 單片機RAM真的像你想的那么“單純”嗎
單片機RAM真的像你想的那么“單純”嗎
當我們寫代碼的時候,會用到很多變量,如果隨意的定義變量,比如寫了N多個“unsigned char/int X;”那么代碼可能會顯的很亂,自己拐回頭看的時候都暈掉了,那么這個時候我們可以構造一個復雜的數據類型-結構體類型,對代碼中出現的變量進行類別的劃分,用構造的結構體類型定義結構體變量,在寫or看代碼的時候,只要看到這個結構體,就能大致的知道其實現功能,這樣看起來就神清氣爽了,可讀性大大提高。
我們定義的結構體變量,如果沒有特殊規定的話是存儲在RAM中的,單片機的RAM資源是有限的,那這個結構體變量在RAM中占的空間大小就是我們需要關注一個問題了,它真的像你想的那么“單純”嗎?接下來我們一起來看看吧!
在看下面的圖之前,我們說一個前提,在STM32單片機這個32位系統中,signed/unsigned int 占4個字節,signed/unsigned short int 占2個字節 signed/unsigned char 占1個字節,我們稱這些為基本數據類型。Size = Sizeof(Test);這個函數是求取這個結構體變量Test所占內存的大小,并返回給Size。
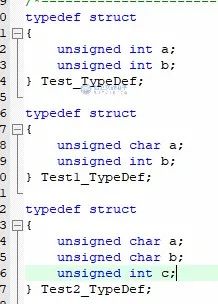
圖1
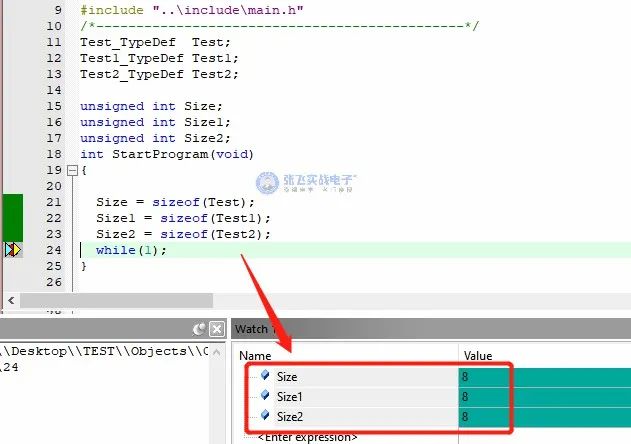
圖2
請看上圖,我們使用基本數據類型構造了3個復雜的結構體數據類型,仔細看會發現,這3個數據類型的成員可是不大一樣的,我們來看第一個Test,這個數據類型總共占4+4=8個字節,這個很好理解,那第二個Test1,占空間大小按道理來說應該是1+4 = 5個字節,但是為什么還是8呢,第三個Test2,占空間大小應該是1+1+4=8,為什么還是8呢?
這個里面就涉及到了結構體對齊,所有的成員在分配內存時都要與所有成員中占內存最多的基本數據類型所占內存空間的字節數對齊。假如這個字節數為N,那么對齊的原則是:理論上所有成員在分配內存時都是緊接在前一個變量后面依次填充的,但是如果是“以 N 對齊”為原則,那么,如果一行中剩下的空間不足以填充某成員變量時,即剩下的空間小于某成員變量的數據類型所占的字節數,該成員變量在分配內存時另起一行分配。如圖3,4:
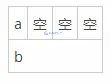
圖3

圖4
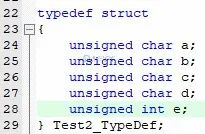
圖5
通過上面的實際測試,我們得出,在構造結構體復雜數據類型的時候,成員變量的排放一定要注意順序,遵守排放原則,否則就會白白浪費你的空間,掌握好排放原理,能大大提高你的空間利用率。比如我們構造如圖5的結構體類型,它依然還是占8個字節。
文末再給大家出個問題,大家看看下面我們構造的數據類型,它們分別占的空間是多大呢?
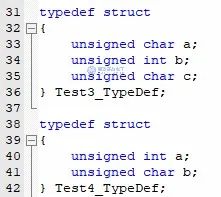
圖6
責任編輯:haq
-
單片機
+關注
關注
6037文章
44566瀏覽量
636025 -
RAM
+關注
關注
8文章
1369瀏覽量
114757 -
代碼
+關注
關注
30文章
4793瀏覽量
68701
原文標題:別再說你的單片機RAM不夠用了,來看看這個吧...
文章出處:【微信號:mcu168,微信公眾號:硬件攻城獅】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
51單片機的主要邏輯功能部件是什么
單片機的中斷機制
十天學會單片機可能嗎?單片機入門需要多久?

單片機燒錄程序的線比單片機上的少還能燒錄嗎

電器設備為何普遍采用單片機?
數字電路仿真軟件單片機怎么用
單片機開發好學嗎?學習中有哪些樂趣與挑戰?
如何系統、科學地自學單片機?
單片機是什么?單片機編程如何入門?





 工商網監
工商網監
評論