 分布式系統架構設計中異地多活是什么
分布式系統架構設計中異地多活是什么
在軟件開發領域,「異地多活」是分布式系統架構設計的一座高峰,很多人經常聽過它,但很少人理解其中的原理。
異地多活到底是什么?為什么需要異地多活?它到底解決了什么問題?究竟是怎么解決的?
這些疑問,想必是每個程序看到異地多活這個名詞時,都想要搞明白的問題。
有幸,我曾經深度參與過一個中等互聯網公司,建設異地多活系統的設計與實施過程。所以今天,我就來和你聊一聊異地多活背后的的實現原理。
認真讀完這篇文章,我相信你會對異地多活架構,有更加深刻的理解。
這篇文章干貨很多,希望你可以耐心讀完。
01 系統可用性
要想理解異地多活,我們需要從架構設計的原則說起。
現如今,我們開發一個軟件系統,對其要求越來越高,如果你了解一些「架構設計」的要求,就知道一個好的軟件架構應該遵循以下 3 個原則:
高性能
高可用
易擴展
其中,高性能意味著系統擁有更大流量的處理能力,更低的響應延遲。例如 1 秒可處理 10W 并發請求,接口響應時間 5 ms 等等。
易擴展表示系統在迭代新功能時,能以最小的代價去擴展,系統遇到流量壓力時,可以在不改動代碼的前提下,去擴容系統。
而「高可用」這個概念,看起來很抽象,怎么理解它呢?通常用 2 個指標來衡量:
平均故障間隔 MTBF(Mean Time Between Failure):表示兩次故障的間隔時間,也就是系統「正常運行」的平均時間,這個時間越長,說明系統穩定性越高
故障恢復時間 MTTR(Mean Time To Repair):表示系統發生故障后「恢復的時間」,這個值越小,故障對用戶的影響越小
可用性與這兩者的關系:
可用性(Availability)= MTBF / (MTBF + MTTR) * 100%
這個公式得出的結果是一個「比例」,通常我們會用「N 個 9」來描述一個系統的可用性。
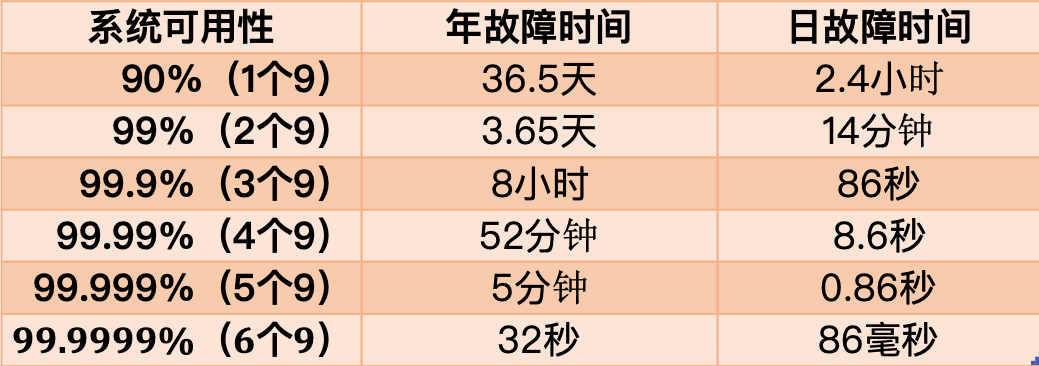
從這張圖你可以看到,要想達到 4 個 9 以上的可用性,平均每天故障時間必須控制在 10 秒以內。
也就是說,只有故障的時間「越短」,整個系統的可用性才會越高,每提升 1 個 9,都會對系統提出更高的要求。
我們都知道,系統發生故障其實是不可避免的,尤其是規模越大的系統,發生問題的概率也越大。這些故障一般體現在 3 個方面:
軟件問題:代碼 Bug、版本迭代
不可抗力:地震、水災、火災、戰爭
這些風險隨時都有可能發生。所以,在面對故障時,我們的系統能否以「最快」的速度恢復,就成為了可用性的關鍵。
可如何做到快速恢復呢?
這篇文章要講的「異地多活」架構,就是為了解決這個問題,而提出的高效解決方案。
下面,我會從一個最簡單的系統出發,帶你一步步演化出一個支持「異地多活」的系統架構。
在這個過程中,你會看到一個系統會遇到哪些可用性問題,以及為什么架構要這樣演進,從而理解異地多活架構的意義。
02 單機架構
我們從最簡單的開始講起。
假設你的業務處于起步階段,體量非常小,那你的架構是這樣的:
這個架構模型非常簡單,客戶端請求進來,業務應用讀寫數據庫,返回結果,非常好理解。
但需要注意的是,這里的數據庫是「單機」部署的,所以它有一個致命的缺點:一旦遭遇意外,例如磁盤損壞、操作系統異常、誤刪數據,那這意味著所有數據就全部「丟失」了,這個損失是巨大的。
如何避免這個問題呢?我們很容易想到一個方案:備份。
你可以對數據做備份,把數據庫文件「定期」cp 到另一臺機器上,這樣,即使原機器丟失數據,你依舊可以通過備份把數據「恢復」回來,以此保證數據安全。
這個方案實施起來雖然比較簡單,但存在 2 個問題:
恢復需要時間:業務需先停機,再恢復數據,停機時間取決于恢復的速度,恢復期間服務「不可用」
數據不完整:因為是定期備份,數據肯定不是「最新」的,數據完整程度取決于備份的周期
很明顯,你的數據庫越大,意味故障恢復時間越久。那按照前面我們提到的「高可用」標準,這個方案可能連 1 個 9 都達不到,遠遠無法滿足我們對可用性的要求。
那有什么更好的方案,既可以快速恢復業務?還能盡可能保證數據完整性呢?
這時你可以采用這個方案:主從副本。
03 主從副本
你可以在另一臺機器上,再部署一個數據庫實例,讓這個新實例成為原實例的「副本」,讓兩者保持「實時同步」,就像這樣:
我們一般把原實例叫作主庫(master),新實例叫作從庫(slave)。這個方案的優點在于:
數據完整性高:主從副本實時同步,數據「差異」很小
抗故障能力提升:主庫有任何異常,從庫可隨時「切換」為主庫,繼續提供服務
讀性能提升:業務應用可直接讀從庫,分擔主庫「壓力」讀壓力
這個方案不錯,不僅大大提高了數據庫的可用性,還提升了系統的讀性能。
同樣的思路,你的「業務應用」也可以在其它機器部署一份,避免單點。因為業務應用通常是「無狀態」的(不像數據庫那樣存儲數據),所以直接部署即可,非常簡單。
因為業務應用部署了多個,所以你現在還需要部署一個「接入層」,來做請求的「負載均衡」(一般會使用 nginx 或 LVS),這樣當一臺機器宕機后,另一臺機器也可以「接管」所有流量,持續提供服務。
從這個方案你可以看出,提升可用性的關鍵思路就是:冗余。
沒錯,擔心一個實例故障,那就部署多個實例,擔心一個機器宕機,那就部署多臺機器。
到這里,你的架構基本已演變成主流方案了,之后開發新的業務應用,都可以按照這種模式去部署。
但這種方案還有什么風險嗎?
04 風險不可控
現在讓我們把視角下放,把焦點放到具體的「部署細節」上來。
按照前面的分析,為了避免單點故障,你的應用雖然部署了多臺機器,但這些機器的分布情況,我們并沒有去深究。
而一個機房有很多服務器,這些服務器通常會分布在一個個「機柜」上,如果你使用的這些機器,剛好在一個機柜,還是存在風險。
如果恰好連接這個機柜的交換機 / 路由器發生故障,那么你的應用依舊有「不可用」的風險。
雖然交換機 / 路由器也做了路線冗余,但不能保證一定不出問題。
部署在一個機柜有風險,那把這些機器打散,分散到不同機柜上,是不是就沒問題了?
這樣確實會大大降低出問題的概率。但我們依舊不能掉以輕心,因為無論怎么分散,它們總歸還是在一個相同的環境下:機房。
那繼續追問,機房會不會發生故障呢?
一般來講,建設一個機房的要求其實是很高的,地理位置、溫濕度控制、備用電源等等,機房廠商會在各方面做好防護。但即使這樣,我們每隔一段時間還會看到這樣的新聞:
2015 年 5 月 27 日,杭州市某地光纖被挖斷,近 3 億用戶長達 5 小時無法訪問支付寶
2021 年 7 月 13 日,B 站部分服務器機房發生故障,造成整站持續 3 個小時無法訪問
2021 年 10 月 9 日,富途證券服務器機房發生電力閃斷故障,造成用戶 2 個小時無法登陸、交易
...
可見,即使機房級別的防護已經做得足夠好,但只要有「概率」出問題,那現實情況就有可能發生。雖然概率很小,但一旦真的發生,影響之大可見一斑。
看到這里你可能會想,機房出現問題的概率也太小了吧,工作了這么多年,也沒讓我碰上一次,有必要考慮得這么復雜嗎?
但你有沒有思考這樣一個問題:不同體量的系統,它們各自關注的重點是什么?
體量很小的系統,它會重點關注「用戶」規模、增長,這個階段獲取用戶是一切。等用戶體量上來了,這個階段會重點關注「性能」,優化接口響應時間、頁面打開速度等等,這個階段更多是關注用戶體驗。
等體量再大到一定規模后你會發現,「可用性」就變得尤為重要。像微信、支付寶這種全民級的應用,如果機房發生一次故障,那整個影響范圍可以說是非常巨大的。
所以,再小概率的風險,我們在提高系統可用性時,也不能忽視。
分析了風險,再說回我們的架構。那到底該怎么應對機房級別的故障呢?
沒錯,還是冗余。
05 同城災備
想要抵御「機房」級別的風險,那應對方案就不能局限在一個機房內了。
現在,你需要做機房級別的冗余方案,也就是說,你需要再搭建一個機房,來部署你的服務。
簡單起見,你可以在「同一個城市」再搭建一個機房,原機房我們叫作 A 機房,新機房叫 B 機房,這兩個機房的網絡用一條「專線」連通。
有了新機房,怎么把它用起來呢?這里還是要優先考慮「數據」風險。
為了避免 A 機房故障導致數據丟失,所以我們需要把數據在 B 機房也存一份。最簡單的方案還是和前面提到的一樣:備份。
A 機房的數據,定時在 B 機房做備份(拷貝數據文件),這樣即使整個 A 機房遭到嚴重的損壞,B 機房的數據不會丟,通過備份可以把數據「恢復」回來,重啟服務。
這種方案,我們稱之為「冷備」。為什么叫冷備呢?因為 B 機房只做備份,不提供實時服務,它是冷的,只會在 A 機房故障時才會啟用。
但備份的問題依舊和之前描述的一樣:數據不完整、恢復數據期間業務不可用,整個系統的可用性還是無法得到保證。
所以,我們還是需要用「主從副本」的方式,在 B 機房部署 A 機房的數據副本,架構就變成了這樣:
這樣,就算整個 A 機房掛掉,我們在 B 機房也有比較「完整」的數據。
數據是保住了,但這時你需要考慮另外一個問題:如果 A 機房真掛掉了,要想保證服務不中斷,你還需要在 B 機房「緊急」做這些事情:
B 機房所有從庫提升為主庫
在 B 機房部署應用,啟動服務
部署接入層,配置轉發規則
DNS 指向 B 機房,接入流量,業務恢復
看到了么?A 機房故障后,B 機房需要做這么多工作,你的業務才能完全「恢復」過來。
你看,整個過程需要人為介入,且需花費大量時間來操作,恢復之前整個服務還是不可用的,這個方案還是不太爽,如果能做到故障后立即「切換」,那就好了。
因此,要想縮短業務恢復的時間,你必須把這些工作在 B 機房「提前」做好,也就是說,你需要在 B 機房提前部署好接入層、業務應用,等待隨時切換。架構就變成了這樣:
這樣的話,A 機房整個掛掉,我們只需要做 2 件事即可:
B 機房所有從庫提升為主庫
DNS 指向 B 機房,接入流量,業務恢復
這樣一來,恢復速度快了很多。
到這里你會發現,B 機房從最開始的「空空如也」,演變到現在,幾乎是「鏡像」了一份 A 機房的所有東西,從最上層的接入層,到中間的業務應用,到最下層的存儲。
兩個機房唯一的區別是,A 機房的存儲都是主庫,而 B 機房都是從庫。
這種方案,我們把它叫做「熱備」。
熱的意思是指,B 機房處于「待命」狀態,A 故障后 B 可以隨時「接管」流量,繼續提供服務。熱備相比于冷備最大的優點是:隨時可切換。
無論是冷備還是熱備,因為它們都處于「備用」狀態,所以我們把這兩個方案統稱為:同城災備。
同城災備的最大優勢在于,我們再也不用擔心「機房」級別的故障了,一個機房發生風險,我們只需把流量切換到另一個機房即可,可用性再次提高,是不是很爽?(后面還有更爽的)
06 同城雙活
我們繼續來看這個架構。
雖然我們有了應對機房故障的解決方案,但這里有個問題是我們不能忽視的:A 機房掛掉,全部流量切到 B 機房,B 機房能否真的如我們所愿,正常提供服務?
這是個值得思考的問題。
這就好比有兩支軍隊 A 和 B,A 軍隊歷經沙場,作戰經驗豐富,而 B 軍隊只是后備軍,除了有軍人的基本素養之外,并沒有實戰經驗,戰斗經驗基本為 0。
如果 A 軍隊喪失戰斗能力,需要 B 軍隊立即頂上時,作為指揮官的你,肯定也會擔心 B 軍隊能否真的擔此重任吧?
我們的架構也是如此,此時的 B 機房雖然是隨時「待命」狀態,但 A 機房真的發生故障,我們要把全部流量切到 B 機房,其實是不敢百分百保證它可以「如期」工作的。
你想,我們在一個機房內部署服務,還總是發生各種各樣的問題,例如:發布應用的版本不一致、系統資源不足、操作系統參數不一樣等等。現在多部署一個機房,這些問題只會增多,不會減少。
另外,從「成本」的角度來看,我們新部署一個機房,需要購買服務器、內存、硬盤、帶寬資源,花費成本也是非常高昂的,只讓它當一個后備軍,未免也太「大材小用」了!
因此,我們需要讓 B 機房也接入流量,實時提供服務,這樣做的好處,一是可以實時訓練這支后備軍,讓它達到與 A 機房相同的作戰水平,隨時可切換,二是 B 機房接入流量后,可以分擔 A 機房的流量壓力。這才是把 B 機房資源優勢,發揮最大化的最好方案!
那怎么讓 B 機房也接入流量呢?很簡單,就是把 B 機房的接入層 IP 地址,加入到 DNS 中,這樣,B 機房從上層就可以有流量進來了。
但這里有一個問題:別忘了,B 機房的存儲,現在可都是 A 機房的「從庫」,從庫默認可都是「不可寫」的,B 機房的寫請求打到本機房存儲上,肯定會報錯,這還是不符合我們預期。怎么辦?
這時,你就需要在「業務應用」層做改造了。
你的業務應用在操作數據庫時,需要區分「讀寫分離」(一般用中間件實現),即兩個機房的「讀」流量,可以讀任意機房的存儲,但「寫」流量,只允許寫 A 機房,因為主庫在 A 機房。
這會涉及到你用的所有存儲,例如項目中用到了 MySQL、Redis、MongoDB 等等,操作這些數據庫,都需要區分讀寫請求,所以這塊需要一定的業務「改造」成本。
因為 A 機房的存儲都是主庫,所以我們把 A 機房叫做「主機房」,B 機房叫「從機房」。
兩個機房部署在「同城」,物理距離比較近,而且兩個機房用「專線」網絡連接,雖然跨機房訪問的延遲,比單個機房內要大一些,但整體的延遲還是可以接受的。
業務改造完成后,B 機房可以慢慢接入流量,從 10%、30%、50% 逐漸覆蓋到 100%,你可以持續觀察 B 機房的業務是否存在問題,有問題及時修復,逐漸讓 B 機房的工作能力,達到和 A 機房相同水平。
現在,因為 B 機房實時接入了流量,此時如果 A 機房掛了,那我們就可以「大膽」地把 A 的流量,全部切換到 B 機房,完成快速切換!
到這里你可以看到,我們部署的 B 機房,在物理上雖然與 A 有一定距離,但整個系統從「邏輯」上來看,我們是把這兩個機房看做一個「整體」來規劃的,也就是說,相當于把 2 個機房當作 1 個機房來用。
這種架構方案,比前面的同城災備更「進了一步」,B 機房實時接入了流量,還能應對隨時的故障切換,這種方案我們把它叫做「同城雙活」。
因為兩個機房都能處理業務請求,這對我們系統的內部維護、改造、升級提供了更多的可實施空間(流量隨時切換),現在,整個系統的彈性也變大了,是不是更爽了?
那這種架構有什么問題呢?
07 兩地三中心
還是回到風險上來說。
雖然我們把 2 個機房當做一個整體來規劃,但這 2 個機房在物理層面上,還是處于「一個城市」內,如果是整個城市發生自然災害,例如地震、水災(河南水災剛過去不久),那 2 個機房依舊存在「全局覆沒」的風險。
真是防不勝防啊?怎么辦?沒辦法,繼續冗余。
但這次冗余機房,就不能部署在同一個城市了,你需要把它放到距離更遠的地方,部署在「異地」。
通常建議兩個機房的距離要在 1000 公里以上,這樣才能應對城市級別的災難。
假設之前的 A、B 機房在北京,那這次新部署的 C 機房可以放在上海。
按照前面的思路,把 C 機房用起來,最簡單粗暴的方案還就是做「冷備」,即定時把 A、B 機房的數據,在 C 機房做備份,防止數據丟失。
這種方案,就是我們經常聽到的「兩地三中心」。
兩地是指 2 個城市,三中心是指有 3 個機房,其中 2 個機房在同一個城市,并且同時提供服務,第 3 個機房部署在異地,只做數據災備。
這種架構方案,通常用在銀行、金融、政企相關的項目中。它的問題還是前面所說的,啟用災備機房需要時間,而且啟用后的服務,不確定能否如期工作。
所以,要想真正的抵御城市級別的故障,越來越多的互聯網公司,開始實施「異地雙活」。
08 偽異地雙活
這里,我們還是分析 2 個機房的架構情況。我們不再把 A、B 機房部署在同一個城市,而是分開部署,例如 A 機房放在北京,B 機房放在上海。
前面我們講了同城雙活,那異地雙活是不是直接「照搬」同城雙活的模式去部署就可以了呢?
事情沒你想的那么簡單。
如果還是按照同城雙活的架構來部署,那異地雙活的架構就是這樣的:
注意看,兩個機房的網絡是通過「跨城專線」連通的。
此時兩個機房都接入流量,那上海機房的請求,可能要去讀寫北京機房的存儲,這里存在一個很大的問題:網絡延遲。
因為兩個機房距離較遠,受到物理距離的限制,現在,兩地之間的網絡延遲就變成了「不可忽視」的因素了。
北京到上海的距離大約 1300 公里,即使架設一條高速的「網絡專線」,光纖以光速傳輸,一個來回也需要近 10ms 的延遲。
況且,網絡線路之間還會經歷各種路由器、交換機等網絡設備,實際延遲可能會達到 30ms ~ 100ms,如果網絡發生抖動,延遲甚至會達到 1 秒。
不止是延遲,遠距離的網絡專線質量,是遠遠達不到機房內網絡質量的,專線網絡經常會發生延遲、丟包、甚至中斷的情況。總之,不能過度信任和依賴「跨城專線」。
你可能會問,這點延遲對業務影響很大嗎?影響非常大!
試想,一個客戶端請求打到上海機房,上海機房要去讀寫北京機房的存儲,一次跨機房訪問延遲就達到了 30ms,這大致是機房內網網絡(0.5 ms)訪問速度的 60 倍(30ms / 0.5ms),一次請求慢 60 倍,來回往返就要慢 100 倍以上。
而我們在 App 打開一個頁面,可能會訪問后端幾十個 API,每次都跨機房訪問,整個頁面的響應延遲有可能就達到了秒級,這個性能簡直慘不忍睹,難以接受。
看到了么,雖然我們只是簡單的把機房部署在了「異地」,但「同城雙活」的架構模型,在這里就不適用了,還是按照這種方式部署,這是「偽異地雙活」!
那如何做到真正的異地雙活呢?
09 真正的異地雙活
既然「跨機房」調用延遲是不容忽視的因素,那我們只能盡量避免跨機房「調用」,規避這個延遲問題。
也就是說,上海機房的應用,不能再「跨機房」去讀寫北京機房的存儲,只允許讀寫上海本地的存儲,實現「就近訪問」,這樣才能避免延遲問題。
還是之前提到的問題:上海機房存儲都是從庫,不允許寫入啊,除非我們只允許上海機房接入「讀流量」,不接收「寫流量」,否則無法滿足不再跨機房的要求。
很顯然,只讓上海機房接收讀流量的方案不現實,因為很少有項目是只有讀流量,沒有寫流量的。所以這種方案還是不行,這怎么辦?
此時,你就必須在「存儲層」做改造了。
要想上海機房讀寫本機房的存儲,那上海機房的存儲不能再是北京機房的從庫,而是也要變為「主庫」。
你沒看錯,兩個機房的存儲必須都是「主庫」,而且兩個機房的數據還要「互相同步」數據,即客戶端無論寫哪一個機房,都能把這條數據同步到另一個機房。
因為只有兩個機房都擁有「全量數據」,才能支持任意切換機房,持續提供服務。
怎么實現這種「雙主」架構呢?它們之間如何互相同步數據?
如果你對 MySQL 有所了解,MySQL 本身就提供了雙主架構,它支持雙向復制數據,但平時用的并不多。而且 Redis、MongoDB 等數據庫并沒有提供這個功能,所以,你必須開發對應的「數據同步中間件」來實現雙向同步的功能。
此外,除了數據庫這種有狀態的軟件之外,你的項目通常還會使用到消息隊列,例如 RabbitMQ、Kafka,這些也是有狀態的服務,所以它們也需要開發雙向同步的中間件,支持任意機房寫入數據,同步至另一個機房。
看到了么,這一下子復雜度就上來了,單單針對每個數據庫、隊列開發同步中間件,就需要投入很大精力了。
業界也開源出了很多數據同步中間件,例如阿里的 Canal、RedisShake、MongoShake,可分別在兩個機房同步 MySQL、Redis、MongoDB 數據。
很多有能力的公司,也會采用自研同步中間件的方式來做,例如餓了么、攜程、美團都開發了自己的同步中間件。
我也有幸參與設計開發了 MySQL、Redis/Codis、MongoDB 的同步中間件,有時間寫一篇文章詳細聊聊實現細節,歡迎持續關注。:)
現在,整個架構就變成了這樣:
注意看,兩個機房的存儲層都互相同步數據的。有了數據同步中間件,就可以達到這樣的效果:
北京機房寫入 X = 1
上海機房寫入 Y = 2
數據通過中間件雙向同步
北京、上海機房都有 X = 1、Y = 2 的數據
這里我們用中間件雙向同步數據,就不用再擔心專線問題,專線出問題,我們的中間件可以自動重試,直到成功,達到數據最終一致。
但這里還會遇到一個問題,兩個機房都可以寫,操作的不是同一條數據那還好,如果修改的是同一條的數據,發生沖突怎么辦?
用戶短時間內發了 2 個修改請求,都是修改同一條數據
一個請求落在北京機房,修改 X = 1(還未同步到上海機房)
另一個請求落在上海機房,修改 X = 2(還未同步到北京機房)
兩個機房以哪個為準?
也就是說,在很短的時間內,同一個用戶修改同一條數據,兩個機房無法確認誰先誰后,數據發生「沖突」。
這是一個很嚴重的問題,系統發生故障并不可怕,可怕的是數據發生「錯誤」,因為修正數據的成本太高了。我們一定要避免這種情況的發生。解決這個問題,有 2 個方案。
第一個方案,數據同步中間件要有自動「合并」數據、解決「沖突」的能力。
這個方案實現起來比較復雜,要想合并數據,就必須要區分出「先后」順序。我們很容易想到的方案,就是以「時間」為標尺,以「后到達」的請求為準。
但這種方案需要兩個機房的「時鐘」嚴格保持一致才行,否則很容易出現問題。例如:
第 1 個請求落到北京機房,北京機房時鐘是 10:01,修改 X = 1
第 2 個請求落到上海機房,上海機房時鐘是 10:00,修改 X = 2
因為北京機房的時間「更晚」,那最終結果就會是 X = 1。但這里其實應該以第 2 個請求為準,X = 2 才對。
可見,完全「依賴」時鐘的沖突解決方案,不太嚴謹。
所以,通常會采用第二種方案,從「源頭」就避免數據沖突的發生。
10 如何實施異地雙活
既然自動合并數據的方案實現成本高,那我們就要想,能否從源頭就「避免」數據沖突呢?
這個思路非常棒!
從源頭避免數據沖突的思路是:在最上層接入流量時,就不要讓沖突的情況發生。
具體來講就是,要在最上層就把用戶「區分」開,部分用戶請求固定打到北京機房,其它用戶請求固定打到上海 機房,進入某個機房的用戶請求,之后的所有業務操作,都在這一個機房內完成,從根源上避免「跨機房」。
所以這時,你需要在接入層之上,再部署一個「路由層」(通常部署在云服務器上),自己可以配置路由規則,把用戶「分流」到不同的機房內。
但這個路由規則,具體怎么定呢?有很多種實現方式,最常見的我總結了 3 類:
按業務類型分片
直接哈希分片
按地理位置分片
1、按業務類型分片
這種方案是指,按應用的「業務類型」來劃分。
舉例:假設我們一共有 4 個應用,北京和上海機房都部署這些應用。但應用 1、2 只在北京機房接入流量,在上海機房只是熱備。應用 3、4 只在上海機房接入流量,在北京機房是熱備。
這樣一來,應用 1、2 的所有業務請求,只讀寫北京機房存儲,應用 3、4 的所有請求,只會讀寫上海機房存儲。
這樣按業務類型分片,也可以避免同一個用戶修改同一條數據。
這里按業務類型在不同機房接入流量,還需要考慮多個應用之間的依賴關系,要盡可能的把完成「相關」業務的應用部署在同一個機房,避免跨機房調用。
例如,訂單、支付服務有依賴關系,會產生互相調用,那這 2 個服務在 A 機房接入流量。社區、發帖服務有依賴關系,那這 2 個服務在 B 機房接入流量。
2、直接哈希分片
這種方案就是,最上層的路由層,會根據用戶 ID 計算「哈希」取模,然后從路由表中找到對應的機房,之后把請求轉發到指定機房內。
舉例:一共 200 個用戶,根據用戶 ID 計算哈希值,然后根據路由規則,把用戶 1 - 100 路由到北京機房,101 - 200 用戶路由到上海機房,這樣,就避免了同一個用戶修改同一條數據的情況發生。
3、按地理位置分片
這種方案,非常適合與地理位置密切相關的業務,例如打車、外賣服務就非常適合這種方案。
拿外賣服務舉例,你要點外賣肯定是「就近」點餐,整個業務范圍相關的有商家、用戶、騎手,它們都是在相同的地理位置內的。
針對這種特征,就可以在最上層,按用戶的「地理位置」來做分片,分散到不同的機房。
舉例:北京、河北地區的用戶點餐,請求只會打到北京機房,而上海、浙江地區的用戶,請求則只會打到上海機房。這樣的分片規則,也能避免數據沖突。
提醒:這 3 種常見的分片規則,第一次看不太好理解,建議配合圖多理解幾遍。搞懂這 3 個分片規則,你才能真正明白怎么做異地多活。
總之,分片的核心思路在于,讓同一個用戶的相關請求,只在一個機房內完成所有業務「閉環」,不再出現「跨機房」訪問。
阿里在實施這種方案時,給它起了個名字,叫做「單元化」。
當然,最上層的路由層把用戶分片后,理論來說同一個用戶只會落在同一個機房內,但不排除程序 Bug 導致用戶會在兩個機房「漂移」。
安全起見,每個機房在寫存儲時,還需要有一套機制,能夠檢測「數據歸屬」,應用層操作存儲時,需要通過中間件來做「兜底」,避免不該寫本機房的情況發生。(篇幅限制,這里不展開講,理解思路即可)
現在,兩個機房就可以都接收「讀寫」流量(做好分片的請求),底層存儲保持「雙向」同步,兩個機房都擁有全量數據,當任意機房故障時,另一個機房就可以「接管」全部流量,實現快速切換,簡直不要太爽。
不僅如此,因為機房部署在異地,我們還可以更細化地「優化」路由規則,讓用戶訪問就近的機房,這樣整個系統的性能也會大大提升。
這里還有一種情況,是無法做數據分片的:全局數據。例如系統配置、商品庫存這類需要強一致的數據,這類服務依舊只能采用寫主機房,讀從機房的方案,不做雙活。
雙活的重點,是要優先保證「核心」業務先實現雙活,并不是「全部」業務實現雙活。
至此,我們才算實現了真正的「異地雙活」!
到這里你可以看出,完成這樣一套架構,需要投入的成本是巨大的。
路由規則、路由轉發、數據同步中間件、數據校驗兜底策略,不僅需要開發強大的中間件,同時還要業務配合改造(業務邊界劃分、依賴拆分)等一些列工作,沒有足夠的人力物力,這套架構很難實施。
11 異地多活
理解了異地雙活,那「異地多活」顧名思義,就是在異地雙活的基礎上,部署多個機房即可。架構變成了這樣:
這些服務按照「單元化」的部署方式,可以讓每個機房部署在任意地區,隨時擴展新機房,你只需要在最上層定義好分片規則就好了。
但這里還有一個小問題,隨著擴展的機房越來越多,當一個機房寫入數據后,需要同步的機房也越來越多,這個實現復雜度會比較高。
所以業界又把這一架構又做了進一步優化,把「網狀」架構升級為「星狀」:
這種方案必須設立一個「中心機房」,任意機房寫入數據后,都只同步到中心機房,再由中心機房同步至其它機房。
這樣做的好處是,一個機房寫入數據,只需要同步數據到中心機房即可,不需要再關心一共部署了多少個機房,實現復雜度大大「簡化」。
但與此同時,這個中心機房的「穩定性」要求會比較高。不過也還好,即使中心機房發生故障,我們也可以把任意一個機房,提升為中心機房,繼續按照之前的架構提供服務。
至此,我們的系統徹底實現了「異地多活」!
多活的優勢在于,可以任意擴展機房「就近」部署。任意機房發生故障,可以完成快速「切換」,大大提高了系統的可用性。
同時,我們也再也不用擔心系統規模的增長,因為這套架構具有極強的「擴展能力」。
怎么樣?我們從一個最簡單的應用,一路優化下來,到最終的架構方案,有沒有幫你徹底理解異地多活呢?
總結
好了,總結一下這篇文章的重點。
1、一個好的軟件架構,應該遵循高性能、高可用、易擴展 3 大原則,其中「高可用」在系統規模變得越來越大時,變得尤為重要
2、系統發生故障并不可怕,能以「最快」的速度恢復,才是高可用追求的目標,異地多活是實現高可用的有效手段
3、提升高可用的核心是「冗余」,備份、主從副本、同城災備、同城雙活、兩地三中心、異地雙活,異地多活都是在做冗余
4、同城災備分為「冷備」和「熱備」,冷備只備份數據,不提供服務,熱備實時同步數據,并做好隨時切換的準備
5、同城雙活比災備的優勢在于,兩個機房都可以接入「讀寫」流量,提高可用性的同時,還提升了系統性能。雖然物理上是兩個機房,但「邏輯」上還是當做一個機房來用
6、兩地三中心是在同城雙活的基礎上,額外部署一個異地機房做「災備」,用來抵御「城市」級別的災害,但啟用災備機房需要時間
7、異地雙活才是抵御「城市」級別災害的更好方案,兩個機房同時提供服務,故障隨時可切換,可用性高。但實現也最復雜,理解了異地雙活,才能徹底理解異地多活
8、異地多活是在異地雙活的基礎上,任意擴展多個機房,不僅又提高了可用性,還能應對更大規模的流量的壓力,擴展性最強,是實現高可用的最終方案
后記
這篇文章我從「宏觀」層面,向你介紹了異地多活架構的「核心」思路,整篇文章的信息量還是很大的,如果不太好理解,我建議你多讀幾遍。
因為篇幅限制,很多細節我并沒有展開來講。這篇文章更像是講異地多活的架構之「道」,而真正實施的「術」,要考慮的點其實也非常繁多,因為它需要開發強大的「基礎設施」才可以完成實施。
不僅如此,要想真正實現異地多活,還需要遵循一些原則,例如業務梳理、業務分級、數據分類、數據最終一致性保障、機房切換一致性保障、異常處理等等。同時,相關的運維設施、監控體系也要能跟得上才行。
宏觀上需要考慮業務(微服務部署、依賴、拆分、SDK、Web 框架)、基礎設施(服務發現、流量調度、持續集成、同步中間件、自研存儲),微觀上要開發各種中間件,還要關注中間件的高性能、高可用、容錯能力,其復雜度之高,只有親身參與過之后才知道。
我曾經有幸參與過,存儲層同步中間件的設計與開發,實現過「跨機房」同步 MySQL、Redis、MongoDB 的中間件,踩過的坑也非常多。當然,這些中間件的設計思路也非常有意思,有時間單獨分享一下這些中間件的設計思路。
值得提醒你的是,只有真正理解了「異地雙活」,才能徹底理解「異地多活」。在我看來,從同城雙活演變為異地雙活的過程,是最為復雜的,最核心的東西包括,業務單元化劃分、存儲層數據雙向同步、最上層的分片邏輯,這些是實現異地多活的重中之重。
希望我分享的架構經驗,對你有所啟發。
責任編輯:haq
-
分布式
+關注
關注
1文章
895瀏覽量
74498 -
架構
+關注
關注
1文章
513瀏覽量
25468
原文標題:搞懂異地多活,看這篇就夠了
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
安科瑞Acrel-1000DP分布式光伏監控系統在8.3MWp分布式光伏發電中的應用
分布式輸電線路故障定位中的分布式是指什么

一體式IO與分布式IO:工業控制系統的兩種架構

分布式SCADA系統的特點的組成
訊維分布式KVM坐席管理系統在數據中心管理中的應用與案例分析
分布式KVM坐席管理系統:打造智慧化城市運營新引擎
分布式系統在交通監控工程中的創新應用案例
Redis實現分布式多規則限流的方式介紹

鴻蒙OS 分布式任務調度
分布式大屏控制系統的可擴展性設計
如何提高分布式大屏控制系統的穩定性和可靠性
什么是分布式架構?
分布式節點服務器是什么?






 工商網監
工商網監
評論