 企業數據平臺:從單體數據湖到分布式數據網格
企業數據平臺:從單體數據湖到分布式數據網格
我工作過的許多公司,都把成為數據驅動型組織設定為它們的首要戰略目標之一。我的客戶深知AI賦能的益處:可以提供基于數據和超個性化(hyper-personalization)的最佳客戶體驗;同時通過數據驅動的優化減少運營成本和時間;還可以為員工提供更強大的趨勢分析和BI能力。他們一直在大力投資數據和智能平臺等賦能引擎。遺憾的是,盡管這些企業在構建此類賦能平臺方面付出了更多的努力和投入,但結果往往不盡人意。
我理解企業在轉變成為數據驅動的組織的過程中面臨著多方面的難題。因為他們從數十年的遺留系統遷移而來的同時,也會被反對依賴數據的遺留文化影響,同時,競爭激烈的業務優先級排序也阻礙了這種轉變。但是,我想分享一種導致數據平臺計劃失敗的架構視角。我將展示如何將過去十年在分布式架構中的學習成果應到數據領域中。我也會介紹一種新的企業數據架構,稱為數據網格(即Data Mesh)。
在閱讀之前,我的建議是暫時先放下“基于當前數據平臺體系構建范式”的假設和偏見;對從單體式和中心化數據湖轉變到數據網格架構的可能性持開放態度;擁抱數據永遠存在、無處不在、天然具有分布性特征的現實。
當前的企業數據平臺架構
它是中心式,單體式和領域不可知的,又被稱為數據湖。
幾乎每個與我合作的客戶都在計劃或正在構建他們的第三代數據和智能平臺,同時也承認過去幾代的失敗:
第一代:專有的企業數據倉庫和商業智能平臺;這些高價的解決方案使公司承擔了巨大的技術債務。這數千個無法維護的數據倉庫技術作業、表格和報告中的技術債務,卻只有一小部分專業人員能夠理解,這使得其對業務產生的積極影響被低估。
第二代:以數據湖為”特效藥“的大數據生態系統;在復雜的大數據生態系統中,超專業數據工程師團隊經過長期運行,已經創建了“數據湖怪獸”,這些龐然大物充其量可以實現大量的“研究與開發”分析,但是存在“承諾有余、實現不足”的情況。
第三代和當前的數據平臺或多或少與上一代相似,但在現代方向上轉變如下:(a)通過Kappa等架構進行流傳輸以實現實時數據可用性,(b)使用Apache Beam等框架統一批處理和流處理以進行數據轉換,(c)全面采用基于云的托管服務,用于存儲,數據管道執行引擎和機器學習平臺。
顯然,第三代數據平臺正在填補前幾代的空白,并在降低管理大數據基礎架構的成本,例如實時數據分析。但是,它同樣具有許多導致上一代失敗的潛在特征。
架構故障模式
為說明各代數據平臺所面臨的潛在限制,讓我們先看一下它們的體系結構和特征。在本文中,我以互聯網媒體流業務領域(例如Spotify,SoundCloud,Apple iTunes等)為例來闡明一些概念。
中心式和單體式
宏觀來看,數據平臺架構如下圖1所示。中心式架構,其目標是:
從企業的各個角落提取數據,這些數據的范圍包括企業的運營和交易系統以及經營業務的領域,還有擴展企業知識的外部數據提供商。例如,在流媒體業務中,數據平臺負責攝取各種數據:“媒體播放器性能”,“用戶與播放器的交互方式”,“被演奏的歌曲”,“被關注的藝術家”以及作為企業已加入的“標簽和藝術家”,與藝術家的“經濟往來”以及外部市場研究數據(例如“客戶人口統計”信息)。
平臺清理、豐富源數據并將其轉換為可滿足各種消費者需求的可信賴數據。在我們的示例中,其中一種轉換是將用戶交互的點擊流變成了帶有用戶詳細信息的數據。這試圖在聚合中重構用戶的行為。
平臺將數據集提供給具有各種需求的消費者,達到分析消費,探索數據以尋找洞見的目的,同時也可以實現基于機器學習的決策制定,撰寫總結業務績效的商業智能報告等。在我們的流媒體示例中,該平臺可以通過分布式日志界面(例如Kafka)提供有關全球媒體播放器的實時信息,或提供正在播放的特定藝術家靜態匯總視圖,以幫助財務理清給藝術家和唱片公司的付款。
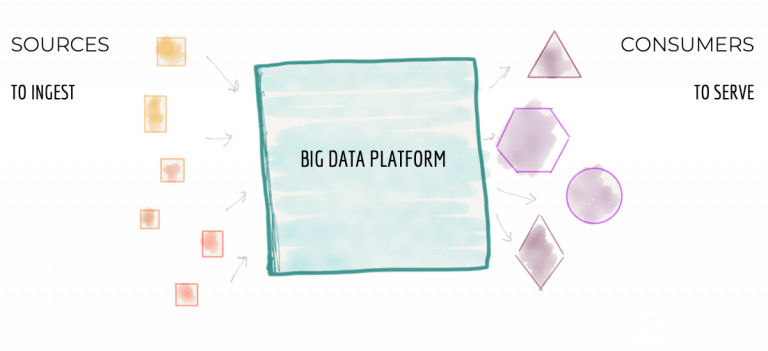
圖1:宏觀視角下整體數據平臺視圖
一般來說,整體數據平臺會托管邏輯上屬于不同領域的數據。例如“播放事件”,“銷售KPI”,“藝術家”,“專輯”,“標簽”,“音頻”,“播客”,“音樂事件”等;來自大量不同領域的數據。
在過去的十年中,盡管我們已成功將領域驅動的設計和有限的上下文應用于我們的操作系統,但我們在很大程度上忽略了數據平臺中的領域概念。我們已經從面向領域的數據所有權轉移到中心式的不可知數據所有權的域。我們以創建最大的整體(即大數據平臺)而自豪。
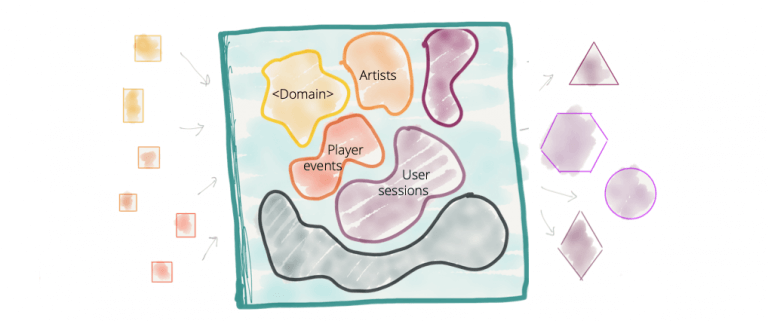
圖2:領域數據界限和所有權不清的數據平臺
盡管此中心式模型可用于領域更簡單、消費案例數量較少的企業,但對于領域豐富,來源眾多且消費者多樣化的企業卻不適用。
中心式數據平臺的體系結構和組織結構上存在兩個壓力點,這些壓力點通常會導致失敗:
無處不在的數據和源擴散:隨著越來越多的數據變得無處不在,在一個平臺的控制下,在一個地方使用所有數據并進行協調的能力將減弱。想象一下,僅在“客戶信息”領域,在企業內外都有越來越多的提供有關現有和潛在客戶的信息來源。如果假設我們需要在一個地方攝取和存儲數據以從各種來源中獲取價值,我們對數據來源擴散的響應能力將被限制。我認為需要數據用戶(例如數據科學家和分析師)以低成本來處理各種數據集,并且需要將操作系統數據使用的數據與用于分析目的的數據區分開來。但是我認為,如果企業是具有豐富領域和不斷添加新資源的大型組織,現有的中心式解決方案不是最佳解決方案。
組織的創新計劃和消費者激增:組織對快速試驗的需求引入了大量用例來消費平臺中的數據。這意味著數據轉換(可以滿足創新的測試和學習周期的聚合,投影和切片)的數量正在不斷增長。滿足數據消費者需求的響應時間過長一直是企業面臨的一個問題,而在現代數據平臺體系結構中仍然如此。
盡管我現在還不想放棄我的解決方案,但我需要澄清的是,我倡導的領域數據不是隱藏在操作系統中的,分散的,孤立的,也不是難以發現,理解和使用的。我不支持技術債務中形成的分散數據倉庫。這是行業領導者的關注點。但是我認為,解決這些問題的方法并不是建立一個中心式的數據平臺,而是由一個中心團隊組成來管理。正如我們在上面論證的那樣,它沒有組織化的規模。
耦合流水線分解
傳統數據平臺體系結構的第二種故障模式與我們如何分解體系結構有關。放大中心式數據平臺后,我們發現一個圍繞攝取,清理,聚合,服務等機械功能的架構分解。企業中的架構師和技術領導者會根據平臺的增長來分解架構。如上一節所述,引入新資源或應對新消費者的需求要求平臺不斷發展。架構師需要找到一種方法,通過將其分解為體系結構量子來擴展系統。如《設計可進化架構》中所述,架構量子是具有高功能凝聚力的、可獨立部署的組件,其中包括系統正常運行所需的所有結構要素。將系統分解成架構量子是為了創建獨立的團隊,團隊里每個人都可以構建和操作架構量子。這些團隊之間的并行工作可提高的運營可擴展性和速度。
鑒于前幾代數據平臺體系結構的影響,架構師將數據平臺分解為一系列數據處理階段。這邪惡管道在高水平處理數據并實現攝取,準備,匯總,服務等功能的凝聚。
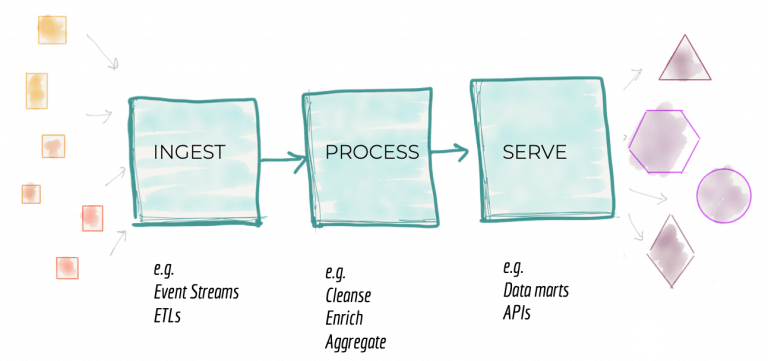
圖3:數據平臺的體系結構分解
盡管此模型通過將團隊分配到流水線的不同階段擴大了規模,但它具有一個固有的局限性,那就是使功能交付速度變慢。它在流水線的各個階段之間具有很高的耦合度,以提供獨立的功能或價值。它與變化軸正交分解。
讓我們看一下我們的流媒體示例。 網絡流媒體平臺有一個強大的媒體類型領域構造。他們通常從“歌曲”和“專輯”等服務開始,然后擴展到“音樂事件”,“播客”,“廣播節目”,“電影”等。啟用單個新功能,例如“播客播放率”的可見性,則需要更改管道中的所有組件。團隊必須引入新的攝取服務,新的清理和準備工作以及用于查看播客播放率的合集。這需要在組件之間進行同步,并在團隊之間進行發布管理。許多數據平臺提供的提取服務可以應資源添加擴展問題,以最大程度地減少開銷。但是,這并沒有從消費者角度解決端到端依賴性問題。我們看似已經達到了流水線階段的架構,但實際上整個流水線(即單體式平臺)是必須改成適應新功能的最小單元:解鎖新數據集并將其用于新的或現有的消費。這限制了我們響應新的使用者或數據源以實現更高速度和更大規模的能力。
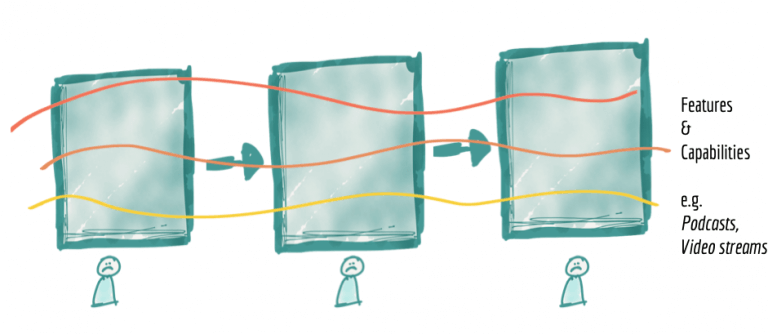
圖4:引入或增強功能時,架構分解與更改軸正交,從而導致耦合和交付速度降低
孤立和超專業的所有權
當今數據平臺的第三種失敗模式與我們如何組織構建平臺的團隊有關。當我們實地觀察數據平臺的人員的生活時,我們發現他們是一群與組織運營部門隔離的超專業數據工程師;對于數據源自何處或在何處使用并付諸行動和決策制定并不知情。數據平臺工程師不僅在組織上處于孤立狀態,而且根據他們在大數據工具方面的技術專長(通常缺乏業務和領域知識)分類使得他們通常缺乏業務和領域知識。
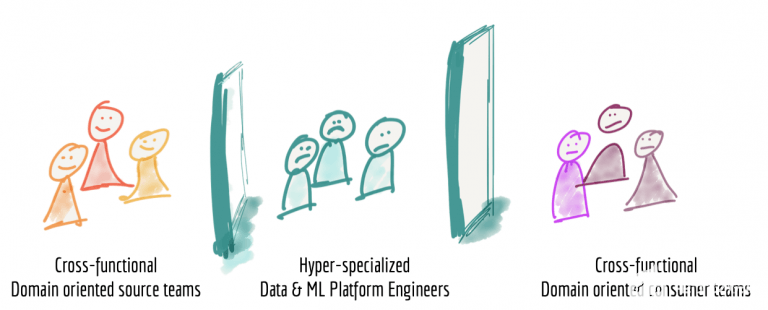
圖5:孤立的超專業數據平臺團隊
我并不羨慕數據平臺工程師的生活。他們需要消費來自團隊的數據,這個團隊通常不能提供有意義的、真實的和正確的數據。他們對生成數據的源域了解甚少,并且團隊中缺乏領域專業知識。他們需要針對各種操作或分析的需求提供數據,但卻不了解數據的應用,也無需與使用領域專家聯系。
在媒體流領域,比如在源端,我們有跨職能的“媒體播放器”團隊,可提供有關用戶如何與他們提供的特定功能進行交互的信號,例如“播放歌曲事件”,“購買事件”,“播放音頻質量”等;另一端是消費者跨職能團隊,例如“歌曲推薦”團隊,報告銷售KPI的“銷售團隊”,根據演出計算和付款給藝人的“藝人支付團隊”等。不幸的是,位于中間的數據平臺團隊則拼命為所有來源和消費提供合適的數據。
實際上,我們還發現有的源團隊彼此沒有聯系,有的互相爭奪,導致過度拉伸。
我們創建的架構和組織結構無法擴展,并且無法實現創建數據驅動型組織所承諾的價值。
下一代企業數據平臺架構
它通過分布式數據網格包含了無處不在的數據。
那么,我們上面討論的故障模式和特征的答案是什么?我認為有必要進行范式轉換,以期在大規模構建現代分布式體系結構中發揮作用。整個技術行業都采用了這些技術,并取得了成功。
我建議下一代企業數據平臺架構是分布式領域驅動架構、自助式平臺設計以及產品思維與數據的融合。
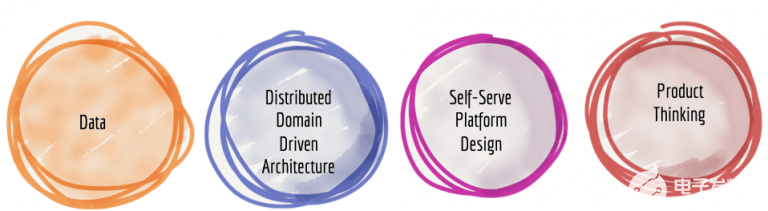
圖6:融合:構建下一個數據平臺的模式轉變
盡管這聽起來像是一句空話,但是這些技術確實在現代化操作系統的技術基礎方面產生了具體的、令人難以置信的積極影響。讓我們來深入研究一下如何將這些方法應用于數據世界,以擺脫當前的舊范式。
數據和分布式領域驅動的架構融合
面向領域的數據分解和所有權
埃里克·埃文斯(Eric Evans)的著作《領域驅動設計》(Domain-Driven Design)對現代架構思想以及組織建模產生了深遠的影響。它通過將系統分解為圍繞業務領域功能構建的分布式服務來影響微服務體系結構。它從根本上改變了團隊的組成方式,從而使團隊可以獨立自主地擁有領域能力。
盡管在實現運營功能時我們采用了定向領域分解和所有權,但奇怪的是,在涉及數據時,我們卻忽略了業務領域的概念。 DDD在數據平臺體系結構中最接近的應用是用于源操作系統發出其業務領域事件,并用于整體數據平臺來接收它們。但是,超出攝取點的范圍,就失去了領域的概念以及不同團隊對領域數據的所有權。
領域綁定上下文是一種功能強大的工具,可用于設計數據集的所有權。 Ben Stopford的Data Dichotomy文章介紹了通過流共享領域數據集的概念。
為了使單體式數據平臺分散化,我們需要顛覆我們對數據本地性和所有權的看法。與其將數據從領域中流到中央擁有的數據湖或平臺中,不如說領域需要以易于使用的方式托管和服務于其領域數據集。
在我們的示例中,與其想象來自媒體播放器的數據流到某個集中位置以供一個集中的團隊接收,不如想象我們有一個擁有并服務其數據集的播放器領域以滿足團隊下游使用的任何目的。數據集實際駐留的物理位置及其流動方式是“播放器領域”的技術實現。物理存儲肯定可以是諸如Amazon S3存儲桶之類的中心式架構,但播放器數據集的內容和所有權仍保留在生成它們的領中。類似地,在我們的示例中,“推薦”領域以適合其應用的格式創建數據集,例如圖形數據庫,同時消化了播放器數據集。如果還有其他領域(例如“新藝術家發現領域”)對“推薦領域”圖數據集有用,則可以選擇提取和訪問該領域。
這意味著當我們將數據轉換為適合該特定領域的形狀時,我們可能會在不同領域中復制數據。例如,與藝術家相關的時間序列播放事件的圖表。
這就要求我們將思維方式從傳統上通過ETL、當前通過事件流的推入和獲取模型轉移到跨所有域的服務和提取模型。
面向領域的數據平臺中的體系結構范圍是一個領域,而不是流水線階段。
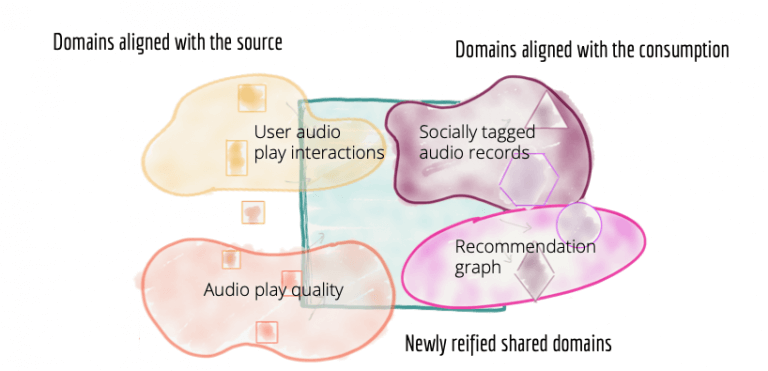
圖7:根據域(源域,使用者域和新創建的共享域)分解擁有數據的架構和團隊
面向源的領域數據
一些領域自然地與數據起源的源一致。源域數據集代表業務的現實情況。源域數據集捕獲與其操作系統的來源和現實關聯非常緊密的數據。在我們的示例中,諸如“用戶如何與服務進行交互”或“入職標簽流程”之類的業務事實導致領域數據集的創建,例如“用戶點擊流”,“音頻播放質量流”和“內置標簽”。這些事實是眾所周知的,并且是由起源處的操作系統生成的。例如,媒體播放器系統最了解“用戶點擊流”。
在理想的情況下,操作系統及其團隊或組織單位不僅負責提供業務功能,而且還負責提供其業務領域的真實情況作為源域數據集。在企業規模上,領域概念和源系統之間從來沒有一對一的映射。通常,有許多系統可以服務屬于某個領域的部分數據,其中一些是舊式的,而某些則易于更改。因此,可能會有許多源對齊的數據集(也稱為現實數據集),最終需要將它們匯總到一個內聚的領域對齊的數據集中。
商業事實最好以商業領域事件的形式呈現,可以將其存儲并作為帶有時間標記的事件的分布式日志,以供任何授權消費者訪問。
除了定時事件外,源數據域還應提供易于使用的源域數據集的歷史快照,這些密切反映其領域的更改間隔的記錄在一定時間范圍內匯總。例如,在向流媒體業務提供音樂的藝術家的“內嵌標簽”源域中,每月匯總通過入職標簽生成的事件的內嵌標簽是一種合理的視圖。
請注意,源對齊領域數據集必須與內部源系統的數據集分開。領域數據集的性質與操作系統用來完成其工作的內部數據有很大不同。與它們的系統相比,它們具有更大的體積,代表著不變的定時事實,并且變化的頻率更低。因此,實際的基礎存儲必須適合大數據,并且必須與現有的操作數據庫分開。數據和自助平臺設計融合部分將介紹如何創建大數據存儲和服務基礎架構。
源域數據集是最基礎的數據集,由于業務事實并不經常更改,所以更改頻率較低。預計這些領域數據集將被永久儲存使用,以便隨著企業發展其數據驅動和情報服務,他們始終可以返回到業務事實,并創建新的匯總或預測。
請注意,源域數據集在創建時幾乎代表原始數據,并且未針對特定使用者進行擬合或建模。
面向消費者的共享領域數據
一些領域與消費密切相關。消費者領域數據集和擁有它們的團隊的目的是滿足一組密切相關的用例。例如,“社交推薦領域”側重于根據用戶彼此之間的社交聯系提供推薦,創建適合此特定需求的領域數據集;也可以通過“用戶社交網絡的圖形”表示。此數據集對于推薦用例很有用,也許對于“聽眾通知”領域也有用,該領域提供給不同聽眾發送通知的數據,比如其社交網絡中的人正在聽的內容。因此,“用戶社交網絡”有可能成為共享的和新定義的領域數據集,供多個消費者使用。 “用戶社交網絡”領域團隊專注于提供“用戶社交網絡”的最新視圖。
消費者對齊的領域數據集與源域數據集相比具有不同的性質。它們在結構上經歷了更多的變化,并且將源域事件轉換為聚合適合特定訪問模型的視圖和結構,例如我們在上面看到的圖形示例。面向領域的數據平臺應該能夠輕松地從源頭重新生成這些消費者數據集。
分布式管道作為領域內部實現
盡管將數據集所有權從中央平臺委托給領域,但是仍然需要清理,準備,聚合和提供數據,數據管道的使用也是如此。在這種體系結構中,數據管道只是內部復雜性和數據域的實現,并在域內部進行處理。結果,我們將看到數據管道階段分布到每個領域中。
例如,源域需要包括對其領域事件的清除,重復數據刪除,擴展它們的領域以便其他領域可以使用它們,而無需復制清除。每個領域數據集都必須為其提供的數據質量、及時性,錯誤率等建立服務水平目標:。例如,我們提供音頻“播放點擊流”的媒體播放器領域可以包括清理和標準化其領域中的數據管道,這樣就可以提供“播放音頻點擊事件”的實時數據流。
同樣,我們將看到從中心式管道的聚合階段進入了消費領域的細節的實現。
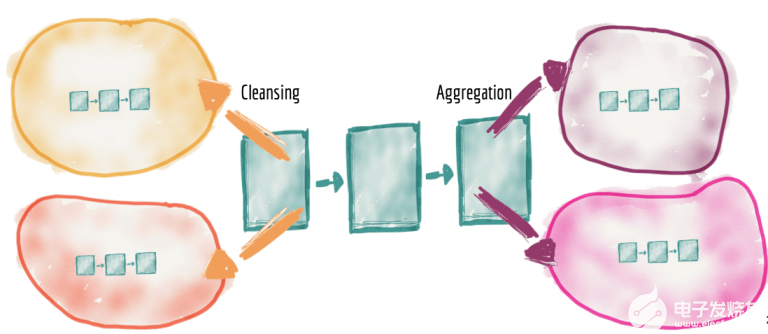
圖8:將管道分配到領域中作為第二類關注點,以及領域的內部實現細節
有人可能會爭辯說,該模型可能會導致每個領域在創建自己的數據處理管道實現,技術堆棧和工具方面做出重復的努力。我將在談論數據和以自助共享數據基礎架構為平臺的思維融合時,很快解決這個問題。
數據和產品思維融合
將數據所有權和數據管道實施分配到業務領域中這件事引起了人們對分布式數據集的關注可行性,可用性和協調性。在這里,學習應用產品思維和數據資產所有權非常方便。
領域數據作為產品
在過去的十年中,運營領域已經將產品思想融入了他們為組織其他部門提供的能力中。領域團隊將這些能力作為API(應用程序接口)提供給組織中其他開發人員以作為創建更高價值和功能的基礎。這些團隊致力于為他們的領域API(應用程序接口)創建最佳的開發人員體驗;包括可發現且易于理解的API文檔,API測試箱,同時密切跟蹤質量和應用的關鍵績效指標。
為了使分布式數據平臺獲得成功,領域數據團隊必須以相似的嚴格度將產品思維應用于他們提供的數據集。將其數據資產視為產品,并將組織里的其余數據科學家,機器學習和數據工程師視為客戶。
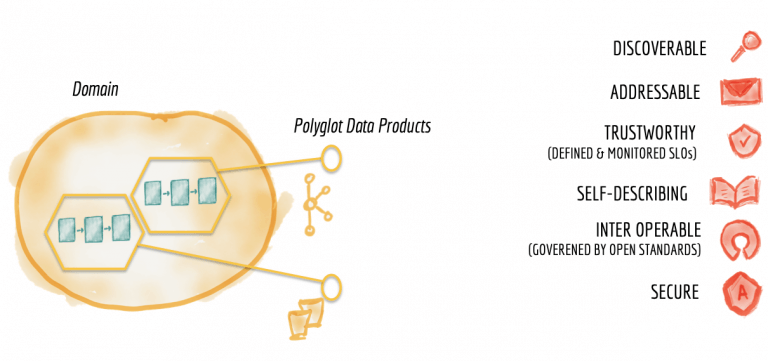
圖9:領域數據集作為產品的特征
回顧我們的示例,互聯網媒體流業務。它的關鍵領域之一是“播放事件”,即誰,何時,何地播放了哪些歌曲。這個關鍵的領域在組織中擁有不同的使用者;例如,近實時消費者會對用戶體驗以及可能的錯誤感興趣,因此在客戶體驗下降或客戶支持電話打入的情況下可以快速響應以恢復錯誤。還有一些消費者更喜歡每日或每月歌曲播放事件聚合的歷史記錄。
在這種情況下,我們的“播放的歌曲”領域為組織的其他部分提供了兩個不同的數據集作為產品。在事件流上公開的實時播放事件,以及在對象存儲中作為序列化文件公開的聚合播放事件。
任何技術產品(這里說的是領域數據產品)的一項重要素質就是使它們的消費者滿意。(這里指的是數據工程師,機器學習工程師或數據科學家。)為了向消費者提供最佳的用戶體驗,領域數據產品需要具有以下基本素質:
可發現的
數據產品必須易于發現。常見的實現方式是對所有可用的數據產品及其元信息(例如其所有者,來源,樣本數據集等)編寫目錄。此中心式可發現性服務使組織里的數據消費者,工程師和科學家能夠輕松找到他們需要的數據集。每個領域數據產品都必須在此中心式數據目錄中注冊以方便查詢。
請注意,這里的觀點轉變是從單一平臺提取數據,到以可發現的方式將其數據作為產品提供到每個領域。
可尋址的
數據產品一經發現,便應該遵循國際慣例,有一個唯一地址,以幫助其用戶以編程方式訪問它。根據數據的基礎存儲和格式,組織可以為數據采用不同的命名約定。考慮到易用性,在分散式體系結構中,有必要制定通用的約定。不同的領域存儲和提供數據集的格式不同,事件可能通過諸如Kafka主題之類的流進行存儲和訪問,而柱狀數據集可能使用CSV文件或序列化Parquet文件的AWSS3存儲桶。多種語言環境中的數據集可尋址性標準消除了查找和訪問信息時的摩擦。
可信賴且真實的
沒有人會使用他們不信任的產品。在傳統的數據平臺中,存在數據有誤、不能反映業務真相或者根本無法信任的情況。在這里,中心式數據管道的大部分工作都集中在此,在提取數據后清理數據。
如果要達到根本性的轉變,數據產品的所有者要圍繞數據的真實性提供可接受的服務,以及提供它與事件發生的真實性的接近程度。在創建數據產品時應該應用數據清理和自動數據完整性測試。提供數據源和數據沿襲作為與每個數據產品相關聯的元數據有助于增加消費者對產品及其適用性方面的信任。
數據完整性(質量)指標的目標值或范圍在領域數據產品之間有所不同。例如,“播放事件”領域可以提供兩種不同的數據產品,一種接近實時,準確性較低,包括丟失或重復的事件,而另一種則具有較長的延遲和較高的事件準確性。每個數據產品定義并保證其作為一組SLO的完整性和真實性。
自描述的語義和語法
優質的產品不需要消費者手持即可使用:它們可以被查詢,理解和消費。將數據集構建為具有最小單元的產品,以供數據工程師和數據科學家使用,這需要對語義和語法對數據進行充分描述,理想情況下將樣本數據集作為示例。數據模式是提供自助數據資產的起點。
可互操作并受全球標準約束
分布式領域數據體系結構中的主要問題之一是關聯跨領域數據并將其有機縫合、連接,過濾,聚合的能力。跨領域有效關聯數據的關鍵是遵循某些標準和統一規則。這樣的標準化應該用于全球治理,以實現多語言領域數據集之間的互操作性。這種標準化工作的共同關注點是字段類型格式化,跨不同領域識別多義詞,數據集地址約定,通用元數據字段,事件格式(例如CloudEvents)等。
例如,在媒體流業務中,“藝術家”可能出現在不同的領域中,并且在每個領域中具有不同的屬性和標識符。 “播放事件流”域對藝術家的識別可能與負責開發票和付款的“藝術家支付”領域的識別不同。但是,為了能夠在不同領域的數據產品之間關聯藝術家的數據,我們需要就如何將藝術家識別為多義詞達成共識。一種方法是考慮具有聯合實體的“藝術家”和“藝術家”的唯一全局聯合實體標識符,這與管理聯合身份的方式類似。
受全球管轄的通信的互操作性和標準化是構建分布式系統的基礎支柱之一。
安全并受全局訪問控制
無論架構是否中心化,都必須安全地訪問產品數據集。在分散的面向領域的數據產品的世界中,對每個領域數據產品都被以更小的單元應用訪問控制。與操作領域類似,訪問控制策略可以被集中定義,但是也可以應用到每個單獨的數據集產品上。使用企業身份管理系統(SSO)和基于角色的訪問控制策略定義是實現產品數據集訪問控制的便捷方法。
數據和自助服務平臺設計的融合部分描述了這一共享的基礎結構,該基礎結構可輕松、自動地為每個數據產品啟用上述功能。
領域數據跨職能團隊
將數據作為產品提供的領域;需要增加新的技能:(a)數據產品所有者和(b)數據工程師。
數據產品所有者根據數據產品的愿景和路線圖做出決策,更多關注消費者的滿意度,并不斷衡量和提高其領域擁有和生產的數據的質量和豐富性。她負責領域數據集的生命周期,以及何時更改,修訂和淘汰數據和架構。她在領域數據使用者的競爭需求之間取得了平衡。
數據產品所有者必須定義成功標準和與業務相關的關鍵績效指標(KPI)。例如,數據產品的消費者成功發現和使用數據產品的交付時間是可衡量的成功標準。
為了構建和運行領域的內部數據管道,團隊必須擁有數據工程師。這種跨職能團隊的一個奇妙的副作用是跨團隊技能互補。我目前的行業觀察是,一些數據工程師雖然能夠使用其交易工具,但在構建數據資產時缺乏軟件工程標準實踐,例如在連續交付和自動化測試方面。同樣,構建操作系統的軟件工程師通常也沒有使用數據工程工具集的經驗。消除技能孤島有助于創建更大的數據工程技能庫。我們已經觀察到與DevOps運動相同的跨團隊技能互補,以及諸如SRE之類的新型工程師的誕生。
必須將數據視為任何軟件生態系統的基礎,因此軟件工程師和軟件通才必須將數據產品開發的經驗和知識添加到他們的工具帶中。同樣,基礎架構工程師需要增加管理數據基礎架構的知識和經驗。企業必須提供從通才到數據工程師的職業發展途徑。由于缺少數據工程的技術從而導致了之前「孤立和超專業的所有權」那節中的中心化的數據工程團的過度局部優化的問題。

圖10:具有明確數據產品所有權的跨功能領域數據團隊
數據和自助平臺設計融合
將數據所有權分配給領域的主要問題之一是可能存在重復工作。幸運的是,將通用基礎架構構建為平臺已經是眾所周知的問題,并且已經得到解決。
將領域不可知的基礎架構功能收集和提取到數據基礎架構平臺中,解決了重復設置數據管道引擎,存儲和流基礎架構的工作的問題。數據基礎架構團隊可以擁有并提供域發現,處理,存儲和服務其數據產品所需的必要技術。
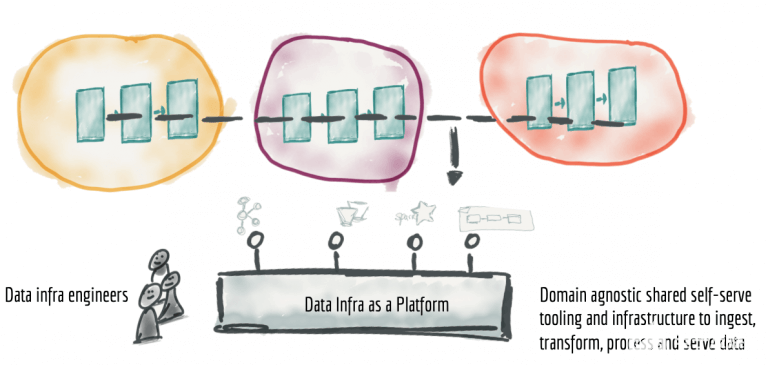
圖11:提取和收集與領域無關的數據管道基礎架構,并將工具構建到作為平臺的獨立數據基礎架構中
將數據基礎架構構建為平臺的關鍵是(a)不包含任何特定于領域的概念或業務邏輯,使其保持領域不可知性;以及(b)確保平臺隱藏了所有潛在的復雜性和提供了數據基礎架構組件自助服務的方式。自助數據基礎架構作為平臺向用戶(領域的數據工程師)提供的功能種類繁多。這里有幾個:
可擴展的多語言大數據存儲
加密靜態和動態數據
數據產品版本控制
數據產品架構
數據產品去識別
統一的數據訪問控制和記錄
數據管道的實現和編排
數據產品發現,目錄注冊和發布
數據治理與標準化
數據產品沿襲
數據產品監控/報警/日志
數據產品質量指標(收集和共享)
內存中數據緩存
聯合身份管理
計算和數據局部性
自助數據基礎架構的成功標準是減少“創建新數據產品的時間”。這將引導“數據產品”功能所需的自動化,這在“將領域數據作為產品”部分中進行了介紹。例如,通過配置和腳本自動執行數據提取,將腳手架放置在適當位置的數據產品創建腳本,在目錄中自動注冊數據產品等。
使用云基礎架構作為基礎可以減少運營成本和工作量,但是,它并沒有完全消除需要在業務環境中放置的更高的抽象。無論云提供商如何,數據基礎架構團隊都可以使用一組豐富且不斷增長的數據基礎結構服務。
向數據網格轉移的范式
讀了這么久了,讓我們總結一下。我們研究了當前數據平臺的一些基本特征:中心式,單體式,高度耦合的管道架構,由超專業數據工程師的獨立操作。我們介紹了作為平臺的無處不在的數據網格的構建模塊;面向領域的分布式數據產品,由獨立的跨職能團隊擁有,這些團隊具有嵌入式數據工程師和數據產品所有者,使用通用數據基礎結構作為承載,準備和服務其數據資產的平臺。
數據網格平臺是經過精心設計的分布式數據體系結構,在集中管理和標準化下實現了互操作性,并通過共享和統一的自助式數據基礎結構實現了此功能。我希望,它與無法訪問的數據零散孤島的景象不同。
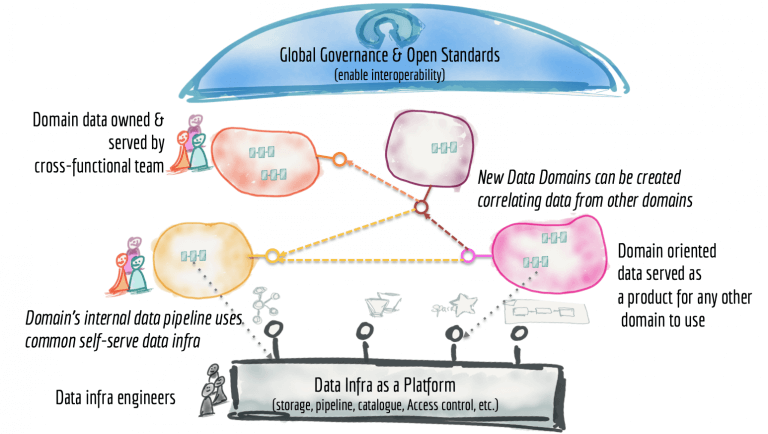
圖12:俯視數據網格架構
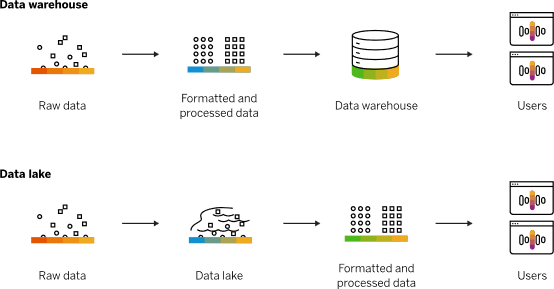
那么,數據湖或數據倉庫在此體系結構中適合什么位置?它們只是網格上的節點。我們很有可能不需要數據湖,因為保存原始數據的分布式日志和存儲是可用與從作為產品的不同的、可尋址的、不可變的數據集中作為產品中進行探索。但是,如果我們確實需要更改數據的原始格式以進行進一步的探索(例如標記),則有此需求的領域可能會創建自己的湖泊或數據中心。
因此,數據湖不再是整個體系結構的核心。我們將繼續應用一些數據湖的原理,例如使不變的數據可用于勘探和分析用途。我們將繼續使用數據湖工具,但是將其用于數據產品的內部實施或作為共享數據基礎結構的一部分。
實際上,這使我們回到了一切的起點:2010年,James Dixon打算將一個數據湖用于單個領域,而多個數據域將形成一個“水上花園”。
主要轉變是將領域數據產品視為第一類關注點,而將數據湖工具和管道視為第二類關注點-即實現細節。這將當前的思維模型從中心化式數據湖轉變為可以很好地協同工作的數據產品生態系統,即數據網格
相同的原則適用于用于業務報告和可視化的數據倉庫。它只是網格上的一個節點,并且可能位于網格的面向消費者的邊緣上。
我承認,盡管我看到數據網格實踐已在我的客戶中應用,但企業規模的采用仍然有很長的路要走。我不認為技術是這里的局限性,我們今天使用的所有工具都可以容納多個團隊的分配和所有權。尤其是向批處理和流傳輸以及諸如Apache Beam或Google Cloud Dataflow之類的工具統一的轉變,可以處理多種類型的數據集。
諸如Google Cloud Data Catalog之類的數據目錄平臺提供了中心化的可發現性,訪問控制和分布式領域數據集的治理。多種云數據存儲選項使領域數據產品可以選擇適合用途的多語言存儲。
需求是真實的,工具已經準備就緒。這需要組織的工程師和領導者來認識到,僅使用新的基于云的工具,現有的大數據范例和一個真正的大數據平臺或數據湖就只會重復過去的失敗。
這種范式轉換需要一套新的管理原則以及一種新的語言:
服務而不是提取
發現和使用而不是提取和載入
發布事件流而不是利用中心化的管道來管理數據
數據產品生態而不是中心化數據平臺
讓我們將大數據單體分解為一個統一,協作和分布式的數據網格生態系統。
來源:https://insights.thoughtworks.cn/data-monolith-to-mesh/
編輯:fqj
-
分布式
+關注
關注
1文章
920瀏覽量
74573 -
數據網絡
+關注
關注
0文章
48瀏覽量
11554
發布評論請先 登錄
相關推薦
HarmonyOS Next 應用元服務開發-分布式數據對象遷移數據文件資產遷移
HarmonyOS Next 應用元服務開發-分布式數據對象遷移數據權限與基礎數據
探秘IO分布式模塊設計:讓大數據處理更高效

鴻蒙開發接口數據管理:【@ohos.data.distributedDataObject (分布式數據對象)】
鴻蒙開發接口數據管理:【@ohos.data.distributedData (分布式數據管理)】

HarmonyOS開發實例:【分布式數據服務】
鴻蒙HarmonyOS開發實例:【分布式關系型數據庫】
分布式運維管理平臺在跨地域企業中的部署與運維案例
分布式運維管理平臺解決大型數據中心運維難題的案例






 工商網監
工商網監
評論