Tom",19,"class3","male")]).toDF("name","age","class","gender")
dfstudents.createOrReplaceTempView("dfclass3")
#INSERTINTO尾部追加,INSERTOVERWRITETABLE覆蓋分區
query="""
INSERTOVERWRITETABLE`students`
PARTITION(class='class3',gender='male')
SELECTname,agefromdfclass3
""".replace("
","")
spark.sql(query)
#寫入到混合分區
dfstudents=spark.createDataFrame([("David",18,"class4","male"),
("Amy",17,"class4","female"),
("Jerry",19,"class4","male"),
("Ann",17,"class4","female")]).toDF("name","age","class","gender")
dfstudents.createOrReplaceTempView("dfclass4")
query="""
INSERTOVERWRITETABLE`students`
PARTITION(class='class4',gender)
SELECTname,age,genderfromdfclass4
""".replace("
","")
spark.sql(query)
#讀取全部數據
dfdata=spark.sql("select*fromstudents")
dfdata.show()
+---------+---+------+------+
|name|age|class|gender|
+---------+---+------+------+
|Ann|17|class4|female|
|Amy|17|class4|female|
|HanMeimei|17|class2|female|
|DaChui|19|class2|male|
|LiLei|18|class1|male|
|Lily|17|class1|female|
|Jerry|19|class4|male|
|David|18|class4|male|
|Jim|18|class3|male|
|Tom|19|class3|male|
+---------+---+------+------+
-
編程
+關注
關注
88文章
3614瀏覽量
93686 -
SQL
+關注
關注
1文章
762瀏覽量
44117
原文標題:2 小時入門 SparkSQL 編程
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何快速入門HAL庫編程 HAL庫與裸機編程的比較
X電容和Y電容的基本概念
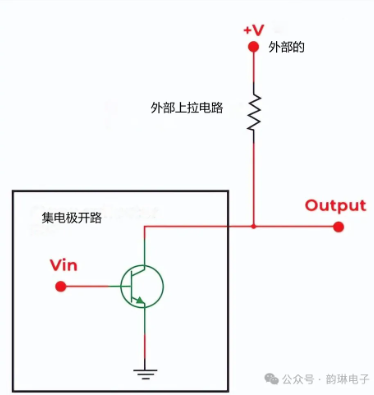
集電極開路的基本概念與原理
DDR4的基本概念和特性
伺服系統基本概念和與變頻的關系
socket的基本概念和原理
BP網絡的基本概念和訓練原理
卷積神經網絡的基本概念、原理及特點
循環神經網絡的基本概念
人機界面觸摸屏編程的基本概念及硬件選擇
組合邏輯控制器的基本概念、實現原理及設計方法

Docker網絡的基本概念和原理與用法
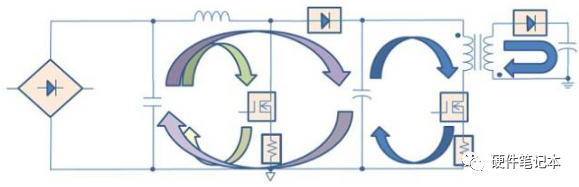
電源路徑的基本概念





 工商網監
工商網監
評論