 對比學習的關鍵技術和基本應用分析
對比學習的關鍵技術和基本應用分析
對比學習可以應用于監督和無監督的場景下,目前在CV、NLP等領域中取得了較好的性能。本文對對比學習進行基礎介紹,以及其在NLP和多模態中的應用。
引言
對比學習的主要思想是相似的樣本的表示相近,而不相似的遠離。對比學習可以應用于監督和無監督的場景下,并且目前在CV、NLP等領域中取得了較好的性能。本文先對對比學習進行基礎介紹,之后會介紹對比學習在NLP和多模態中的應用,歡迎大家批評和交流。
對比學習基礎介紹
損失函數
1. NCE[1](Noise-contrastive estimation):是估計統計模型的參數的一種方法,主要通過學習數據分布和噪聲分布之間的區別。下面給出NCE的原始形式,它包含一個正負樣本對。在之后的許多研究工作中,包含多個正樣本或負樣本也被廣義的稱為NCE。下式中x表示數據,y為噪聲。
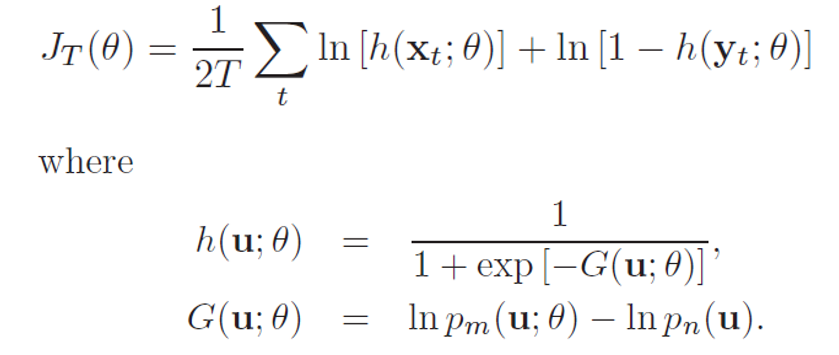
2. InfoNCE[2]:在CPC中提出,使用分類交叉熵損失在一組負樣本中識別正樣本。原論文給出的式子如下:
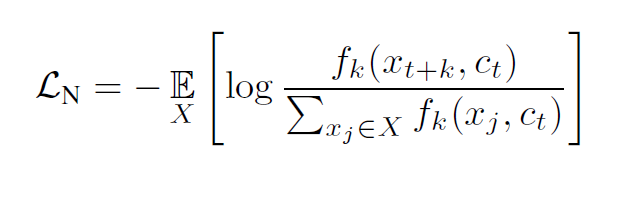
3. Triplet Loss:三元組損失,最初是由谷歌在FaceNet[3]中提出,主要用于識別在不同角度和姿勢下的人臉。下式中加號在右下角表示max(x,0)。

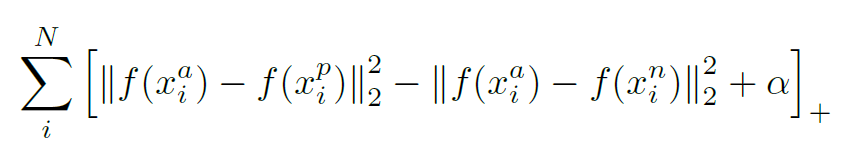
4. N-pair Loss[4]:Multi-Class N-pair loss,是將Triplet Loss泛化到與多個負樣本進行對比。
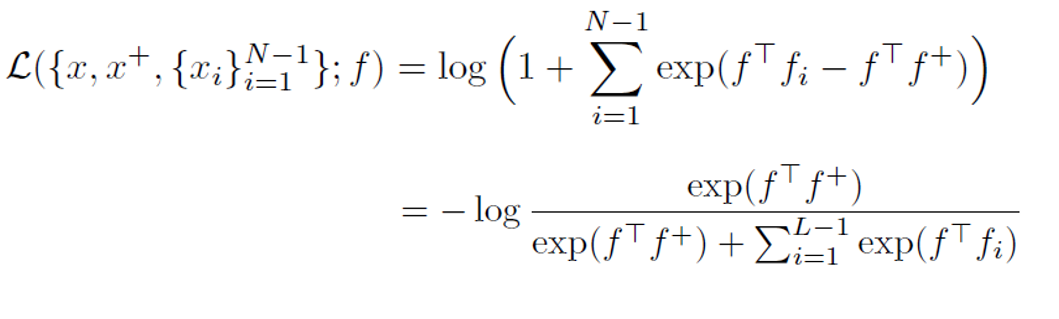
衡量標準
衡量指標由(Wang & Isola, 2020)[5]提出,文中說明了對比學習算法具有兩個關鍵屬性alignment和uniformity,很多有效的對比學習算法正是較好地滿足了這兩種性質。
alignment:衡量正例樣本間的近似程度
uniformity:衡量特征向量在超球體上的分布的均勻性
文章同時給出了衡量兩種性質的評價指標,并同時指出優化這兩個指標會在下游任務上表現更好。
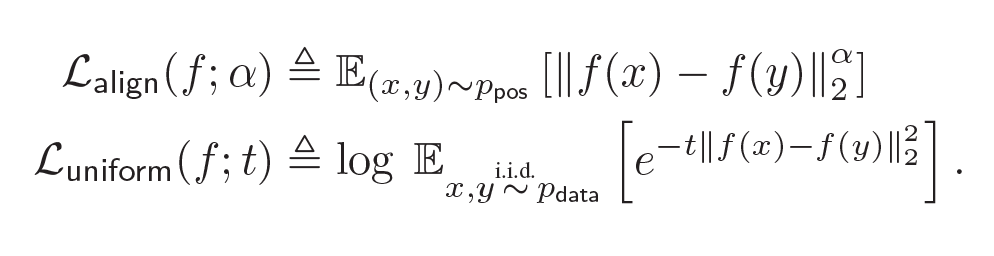
關鍵技術
1. 正負樣本的構造
數據增強:給定訓練數據,需要進行數據增強來得到更多正樣本。正確有效的數據增強技術對于學習好的表征至關重要。比如SimCLR[6]的實驗表明,圖片的隨機裁剪和顏色失真是最有效的兩種方式。而對于句子來說,刪除或替換可能會導致語義的改變。
負樣本構造:一般對比學習中使用in-batch negatives,將一個batch內的不相關數據看作負樣本。
多個模態:正樣本對可以是兩種模態的數據,比如圖片和圖片對應描述。
2. 大的batch size
在訓練期間使用大的batch size是許多對比學習方法成功的一個關鍵因素。當batch size足夠大時,能夠提供大量的負樣本,使得模型學習更好表征來區別不同樣本。
對比學習在NLP領域的應用
A Simple but Tough-to-Beat Data Augmentation Approach for Natural Language Understanding and Generation
受多視圖學習的啟發,這篇文章主要提出了一種Cutoff的數據增強方法,包含以下三種策略:
Token cutoff:刪除選中的token信息。為了防止信息泄露,三種類型的編碼都被改為0。
Feature cutoff:刪除特征,將整列置為0。。
Span cutoff:刪除連續的文本塊。
作者將Cutoff應用到自然語言理解和機器翻譯任務上去,實驗結果表明這種簡單的數據增強方式得到了與基線相當或更好的結果。目前,Cutoff也作為一種常用的數據增強方法應用到不同的對比學習模型中去。
CERT:Contrastive Self-supervised Learning for Language Understanding
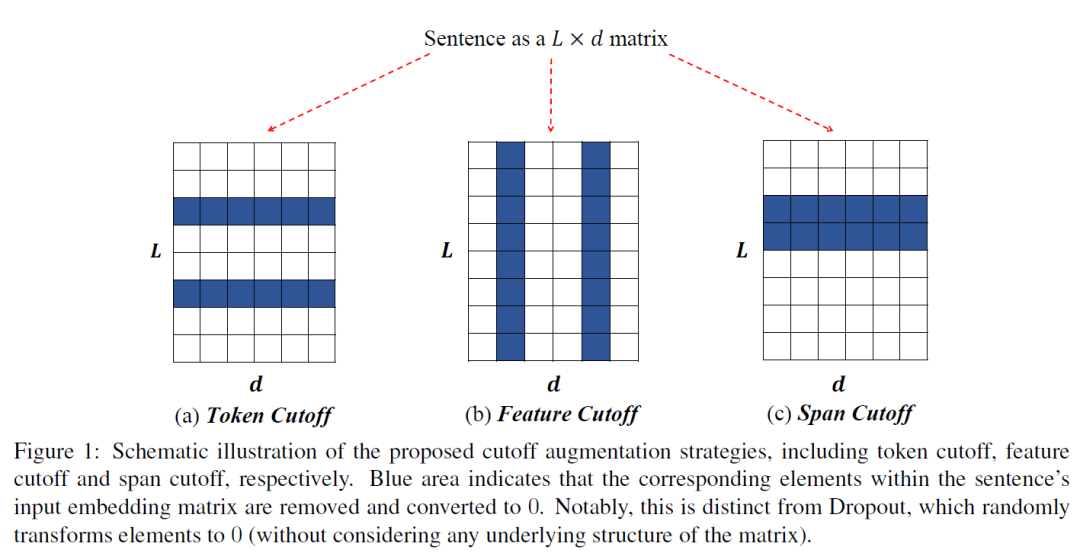
CERT主要流程圖如下。可以看出,在預訓練Bert的基礎上,CERT增加了CSSL預訓練任務來得到更好的表征。
本文首先通過back-translation方式進行數據增強,使用不同語言的翻譯模型來創建不同的正樣本。
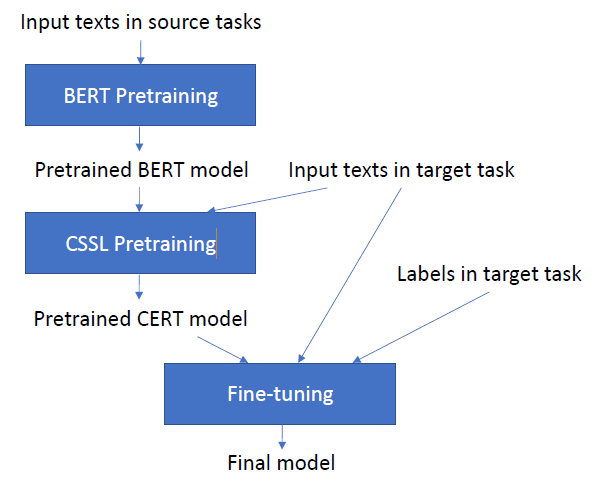
CSSL Pretraining:使用類似MoCo[7]的對比學習框架,采用一個隊列去存儲數據增強后的keys,并且使用一種動量更新的方法對該隊列進行更新。給定句子q,設隊列中存有與其互為正樣本的k+,故對比損失定義如下:
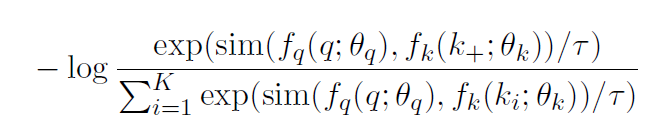
作者測試了CERT在GLUE 數據集的上的性能。在11個任務中,CERT在7個任務上優于BERT,2個任務上效果相當,整體性能優于BERT。這進一步證明了對比自監督學習是一個學習更好的語言表征的方法。
SimCSE: Simple Contrastive Learning of Sentence Embeddings(EMNLP2021)
SimCSE有兩個變體:Unsupervised SimCSE和Supervised SimCSE,主要不同在于對比學習的正負例的構造。
Unsupervised SimCSE:
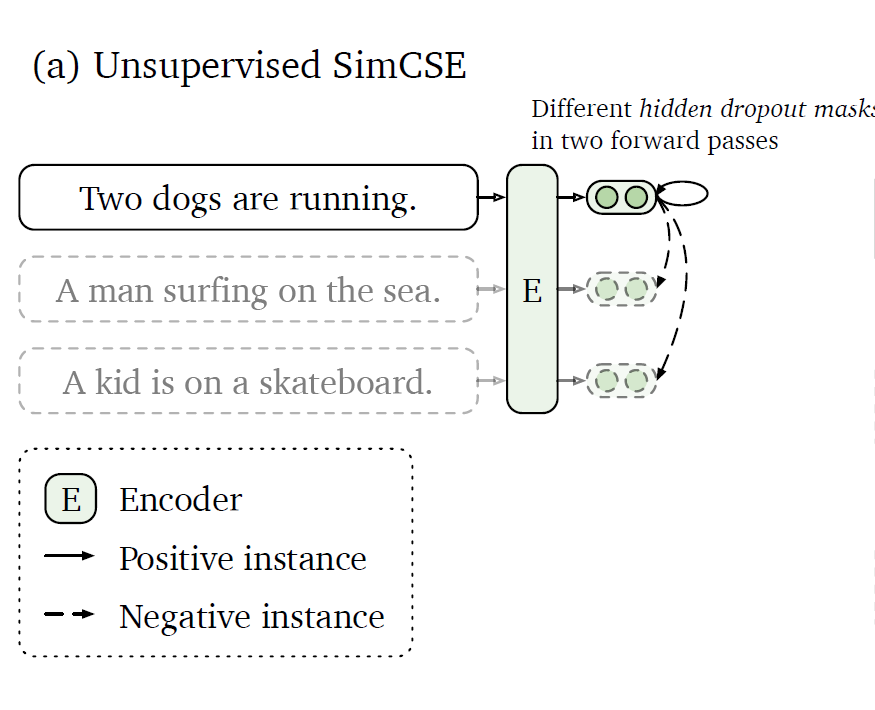
正樣本:一個句子通過編碼器進行兩次編碼,兩次使用不同的dropout 掩碼,
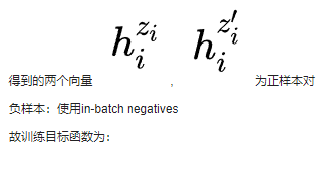
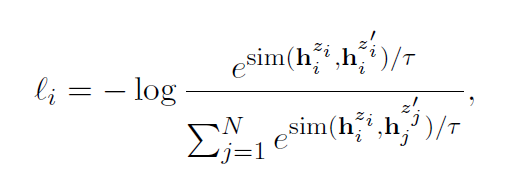
Supervised SimCSE:
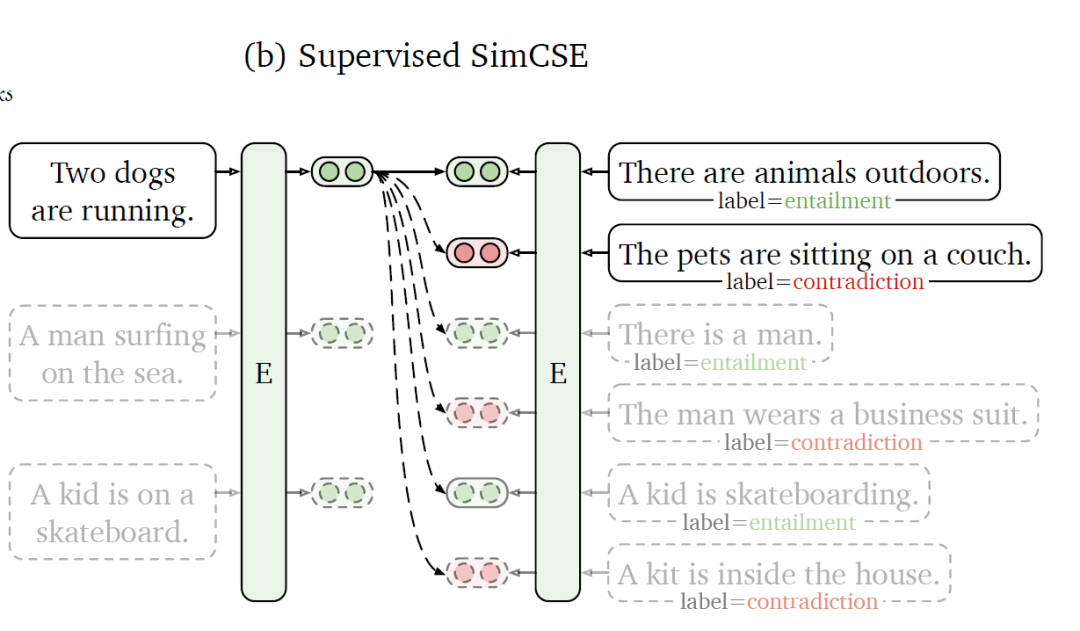
使用NLI(Natural Language Inference)數據集,利用其標注的句子之間的關系來構造對比學習的正負樣本。如上圖所示,給定一個前提

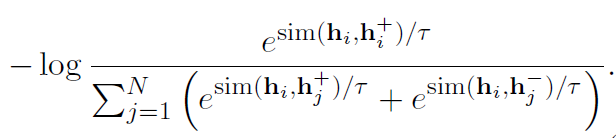
本文作者在多個數據集上評估了SimCSE的性能,發現在STS(語義文本相似性)系列任務上,SimCSE在無監督和有監督的條件下均大幅超越了之前的SOTA模型。
上面提到了衡量對比學習質量的指標:alignment和uniformity,作者將其進行了可視化,可以發現所有模型的uniformity都有所改進,表明預訓練BERT的語義向量分布的奇異性被逐步減弱。
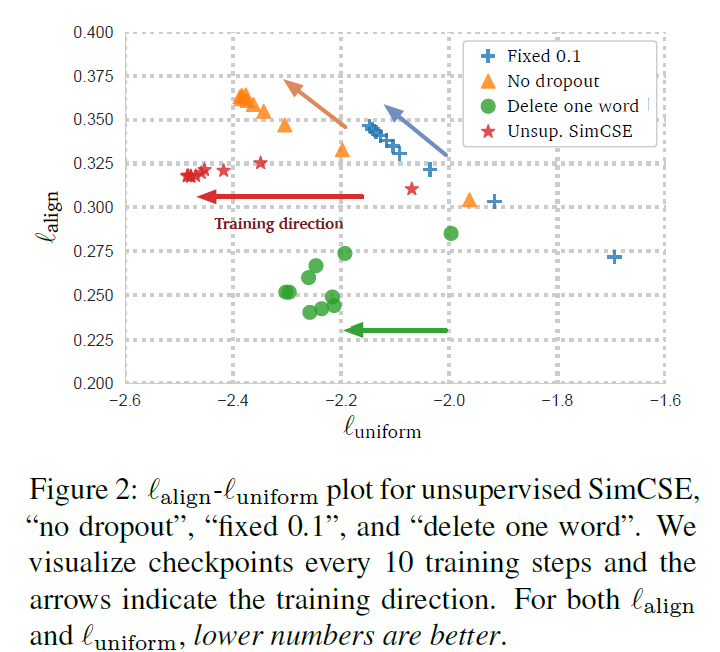
ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
ESimCSE是對上述SimCSE構建正負樣本方法的改進,主要出發點如下:
句子的長度信息通常會被編碼,因此無監督的SimCSE中的每個正對長度是相同的。故用這些正對訓練的無監督SimCSE 往往會認為長度相同或相似的句子在語義上更相似。
Momentum Contrast(動量對比)最早是在MoCo提出,是一種能夠有效的擴展負例對并同時緩解內存限制的一種方法。ESimCSE借鑒了這一思想來擴展負例。
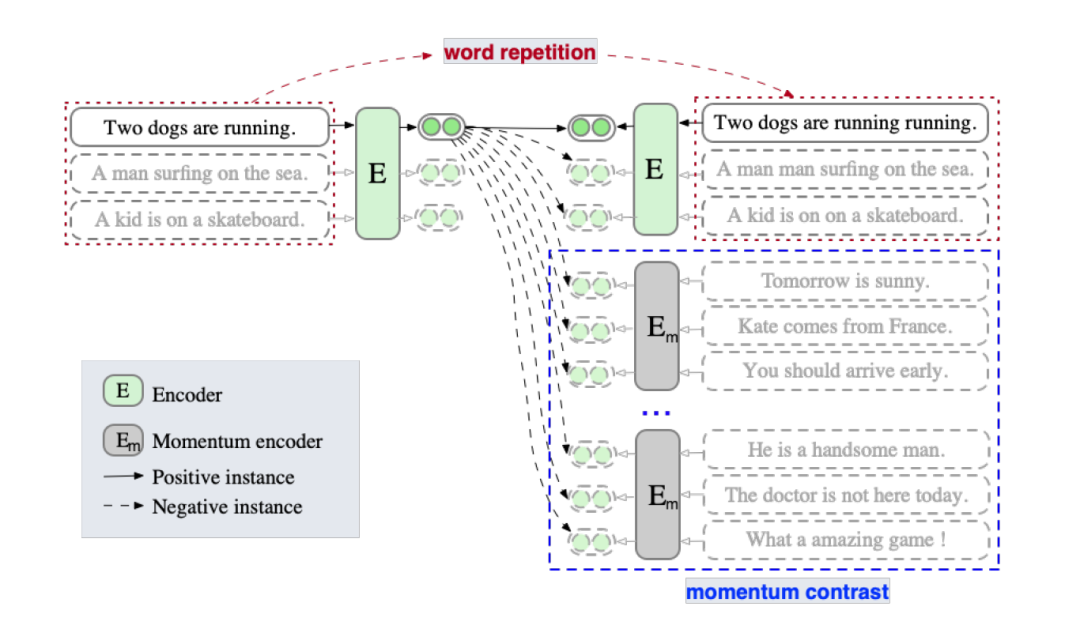
正例:作者先探究了句子對的長度差對SimCSE的影響,當長度差大于3時無監督SimCSE模型的效果大幅度降低。為了降低句子長度差異的影響,作者嘗試了隨機插入、隨機刪除和詞重復三種方法構建正例,發現前兩者導致語義相似度下降明顯,而詞重復可以保持較高的相似度,同時緩解了句子長度帶來的問題。故使用word repetition進行正例構造。
負例:① in-batch negatives ② 動量更新隊列中的樣本
故損失函數如下:
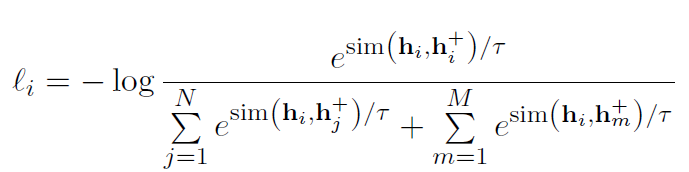
實驗表明,ESimCSE整體效果優于無監督的SimCSE,在語義文本相似性(STS)任務上效果優于BERTbase版的SimCSE 2%。
對比學習在多模態中的應用
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision (ICML 2021)
本文提出ALIGN模型,作者利用了超過10億的圖像文本對的噪聲數據集,沒有進行細致的數據清洗或處理。ALIGN使用一個簡單的雙編碼器結構,基于對比學習損失來對齊圖像和文本對的視覺和語言表示 。作者證明了,數據規模的巨大提升可以彌補數據內部存在的噪聲,因此即使使用簡單的對比學習方式,模型也能達到SOTA的特征表示。
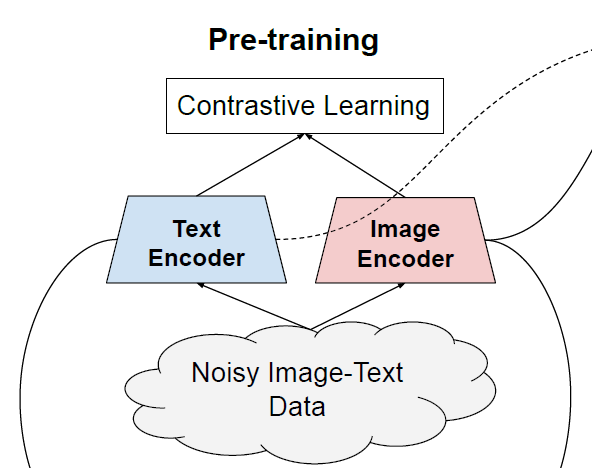
在預訓練中,將匹配的圖像-文本對視為正樣本,并將當前訓練batch中的其他隨機圖像-文本對視為負樣本。損失函數如下:
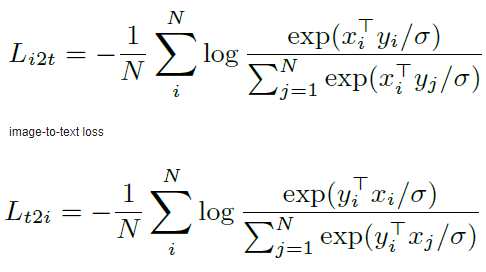
text-to-imageloss
ALIGN模型得到的對齊的圖像和文本表示在跨模態匹配/檢索任務中實現了SOTA效果。同時ALIGN模型也適用于zero-shot圖像分類、圖像分類等任務。例如,ALIGN在ImageNet中達到了88.64%的Top-1準確率 。
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation (NeurIPS 2021)
作者提出了 ALign BEfore Fuse(ALBEF) ,首先用一個圖像編碼器和一個文本編碼器獨立地對圖像和文本進行編碼。然后利用多模態編碼器,通過跨模態注意,將圖像特征與文本特征進行融合。并提出動量蒸餾(Momentum Distillation)對抗數據中的噪聲,得到更好的表征。
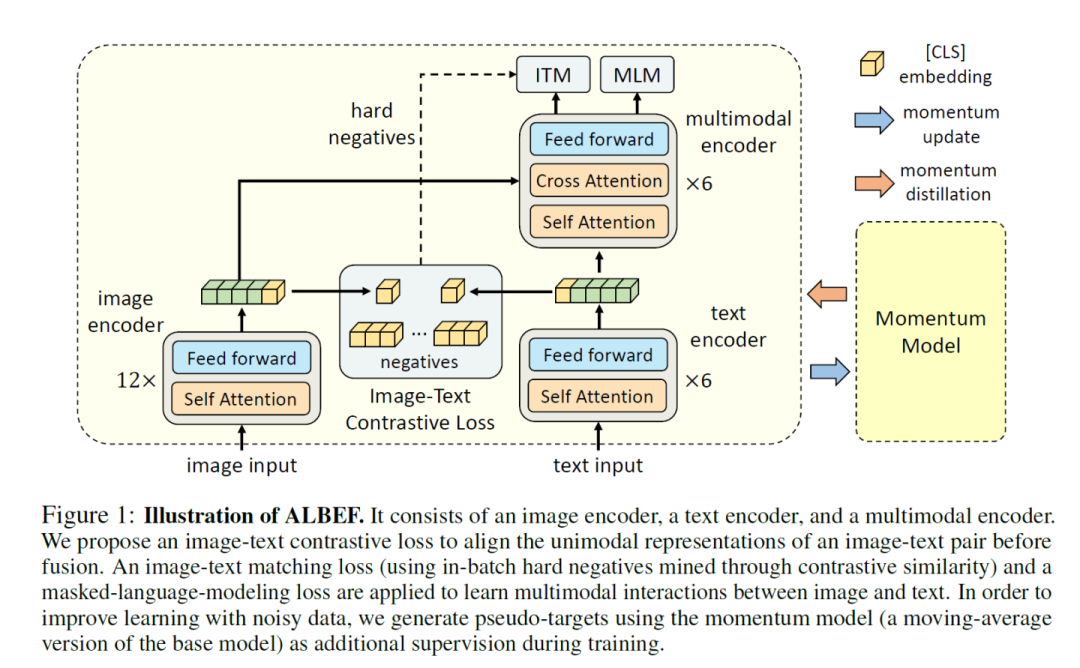
ALBEF預訓練任務:圖像-文本對比學習(ITC) 、掩蔽語言建模(MLM) 和圖像-文本匹配(ITM) 。
ITC:Image-Text Contrastive Learning,目的是在融合前學習到更好的單模態表征。受MoCo的啟發,作者維護了兩個隊列來存儲最近的M個圖像-文本表示,故對于每個圖像和文本,作者計算圖像到文本和文本到圖像的相似度如下:
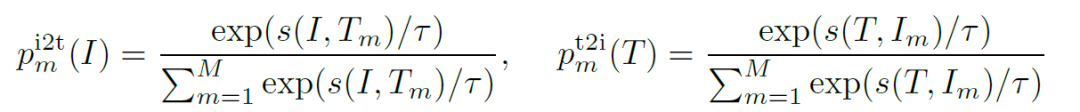
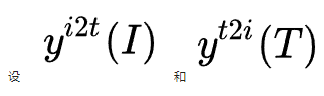
為ground truth(one-hot 編碼),ITC定義為p和y之間的交叉熵:
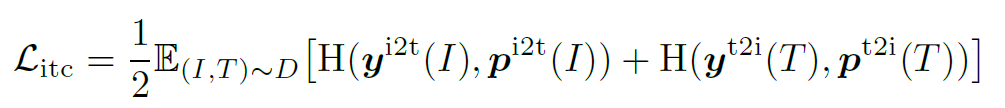
MLM:Masked Language Modeling,利用給定圖像和上下文文本來預測mask詞
ITM:Image-Text Matching,把圖像和文本是否匹配看作二分類問題
故整個預訓練的損失函數為上述三者的和。
由于用于預訓練的數據集往往含有噪聲,作者提出同時從動量模型生產的偽標簽中去學習。將上述相似度計算公式中的
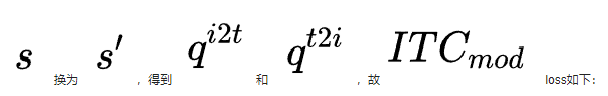
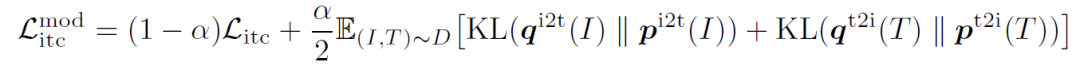
同時,作者從互信息最大化的角度來證明了ALBEF實際上最大化了圖像-文本對的不同views之間的互信息的下界。
與現有的方法相比,ALBEF在多個下游視覺語言任務上達到了SOTA的效果。
VLMO: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
本文提出VLMO模型,既可以作為融合編碼器去做分類任務,也可以作為雙編碼器去做檢索任務。VLMO引入一個 Mixture-of-Modality-Experts(MoME)的Transformer,能夠根據輸入數據的類型選擇不同的expert,如下圖所示。
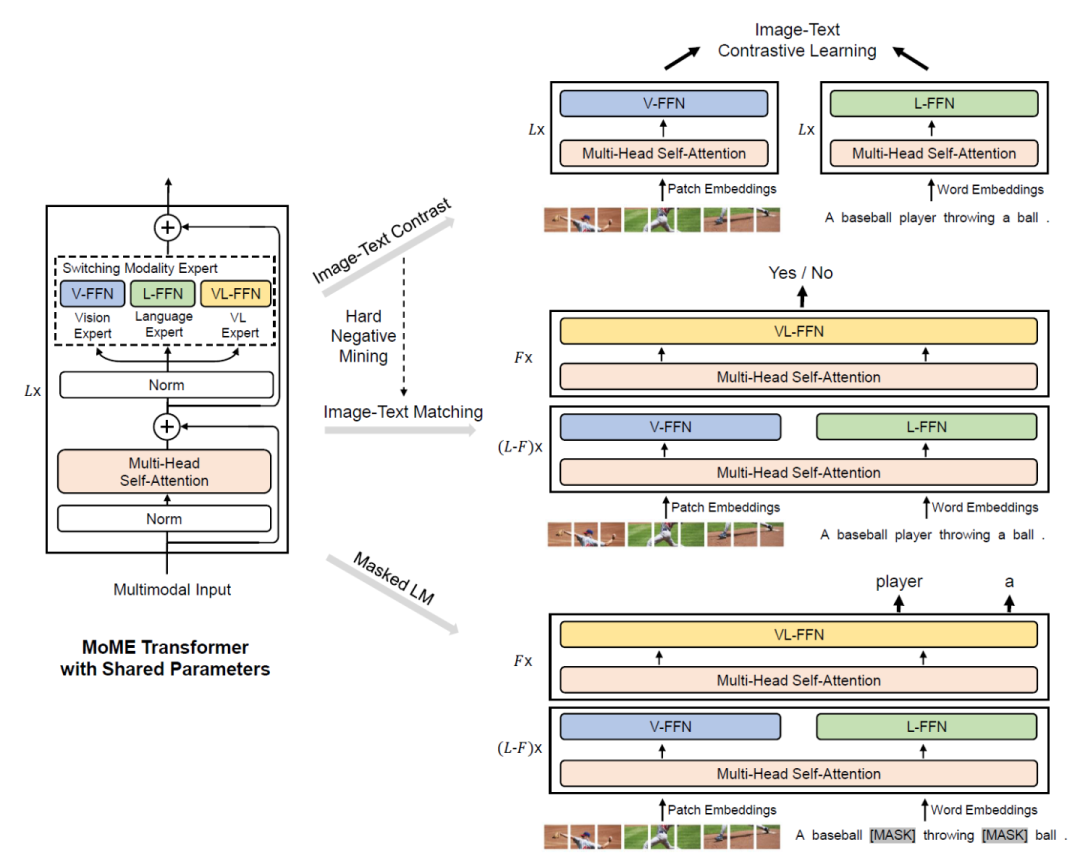
VLMO的預訓練任務與前面類似,通過圖像-文本對比學習、掩碼語言建模和圖像-文本對匹配進行聯合預訓練。
其中,Image-Text Contrast預訓練任務具體為:給定一個batch的圖像文本對,圖像文本對比學習的目標是從n*n個可能的圖像文本對中預測匹配的對,事實上在這一batch中有N個正樣本對,之后使用交叉熵損失進行訓練。下式中,h為編碼,p為softmax歸一化后的相似性。
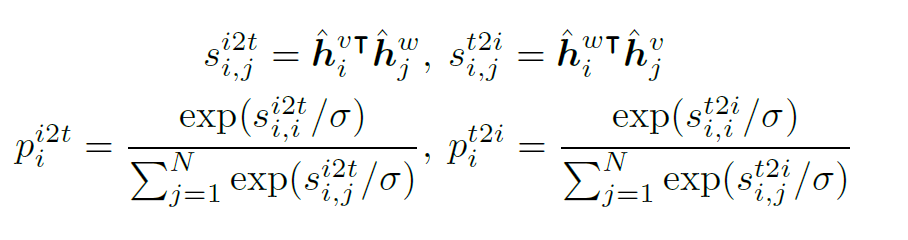
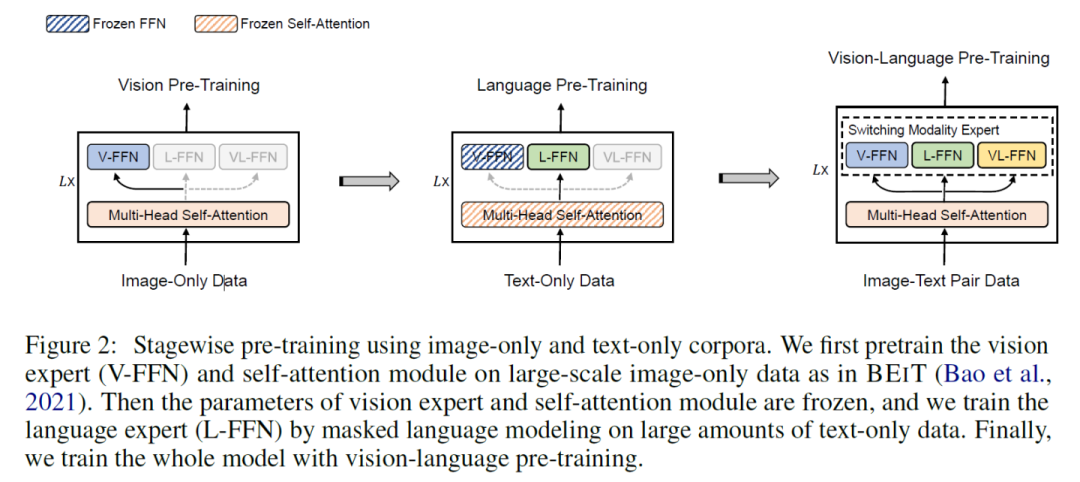
本文巧妙的地方在于采用了分階段的預訓練方式,得到了更泛化的表示。
VLMO模型在VQA等多模態下游任務上進行微調,效果達到了SOTA。
審核編輯:gt
-
谷歌
+關注
關注
27文章
6164瀏覽量
105323 -
nlp
+關注
關注
1文章
488瀏覽量
22033
原文標題:對比學習在NLP和多模態領域的應用
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
SOA關鍵技術專利分析(一)
云計算HPC軟件關鍵技術
深度學習在自動駕駛中的關鍵技術
儲能BMS的關鍵技術是什么
實時頻譜分析儀的關鍵技術淺析
矢量網絡分析儀的關鍵技術指標解讀
邏輯分析儀的基本原理、結構組成及關鍵技術
車載電池的類型及關鍵技術分析







 工商網監
工商網監
評論