 Graphcore發布最新IPU:世界首款采用臺積電3D Wafer-on-Wafer的處理器
Graphcore發布最新IPU:世界首款采用臺積電3D Wafer-on-Wafer的處理器
電子發燒友網報道(文/李彎彎)3月3日,Graphcore發布最新一代IPU,性能比上一代提升40%,電源效率提升16%,這是全球首款基于臺積電3D Wafer-on-Wafer的處理器。從上一代IPU到新的IPU,開發者無需修改代碼,價格保持不變,現在已經上市。

世界首顆基于臺積電3D Wafer-on-Wafer的處理器
Graphcore大中華區總裁兼全球首席營收官盧濤向媒體介紹,新一代IPU名叫Bow IPU,是一個3D封裝的芯片,單個封裝中有超過600億個晶體管,具有350 TeraFLOPS的人工智能計算的性能,上一代MK2 IPU是250 TeraFLOPS。

Bow IPU在供電方面也做了很多優化,片內存儲保持了0.9 GB的容量,但吞吐量從47.5TB/s提高到65TB/s。
處理器內核個數、獨立線程個數等等,包括外部的一些接口,Bow IPU跟上一代處理器相比都沒有變化。相比上一代,Bow IPU變化主要體現在它是一個3D封裝的處理器,晶體管的規模有所增加,以及算力和吞吐量有所提升。
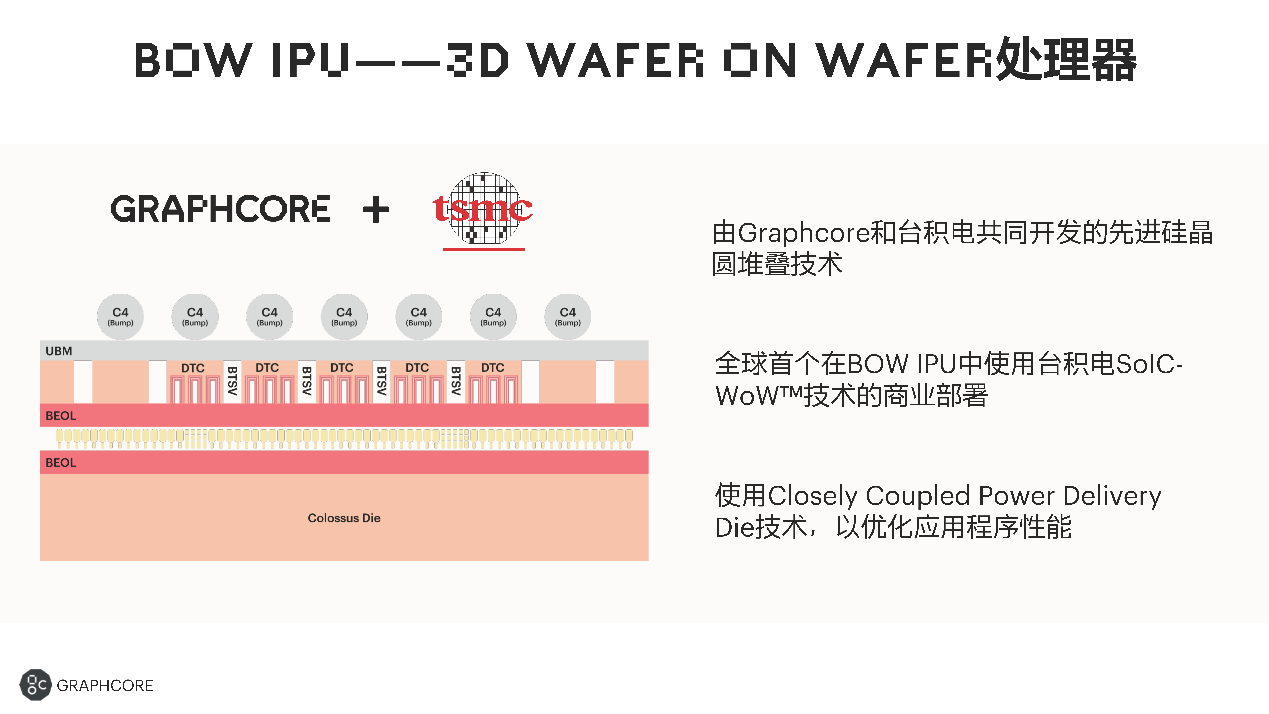
Bow IPU由2顆裸片疊在一起構成,使用了臺積電的SoIC-WoW技術。一個IPU的裸片在下面,另一個裸片在上面。上面的裸片為供電、節能等功能提供幫助。
盧濤表示,跟之前的處理器相比,這個設計使得新產品在實際運算算力提高的情況下,能效方面也有所提升。
從某種意義來說,這是Graphcore跟臺積電一起聯合創新的結果。
基于Bow IPU的Bow系統性能大幅提升
除了BowIPU,Graphcore同時發布了基于Bow IPU的Bow系統,包括Bow Pod16、Bow Pod32、Bow Pod64、Bow Pod256,以及Bow Pod1024。以Bow Pod16為例,Bow Pod16中包括4臺1U的Bow-2000,還包括1臺CPU服務器,能提供5.6 PetaFLOPS算力。

以Bow Pod16縱向擴展的Bow Pod32、Bow Pod64分別包括8臺Bow-2000、16臺Bow-2000。基于Bow Pod64可以再橫向擴展到Bow Pod256、Bow Pod1024等。Bow Pod1024包括256臺Bow-2000,可以提供358.4 PetaFLOPS的人工智能計算。目前,除了Bow Pod1024在早期訪問階段外,Bow Pod16、Bow Pod32、Bow Pod64、Bow Pod256均已量產。

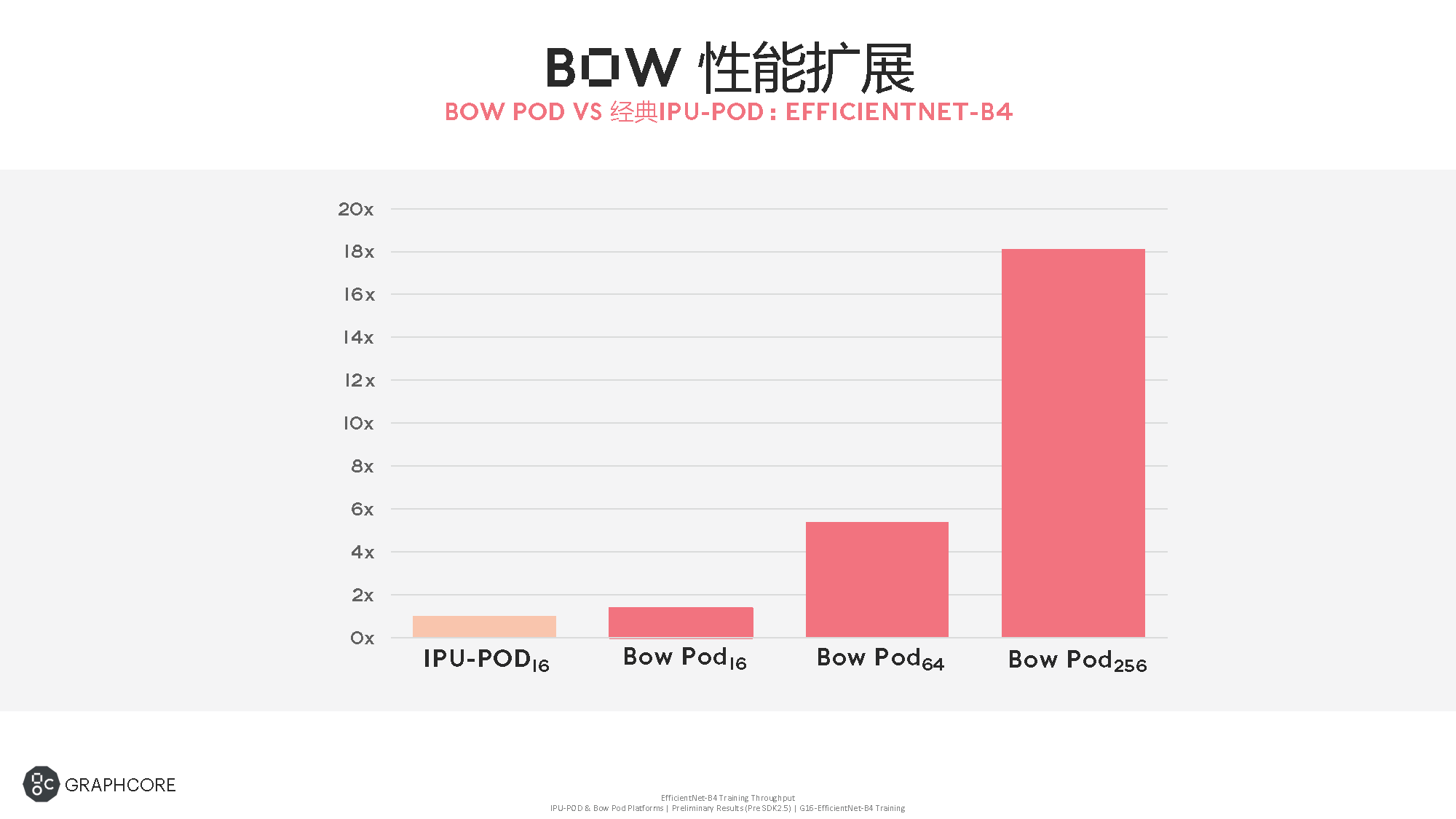
性能擴展方面,以IPU-POD16的性能作為基準,Bow Pod16的性能可以提升1.4倍,Bow Pod256可以提升18倍。
盧濤介紹,Bow-2000 IPUMachine使用了4顆Bow IPU。此前,在這樣一個1U刀片里,Graphcore提供了1 PetaFLOPS的算力,現在Graphcore提供了1.4 PetaFLOPS的算力。Bow-2000具有3.6 GB處理器內存儲,吞吐量為260TB/s,IPU流存儲多達256 GB,IPU-Fabric為2.8 Tbps。
100%軟件兼容,開箱即用無需更改代碼

盧濤強調,新一代產品跟前一代產品百分之百軟件兼容,基本上能做到開箱即用。用戶得到性能提升的同時不需要修改代碼,不僅是應用軟件,包括底層軟件、驅動等都不需要做任何修改,可以無縫集成到正在不斷變得更加廣泛的IPU軟件合作伙伴生態中。
這一點特別關鍵。很多產品在從一代往另一代演進的時候,在實現性能提升的同時,還需要很多的軟件適配工作。而100%的軟件兼容,意味著已經使用Graphcore上一代IPU的用戶在未來購置新的Bow IPU后,不需要做任何軟件適配工作就能獲得性能提升。
提供完整軟件棧生態系統
Graphcore中國工程副總裁、AI算法科學家金琛對媒體表示,上述的這些性能提升,除了硬件新架構外,也要歸功于Graphcore的軟件棧和生態系統,其中的核心部分就是Poplar SDK。
金琛表示,Poplar SDK包括driver,上層XLA的backend,以及Graphcore自研的PopART等,這些軟件的加持使得Graphcore能夠實現在不同應用的性能上的廣泛和通用的提升。
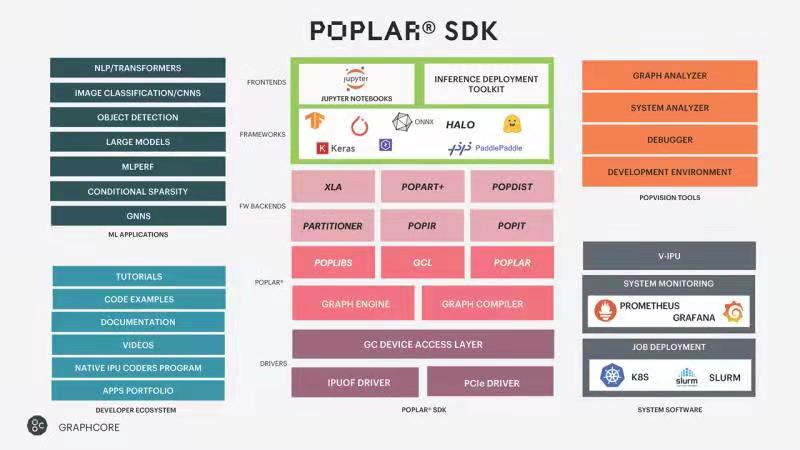
除此之外,Graphcore還提供比較豐富的生態。比如AI軟件框架,支持PyTorch、TensorFlow、HALO、PaddlePaddle,以及Keras等。在用戶方面,支持Jupyter NoteBook,以及Inference Deployment Toolkit等,幫助客戶實現推算一體的部署。
在開發者社區方面,Graphcore提供廣泛的代碼用例,以及各種文檔、視頻的示范。Graphcore在機器學習應用上提供了特別多模型范例,覆蓋了不同的AI垂直領域,如圖像識別、物體檢測,語音模型、語言模型等,這個模型庫還在不停迭代和增加。
在云上,Graphcore也提供了廣泛的部署。此外,Graphcore的PopVision工具可以幫助用戶和Poplar編程者更有效地提升應用在Graphcore的平臺上的性能優化。
提供10倍的總體擁有成本優勢
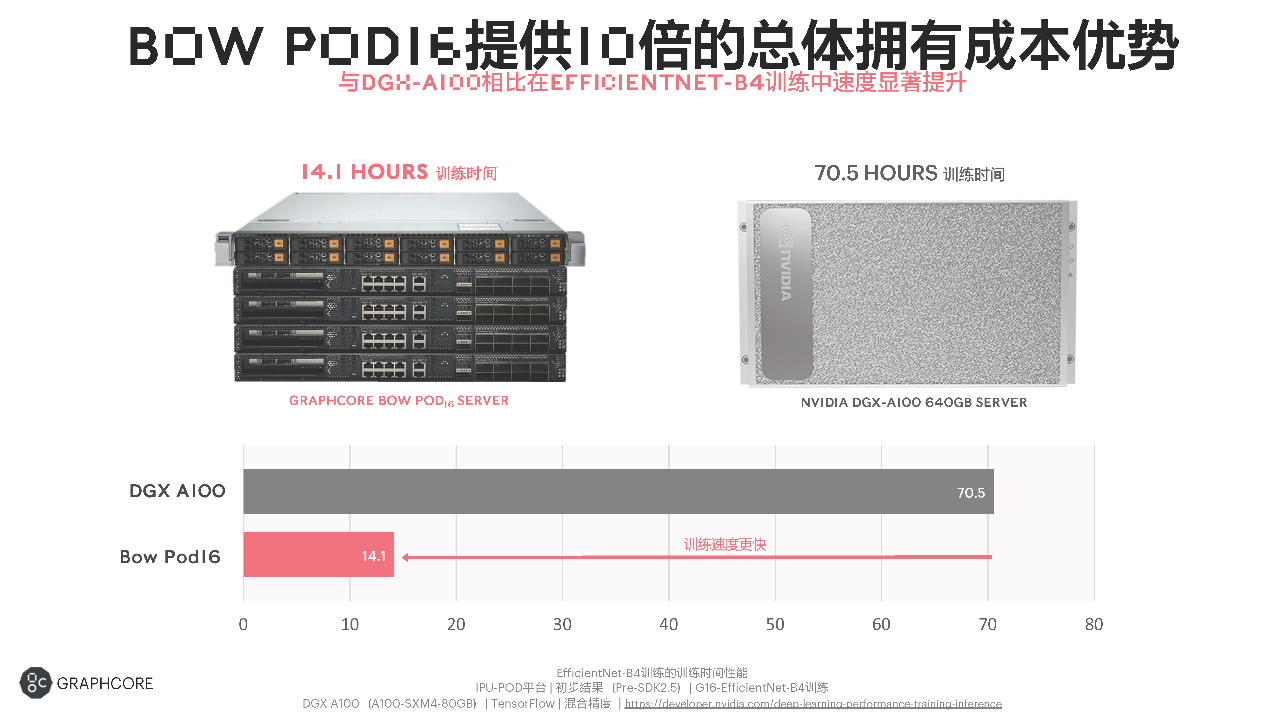
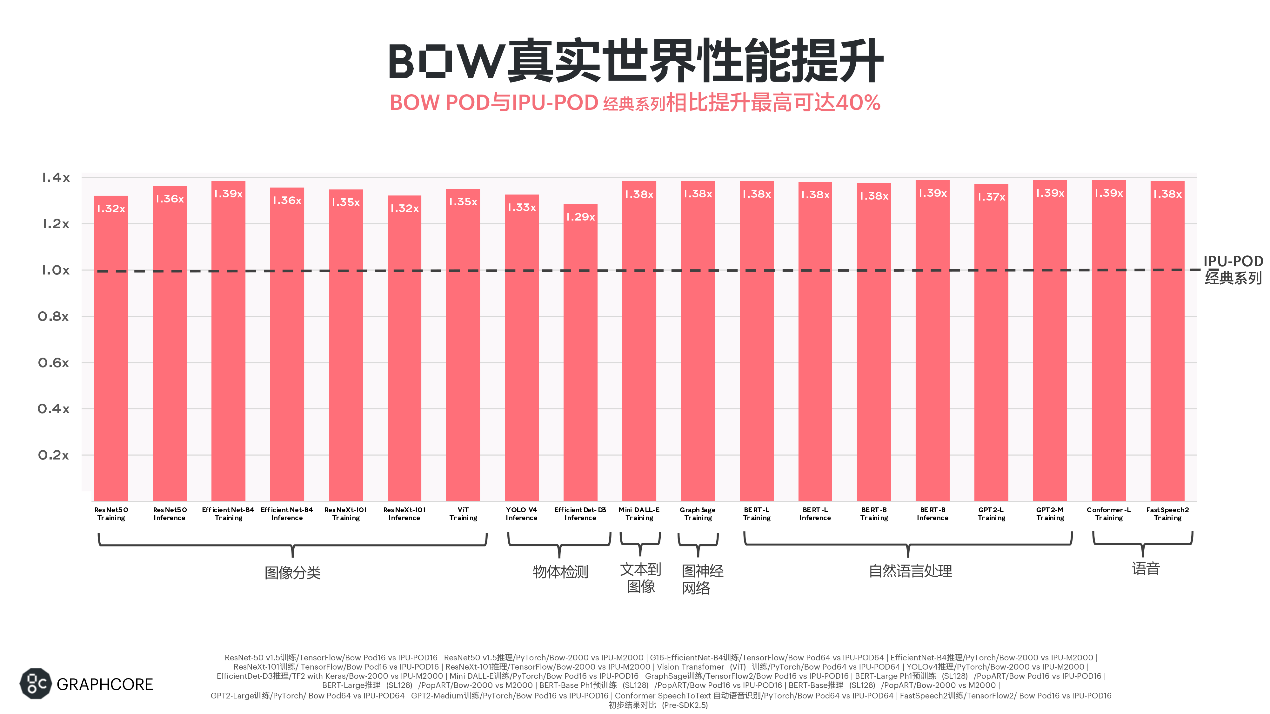
Graphcore不僅提供高效的性能,在性價比上也有比較顯著的優勢。比如,上圖左邊是Bow Pod的一個形態,右邊是DGX-A100的一個形態。可以看到,在DGX-A100上需要70個小時的訓練時間,在Bow Pod16上,EfficientNet-B4的backbone的訓練只需要14個小時左右,基本快了5倍,性價比又有優勢,總體擁有成本(TCO)的增益可以達到接近10倍左右。
Graphcore未來還要做什么?

人的大腦大概有860億個神經元,100萬億個突觸,這個突觸相當于人工智能里面模型的參數個數。也就是說,最大的人工智能模型的參數跟真正的人的大腦比較起來,還有100倍左右的差距。
盧濤談到,目前Graphcore正在開發一款可以用來超越人腦處理的超級智能機器——Good Computer,即古德計算機。這個命名有兩層含義,一層是好的計算機,希望計算機能夠帶來正面的影響,另外也是向前輩致敬——JackGood是一位非常知名的計算機科學家。

Good Computer大概能夠達到8192個未來的IPU,提供超過10 Exa-Flops的AI算力,未來也許會繼續向3D Wafer-on-Wafer演進,可以實現4 PB的存儲,可以助力超過500萬億參數規模的人工智能模型的開發,Poplar SDK完全支持。
預計價格取決于不同的配置,大概在100萬美元到1.5億美元的規模。盧濤表示,從Bow IPU往前展望,這是Graphcore正在做的一個產品。
-
臺積電
+關注
關注
44文章
5632瀏覽量
166418 -
IPU
+關注
關注
0文章
34瀏覽量
15557
發布評論請先 登錄
相關推薦
臺積電CoWoS封裝A1技術介紹
Monitor Wafer的核心功能、特點、生產流程和應用
WAFER連接器在現代電子領域的多樣化應用
WAFER線對板連接器的特點與應用分析






 工商網監
工商網監
評論