 FPGA, CPU, GPU, ASIC區別,為什么使用FPGA?
FPGA, CPU, GPU, ASIC區別,為什么使用FPGA?
一、為什么使用 FPGA?
眾所周知,通用處理器(CPU)的摩爾定律已入暮年,而機器學習和 Web 服務的規模卻在指數級增長。
人們使用定制硬件來加速常見的計算任務,然而日新月異的行業又要求這些定制的硬件可被重新編程來執行新類型的計算任務。
FPGA 正是一種硬件可重構的體系結構。它的英文全稱是Field Programmable Gate Array,中文名是現場可編程門陣列。
FPGA常年來被用作專用芯片(ASIC)的小批量替代品,然而近年來在微軟、百度等公司的數據中心大規模部署,以同時提供強大的計算能力和足夠的靈活性。
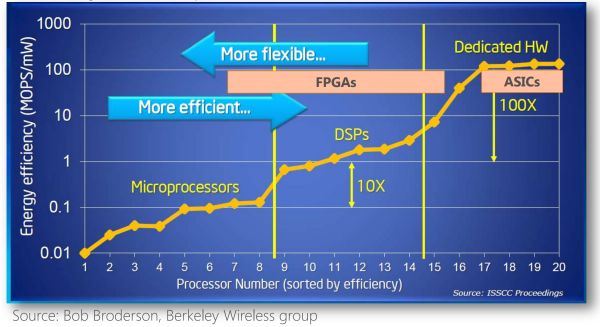
不同體系結構性能和靈活性的比較
FPGA 為什么快?「都是同行襯托得好」。
CPU、GPU 都屬于馮·諾依曼結構,指令譯碼執行、共享內存。FPGA 之所以比 CPU 甚至 GPU 能效高,本質上是無指令、無需共享內存的體系結構帶來的福利。
馮氏結構中,由于執行單元(如 CPU 核)可能執行任意指令,就需要有指令存儲器、譯碼器、各種指令的運算器、分支跳轉處理邏輯。由于指令流的控制邏輯復雜,不可能有太多條獨立的指令流,因此 GPU 使用 SIMD(單指令流多數據流)來讓多個執行單元以同樣的步調處理不同的數據,CPU 也支持 SIMD 指令。
而 FPGA 每個邏輯單元的功能在重編程(燒寫)時就已經確定,不需要指令
馮氏結構中使用內存有兩種作用。一是保存狀態,二是在執行單元間通信。
由于內存是共享的,就需要做訪問仲裁;為了利用訪問局部性,每個執行單元有一個私有的緩存,這就要維持執行部件間緩存的一致性。
對于保存狀態的需求,FPGA 中的寄存器和片上內存(BRAM)是屬于各自的控制邏輯的,無需不必要的仲裁和緩存。
對于通信的需求,FPGA 每個邏輯單元與周圍邏輯單元的連接在重編程(燒寫)時就已經確定,并不需要通過共享內存來通信。
說了這么多三千英尺高度的話,FPGA 實際的表現如何呢?我們分別來看計算密集型任務和通信密集型任務。
計算密集型任務的例子包括矩陣運算、圖像處理、機器學習、壓縮、非對稱加密、Bing 搜索的排序等。這類任務一般是 CPU 把任務卸載(offload)給 FPGA 去執行。對這類任務,目前我們正在用的 Altera(似乎應該叫 Intel 了,我還是習慣叫 Altera……)Stratix V FPGA 的整數乘法運算性能與 20 核的 CPU 基本相當,浮點乘法運算性能與 8 核的 CPU 基本相當,而比 GPU 低一個數量級。我們即將用上的下一代 FPGA,Stratix 10,將配備更多的乘法器和硬件浮點運算部件,從而理論上可達到與現在的頂級 GPU 計算卡旗鼓相當的計算能力。
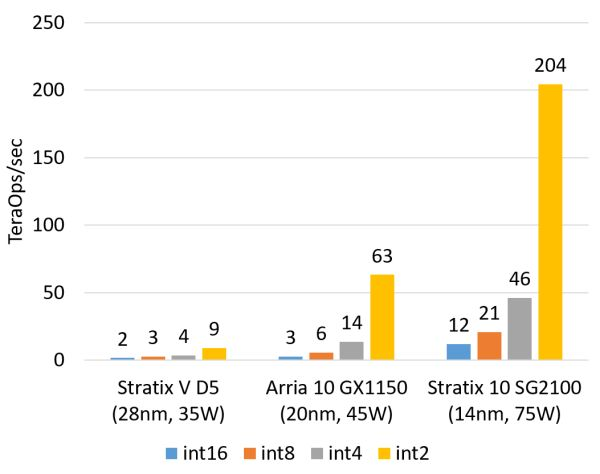
FPGA 的整數乘法運算能力(估計值,不使用 DSP,根據邏輯資源占用量估計)
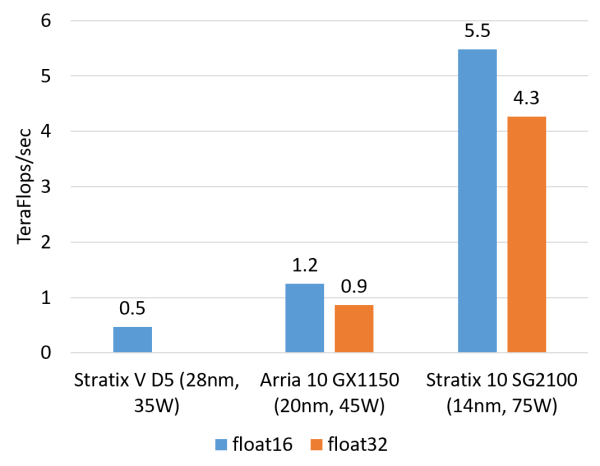
FPGA 的浮點乘法運算能力(估計值,float16 用軟核,float 32 用硬核)
在數據中心,FPGA 相比 GPU 的核心優勢在于延遲。
像 Bing 搜索排序這樣的任務,要盡可能快地返回搜索結果,就需要盡可能降低每一步的延遲
如果使用 GPU 來加速,要想充分利用 GPU 的計算能力,batch size 就不能太小,延遲將高達毫秒量級。
使用 FPGA 來加速的話,只需要微秒級的 PCIe 延遲(我們現在的 FPGA 是作為一塊 PCIe 加速卡)。
未來 Intel 推出通過 QPI 連接的 Xeon + FPGA 之后,CPU 和 FPGA 之間的延遲更可以降到 100 納秒以下,跟訪問主存沒什么區別了。
FPGA 為什么比 GPU 的延遲低這么多?
這本質上是體系結構的區別。
FPGA 同時擁有流水線并行和數據并行,而 GPU 幾乎只有數據并行(流水線深度受限)。
例如處理一個數據包有 10 個步驟,FPGA 可以搭建一個 10 級流水線,流水線的不同級在處理不同的數據包,每個數據包流經 10 級之后處理完成。每處理完成一個數據包,就能馬上輸出。
而 GPU 的數據并行方法是做 10 個計算單元,每個計算單元也在處理不同的數據包,然而所有的計算單元必須按照統一的步調,做相同的事情(SIMD,Single Instruction Multiple Data)。這就要求 10 個數據包必須一起輸入、一起輸出,輸入輸出的延遲增加了。
當任務是逐個而非成批到達的時候,流水線并行比數據并行可實現更低的延遲。因此對流式計算的任務,FPGA 比 GPU 天生有延遲方面的優勢。
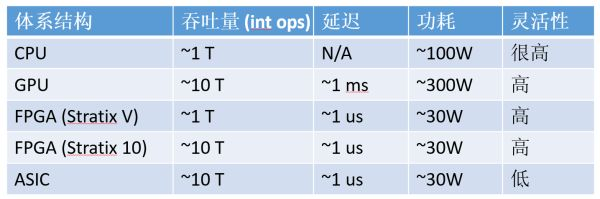
計算密集型任務,CPU、GPU、FPGA、ASIC 的數量級比較(以 16 位整數乘法為例,數字僅為數量級的估計
ASIC 專用芯片在吞吐量、延遲和功耗三方面都無可指摘,但微軟并沒有采用,出于兩個原因:
數據中心的計算任務是靈活多變的,而 ASIC 研發成本高、周期長。好不容易大規模部署了一批某種神經網絡的加速卡,結果另一種神經網絡更火了,錢就白費了。FPGA 只需要幾百毫秒就可以更新邏輯功能。FPGA 的靈活性可以保護投資,事實上,微軟現在的 FPGA 玩法與最初的設想大不相同。
數據中心是租給不同的租戶使用的,如果有的機器上有神經網絡加速卡,有的機器上有 Bing 搜索加速卡,有的機器上有網絡虛擬化加速卡,任務的調度和服務器的運維會很麻煩。使用 FPGA 可以保持數據中心的同構性。
接下來看通信密集型任務。
相比計算密集型任務,通信密集型任務對每個輸入數據的處理不甚復雜,基本上簡單算算就輸出了,這時通信往往會成為瓶頸。對稱加密、防火墻、網絡虛擬化都是通信密集型的例子。
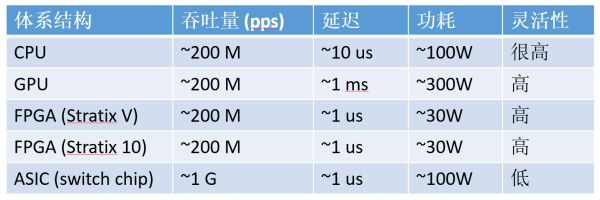
通信密集型任務,CPU、GPU、FPGA、ASIC 的數量級比較(以 64 字節網絡數據包處理為例,數字僅為數量級的估計)
對通信密集型任務,FPGA 相比 CPU、GPU 的優勢就更大了。
從吞吐量上講,FPGA 上的收發器可以直接接上 40 Gbps 甚至 100 Gbps 的網線,以線速處理任意大小的數據包;而 CPU 需要從網卡把數據包收上來才能處理,很多網卡是不能線速處理 64 字節的小數據包的。盡管可以通過插多塊網卡來達到高性能,但 CPU 和主板支持的 PCIe 插槽數量往往有限,而且網卡、交換機本身也價格不菲。
從延遲上講,網卡把數據包收到 CPU,CPU 再發給網卡,即使使用 DPDK 這樣高性能的數據包處理框架,延遲也有 4~5 微秒。更嚴重的問題是,通用 CPU 的延遲不夠穩定。例如當負載較高時,轉發延遲可能升到幾十微秒甚至更高(如下圖所示);現代操作系統中的時鐘中斷和任務調度也增加了延遲的不確定性。
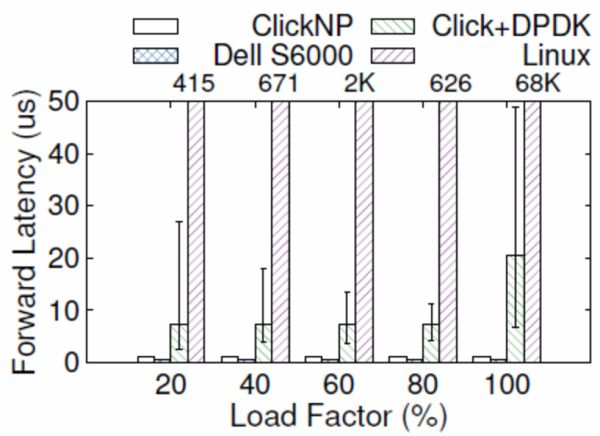
ClickNP(FPGA)與 Dell S6000 交換機(商用交換機芯片)、Click+DPDK(CPU)和 Linux(CPU)的轉發延遲比較,error bar 表示 5% 和 95%。來源:[5
雖然 GPU 也可以高性能處理數據包,但 GPU 是沒有網口的,意味著需要首先把數據包由網卡收上來,再讓 GPU 去做處理。這樣吞吐量受到 CPU 和/或網卡的限制。GPU 本身的延遲就更不必說了。
那么為什么不把這些網絡功能做進網卡,或者使用可編程交換機呢?ASIC 的靈活性仍然是硬傷。
盡管目前有越來越強大的可編程交換機芯片,比如支持 P4 語言的 Tofino,ASIC 仍然不能做復雜的有狀態處理,比如某種自定義的加密算法。
綜上,在數據中心里 FPGA 的主要優勢是穩定又極低的延遲,適用于流式的計算密集型任務和通信密集型任務。
二、微軟部署 FPGA 的實踐
2016 年 9 月,《連線》(Wired)雜志發表了一篇《微軟把未來押注在 FPGA 上》的報道 [3],講述了 Catapult 項目的前世今生。
緊接著,Catapult 項目的老大 Doug Burger 在 Ignite 2016 大會上與微軟 CEO Satya Nadella 一起做了 FPGA 加速機器翻譯的演
演示的總計算能力是 103 萬 T ops,也就是 1.03 Exa-op,相當于 10 萬塊頂級 GPU 計算卡。一塊 FPGA(加上板上內存和網絡接口等)的功耗大約是 30 W,僅增加了整個服務器功耗的十分之一。
Ignite 2016 上的演示:每秒 1 Exa-op (10^18) 的機器翻譯運算能力
微軟部署 FPGA 并不是一帆風順的。對于把 FPGA 部署在哪里這個問題,大致經歷了三個階段:
專用的 FPGA 集群,里面插滿了 FPGA
每臺機器一塊 FPGA,采用專用網絡連接
每臺機器一塊 FPGA,放在網卡和交換機之間,共享服務器網絡
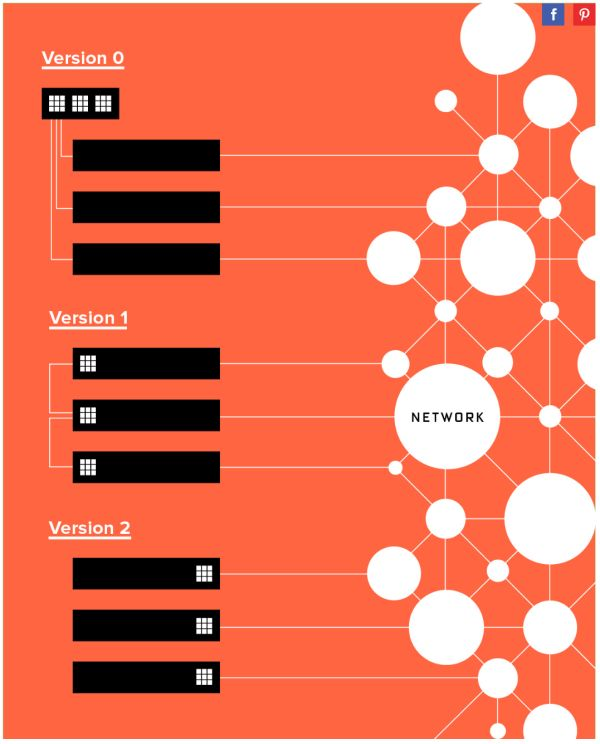
微軟 FPGA 部署方式的三個階段,來源:[3]
第一個階段是專用集群,里面插滿了 FPGA 加速卡,就像是一個 FPGA 組成的超級計算機。
下圖是最早的 BFB 實驗板,一塊 PCIe 卡上放了 6 塊 FPGA,每臺 1U 服務器上又插了 4 塊 PCIe 卡。

最早的 BFB 實驗板,上面放了 6 塊 FPGA。
可以注意到該公司的名字。在半導體行業,只要批量足夠大,芯片的價格都將趨向于沙子的價格。據傳聞,正是由于該公司不肯給「沙子的價格」 ,才選擇了另一家公
當然現在數據中心領域用兩家公司 FPGA 的都有。只要規模足夠大,對 FPGA 價格過高的擔心將是不必要的。
最早的 BFB 實驗板,1U 服務器上插了 4 塊 FPGA 卡。
像超級計算機一樣的部署方式,意味著有專門的一個機柜全是上圖這種裝了 24 塊 FPGA 的服務器(下圖左)。
這種方式有幾個問題:
不同機器的 FPGA 之間無法通信,FPGA 所能處理問題的規模受限于單臺服務器上 FPGA 的數量;
數據中心里的其他機器要把任務集中發到這個機柜,構成了 in-cast,網絡延遲很難做到穩定。
FPGA 專用機柜構成了單點故障,只要它一壞,誰都別想加速了;
裝 FPGA 的服務器是定制的,冷卻、運維都增加了麻煩。

部署 FPGA 的三種方式,從中心化到分布式。來源:[1]
一種不那么激進的方式是,在每個機柜一面部署一臺裝滿 FPGA 的服務器(上圖中)。這避免了上述問題 (2)(3),但 (1)(4) 仍然沒有解決。
第二個階段,為了保證數據中心中服務器的同構性(這也是不用 ASIC 的一個重要原因),在每臺服務器上插一塊 FPGA(上圖右),FPGA 之間通過專用網絡連接。這也是微軟在 ISCA'14 上所發表論文采用的部署方式。

Open Compute Server 在機架中。

Open Compute Server 內景。紅框是放 FPGA 的位置。

插入 FPGA 后的 Open Compute Server。

FPGA 與 Open Compute Server 之間的連接與固定。來源:[1]
FPGA 采用 Stratix V D5,有 172K 個 ALM,2014 個 M20K 片上內存,1590 個 DSP。板上有一個 8GB DDR3-1333 內存,一個 PCIe Gen3 x8 接口,兩個 10 Gbps 網絡接口。一個機柜之間的 FPGA 采用專用網絡連接,一組 10G 網口 8 個一組連成環,另一組 10G 網口 6 個一組連成環,不使用交換機。
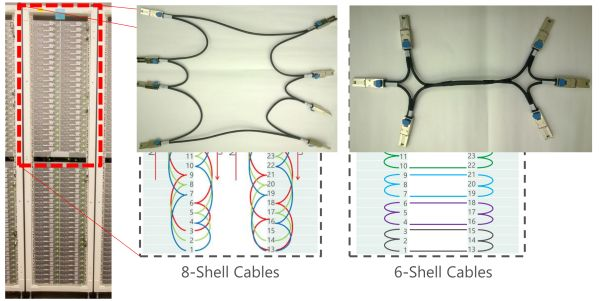
機柜中 FPGA 之間的網絡連接方式。來源:[1]
這樣一個 1632 臺服務器、1632 塊 FPGA 的集群,把 Bing 的搜索結果排序整體性能提高到了 2 倍(換言之,節省了一半的服務器)。
如下圖所示,每 8 塊 FPGA 穿成一條鏈,中間用前面提到的 10 Gbps 專用網線來通信。這 8 塊 FPGA 各司其職,有的負責從文檔中提取特征(黃色),有的負責計算特征表達式(綠色),有的負責計算文檔的得分(紅色)。
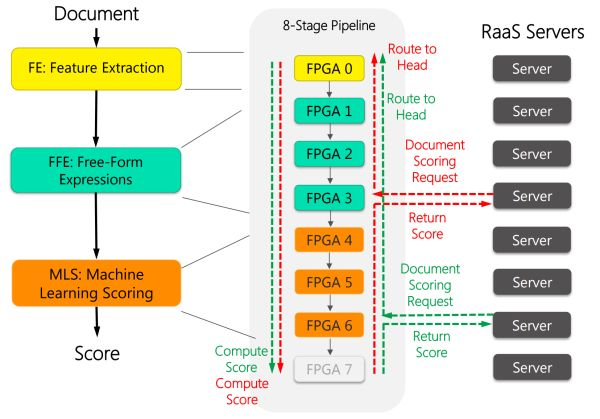
FPGA 加速 Bing 的搜索排序過程。來源:[1]
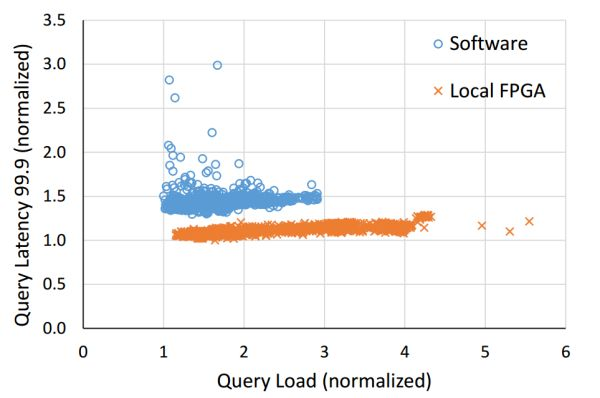
FPGA 不僅降低了 Bing 搜索的延遲,還顯著提高了延遲的穩定性。來源:[4]
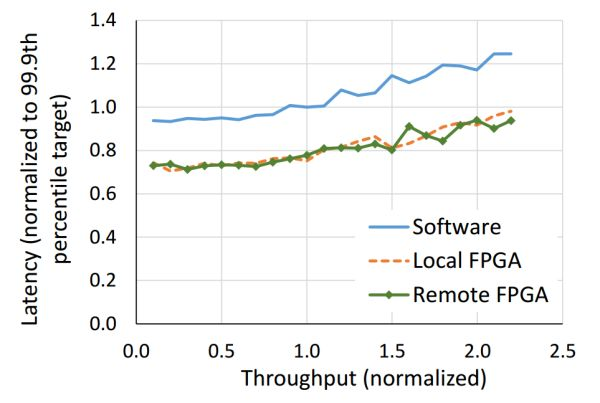
本地和遠程的 FPGA 均可以降低搜索延遲,遠程 FPGA 的通信延遲相比搜索延遲可忽略。來源:[4]
FPGA 在 Bing 的部署取得了成功,Catapult 項目繼續在公司內擴張。
微軟內部擁有最多服務器的,就是云計算 Azure 部門了。
Azure 部門急需解決的問題是網絡和存儲虛擬化帶來的開銷。Azure 把虛擬機賣給客戶,需要給虛擬機的網絡提供防火墻、負載均衡、隧道、NAT 等網絡功能。由于云存儲的物理存儲跟計算節點是分離的,需要把數據從存儲節點通過網絡搬運過來,還要進行壓縮和加密。
在 1 Gbps 網絡和機械硬盤的時代,網絡和存儲虛擬化的 CPU 開銷不值一提。隨著網絡和存儲速度越來越快,網絡上了 40 Gbps,一塊 SSD 的吞吐量也能到 1 GB/s,CPU 漸漸變得力不從心了。
例如 Hyper-V 虛擬交換機只能處理 25 Gbps 左右的流量,不能達到 40 Gbps 線速,當數據包較小時性能更差;AES-256 加密和 SHA-1 簽名,每個 CPU 核只能處理 100 MB/s,只是一塊 SSD 吞吐量的十分之一。
網絡隧道協議、防火墻處理 40 Gbps 需要的 CPU 核數。來源:[5]
為了加速網絡功能和存儲虛擬化,微軟把 FPGA 部署在網卡和交換機之間。
如下圖所示,每個 FPGA 有一個 4 GB DDR3-1333 DRAM,通過兩個 PCIe Gen3 x8 接口連接到一個 CPU socket(物理上是 PCIe Gen3 x16 接口,因為 FPGA 沒有 x16 的硬核,邏輯上當成兩個 x8 的用)。物理網卡(NIC)就是普通的 40 Gbps 網卡,僅用于宿主機與網絡之間的通信。
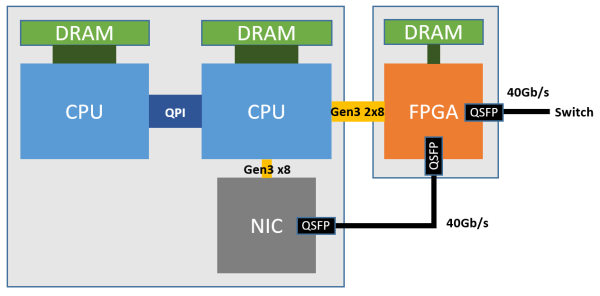
Azure 服務器部署 FPGA 的架構。來源:[6]
FPGA(SmartNIC)對每個虛擬機虛擬出一塊網卡,虛擬機通過 SR-IOV 直接訪問這塊虛擬網卡。原本在虛擬交換機里面的數據平面功能被移到了 FPGA 里面,虛擬機收發網絡數據包均不需要 CPU 參與,也不需要經過物理網卡(NIC)。這樣不僅節約了可用于出售的 CPU 資源,還提高了虛擬機的網絡性能(25 Gbps),把同數據中心虛擬機之間的網絡延遲降低了 10 倍。
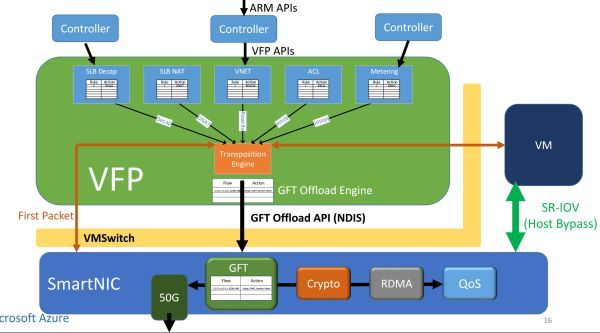
網絡虛擬化的加速架構。來源:[6]
這就是微軟部署 FPGA 的第三代架構,也是目前「每臺服務器一塊 FPGA」大規模部署所采用的架構。
FPGA 復用主機網絡的初心是加速網絡和存儲,更深遠的影響則是把 FPGA 之間的網絡連接擴展到了整個數據中心的規模,做成真正 cloud-scale 的「超級計算機」。
第二代架構里面,FPGA 之間的網絡連接局限于同一個機架以內,FPGA 之間專網互聯的方式很難擴大規模,通過 CPU 來轉發則開銷太高。
第三代架構中,FPGA 之間通過 LTL (Lightweight Transport Layer) 通信。同一機架內延遲在 3 微秒以內;8 微秒以內可達 1000 塊 FPGA;20 微秒可達同一數據中心的所有 FPGA。第二代架構盡管 8 臺機器以內的延遲更低,但只能通過網絡訪問 48 塊 FPGA。為了支持大范圍的 FPGA 間通信,第三代架構中的 LTL 還支持 PFC 流控協議和 DCQCN 擁塞控制協議。
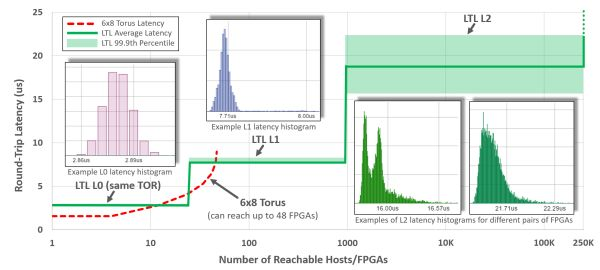
縱軸:LTL 的延遲,橫軸:可達的 FPGA 數量。來源:[4]
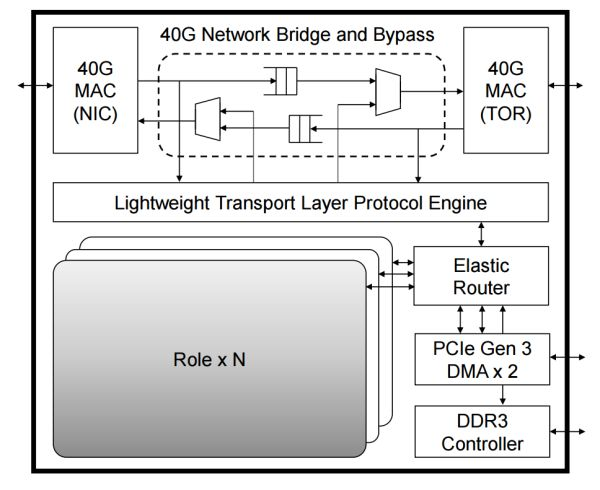
FPGA 內的邏輯模塊關系,其中每個 Role 是用戶邏輯(如 DNN 加速、網絡功能加速、加密),外面的部分負責各個 Role 之間的通信及 Role 與外設之間的通信。來源:[4]
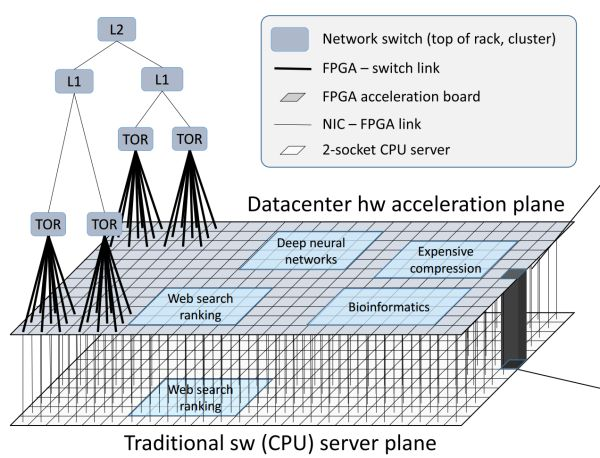
FPGA 構成的數據中心加速平面,介于網絡交換層(TOR、L1、L2)和傳統服務器軟件(CPU 上運行的軟件)之間。來源:[4]
通過高帶寬、低延遲的網絡互聯的 FPGA 構成了介于網絡交換層和傳統服務器軟件之間的數據中心加速平面。
除了每臺提供云服務的服務器都需要的網絡和存儲虛擬化加速,FPGA 上的剩余資源還可以用來加速 Bing 搜索、深度神經網絡(DNN)等計算任務。
對很多類型的應用,隨著分布式 FPGA 加速器的規模擴大,其性能提升是超線性的。
例如 CNN inference,當只用一塊 FPGA 的時候,由于片上內存不足以放下整個模型,需要不斷訪問 DRAM 中的模型權重,性能瓶頸在 DRAM;如果 FPGA 的數量足夠多,每塊 FPGA 負責模型中的一層或者一層中的若干個特征,使得模型權重完全載入片上內存,就消除了 DRAM 的性能瓶頸,完全發揮出 FPGA 計算單元的性能。
當然,拆得過細也會導致通信開銷的增加。把任務拆分到分布式 FPGA 集群的關鍵在于平衡計算和通信。
從神經網絡模型到 HaaS 上的 FPGA。利用模型內的并行性,模型的不同層、不同特征映射到不同 FPGA。來源:[4]
在 MICRO'16 會議上,微軟提出了 Hardware as a Service (HaaS) 的概念,即把硬件作為一種可調度的云服務,使得 FPGA 服務的集中調度、管理和大規模部署成為可能。
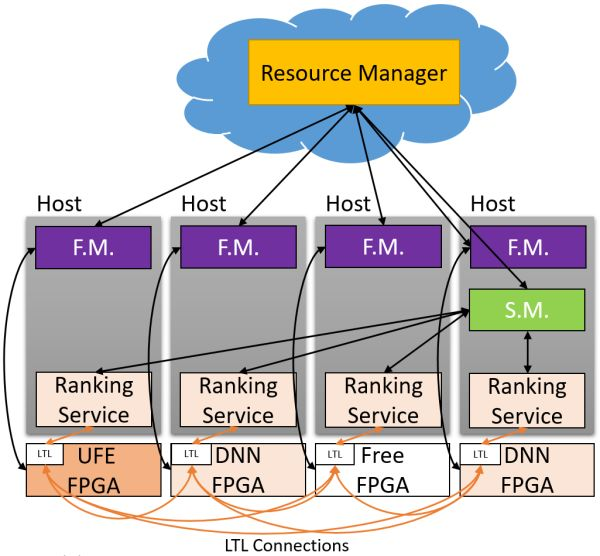
Hardware as a Service (HaaS)。來源:[4]
從第一代裝滿 FPGA 的專用服務器集群,到第二代通過專網連接的 FPGA 加速卡集群,到目前復用數據中心網絡的大規模 FPGA 云,三個思想指導我們的路線:
硬件和軟件不是相互取代的關系,而是合作的關系;
必須具備靈活性,即用軟件定義的能力;
必須具備可擴放性(scalability)。
三、FPGA 在云計算中的角色
FPGA 在云規模的網絡互連系統中應當充當怎樣的角色?
如何高效、可擴放地對 FPGA + CPU 的異構系統進行編程?
我對 FPGA 業界主要的遺憾是,FPGA 在數據中心的主流用法,從除微軟外的互聯網巨頭,到兩大 FPGA 廠商,再到學術界,大多是把 FPGA 當作跟 GPU 一樣的計算密集型任務的加速卡。然而 FPGA 真的很適合做 GPU 的事情嗎?
前面講過,FPGA 和 GPU 最大的區別在于體系結構,FPGA 更適合做需要低延遲的流式處理,GPU 更適合做大批量同構數據的處理。
由于很多人打算把 FPGA 當作計算加速卡來用,兩大 FPGA 廠商推出的高層次編程模型也是基于 OpenCL,模仿 GPU 基于共享內存的批處理模式。CPU 要交給 FPGA 做一件事,需要先放進 FPGA 板上的 DRAM,然后告訴 FPGA 開始執行,FPGA 把執行結果放回 DRAM,再通知 CPU 去取回。
CPU 和 FPGA 之間本來可以通過 PCIe 高效通信,為什么要到板上的 DRAM 繞一圈?也許是工程實現的問題,我們發現通過 OpenCL 寫 DRAM、啟動 kernel、讀 DRAM 一個來回,需要 1.8 毫秒。而通過 PCIe DMA 來通信,卻只要 1~2 微秒。
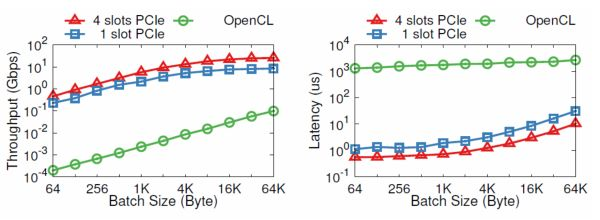
PCIe I/O channel 與 OpenCL 的性能比較。縱坐標為對數坐標。來源:[5
OpenCL 里面多個 kernel 之間的通信就更夸張了,默認的方式也是通過共享內存。
本文開篇就講,FPGA 比 CPU 和 GPU 能效高,體系結構上的根本優勢是無指令、無需共享內存。使用共享內存在多個 kernel 之間通信,在順序通信(FIFO)的情況下是毫無必要的。況且 FPGA 上的 DRAM 一般比 GPU 上的 DRAM 慢很多。
因此我們提出了 ClickNP 網絡編程框架 [5],使用管道(channel)而非共享內存來在執行單元(element/kernel)間、執行單元和主機軟件間進行通信。
需要共享內存的應用,也可以在管道的基礎上實現,畢竟 CSP(Communicating Sequential Process)和共享內存理論上是等價的嘛。ClickNP 目前還是在 OpenCL 基礎上的一個框架,受到 C 語言描述硬件的局限性(當然 HLS 比 Verilog 的開發效率確實高多了)。理想的硬件描述語言,大概不會是 C 語言吧。
ClickNP 使用 channel 在 elements 間通信,來源:[5]
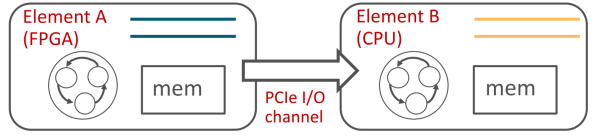
ClickNP 使用 channel 在 FPGA 和 CPU 間通信,來源:[5]
低延遲的流式處理,需要最多的地方就是通信。
然而CPU 由于并行性的限制和操作系統的調度,做通信效率不高,延遲也不穩定。
此外,通信就必然涉及到調度和仲裁,CPU 由于單核性能的局限和核間通信的低效,調度、仲裁性能受限,硬件則很適合做這種重復工作。因此我的博士研究把 FPGA 定義為通信的「大管家」,不管是服務器跟服務器之間的通信,虛擬機跟虛擬機之間的通信,進程跟進程之間的通信,CPU 跟存儲設備之間的通信,都可以用 FPGA 來加速。
成也蕭何,敗也蕭何。缺少指令同時是 FPGA 的優勢和軟肋。
每做一點不同的事情,就要占用一定的 FPGA 邏輯資源。如果要做的事情復雜、重復性不強,就會占用大量的邏輯資源,其中的大部分處于閑置狀態。這時就不如用馮·諾依曼結構的處理器。
數據中心里的很多任務有很強的局部性和重復性:一部分是虛擬化平臺需要做的網絡和存儲,這些都屬于通信;另一部分是客戶計算任務里的,比如機器學習、加密解密。
首先把 FPGA 用于它最擅長的通信,日后也許也會像 AWS 那樣把 FPGA 作為計算加速卡租給客戶。
不管通信還是機器學習、加密解密,算法都是很復雜的,如果試圖用 FPGA 完全取代 CPU,勢必會帶來 FPGA 邏輯資源極大的浪費,也會提高 FPGA 程序的開發成本。更實用的做法是FPGA 和 CPU 協同工作,局部性和重復性強的歸 FPGA,復雜的歸 CPU。
當我們用 FPGA 加速了 Bing 搜索、深度學習等越來越多的服務;當網絡虛擬化、存儲虛擬化等基礎組件的數據平面被 FPGA 把持;當 FPGA 組成的「數據中心加速平面」成為網絡和服務器之間的天塹……似乎有種感覺,FPGA 將掌控全局,CPU 上的計算任務反而變得碎片化,受 FPGA 的驅使。以往我們是 CPU 為主,把重復的計算任務卸載(offload)到 FPGA 上;以后會不會變成 FPGA 為主,把復雜的計算任務卸載到 CPU 上呢?隨著 Xeon + FPGA 的問世,古老的 SoC 會不會在數據中心煥發新生?
審核編輯 :李倩
-
FPGA
+關注
關注
1629文章
21729瀏覽量
603013 -
機器學習
+關注
關注
66文章
8406瀏覽量
132567
原文標題:FPGA, CPU, GPU, ASIC區別,FPGA為何這么牛
文章出處:【微信號:gh_9d70b445f494,微信公眾號:FPGA設計論壇】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

FPGA真的能取代CPU和GPU嗎?
自動駕駛主流架構方案對比:GPU、FPGA、ASIC
相比CPU、GPU、ASIC,FPGA有什么優勢
ASIC和FPGA有什么區別
ASIC、ASSP、SoC和FPGA之間到底有何區別?
FPGA為什么比CPU和GPU快
什么是ASIC芯片?與CPU、GPU、FPGA相比如何?





 工商網監
工商網監
評論