") 解密高并發(fā)業(yè)務(wù)場景下典型的秒殺系統(tǒng)的架構(gòu)
解密高并發(fā)業(yè)務(wù)場景下典型的秒殺系統(tǒng)的架構(gòu)
很多小伙伴反饋說,高并發(fā)專題學(xué)了那么久,但是,在真正做項目時,仍然不知道如何下手處理高并發(fā)業(yè)務(wù)場景!甚至很多小伙伴仍然停留在只是簡單的提供接口(CRUD)階段,不知道學(xué)習(xí)的并發(fā)知識如何運用到實際項目中,就更別提如何構(gòu)建高并發(fā)系統(tǒng)了!
究竟什么樣的系統(tǒng)算是高并發(fā)系統(tǒng)?今天,我們就一起解密高并發(fā)業(yè)務(wù)場景下典型的秒殺系統(tǒng)的架構(gòu),結(jié)合高并發(fā)專題下的其他文章,學(xué)以致用。
電商系統(tǒng)架構(gòu)
在電商領(lǐng)域,存在著典型的秒殺業(yè)務(wù)場景,那何謂秒殺場景呢。簡單的來說就是一件商品的購買人數(shù)遠(yuǎn)遠(yuǎn)大于這件商品的庫存,而且這件商品在很短的時間內(nèi)就會被搶購一空。
比如每年的618、雙11大促,小米新品促銷等業(yè)務(wù)場景,就是典型的秒殺業(yè)務(wù)場景。
我們可以簡單的將電商系統(tǒng)的核心層分為:負(fù)載均衡層、應(yīng)用層和持久層。接下來,我們就預(yù)估下每一層的并發(fā)量。
-
假如負(fù)載均衡層使用的是高性能的Nginx,則我們可以預(yù)估Nginx最大的并發(fā)度為:10W+,這里是以萬為單位。
-
假設(shè)應(yīng)用層我們使用的是Tomcat,而Tomcat的最大并發(fā)度可以預(yù)估為800左右,這里是以百為單位。
-
假設(shè)持久層的緩存使用的是Redis,數(shù)據(jù)庫使用的是MySQL,MySQL的最大并發(fā)度可以預(yù)估為1000左右,以千為單位。Redis的最大并發(fā)度可以預(yù)估為5W左右,以萬為單位。
所以,負(fù)載均衡層、應(yīng)用層和持久層各自的并發(fā)度是不同的,那么,為了提升系統(tǒng)的總體并發(fā)度和緩存,我們通常可以采取哪些方案呢?
(1)系統(tǒng)擴(kuò)容
系統(tǒng)擴(kuò)容包括垂直擴(kuò)容和水平擴(kuò)容,增加設(shè)備和機(jī)器配置,絕大多數(shù)的場景有效。
(2)緩存
本地緩存或者集中式緩存,減少網(wǎng)絡(luò)IO,基于內(nèi)存讀取數(shù)據(jù)。大部分場景有效。
(3)讀寫分離
采用讀寫分離,分而治之,增加機(jī)器的并行處理能力。
秒殺系統(tǒng)的特點
對于秒殺系統(tǒng)來說,我們可以從業(yè)務(wù)和技術(shù)兩個角度來闡述其自身存在的一些特點。
秒殺系統(tǒng)的業(yè)務(wù)特點
這里,我們可以使用12306網(wǎng)站來舉例,每年春運時,12306網(wǎng)站的訪問量是非常大的,但是網(wǎng)站平時的訪問量卻是比較平緩的,也就是說,每年春運時節(jié),12306網(wǎng)站的訪問量會出現(xiàn)瞬時突增的現(xiàn)象。
再比如,小米秒殺系統(tǒng),在上午10點開售商品,10點前的訪問量比較平緩,10點時同樣會出現(xiàn)并發(fā)量瞬時突增的現(xiàn)象。
所以,秒殺系統(tǒng)的流量和并發(fā)量我們可以使用下圖來表示。
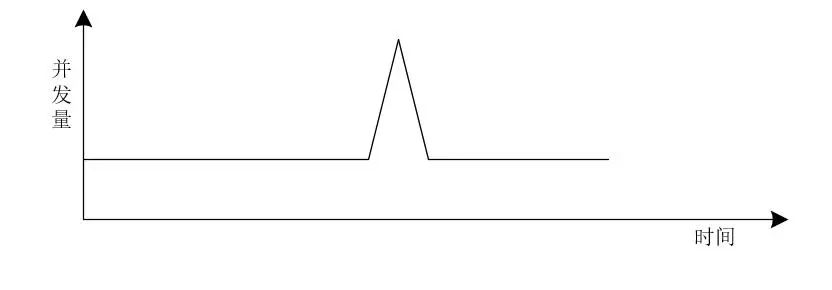
由圖可以看出,秒殺系統(tǒng)的并發(fā)量存在瞬時凸峰的特點,也叫做流量突刺現(xiàn)象。
(1)限時、限量、限價
在規(guī)定的時間內(nèi)進(jìn)行;秒殺活動中商品的數(shù)量有限;商品的價格會遠(yuǎn)遠(yuǎn)低于原來的價格,也就是說,在秒殺活動中,商品會以遠(yuǎn)遠(yuǎn)低于原來的價格出售。
例如,秒殺活動的時間僅限于某天上午10點到10點半,商品數(shù)量只有10萬件,售完為止,而且商品的價格非常低,例如:1元購等業(yè)務(wù)場景。
限時、限量和限價可以單獨存在,也可以組合存在。
(2)活動預(yù)熱
需要提前配置活動;活動還未開始時,用戶可以查看活動的相關(guān)信息;秒殺活動開始前,對活動進(jìn)行大力宣傳。
(3)持續(xù)時間短
購買的人數(shù)數(shù)量龐大;商品會迅速售完。
在系統(tǒng)流量呈現(xiàn)上,就會出現(xiàn)一個突刺現(xiàn)象,此時的并發(fā)訪問量是非常高的,大部分秒殺場景下,商品會在極短的時間內(nèi)售完。
秒殺系統(tǒng)的技術(shù)特點
我們可以將秒殺系統(tǒng)的技術(shù)特點總結(jié)如下。
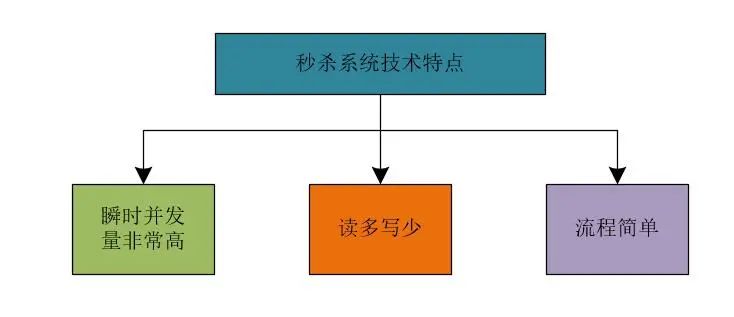
(1)瞬時并發(fā)量非常高
大量用戶會在同一時間搶購商品;瞬間并發(fā)峰值非常高。
(2)讀多寫少
系統(tǒng)中商品頁的訪問量巨大;商品的可購買數(shù)量非常少;庫存的查詢訪問數(shù)量遠(yuǎn)遠(yuǎn)大于商品的購買數(shù)量。
在商品頁中往往會加入一些限流措施,例如早期的秒殺系統(tǒng)商品頁會加入驗證碼來平滑前端對系統(tǒng)的訪問流量,近期的秒殺系統(tǒng)商品詳情頁會在用戶打開頁面時,提示用戶登錄系統(tǒng)。這都是對系統(tǒng)的訪問進(jìn)行限流的一些措施。
(3)流程簡單
秒殺系統(tǒng)的業(yè)務(wù)流程一般比較簡單;總體上來說,秒殺系統(tǒng)的業(yè)務(wù)流程可以概括為:下單減庫存。
秒殺三階段
通常,從秒殺開始到結(jié)束,往往會經(jīng)歷三個階段:
- 準(zhǔn)備階段:這個階段也叫作系統(tǒng)預(yù)熱階段,此時會提前預(yù)熱秒殺系統(tǒng)的業(yè)務(wù)數(shù)據(jù),往往這個時候,用戶會不斷刷新秒殺頁面,來查看秒殺活動是否已經(jīng)開始。在一定程度上,通過用戶不斷刷新頁面的操作,可以將一些數(shù)據(jù)存儲到Redis中進(jìn)行預(yù)熱。
- 秒殺階段:這個階段主要是秒殺活動的過程,會產(chǎn)生瞬時的高并發(fā)流量,對系統(tǒng)資源會造成巨大的沖擊,所以,在秒殺階段一定要做好系統(tǒng)防護(hù)。
- 結(jié)算階段: 完成秒殺后的數(shù)據(jù)處理工作,比如數(shù)據(jù)的一致性問題處理,異常情況處理,商品的回倉處理等。
針對這種短時間內(nèi)大流量的系統(tǒng)來說,就不太適合使用系統(tǒng)擴(kuò)容了,因為即使系統(tǒng)擴(kuò)容了,也就是在很短的時間內(nèi)會使用到擴(kuò)容后的系統(tǒng),大部分時間內(nèi),系統(tǒng)無需擴(kuò)容即可正常訪問。
那么,我們可以采取哪些方案來提升系統(tǒng)的秒殺性能呢?
秒殺系統(tǒng)方案
針對秒殺系統(tǒng)的特點,我們可以采取如下的措施來提升系統(tǒng)的性能。
(1)異步解耦
將整體流程進(jìn)行拆解,核心流程通過隊列方式進(jìn)行控制。
(2)限流防刷
控制網(wǎng)站整體流量,提高請求的門檻,避免系統(tǒng)資源耗盡。
(3)資源控制
將整體流程中的資源調(diào)度進(jìn)行控制,揚(yáng)長避短。
由于應(yīng)用層能夠承載的并發(fā)量比緩存的并發(fā)量少很多。所以,在高并發(fā)系統(tǒng)中,我們可以直接使用OpenResty由負(fù)載均衡層訪問緩存,避免了調(diào)用應(yīng)用層的性能損耗。
大家可以到https://openresty.org/cn/來了解有關(guān)OpenResty更多的知識。同時,由于秒殺系統(tǒng)中,商品數(shù)量比較少,我們也可以使用動態(tài)渲染技術(shù),CDN技術(shù)來加速網(wǎng)站的訪問性能。
如果在秒殺活動開始時,并發(fā)量太高時,我們可以將用戶的請求放入隊列中進(jìn)行處理,并為用戶彈出排隊頁面。
注:圖片來自魅族
秒殺系統(tǒng)時序圖
網(wǎng)上很多的秒殺系統(tǒng)和對秒殺系統(tǒng)的解決方案,并不是真正的秒殺系統(tǒng),他們采用的只是同步處理請求的方案,一旦并發(fā)量真的上來了,他們所謂的秒殺系統(tǒng)的性能會急劇下降。我們先來看一下秒殺系統(tǒng)在同步下單時的時序圖。
同步下單流程
1.用戶發(fā)起秒殺請求
在同步下單流程中,首先,用戶發(fā)起秒殺請求。商城服務(wù)需要依次執(zhí)行如下流程來處理秒殺請求的業(yè)務(wù)。
(1)識別驗證碼是否正確
商城服務(wù)判斷用戶發(fā)起秒殺請求時提交的驗證碼是否正確。
(2)判斷活動是否已經(jīng)結(jié)束
驗證當(dāng)前秒殺活動是否已經(jīng)結(jié)束。
(3)驗證訪問請求是否處于黑名單
在電商領(lǐng)域中,存在著很多的惡意競爭,也就是說,其他商家可能會通過不正當(dāng)手段來惡意請求秒殺系統(tǒng),占用系統(tǒng)大量的帶寬和其他系統(tǒng)資源。
此時,就需要使用風(fēng)控系統(tǒng)等實現(xiàn)黑名單機(jī)制。為了簡單,也可以使用攔截器統(tǒng)計訪問頻次實現(xiàn)黑名單機(jī)制。
(4)驗證真實庫存是否足夠
系統(tǒng)需要驗證商品的真實庫存是否足夠,是否能夠支持本次秒殺活動的商品庫存量。
(5)扣減緩存中的庫存
在秒殺業(yè)務(wù)中,往往會將商品庫存等信息存放在緩存中,此時,還需要驗證秒殺活動使用的商品庫存是否足夠,并且需要扣減秒殺活動的商品庫存數(shù)量。
(6)計算秒殺的價格
由于在秒殺活動中,商品的秒殺價格和商品的真實價格存在差異,所以,需要計算商品的秒殺價格。
注意:如果在秒殺場景中,系統(tǒng)涉及的業(yè)務(wù)更加復(fù)雜的話,會涉及更多的業(yè)務(wù)操作,這里,我只是列舉出一些常見的業(yè)務(wù)操作。
2.提交訂單
(1)訂單入口
將用戶提交的訂單信息保存到數(shù)據(jù)庫中。
(2)扣減真實庫存
訂單入庫后,需要在商品的真實庫存中將本次成功下單的商品數(shù)量扣除。
如果我們使用上述流程開發(fā)了一個秒殺系統(tǒng),當(dāng)用戶發(fā)起秒殺請求時,由于系統(tǒng)每個業(yè)務(wù)流程都是串行執(zhí)行的,整體上系統(tǒng)的性能不會太高,當(dāng)并發(fā)量太高時,我們會為用戶彈出下面的排隊頁面,來提示用戶進(jìn)行等待。
此時的排隊時間可能是15秒,也可能是30秒,甚至是更長時間。這就存在一個問題:在用戶發(fā)起秒殺請求到服務(wù)器返回結(jié)果的這段時間內(nèi),客戶端和服務(wù)器之間的連接不會被釋放,這就會占大量占用服務(wù)器的資源。
網(wǎng)上很多介紹如何實現(xiàn)秒殺系統(tǒng)的文章都是采用的這種方式,那么,這種方式能做秒殺系統(tǒng)嗎?答案是可以做,但是這種方式支撐的并發(fā)量并不是太高。
此時,有些小伙伴可能會問:我們公司就是這樣做的秒殺系統(tǒng)啊!上線后一直在用,沒啥問題啊!
我想說的是:使用同步下單方式確實可以做秒殺系統(tǒng),但是同步下單的性能不會太高。
之所以你們公司采用同步下單的方式做秒殺系統(tǒng)沒出現(xiàn)大的問題,那是因為你們的秒殺系統(tǒng)的并發(fā)量沒達(dá)到一定的量級,也就是說,你們的秒殺系統(tǒng)的并發(fā)量其實并不高。
所以,很多所謂的秒殺系統(tǒng),存在著秒殺的業(yè)務(wù),但是稱不上真正的秒殺系統(tǒng),原因就在于他們使用的是同步的下單流程,限制了系統(tǒng)的并發(fā)流量。之所以上線后沒出現(xiàn)太大的問題,是因為系統(tǒng)的并發(fā)量不高,不足以壓死整個系統(tǒng)。
如果12306、淘寶、天貓、京東、小米等大型商城的秒殺系統(tǒng)是這么玩的話,那么,他們的系統(tǒng)遲早會被玩死,他們的系統(tǒng)工程師不被開除才怪!所以,在秒殺系統(tǒng)中,這種同步處理下單的業(yè)務(wù)流程的方案是不可取的。
以上就是同步下單的整個流程操作,如果下單流程更加復(fù)雜的話,就會涉及到更多的業(yè)務(wù)操作。
異步下單流程
既然同步下單流程的秒殺系統(tǒng)稱不上真正的秒殺系統(tǒng),那我們就需要采用異步的下單流程了。異步的下單流程不會限制系統(tǒng)的高并發(fā)流量。
1.用戶發(fā)起秒殺請求
用戶發(fā)起秒殺請求后,商城服務(wù)會經(jīng)過如下業(yè)務(wù)流程。
(1)檢測驗證碼是否正確
用戶發(fā)起秒殺請求時,會將驗證碼一同發(fā)送過來,系統(tǒng)會檢驗驗證碼是否有效,并且是否正確。
(2)是否限流
系統(tǒng)會對用戶的請求進(jìn)行是否限流的判斷,這里,我們可以通過判斷消息隊列的長度來進(jìn)行判斷。因為我們將用戶的請求放在了消息隊列中,消息隊列中堆積的是用戶的請求,我們可以根據(jù)當(dāng)前消息隊列中存在的待處理的請求數(shù)量來判斷是否需要對用戶的請求進(jìn)行限流處理。
例如,在秒殺活動中,我們出售1000件商品,此時在消息隊列中存在1000個請求,如果后續(xù)仍然有用戶發(fā)起秒殺請求,則后續(xù)的請求我們可以不再處理,直接向用戶返回商品已售完的提示。
所以,使用限流后,我們可以更快的處理用戶的請求和釋放連接的資源。
(3)發(fā)送MQ
用戶的秒殺請求通過前面的驗證后,我們就可以將用戶的請求參數(shù)等信息發(fā)送到MQ中進(jìn)行異步處理,同時,向用戶響應(yīng)結(jié)果信息。在商城服務(wù)中,會有專門的異步任務(wù)處理模塊來消費消息隊列中的請求,并處理后續(xù)的異步流程。
在用戶發(fā)起秒殺請求時,異步下單流程比同步下單流程處理的業(yè)務(wù)操作更少,它將后續(xù)的操作通過MQ發(fā)送給異步處理模塊進(jìn)行處理,并迅速向用戶返回響應(yīng)結(jié)果,釋放請求連接。
2.異步處理
我們可以將下單流程的如下操作進(jìn)行異步處理。
(1)判斷活動是否已經(jīng)結(jié)束
(2)判斷本次請求是否處于系統(tǒng)黑名單,為了防止電商領(lǐng)域同行的惡意競爭可以為系統(tǒng)增加黑名單機(jī)制,將惡意的請求放入系統(tǒng)的黑名單中。可以使用攔截器統(tǒng)計訪問頻次來實現(xiàn)。
(3)扣減緩存中的秒殺商品的庫存數(shù)量。
(4)生成秒殺Token,這個Token是綁定當(dāng)前用戶和當(dāng)前秒殺活動的,只有生成了秒殺Token的請求才有資格進(jìn)行秒殺活動。
這里我們引入了異步處理機(jī)制,在異步處理中,系統(tǒng)使用多少資源,分配多少線程來處理相應(yīng)的任務(wù),是可以進(jìn)行控制的。
3.短輪詢查詢秒殺結(jié)果
這里,可以采取客戶端短輪詢查詢是否獲得秒殺資格的方案。例如,客戶端可以每隔3秒鐘輪詢請求服務(wù)器,查詢是否獲得秒殺資格,這里,我們在服務(wù)器的處理就是判斷當(dāng)前用戶是否存在秒殺Token,如果服務(wù)器為當(dāng)前用戶生成了秒殺Token,則當(dāng)前用戶存在秒殺資格。否則繼續(xù)輪詢查詢,直到超時或者服務(wù)器返回商品已售完或者無秒殺資格等信息為止。
采用短輪詢查詢秒殺結(jié)果時,在頁面上我們同樣可以提示用戶排隊處理中,但是此時客戶端會每隔幾秒輪詢服務(wù)器查詢秒殺資格的狀態(tài),相比于同步下單流程來說,無需長時間占用請求連接。
此時,可能會有網(wǎng)友會問:采用短輪詢查詢的方式,會不會存在直到超時也查詢不到是否具有秒殺資格的狀態(tài)呢?答案是:有可能!
這里我們試想一下秒殺的真實場景,商家參加秒殺活動本質(zhì)上不是為了賺錢,而是提升商品的銷量和商家的知名度,吸引更多的用戶來買自己的商品。所以,我們不必保證用戶能夠100%的查詢到是否具有秒殺資格的狀態(tài)。
4.秒殺結(jié)算
(1)驗證下單Token
客戶端提交秒殺結(jié)算時,會將秒殺Token一同提交到服務(wù)器,商城服務(wù)會驗證當(dāng)前的秒殺Token是否有效。
(2)加入秒殺購物車
商城服務(wù)在驗證秒殺Token合法并有效后,會將用戶秒殺的商品添加到秒殺購物車。
5.提交訂單
(1)訂單入庫
將用戶提交的訂單信息保存到數(shù)據(jù)庫中。
(2)刪除Token
秒殺商品訂單入庫成功后,刪除秒殺Token。
這里大家可以思考一個問題:我們?yōu)槭裁粗辉诋惒较聠瘟鞒痰姆凵糠植捎卯惒教幚恚鴽]有在其他部分采取異步削峰和填谷的措施呢?
這是因為在異步下單流程的設(shè)計中,無論是在產(chǎn)品設(shè)計上還是在接口設(shè)計上,我們在用戶發(fā)起秒殺請求階段對用戶的請求進(jìn)行了限流操作,可以說,系統(tǒng)的限流操作是非常前置的。
在用戶發(fā)起秒殺請求時進(jìn)行了限流,系統(tǒng)的高峰流量已經(jīng)被平滑解決了,再往后走,其實系統(tǒng)的并發(fā)量和系統(tǒng)流量并不是非常高了。
所以,網(wǎng)上很多的文章和帖子中在介紹秒殺系統(tǒng)時,說是在下單時使用異步削峰來進(jìn)行一些限流操作,那都是在扯淡!因為下單操作在整個秒殺系統(tǒng)的流程中屬于比較靠后的操作了,限流操作一定要前置處理,在秒殺業(yè)務(wù)后面的流程中做限流操作是沒啥卵用的。
高并發(fā)“黑科技”與致勝奇招
假設(shè),在秒殺系統(tǒng)中我們使用Redis實現(xiàn)緩存,假設(shè)Redis的讀寫并發(fā)量在5萬左右。我們的商城秒殺業(yè)務(wù)需要支持的并發(fā)量在100萬左右。
如果這100萬的并發(fā)全部打入Redis中,Redis很可能就會掛掉,那么,我們?nèi)绾谓鉀Q這個問題呢?接下來,我們就一起來探討這個問題。
在高并發(fā)的秒殺系統(tǒng)中,如果采用Redis緩存數(shù)據(jù),則Redis緩存的并發(fā)處理能力是關(guān)鍵,因為很多的前綴操作都需要訪問Redis。而異步削峰只是基本的操作,關(guān)鍵還是要保證Redis的并發(fā)處理能力。
解決這個問題的關(guān)鍵思想就是:分而治之,將商品庫存分開放。
暗度陳倉
我們在Redis中存儲秒殺商品的庫存數(shù)量時,可以將秒殺商品的庫存進(jìn)行“分割”存儲來提升Redis的讀寫并發(fā)量。
例如,原來的秒殺商品的id為10001,庫存為1000件,在Redis中的存儲為(10001, 1000),我們將原有的庫存分割為5份,則每份的庫存為200件,此時,我們在Redia中存儲的信息為(10001_0, 200),(10001_1, 200),(10001_2, 200),(10001_3, 200),(10001_4, 200)。
此時,我們將庫存進(jìn)行分割后,每個分割后的庫存使用商品id加上一個數(shù)字標(biāo)識來存儲,這樣,在對存儲商品庫存的每個Key進(jìn)行Hash運算時,得出的Hash結(jié)果是不同的,這就說明,存儲商品庫存的Key有很大概率不在Redis的同一個槽位中,這就能夠提升Redis處理請求的性能和并發(fā)量。
分割庫存后,我們還需要在Redis中存儲一份商品id和分割庫存后的Key的映射關(guān)系,此時映射關(guān)系的Key為商品的id,也就是10001,Value為分割庫存后存儲庫存信息的Key,也就是10001_0,10001_1,10001_2,10001_3,10001_4。在Redis中我們可以使用List來存儲這些值。
在真正處理庫存信息時,我們可以先從Redis中查詢出秒殺商品對應(yīng)的分割庫存后的所有Key,同時使用AtomicLong來記錄當(dāng)前的請求數(shù)量,使用請求數(shù)量對從Redia中查詢出的秒殺商品對應(yīng)的分割庫存后的所有Key的長度進(jìn)行求模運算,得出的結(jié)果為0,1,2,3,4。再在前面拼接上商品id就可以得出真正的庫存緩存的Key。此時,就可以根據(jù)這個Key直接到Redis中獲取相應(yīng)的庫存信息。
移花接木
在高并發(fā)業(yè)務(wù)場景中,我們可以直接使用Lua腳本庫(OpenResty)從負(fù)載均衡層直接訪問緩存。
這里,我們思考一個場景:如果在秒殺業(yè)務(wù)場景中,秒殺的商品被瞬間搶購一空。此時,用戶再發(fā)起秒殺請求時,如果系統(tǒng)由負(fù)載均衡層請求應(yīng)用層的各個服務(wù),再由應(yīng)用層的各個服務(wù)訪問緩存和數(shù)據(jù)庫,其實,本質(zhì)上已經(jīng)沒有任何意義了,因為商品已經(jīng)賣完了,再通過系統(tǒng)的應(yīng)用層進(jìn)行層層校驗已經(jīng)沒有太多意義了!!而應(yīng)用層的并發(fā)訪問量是以百為單位的,這又在一定程度上會降低系統(tǒng)的并發(fā)度。
為了解決這個問題,此時,我們可以在系統(tǒng)的負(fù)載均衡層取出用戶發(fā)送請求時攜帶的用戶id,商品id和秒殺活動id等信息,直接通過Lua腳本等技術(shù)來訪問緩存中的庫存信息。如果秒殺商品的庫存小于或者等于0,則直接返回用戶商品已售完的提示信息,而不用再經(jīng)過應(yīng)用層的層層校驗了。 針對這個架構(gòu),我們可以參見本文中的電商系統(tǒng)的架構(gòu)圖(正文開始的第一張圖)。
Redis助力秒殺系統(tǒng)
我們可以在Redis中設(shè)計一個Hash數(shù)據(jù)結(jié)構(gòu),來支持商品庫存的扣減操作,如下所示。
seckill${goodsId}{
totalCount:200,
initStatus:0,
seckillCount:0
}
在我們設(shè)計的Hash數(shù)據(jù)結(jié)構(gòu)中,有三個非常主要的屬性。
- totalCount:表示參與秒殺的商品的總數(shù)量,在秒殺活動開始前,我們就需要提前將此值加載到Redis緩存中。
- initStatus:我們把這個值設(shè)計成一個布爾值。秒殺開始前,這個值為0,表示秒殺未開始。可以通過定時任務(wù)或者后臺操作,將此值修改為1,則表示秒殺開始。
- seckillCount:表示秒殺的商品數(shù)量,在秒殺過程中,此值的上限為totalCount,當(dāng)此值達(dá)到totalCount時,表示商品已經(jīng)秒殺完畢。
我們可以通過下面的代碼片段在秒殺預(yù)熱階段,將要參與秒殺的商品數(shù)據(jù)加載的緩存。
/**
*@authorbinghe
*@description秒殺前構(gòu)建商品緩存代碼示例
*/
publicclassSeckillCacheBuilder{
privatestaticfinalStringGOODS_CACHE="seckill";
privateStringgetCacheKey(Stringid){
returnGOODS_CACHE.concat(id);
}
publicvoidprepare(Stringid,inttotalCount){
Stringkey=getCacheKey(id);
Mapgoods=newHashMap<>();
goods.put("totalCount",totalCount);
goods.put("initStatus",0);
goods.put("seckillCount",0);
redisTemplate.opsForHash().putAll(key,goods);
}
}
秒殺開始的時候,我們需要在代碼中首先判斷緩存中的seckillCount值是否小于totalCount值,如果seckillCount值確實小于totalCount值,我們才能夠?qū)齑孢M(jìn)行鎖定。在我們的程序中,這兩步其實并不是原子性的。如果在分布式環(huán)境中,我們通過多臺機(jī)器同時操作Redis緩存,就會發(fā)生同步問題,進(jìn)而引起“超賣”的嚴(yán)重后果。
在電商領(lǐng)域,有一個專業(yè)名詞叫作“超賣”。顧名思義:“超賣”就是說賣出的商品數(shù)量比商品的庫存數(shù)量多,這在電商領(lǐng)域是一個非常嚴(yán)重的問題。那么,我們?nèi)绾谓鉀Q“超賣”問題呢?
Lua腳本完美解決超賣問題
我們?nèi)绾谓鉀Q多臺機(jī)器同時操作Redis出現(xiàn)的同步問題呢?一個比較好的方案就是使用Lua腳本。我們可以使用Lua腳本將Redis中扣減庫存的操作封裝成一個原子操作,這樣就能夠保證操作的原子性,從而解決高并發(fā)環(huán)境下的同步問題。
例如,我們可以編寫如下的Lua腳本代碼,來執(zhí)行Redis中的庫存扣減操作。
localresultFlag="0"
localn=tonumber(ARGV[1])
localkey=KEYS[1]
localgoodsInfo=redis.call("HMGET",key,"totalCount","seckillCount")
localtotal=tonumber(goodsInfo[1])
localalloc=tonumber(goodsInfo[2])
ifnottotalthen
returnresultFlag
end
iftotal>=alloc+nthen
localret=redis.call("HINCRBY",key,"seckillCount",n)
returntostring(ret)
end
returnresultFlag
我們可以使用如下的Java代碼來調(diào)用上述Lua腳本。
publicintsecKill(Stringid,intnumber){
Stringkey=getCacheKey(id);
ObjectseckillCount=redisTemplate.execute(script,Arrays.asList(key),String.valueOf(number));
returnInteger.valueOf(seckillCount.toString());
}
這樣,我們在執(zhí)行秒殺活動時,就能夠保證操作的原子性,從而有效的避免數(shù)據(jù)的同步問題,進(jìn)而有效的解決了“超賣”問題。
為了應(yīng)對秒殺系統(tǒng)高并發(fā)大流量的業(yè)務(wù)場景,除了秒殺系統(tǒng)本身的業(yè)務(wù)架構(gòu)外,我們還要進(jìn)一步優(yōu)化服務(wù)器硬件的性能,接下來,我們就一起來看一下如何優(yōu)化服務(wù)器的性能。
優(yōu)化服務(wù)器性能
操作系統(tǒng)
這里,我使用的操作系統(tǒng)為CentOS 8,我們可以輸入如下命令來查看操作系統(tǒng)的版本。
CentOSLinuxrelease8.0.1905(Core)
對于高并發(fā)的場景,我們主要還是優(yōu)化操作系統(tǒng)的網(wǎng)絡(luò)性能,而操作系統(tǒng)中,有很多關(guān)于網(wǎng)絡(luò)協(xié)議的參數(shù),我們對于服務(wù)器網(wǎng)絡(luò)性能的優(yōu)化,主要是對這些系統(tǒng)參數(shù)進(jìn)行調(diào)優(yōu),以達(dá)到提升我們應(yīng)用訪問性能的目的。
系統(tǒng)參數(shù)
在CentOS 操作系統(tǒng)中,我們可以通過如下命令來查看所有的系統(tǒng)參數(shù)。
/sbin/sysctl-a
部分輸出結(jié)果如下所示。
這里的參數(shù)太多了,大概有一千多個,在高并發(fā)場景下,我們不可能對操作系統(tǒng)的所有參數(shù)進(jìn)行調(diào)優(yōu)。我們更多的是關(guān)注與網(wǎng)絡(luò)相關(guān)的參數(shù)。如果想獲得與網(wǎng)絡(luò)相關(guān)的參數(shù),那么,我們首先需要獲取操作系統(tǒng)參數(shù)的類型,如下命令可以獲取操作系統(tǒng)參數(shù)的類型。
/sbin/sysctl-a|awk-F"."'{print$1}'|sort-k1|uniq
運行命令輸出的結(jié)果信息如下所示。
abi
crypto
debug
dev
fs
kernel
net
sunrpc
user
vm
其中的net類型就是我們要關(guān)注的與網(wǎng)絡(luò)相關(guān)的操作系統(tǒng)參數(shù)。我們可以獲取net類型下的子類型,如下所示。
/sbin/sysctl-a|grep"^net."|awk-F"[.|]"'{print$2}'|sort-k1|uniq
輸出的結(jié)果信息如下所示。
bridge
core
ipv4
ipv6
netfilter
nf_conntrack_max
unix
在Linux操作系統(tǒng)中,這些與網(wǎng)絡(luò)相關(guān)的參數(shù)都可以在/etc/sysctl.conf 文件里修改,如果/etc/sysctl.conf 文件中不存在這些參數(shù),我們可以自行在/etc/sysctl.conf 文件中添加這些參數(shù)。
在net類型的子類型中,我們需要重點關(guān)注的子類型有:core和ipv4。
優(yōu)化套接字緩沖區(qū)
如果服務(wù)器的網(wǎng)絡(luò)套接字緩沖區(qū)太小,就會導(dǎo)致應(yīng)用程序讀寫多次才能將數(shù)據(jù)處理完,這會大大影響我們程序的性能。如果網(wǎng)絡(luò)套接字緩沖區(qū)設(shè)置的足夠大,從一定程度上能夠提升我們程序的性能。
我們可以在服務(wù)器的命令行輸入如下命令,來獲取有關(guān)服務(wù)器套接字緩沖區(qū)的信息。
/sbin/sysctl-a|grep"^net."|grep"[r|w|_]mem[_|]"
輸出的結(jié)果信息如下所示。
net.core.rmem_default=212992
net.core.rmem_max=212992
net.core.wmem_default=212992
net.core.wmem_max=212992
net.ipv4.tcp_mem=435455806287090
net.ipv4.tcp_rmem=4096873806291456
net.ipv4.tcp_wmem=4096163844194304
net.ipv4.udp_mem=87093116125174186
net.ipv4.udp_rmem_min=4096
net.ipv4.udp_wmem_min=4096
其中,帶有max、default、min關(guān)鍵字的為分別代表:最大值、默認(rèn)值和最小值;帶有mem、rmem、wmem關(guān)鍵字的分別為:總內(nèi)存、接收緩沖區(qū)內(nèi)存、發(fā)送緩沖區(qū)內(nèi)存。
這里需要注意的是:帶有rmem 和 wmem關(guān)鍵字的單位都是“字節(jié)”,而帶有mem關(guān)鍵字的單位是“頁”。“頁”是操作系統(tǒng)管理內(nèi)存的最小單位,在 Linux 系統(tǒng)里,默認(rèn)一頁是 4KB 大小。
如何優(yōu)化頻繁收發(fā)大文件
如果在高并發(fā)場景下,需要頻繁的收發(fā)大文件,我們該如何優(yōu)化服務(wù)器的性能呢?
這里,我們可以修改的系統(tǒng)參數(shù)如下所示。
net.core.rmem_default
net.core.rmem_max
net.core.wmem_default
net.core.wmem_max
net.ipv4.tcp_mem
net.ipv4.tcp_rmem
net.ipv4.tcp_wmem
這里,我們做個假設(shè),假設(shè)系統(tǒng)最大可以給TCP分配 2GB 內(nèi)存,最小值為 256MB,壓力值為 1.5GB。按照一頁為 4KB 來計算, tcp_mem 的最小值、壓力值、最大值分別是 65536、393216、524288,單位是“頁” 。
假如平均每個文件數(shù)據(jù)包為 512KB,每個套接字讀寫緩沖區(qū)最小可以各容納 2 個數(shù)據(jù)包,默認(rèn)可以各容納 4 個數(shù)據(jù)包,最大可以各容納 10 個數(shù)據(jù)包,那我們可以算出 tcp_rmem 和 tcp_wmem 的最小值、默認(rèn)值、最大值分別是 1048576、2097152、5242880,單位是“字節(jié)”。而 rmem_default 和 wmem_default 是 2097152,rmem_max 和 wmem_max 是 5242880。
注:后面詳細(xì)介紹這些數(shù)值是如何計算的~~
這里,還需要注意的是:緩沖區(qū)超過了 65535,還需要將 net.ipv4.tcp_window_scaling 參數(shù)設(shè)置為 1。
經(jīng)過上面的分析后,我們最終得出的系統(tǒng)調(diào)優(yōu)參數(shù)如下所示。
net.core.rmem_default=2097152
net.core.rmem_max=5242880
net.core.wmem_default=2097152
net.core.wmem_max=5242880
net.ipv4.tcp_mem=65536393216524288
net.ipv4.tcp_rmem=104857620971525242880
net.ipv4.tcp_wmem=104857620971525242880
優(yōu)化TCP連接
對計算機(jī)網(wǎng)絡(luò)有一定了解的小伙伴都知道,TCP的連接需要經(jīng)過“三次握手”和“四次揮手”的,還要經(jīng)過慢啟動、滑動窗口、粘包算法等支持可靠性傳輸?shù)囊幌盗屑夹g(shù)支持。雖然,這些能夠保證TCP協(xié)議的可靠性,但有時這會影響我們程序的性能。
那么,在高并發(fā)場景下,我們該如何優(yōu)化TCP連接呢?
(1)關(guān)閉粘包算法
如果用戶對于請求的耗時很敏感,我們就需要在TCP套接字上添加tcp_nodelay參數(shù)來關(guān)閉粘包算法,以便數(shù)據(jù)包能夠立刻發(fā)送出去。此時,我們也可以設(shè)置net.ipv4.tcp_syncookies的參數(shù)值為1。
(2)避免頻繁的創(chuàng)建和回收連接資源
網(wǎng)絡(luò)連接的創(chuàng)建和回收是非常消耗性能的,我們可以通過關(guān)閉空閑的連接、重復(fù)利用已經(jīng)分配的連接資源來優(yōu)化服務(wù)器的性能。重復(fù)利用已經(jīng)分配的連接資源大家其實并不陌生,像:線程池、數(shù)據(jù)庫連接池就是復(fù)用了線程和數(shù)據(jù)庫連接。
我們可以通過如下參數(shù)來關(guān)閉服務(wù)器的空閑連接和復(fù)用已分配的連接資源。
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_tw_recycle=1
net.ipv4.tcp_fin_timeout=30
net.ipv4.tcp_keepalive_time=1800
(3)避免重復(fù)發(fā)送數(shù)據(jù)包
TCP支持超時重傳機(jī)制。如果發(fā)送方將數(shù)據(jù)包已經(jīng)發(fā)送給接收方,但發(fā)送方并未收到反饋,此時,如果達(dá)到設(shè)置的時間間隔,就會觸發(fā)TCP的超時重傳機(jī)制。為了避免發(fā)送成功的數(shù)據(jù)包再次發(fā)送,我們需要將服務(wù)器的net.ipv4.tcp_sack參數(shù)設(shè)置為1。
(4)增大服務(wù)器文件描述符數(shù)量
在Linux操作系統(tǒng)中,一個網(wǎng)絡(luò)連接也會占用一個文件描述符,連接越多,占用的文件描述符也就越多。如果文件描述符設(shè)置的比較小,也會影響我們服務(wù)器的性能。此時,我們就需要增大服務(wù)器文件描述符的數(shù)量。
例如:fs.file-max = 10240000,表示服務(wù)器最多可以打開10240000個文件。
責(zé)任編輯:haq
-
嵌入式系統(tǒng)
+關(guān)注
關(guān)注
41文章
3587瀏覽量
129436 -
架構(gòu)
+關(guān)注
關(guān)注
1文章
513瀏覽量
25468
原文標(biāo)題:萬字詳解秒殺系統(tǒng)!!
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
【書籍評測活動NO.53】鴻蒙操作系統(tǒng)設(shè)計原理與架構(gòu)
一致性測試系統(tǒng)的技術(shù)原理和也應(yīng)用場景
信令測試儀器的技術(shù)原理和應(yīng)用場景
測試聊并發(fā)-入門篇

【「嵌入式Hypervisor:架構(gòu)、原理與應(yīng)用」閱讀體驗】+ Hypervisor應(yīng)用場景調(diào)研
重塑定位邊界:革新 UWB 信標(biāo)定位系統(tǒng)測試套件,精準(zhǔn)并發(fā)融合引領(lǐng)未來

高并發(fā)物聯(lián)網(wǎng)云平臺是什么
高并發(fā)系統(tǒng)的藝術(shù):如何在流量洪峰中游刃有余
FPGA與MCU的應(yīng)用場景
讀寫分離解決什么問題
鴻蒙原生應(yīng)用開發(fā)-ArkTS語言基礎(chǔ)類庫多線程并發(fā)概述
鴻蒙原生應(yīng)用開發(fā)-ArkTS語言基礎(chǔ)類庫多線程并發(fā)概述
華為云網(wǎng)站高可用解決方案引爆華為云開年采購季:助力多場景下業(yè)務(wù)高可用、數(shù)據(jù)高可靠
現(xiàn)代典型工程裝備動力傳動系統(tǒng)故障模擬及測試平臺的應(yīng)用場景





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論