 我們怎樣讀源碼才能更高效
我們怎樣讀源碼才能更高效
用了這么久的 Redis,也翻了很多次源碼,經常有人問我到底怎么讀 Redis 源碼。
一提到讀源碼,很多人都會比較畏懼,認為讀源碼是高手才會做的事情。他們可能遇到問題時,會更傾向于去找別人分享的答案。但往往很多時候,自己查到的資料并不能解決所有問題,尤其是比較細節的問題。
從我的實戰經驗來看,遇到這種情況,通常就需要去源碼中尋找答案了,因為在源碼面前,這些細節會變得「一覽無余」。
而且我認為,掌握讀源碼的能力,是從只懂得如何使用 Redis,到精通 Redis 實現原理的成長之路上,必須跨越的門檻。
可是,面對龐大復雜的項目,我們怎樣讀源碼才能更高效呢?
這篇文章我就來和你聊一聊,我讀 Redis 源碼的經驗,以及讀源碼的「通用思路」,希望這些心得可以幫助到你。
01 找到地圖
很多開源項目的源碼,代碼量一般都比較龐大,如果在讀代碼之前,我們沒有制定合理的方法,就一頭扎進去讀代碼,勢必會把自己搞暈。
所以,我在拿到一個項目的代碼之后,并不會馬上著手去讀,而是會先對整個項目結構進行梳理,劃分出項目具體包含的模塊。這樣,我就對整個項目有了一個「宏觀」的了解。
讀代碼就好比去一個陌生城市旅行,這個旅途過程充滿著未知。如果在出發之前,我們手里能有一張地圖,那我們對自己的行程就可以有一個非常清晰的規劃。
我們就知道,如果想要到達目的地,需要從哪里出發、經過哪些地方、通過什么方式才能到達,有了地圖就有了行進方向,否則很容易迷失。
因此,提前花一些時間梳理整個項目的「結構和目錄」,對于后面更好地閱讀代碼是非常有必要的。
就拿 Redis 來舉例,在讀 Redis 源碼之前,我們可以先梳理出整個項目的功能模塊,以及每個模塊對應的代碼文件(src 下的代碼結構):
這樣,有了這張地圖之后,我們再去看代碼的時候,就可以有重點地閱讀了。
02 前置知識準備
在梳理完整個項目結構之后,我們就可以正式進入閱讀環節當中了。不過,在閱讀代碼之前,我們其實還需要預先掌握一些「前置知識」。
因為一個完整的項目,必然綜合了各個領域的技術知識點,比如數據結構、操作系統、網絡協議、編程語言等,如果我們提前做好一些功課,在讀源碼的過程中就會輕松很多。
以下是根據我在閱讀 Redis 書籍和實戰過程中,提取的讀源碼必備前置知識點,你可以參考下:
常用數據結構:數組、鏈表、哈希表、跳表
網絡協議:TCP 協議
網絡 IO 模型:IO 多路復用、非阻塞 IO、Reactor 網絡模型
操作系統:寫時復制(Copy On Write)、常見系統調用、磁盤 IO 機制
C 語言基礎:循環、分支、結構體、指針
當然,在閱讀源碼的過程中,我們也可以根據實際問題再去查閱相關資料,但不管怎樣,提前熟悉這些方面的知識,在真正讀代碼時就會省下不少時間。
03 從基礎模塊開始讀
好,有了地圖并掌握了前置知識之后,接下來我們就要進入主題了:讀代碼。
但具體要從哪個地方開始讀起呢?我認為要先從「最基礎」的模塊開始讀起。
我在前面也分析了,一個完整的項目會劃分很多的功能模塊,但這些模塊并不是孤立的,而很可能是有「依賴」關系的。
比如說,Redis 中的 networking.c 文件,表示處理網絡 IO 的具體實現。而如果我們能在理解事件驅動模塊 ae.c 的基礎上,再去閱讀網絡 IO 模塊,效率就會更高。
那在 Redis 源碼中,哪些是最基礎的模塊呢?
想一下,我們在使用 Redis 時,接觸最頻繁的是哪些功能?
答案是各種數據類型。
一切操作的基礎,其實都是基于這些最常用的數據類型來做的,比如 String、List、Hash、Set、Sorted Set等。所以,我們就可以從這些基礎模塊開始讀起,也就是從 t_string.c、t_list.c、t_hash.c、t_set.c、t_zset.c 代碼入手。
如果你對 Redis 的數據類型有所了解,就會看到這些數據類型在實現時,底層都對應了不同的數據結構。比如,String 的底層是 SDS,List 的底層是 ziplist + quicklist,Hash 底層可能是ziplist,也可能是哈希表,等等。
由此一來,我們會發現,這些數據結構又是更為「底層」的模塊,所以我們在閱讀數據類型模塊時,就需要重點聚焦在這些模塊上,也就是 sds.c、ziplist.c、quicklist.c、dict.c、intset.c 文件,而且這些文件都是比較獨立的,閱讀起來就可以更加集中。
這樣,當我們真正掌握了這些「底層數據結構」的實現后,就能更好地理解基于它們實現的各種「數據類型」了。
這些基礎模塊就相當于一座大廈的地基,地基打好了,才能做到高樓聳立。
04 找到核心主線
接著,掌握了數據結構模塊之后,這時我們的重點就需要放在「核心主線」上來了。
在這個階段,我們需要找到一個明確的目標,以這個目標為主線去讀代碼。因為讀源碼一個很常見的需求,就是為了了解這個項目最「核心功能」的實現細節,我們只有以此為目標,找到這條主線去讀代碼,才能達到最終目的。
那么在讀 Redis 源碼時,什么才是它的核心主線呢?這里我分享一個非常好用的技巧,就是根據「Redis 究竟是怎么處理客戶端發來的命令的?」 為主線來梳理。
舉個例子,當我們在執行 SET testkey testval EX 60 這樣一條命令時,就需要搞清楚 Redis 是怎么執行這條命令的。
也就是要明確,Redis 從收到客戶端請求,到把數據存到 Redis 中、設置過期時間,最后把響應結果返回給客戶端,整個過程的每一個環節,到底是如何處理的。
有了這條主線,我們就有了非常明確的目標,而且沿著這條主線去讀代碼,我們還可以很清晰地把多個模塊「串聯」起來。比如從前面的例子中,我們會看到一條命令的執行,主要包含了這樣幾個階段。
Redis Server 初始化:加載配置、監聽端口、注冊連接建立事件、啟動事件循環(server.c、anet.c)。
接收、解析客戶端請求:初始化 client、注冊讀事件、讀客戶端 socket(networking.c)。
處理具體的命令:找到對應的命令函數、執行命令(server.c、t_string.c、t_list.c、t_hash.c、t_set.c、t_zset.c)。
返回響應給客戶端:寫客戶端緩沖區、注冊寫事件、寫客戶端 socket(networking.c)。
沿著這條主線去讀代碼,我們就可以掌握一條命令的執行全過程。
而且,由于這條主線的代碼邏輯,已經覆蓋了「所有命令」的執行流程,我們下次再去讀其它命令時,比如 SADD,就只需要關注「處理命令」部分的邏輯即可,其它邏輯有 80% 都是相同的。
05 先整體后細節
當然,在閱讀主線代碼的過程中,肯定也會遇到過于「復雜」的函數,第一次在讀這種函數時,很容易就會「陷進去」,導致整個主線代碼的閱讀,無法繼續推進下去。
遇到這種情況其實是很正常的,可這時我們應該怎么辦呢?
這里我的做法是,前期讀到這種邏輯時,不要馬上陷入到細節中去,而是要先「抓整體」。
具體來說,對于復雜的函數邏輯,我們剛開始并不需要知道它的每一個細節是如何實現的,而是只需知道這個函數「大致」做了幾件事情即可。
舉個例子,在執行 HSET 命令時,有一段代碼很復雜,其中包括了很多分支判斷,一次很難讀懂:
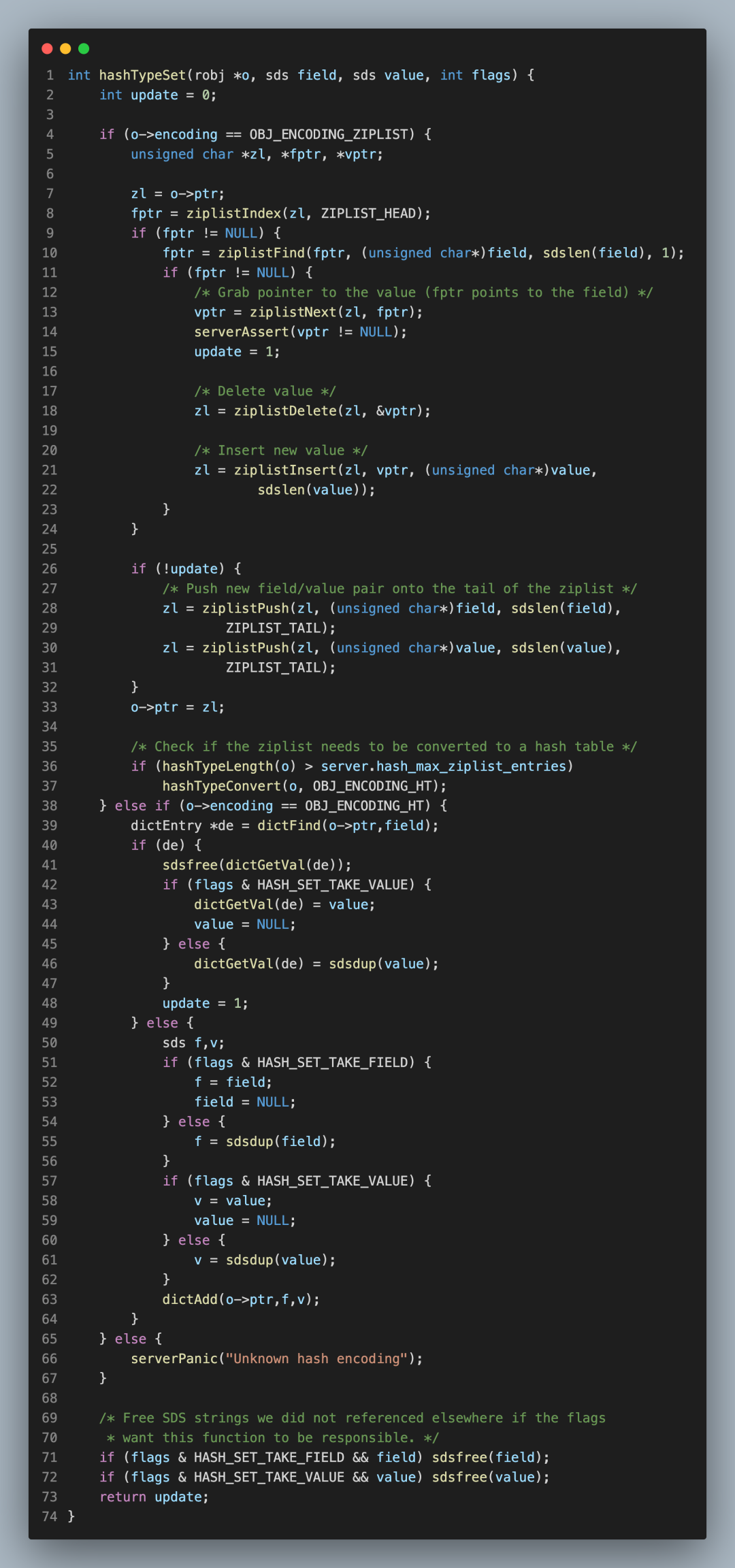
那么,我在讀這段代碼時,就可以先簡化邏輯,把握整體思路:
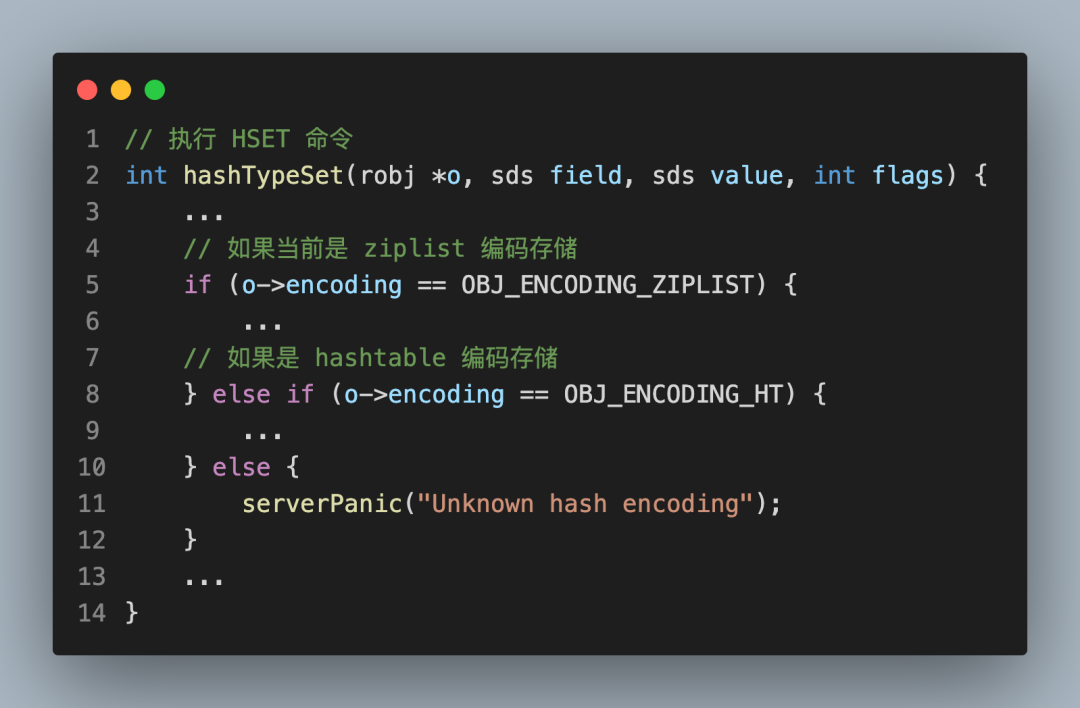
之后,再了解每個分支大致做了哪些事情:
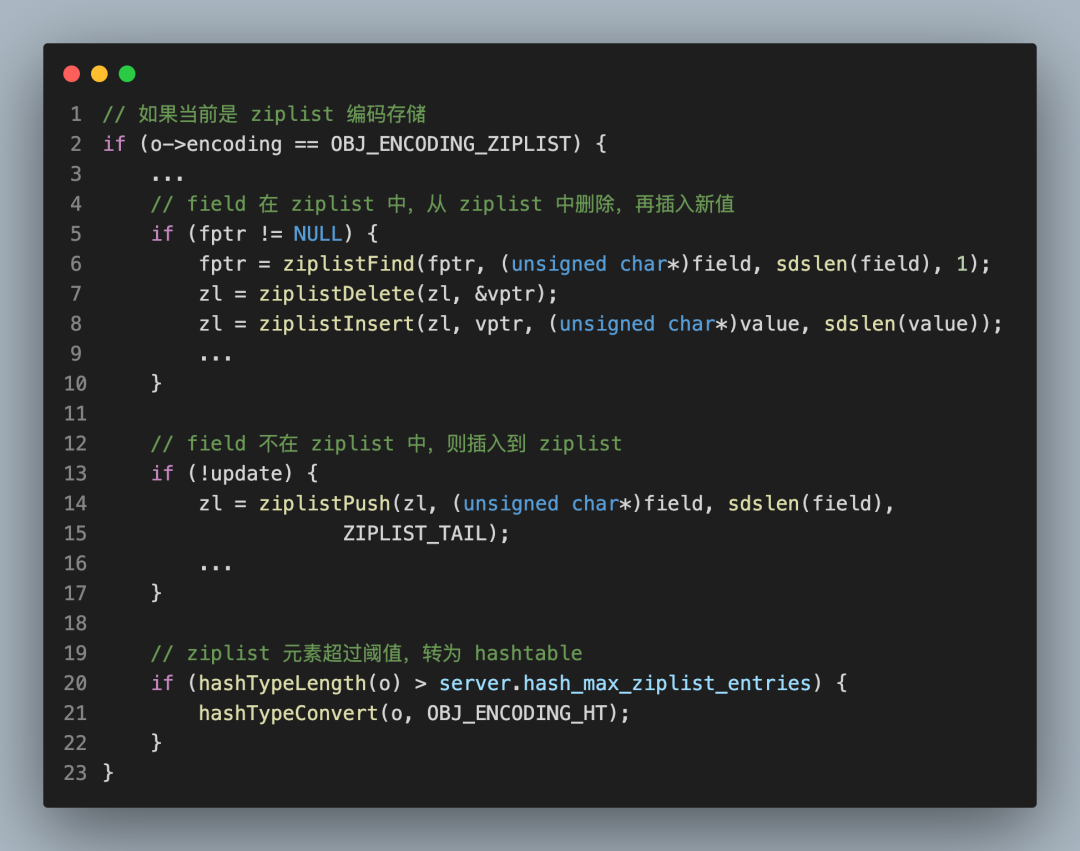
這樣做的好處,一是不會被復雜的細節邏輯搞暈,打擊自己的自信心,二是可以有效避免閱讀的連貫性被打斷,從而能持續推進我們把整個主線邏輯讀完。
所以,這里的重點就是:先把復雜代碼的主邏輯搞清楚,知道涉及的每個方法完成了什么事,心里要先搭建一個簡單的「框架」,等有了框架之后,我們再去給框架填充「細節」。
這樣通過「先整體后細節」的方式,我們就可以不再畏懼代碼中的復雜邏輯。
06 先主線后支線
不過,在閱讀主線代碼的過程中,我們肯定還會遇到各種「支線」邏輯,比如數據過期、替換淘汰、持久化、主從復制等。
其實,在閱讀主線邏輯的時候,我們并不需要去重點關注這些支線,而當整個主線邏輯「清晰」起來之后,我們再去讀這些支線模塊,就會容易很多了。
這時,我們就可以從這些支線中,選取下一個「目標」,帶著這個目標去閱讀,比如說:
過期策略是怎么實現的?(expire.c、lazyfree.c)
淘汰策略是如何實現的?(evict.c)
持久化 RDB、AOF 是怎么做的?(rdb.c、aof.c)
主從復制是怎么做的?(replication.c)
哨兵如何完成故障自動切換?(sentinel.c)
分片邏輯如何實現?(cluster.c)
。..
有了新的支線目標后,我們依舊可以采用前面提到的「先整體后細節」的思路閱讀相關模塊,這樣下來,整個項目的每個模塊,就可以被「逐一擊破」了。
07 查漏補缺
最后,我們還需要「查漏補缺」。
按照前面提到的方法,基本就可以把整個項目的主要模塊讀得七七八八了,這時我們基本已經對整個項目有了整體的「把控」。
不過,當我們在工作中遇到問題時,很有可能會發現,在當時讀代碼的過程中,有很多并不在意的「細節」被忽略了。
所以這時,我們就可以再帶著「具體問題」出發,聚焦這個問題相關的模塊,再一次去讀源碼。這樣一來,我們就可以填補當時閱讀源碼的「空白區」。
舉個例子,當我們在閱讀 String 底層數據結構 SDS(簡單動態字符串)的實現時,我們會看到當 SDS 需要追加新內容時會進行擴容,而我們之前閱讀這塊代碼時,很有可能只是了解到有這樣的邏輯存在,但并沒有在意擴容的相關細節(一次擴容多大)。
所以,當我們在工作中遇到這個細節問題后,就可以把目光聚焦在 SDS 的擴容邏輯上(sds.c 的sdsMakeRoomFor函數),而此時我們會發現,當需要申請的新內存小于 1MB 時,Redis 就會翻倍申請內存,否則按 1MB 申請新內存。
采用這個方法進行查漏補缺,我們就可以對整個項目了解得更深入、更全面,真正把項目「吃透」。
總結
好了,以上就是我在閱讀 Redis 源碼時的經驗心得,總結一下這 7 個步驟。
1、找到地圖:拿到項目代碼后,提前梳理整個項目結構,知曉整個項目的模塊劃分,以及對應的代碼文件。
2、前置知識準備:提前掌握項目中用到的前置知識,比如數據結構、操作系統原理、網絡協議、網絡 IO 模型、編程語言語法等等。
3、從基礎模塊開始讀:從最底層的基礎模塊開始入手,先掌握了這些模塊,之后基于它們構建的模塊讀起來會更加高效。
4、找到核心主線:找到整個項目中最核心的主線邏輯,以此為目標,了解各模塊為了完成這個功能,是如何協作和組織的。
5、先整體后細節:對于復雜函數,不要上來就陷入細節,前期閱讀只需了解這個函數大致做了什么事情,建立框架,等搭建起框架之后,再去填充細節。
6、先主線后支線:整個主線邏輯清晰之后,再去延伸閱讀支線邏輯,因為支線邏輯肯定是服務主線邏輯的,讀完主線后再去讀這些支線,也會變得更簡單。
7、查漏補缺:在工作中遇到具體問題,帶著這些實際的問題出發再次去讀源碼,進行查漏補缺,填補之前讀源碼時沒有注意到的地方。
后記
你可以看到,這篇文章介紹的閱讀源碼的方法,其實并不局限于讀 Redis 代碼。
這 7 個步驟,可以算是一個的「通用思路」,我也經常用這個思路來讀其它項目的源碼,非常有用,你也可以試試。
另外,我認為很多人讀源碼覺得難,一是因為心理上自認為自己讀不懂,不敢邁步這一步,二是因為找不到合理的方法,在讀源碼時屢次受挫,最終知難而退。
我在讀源碼時也經歷過這些,這里再分享一下我的經驗。
1、永遠不要給自己設限:想想看,曾經以為很多自己做不到的事,在有壓力的情況下,是不是慢慢都做到了,而且發現做得還挺好?學習技術也是一樣,技術是死的,東西就那么多,一遍不行來兩遍,總有一次能搞懂,所以心態上一定不要先「否定」自己,凡事先邁一小步進去試試看,好的開始就是成功的一半。
2、找到對的學習方法:正所謂「學會學習,再學習」,科學高效的方法,能幫你事半功倍,這篇文章分享的方法論,就是屬于學習方法的范疇,你可以結合自己的實際情況試試看。
希望我的這些經驗和心得,對你有所啟發。
如果你也有自己的閱讀源碼的實踐經驗和方法,歡迎在留言區分享出來,我們一起交流,共同進步~
責任編輯:haq
-
源碼
+關注
關注
8文章
639瀏覽量
29185 -
Redis
+關注
關注
0文章
374瀏覽量
10871
原文標題:讀懂 Redis 源碼,我總結了這 7 點心得
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
在TLV320AIC3254中怎樣去讀頻率值和幅度值?
二維碼識讀設備有哪些類型

通過簡單的電阻電容組合怎樣才能把25K方波變成正弦?
智能升級,樓宇自控系統讓辦公更高效

我們需要怎樣的大模型?

如何使用PyTorch構建更高效的人工智能
固定讀碼器怎么選型 工業二維碼讀碼器推薦

怎樣才能選到合適的無線模塊?

比車用級別更高,eVTOL到底需要怎樣的電機?

搭載星火認知大模型的AI鼠標:一鍵呼出AI助手,辦公更高效

工業固定式讀碼器快速高效掃碼,實現防重復防漏條碼指令觸發功能






 工商網監
工商網監
評論